I denne artikel vil vi diskutere typiske fejl, som nybegyndere kan stå over for, mens de designer T-SQL-kode. Derudover vil vi se på bedste praksis og nogle nyttige tips, der kan hjælpe dig, når du arbejder med SQL Server, samt løsninger til forbedring af ydeevnen.
Indhold:
1. Datatyper
2. *
3. Alias
4. Kolonnerækkefølge
5. NOT IN vs NULL
6. Datoformat
7. Datofilter
8. Beregning
9. Konverter implicit
10. LIKE &undertrykt indeks
11. Unicode vs ANSI
12. SAMLET
13. BINÆR SAMLING
14. Kodestil
15. [var]char
16. Datalængde
17. ISNULL vs COALESCE
18. Matematik
19. UNION vs UNION ALLE
20. Genlæs
21. Underforespørgsel
22. TILFÆLDE HVORNÅR
23. Skalær funktion
24. VISNINGER
25. CURSORER
26. STRING_CONCAT
27. SQL-injektion
Datatyper
Det største problem, vi står over for, når vi arbejder med SQL Server, er et forkert valg af datatyper.
Antag, at vi har to identiske tabeller:
DECLARE @Employees1 TABEL ( EmployeeID BIGINT PRIMARY KEY , IsMale VARCHAR(3) , Fødselsdato VARCHAR(20))INDSÆT I @Employees1VALUES (123, 'JA', '2012-09-01')DEKLARER Employeem TAB INT PRIMARY KEY , IsMale BIT , Fødselsdato)INDSÆT I @Employees2VALUES (123, 1, '2012-09-01')
Lad os udføre en forespørgsel for at kontrollere, hvad forskellen er:
DECLARE @BirthDate DATE ='2012-09-01'SELECT * FROM @Employees1 WHERE BirthDate =@BirthDateSELECT * FRA @Employees2 WHERE BirthDate =@BirthDate
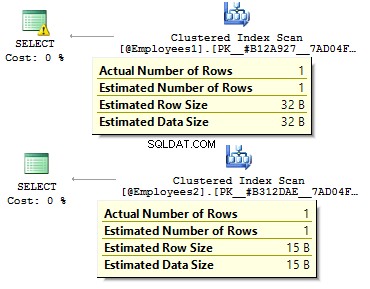
I det første tilfælde er datatyperne mere overflødige, end de måske er. Hvorfor skal vi gemme en bitværdi som JA/NEJ række? Hvorfor skal vi gemme en dato som en række? Hvorfor skal vi bruge BIGINT for medarbejdere i tabellen i stedet for INT ?
Det fører til følgende ulemper:
- Tabeller kan tage meget plads på disken;
- Vi er nødt til at læse flere sider og lægge flere data i BufferPool at håndtere data.
- Dårlig ydeevne.
*
Jeg har stået over for den situation, hvor udviklere henter alle data fra en tabel, og derefter på klientsiden bruger DataReader kun at vælge nødvendige felter. Jeg anbefaler ikke at bruge denne tilgang:
BRUG AdventureWorks2014GOSET STATISTICS TID, IO TILVÆLG *FRA Person.PersonSELECT BusinessEntityID , FirstName , MiddleName , EfternavnFRA Person.PersonSET STATISTICS TIME, IO OFF
Der vil være en væsentlig forskel i forespørgslens udførelsestid. Derudover kan det dækkende indeks reducere en række logiske læsninger.
Tabel 'Person'. Scanningsantal 1, logisk læser 3819, fysisk læser 3, ... SQL Server-udførelsestider:CPU-tid =31 ms, forløbet tid =1235 ms. Tabel 'Person'. Scanningsantal 1, logisk læsning 109, fysisk læsning 1, ... SQL Server-udførelsestider:CPU-tid =0 ms, forløbet tid =227 ms.
Alias
Lad os oprette en tabel:
USE AdventureWorks2014GOIF OBJECT_ID('Sales.UserCurrency') IS NOT NULL DROP TABLE Sales.UserCurrencyGOCREATE TABEL Sales.UserCurrency ( Valutakode NCHAR(3) PRIMÆR NØGLE)INSERT INDSÆT Salg.VÆRDIERCURS'>INSERT (VÆRDIERCURS)
Antag, at vi har en forespørgsel, der returnerer antallet af identiske rækker i begge tabeller:
VÆLG COUNT_BIG(*)FROM Sales.CurrencyWHERE CurrencyCode IN (SELECT CurrencyCode FROM Sales.UserCurrency)
Alt vil fungere som forventet, indtil nogen omdøber en kolonne i Sales.UserCurrency tabel:
EXEC sys.sp_rename 'Sales.UserCurrency.CurrencyCode', 'Code', 'COLUMN'
Dernæst vil vi udføre en forespørgsel og se, at vi får alle rækkerne i Sales.Currency tabel i stedet for 1 række. Ved opbygning af en eksekveringsplan vil SQL Server på bindingsstadiet kontrollere kolonnerne i Sales.UserCurrency, den vil ikke finde CurrencyCode der og beslutter, at denne kolonne tilhører Sales.Currency bord. Derefter vil en optimeringsværktøj slette CurrencyCode =CurrencyCode tilstand.
Derfor anbefaler jeg at bruge aliaser:
VÆLG COUNT_BIG(*)FROM Sales.Currency cWHERE c.CurrencyCode IN (VÆLG u.CurrencyCode FROM Sales.UserCurrency u )
Kolonnerækkefølge
Antag, at vi har en tabel:
HVIS OBJECT_ID('dbo.DatePeriod') IKKE ER NULL DROP TABEL dbo.DatePeriodGOCREATE TABEL dbo.DatePeriod (StartDato DATO , Slutdato DATO)
Vi indsætter altid data der baseret på oplysningerne om kolonnerækkefølgen.
INSERT INTO dbo.DatePeriodSELECT '2015-01-01', '2015-01-31'
Antag, at nogen ændrer rækkefølgen af kolonner:
OPRET TABEL dbo.DatePeriod ( EndDate DATE , StartDate DATE)
Data vil blive indsat i en anden rækkefølge. I dette tilfælde er det en god idé eksplicit at angive kolonner i INSERT-sætningen:
INSERT INTO dbo.DatePeriod (StartDate, EndDate)SELECT '2015-01-01', '2015-01-31'
Her er et andet eksempel:
VÆLG TOP(1) *FRA dbo.DatePeriodORDER BY 2 DESC
På hvilken kolonne skal vi bestille data? Det vil afhænge af kolonnerækkefølgen i en tabel. Hvis man ændrer rækkefølgen, får vi forkerte resultater.
IKKE IN vs. NULL
Lad os tale om NOT IN erklæring.
For eksempel skal du skrive et par forespørgsler:returner posterne fra den første tabel, som ikke findes i den anden tabel og visa vers. Normalt bruger juniorudviklere IN og IKKE I :
ERKLÆR @t1 TABEL (t1 INT, UNIK KLUSTERET(t1))INDSÆT I @t1-VÆRDIER (1), (2)ERKLÆR @t2 TABEL (t2 INT, UNIK KLYNGERET(t2))INDSÆT I @t2-VÆRDIER (1) )SELECT *FROM @t1WHERE t1 NOT IN (SELECT t2 FROM @t2)SELECT *FROM @t1WHERE t1 IN (SELECT t2 FROM @t2)
Den første forespørgsel returnerede 2, den anden – 1. Yderligere tilføjer vi en anden værdi i den anden tabel – NULL :
INSERT INTO @t2 VALUES (1), (NULL)
Når du udfører forespørgslen med NOT IN , får vi ingen resultater. Hvorfor IN virker og IKKE I ikke? Årsagen er, at SQL Server bruger TRUE , FALSK , og UKENDT logik ved sammenligning af data.
Når en forespørgsel udføres, fortolker SQL Server IN-betingelsen på følgende måde:
a IN (1, NULL) ==a=1 ELLER a=NULL
IKKE I :
a NOT IN (1, NULL) ==a<>1 OG en<>NULL
Når du sammenligner en værdi med NULL, SQL Server returnerer UNKNOWN. Enten1=NULL eller NULL=NULL – begge resulterer i UKENDT. Så vidt vi har OG i udtrykket, returnerer begge sider UKENDT.
Jeg vil gerne påpege, at denne sag ikke er sjælden. For eksempel markerer du en kolonne som IKKE NULL. Efter et stykke tid beslutter en anden udvikler at tillade NULLs for den kolonne. Dette kan føre til den situation, at en klientrapport holder op med at virke, når en NULL-værdi er indsat i tabellen.
I dette tilfælde vil jeg anbefale at ekskludere NULL-værdier:
VÆLG *FRA @t1WHERE t1 NOT IN (VÆLG t2 FRA @t2 HVOR t2 IKKE ER NULL)
Derudover er det muligt at bruge EXCEPT :
VÆLG * FRA @t1EXCEPTSELECT * FRA @t2
Alternativt kan du bruge FINDER IKKE :
VÆLG *FRA @t1WHERE IKKE FINDER(VÆLG 1 FRA @t2 HVOR t1 =t2)
Hvilken mulighed er mere at foretrække? Sidstnævnte mulighed med FINDER IKKE synes at være den mest produktive, da den genererer den mere optimale prædikat pushdown operatør for at få adgang til data fra den anden tabel.
Faktisk kan NULL-værdierne returnere et uventet resultat.
Overvej det på dette særlige eksempel:
BRUG AdventureWorks2014GOSELECT COUNT_BIG(*)FROM Production.ProductSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color ='Grey'SELECT COUNT_BIG(*)FROM Production.ProductWHERE Farve <> 'Grå'
Som du kan se, har du ikke fået det forventede resultat af den grund, at NULL-værdier har separate sammenligningsoperatorer:
VÆLG COUNT_BIG(*)FROM Production.ProductWHERE Color IS NULLSELECT COUNT_BIG(*)FROM Production.ProductWHERE Color IS NOT NULL
Her er et andet eksempel med CHECK begrænsninger:
HVIS OBJECT_ID('tempdb.dbo.#temp') IKKE ER NULL DROP TABEL #tempGOCREATE TABEL #temp ( Farve VARCHAR(15) --NULL , CONSTRAINT CK CHECK (Color IN ('Sort', 'White') ))
Vi opretter en tabel med tilladelse til kun at indsætte hvide og sorte farver:
INSERT INTO #temp VALUES ('Sort')(1 række(r) påvirket)
Alt fungerer som forventet.
INSERT INTO #temp VALUES ('Rød') INSERT-sætningen var i konflikt med CHECK-begrænsningen... Sætningen er blevet afsluttet.
Lad os nu tilføje NULL:
INSERT INTO #temp VALUES (NULL)(1 række(r) påvirket)
Hvorfor bestod CHECK-begrænsningen NULL-værdien? Nå, grunden er, at der er nok NOT FALSE betingelse for at lave en optegnelse. Løsningen er eksplicit at definere en kolonne som IKKE NULL eller brug NULL i begrænsningen.
Datoformat
Meget ofte kan du have problemer med datatyper.
For eksempel skal du have den aktuelle dato. For at gøre dette kan du bruge GETDATE-funktionen:
VÆLG GETDATE()
Kopier derefter det returnerede resultat i en påkrævet forespørgsel, og slet tiden:
VÆLG *FRA sys.objectsWHERE create_date <'2016-11-14'
Er det korrekt?
Datoen er angivet af en strengkonstant:
INDSTIL SPROG EnglishINDSTIL DATOFORMAT DMYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05 -dec-2016'SELECT @d1, @d2, @d3, @d4
Alle værdier har en en-værdi fortolkning:
------------ ----------- ----------- ----------2016-12 -05 2016-05-12 2016-05-12 2016-12-05
Det vil ikke forårsage nogen problemer, før forespørgslen med denne forretningslogik udføres på en anden server, hvor indstillingerne kan variere:
INDSTIL DATOFORMAT MDYDECLARE @d1 DATETIME ='05/12/2016' , @d2 DATETIME ='2016/12/05' , @d3 DATETIME ='2016-12-05' , @d4 DATETIME ='05-dec. -2016'SELECT @d1, @d2, @d3, @d4
Disse muligheder kan dog føre til en forkert fortolkning af datoen:
------------ ----------- ----------- ----------2016-05 -12 2016-12-05 2016-12-05 2016-12-05
Desuden kan denne kode føre til både en synlig og latent fejl.
Overvej følgende eksempel. Vi skal indsætte data i en testtabel. På en testserver fungerer alt perfekt:
ERKLÆR @t-TABEL (en DATOTIME)INDSÆT I @t-VÆRDIER ('05/13/2016')
Alligevel vil denne forespørgsel på klientsiden have problemer, da vores serverindstillinger er forskellige:
ERKLÆR @t TABEL (en DATOTIME)INDSTIL DATOFORMAT DMYINDSÆT I @t-VÆRDIER ('05/13/2016') Besked 242, niveau 16, tilstand 3, linje 28. Konverteringen af en varchar-datatype til en datetime-datatype resulterede i en værdi uden for området.
Hvilket format skal vi bruge til at erklære datokonstanter? For at besvare dette spørgsmål skal du udføre denne forespørgsel:
INDSTIL DATOFORMAT YMDSET LANGUAGE EnglishDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112 'SELECT @d1, @d2, @d3, @d4GOSET LANGUAGE DeutschDECLARE @d1 DATETIME ='2016/01/12' , @d2 DATETIME ='2016-01-12' , @d3 DATETIME ='12-jan-2016' , @d4 DATETIME ='20160112'SELECT @d1, @d2, @d3, @d4
Fortolkningen af konstanter kan variere afhængigt af det installerede sprog:
------------ ----------- ----------- ----------2016-01 -12 2016-01-12 2016-01-12 2016-01-12 ------------------ ------------------ ----------- ----------2016-12-01 2016-12-01 2016-01-12 2016-01-12
Derfor er det bedre at bruge de to sidste muligheder. Jeg vil også gerne tilføje, at det ikke er en god idé at udtrykke datoen:
INDSTIL SPROG FrenchDECLARE @d DATETIME ='12-jan-2016'Besked 241, niveau 16, tilstand 1, linje 29. Konvertering af dato og/eller tid til at deltage i en chaîne de caractères.
Derfor, hvis du ønsker, at konstanter med datoerne skal fortolkes korrekt, skal du angive dem i følgende format ÅÅÅÅMMDD.
Derudover vil jeg gerne henlede din opmærksomhed på nogle datatypers adfærd:
SET LANGUAGE EnglishINDSTIL DATOFORMAT YMDDECLARE @d1 DATE ='2016-01-12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2GOSET LANGUAGE DeutschSET DATEFORMAT DMYDECLARE @d1 DATE ='2016-0 12' , @d2 DATETIME ='2016-01-12'SELECT @d1, @d2
I modsætning til DATETIME er DATE type fortolkes korrekt med forskellige indstillinger på en server:
---------- ----------2016-01-12 2016-01-12---------------- ------- ---2016-01-12 2016-12-01
Datofilter
For at komme videre vil vi overveje, hvordan man filtrerer data effektivt. Lad os tage udgangspunkt i dem DATETIME/DATE:
BRUG AdventureWorks2014GOUPDATE TOP(1) dbo.DatabaseLogSET PostTime ='20140716 12:12:12'
Nu vil vi forsøge at finde ud af, hvor mange rækker forespørgslen returnerer for en bestemt dag:
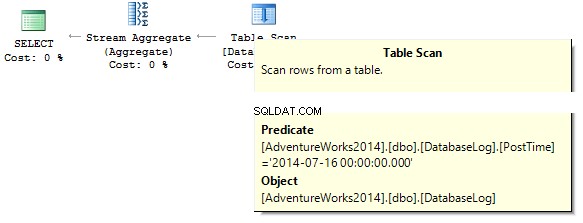
VÆLG COUNT_BIG(*) FROM dbo.DatabaseLogWHERE PostTime ='20140716'
Forespørgslen returnerer 0. Når du bygger en eksekveringsplan, forsøger SQL-serveren at caste en strengkonstant til datatypen for kolonnen, som vi skal filtrere fra:
Opret et indeks:
OPRET IKKE KLUSTERET INDEX IX_PostTime PÅ dbo.DatabaseLog (PostTime)
Der er korrekte og forkerte muligheder for at udlæse data. For eksempel skal du slette tidskolonnen:
VÆLG COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) ='20140716'VÆLG COUNT_BIG(*)FRA dbo.DatabaseLogWHERE CAST(PostTime AS DATE) ='20140716'
Eller vi skal angive et interval:
VÆLG COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime MELLEM '20140716' OG '20140716 23:59:59.997'VÆLG COUNT_BIG(*)FRA dbo.DatabaseLogWHERE PostTime>='161'4AND <7172'4AND <7201'4AND>
Med hensyn til optimering kan jeg sige, at disse to forespørgsler er de mest korrekte. Pointen er, at al konvertering og beregninger af indekskolonner, der filtreres fra, kan reducere ydeevnen drastisk og øge tiden for logiske aflæsninger:
Tabel 'DatabaseLog'. Scanning tæller 1, logisk læser 7, ... Tabel 'DatabaseLog'. Scanning tæller 1, logisk læser 2, ...
PostTime felt havde ikke været med i indekset før, og vi kunne ikke se nogen effektivitet i at bruge denne korrekte tilgang til filtrering. En anden ting er, når vi skal udlæse data for en måned:
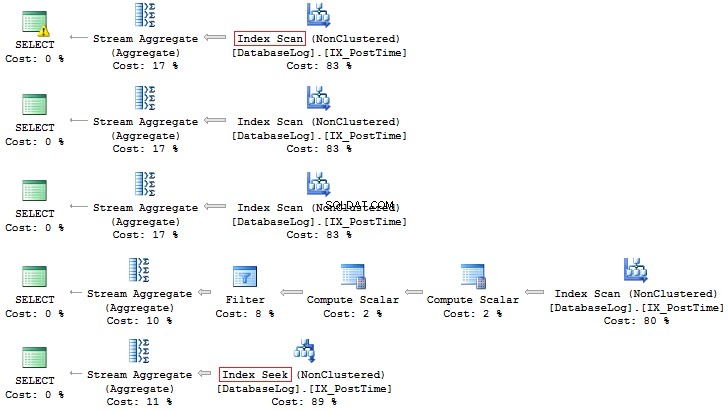
VÆLG COUNT_BIG(*)FROM dbo.DatabaseLogWHERE CONVERT(CHAR(8), PostTime, 112) LIKE '201407%'VÆLG COUNT_BIG(*)FRA dbo.DatabaseLogWHERE DATEPART(YEAR, PostTime) =DATEPART(MONTH, TH) PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE YEAR(PostTime) =2014 AND MONTH(PostTime) =7SELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE EOMONTH(PostTime) ='2014073BIGROM. PostTime>='20140701' OG PostTime <'20140801'
Igen er sidstnævnte mulighed mere at foretrække:
Derudover kan du altid oprette et indeks baseret på et beregnet felt:
IF COL_LENGTH('dbo.DatabaseLog', 'MonthLastDay') IS NOT NULL ALTER TABLE dbo.DatabaseLog DROP COLUMN MonthLastDayGOALTER TABLE dbo.DatabaseLog ADD MonthLastDay ASGOEOMONTH_TIMEDEXDAY(MostInDEXDay) dbo.
Sammenlignet med den tidligere forespørgsel kan forskellen i logiske aflæsninger være betydelig (hvis der er tale om store tabeller):
INDSTIL STATISTIK IO ONSELECT COUNT_BIG(*)FROM dbo.DatabaseLogWHERE PostTime>='20140701' OG PostTime <'20140801'VÆLG COUNT_BIG(*)FRA dbo.DatabaseLogWHERE MonthLastDay4SETIOGOFFDAG'72TIOgStiDaSTIOgStiDaStIOgStiDaStIOg'3140701' Scanning tæller 1, logisk læser 7, ... Tabel 'DatabaseLog'. Scanning tæller 1, logisk læser 3, ...
Beregning
Som det allerede er blevet diskuteret, reducerer enhver beregning på indekskolonner ydeevnen og øger logiktiden:
BRUG AdventureWorks2014GOSET STATISTICS IO ONSELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID * 2 =10000SELECT BusinessEntityIDFROM Person.PersonWHERE BusinessEntityID =2500 * 2SELECT BusinessEntityIDFROMHPersonWHERE BusinessEntityWIDERE 'EnerP0Tsontablet. Scanningstæller 1, logisk lyder 67, ...Tabel 'Person'. Scanning tæller 0, logisk læser 3, ...
Hvis vi ser på eksekveringsplanerne, så udfører SQL Server i den første IndexScan :
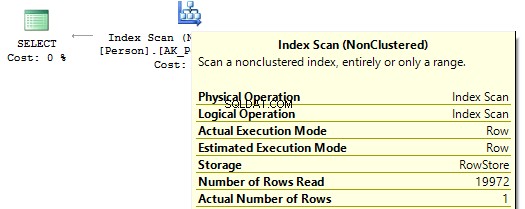
Så, når der ikke er nogen beregninger på indekskolonnerne, vil vi se IndexSeek :

Konverter implicit
Lad os se på disse to forespørgsler, der filtrerer efter den samme værdi:
BRUG AdventureWorks2014GOSELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber =30845SELECT BusinessEntityID, NationalIDNumberFROM HumanResources.EmployeeWHERE NationalIDNumber ='30845'
Udførelsesplanerne giver følgende oplysninger:
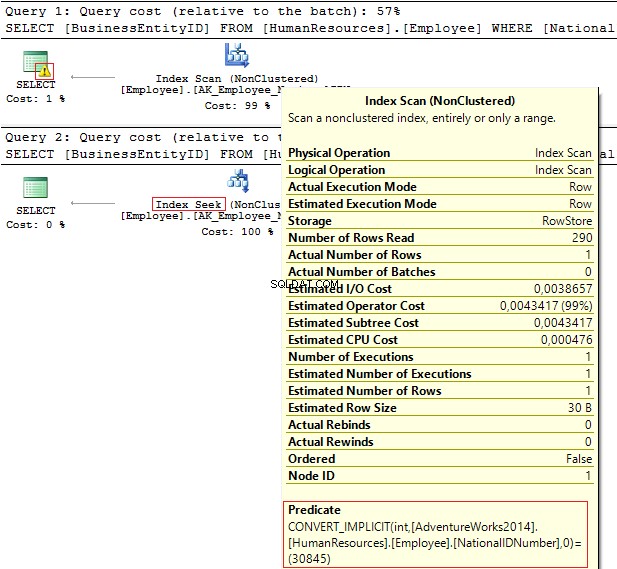
- Advarsel og IndexScan på den første plan
- IndexSeek – på den anden.
Tabel 'Medarbejder'. Scanning tæller 1, logisk lyder 4, ... Tabel 'Medarbejder'. Scanningsantal 0, logisk læser 2, ...
NationalIDNumber kolonnen har NVARCHAR(15) datatype. Konstanten vi bruger til at filtrere data fra er sat som INT hvilket fører os til en implicit datatypekonvertering. Til gengæld kan det forringe ydeevnen. Du kan overvåge det, når nogen ændrer datatypen i kolonnen, men forespørgslerne ændres ikke.
Det er vigtigt at forstå, at en implicit datatypekonvertering kan føre til fejl under kørsel. For eksempel, før feltet Postnummer var numerisk, viste det sig, at et postnummer kunne indeholde bogstaver. Datatypen blev således opdateret. Alligevel, hvis vi indsætter et alfabetisk postnummer, vil den gamle forespørgsel ikke længere virke:
SELECT AddressIDFROM Person.[Address]WHERE PostalCode =92700SELECT AddressIDFROM Person.[Address]WHERE PostalCode ='92700'Msg 245, Level 16, State 1, Line 16Konvertering mislykkedes ved konvertering af nvarchar-værdien 'K4B 1S2' int.
Et andet eksempel er, når du skal bruge EntityFramework på projektet, som som standard fortolker alle rækkefelter som Unicode:
SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber =N'AW00000009'SELECT CustomerID, AccountNumberFROM Sales.CustomerWHERE AccountNumber ='AW00000009'
Derfor genereres forkerte forespørgsler:

For at løse dette problem skal du sørge for, at datatyperne stemmer overens.
LIKE og undertrykt indeks
Faktisk betyder det ikke, at du har et dækkende indeks, at du vil bruge det effektivt.
Lad os tjekke det på dette særlige eksempel. Antag, at vi skal udskrive alle de rækker, der starter med...
BRUG AdventureWorks2014GOSET STATISTICS IO ONSELECT AddressLine1FROM Person.[Address]WHERE SUBSTRING(AddressLine1, 1, 3) ='100'VÆLG AdresseLine1FROM Person.[Adresse]WHERE LEFT(AddressLine1, 3'SELECT) ='10.Line Adresse]WHERE CAST(AddressLine1 AS CHAR(3)) ='100'VÆLG AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '100%'
Vi får følgende logiske aflæsninger og udførelsesplaner:
Tabel 'Adresse'. Scanningsantal 1, logisk læser 216, ...Tabel 'Adresse'. Scanningsantal 1, logisk læser 216, ...Tabel 'Adresse'. Scanningsantal 1, logisk læser 216, ...Tabel 'Adresse'. Scanning tæller 1, logisk læser 4, ...
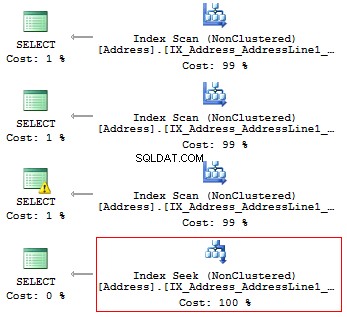
Hvis der er et indeks, bør det således ikke indeholde nogen beregninger eller konvertering af typer, funktioner osv.
Men hvad gør du, hvis du skal finde forekomsten af en understreng i en streng?
VÆLG AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'v
Vi vender tilbage til dette spørgsmål senere.
Unicode vs ANSI
Det er vigtigt at huske, at der er UNICODE og ANSI strenge. UNICODE-typen inkluderer NVARCHAR/NCHAR (2 bytes til et symbol). For at gemme ANSI strenge, er det muligt at bruge VARCHAR/CHAR (1 byte til 1 symbol). Der er også TEXT/NTEXT , men jeg anbefaler ikke at bruge dem, da de kan forringe ydeevnen.
Hvis du angiver en Unicode-konstant i en forespørgsel, er det nødvendigt at sætte N-symbolet foran den. For at kontrollere det skal du udføre følgende forespørgsel:
VÆLG '文本 ANSI' , N'文本 UNICODE'------- ------------?? ANSI 文本 UNICODE
Hvis N ikke går forud for konstanten, vil SQL Server forsøge at finde et passende symbol i ANSI-kodningen. Hvis den ikke kan finde, vil den vise et spørgsmålstegn.
SAMLER
Meget ofte, når en interviewer bliver interviewet til stillingen mellem-/senior DB-udvikler, stiller en interviewer ofte følgende spørgsmål:Vil denne forespørgsel returnere dataene?
DECLARE @a NCHAR(1) ='Ё' , @b NCHAR(1) ='Ф'VÆLG @a, @bWHERE @a =@b
Det kommer an på. For det første går N-symbolet ikke forud for en strengkonstant, og det vil derfor blive fortolket som ANSI. For det andet afhænger meget af den aktuelle COLLATE-værdi, som er et sæt regler, når du vælger og sammenligner strengdata.
BRUG [master]GOIF DB_ID('test') IS NOT NULL BEGIN ÆNDRING DATABASE-test SÆT SINGLE_USER MED ROLLBACK STRAKS DROP DATABASE-testENDGOCREATE DATABASE-test COLLATE Latin1_General_100_CI_ASGOUSE ) ='Ф'VÆLG @a, @bWHERE @a =@b Denne COLLATE-sætning returnerer spørgsmålstegn, da deres symboler er ens:
---- ----? ?
Hvis vi ændrer COLLATE-sætningen til en anden sætning:
ALTER DATABASE test COLLATE Cyrillic_General_100_CI_AS
I dette tilfælde returnerer forespørgslen intet, da kyrilliske tegn vil blive fortolket korrekt.
Derfor, hvis en strengkonstant optager UNICODE, så er det nødvendigt at sætte N forud for en strengkonstant. Alligevel vil jeg ikke anbefale at indstille det overalt af de årsager, vi har diskuteret ovenfor.
Et andet spørgsmål, der skal stilles i interviewet, refererer til sammenligning af rækker.
Overvej følgende eksempel:
ERKLÆR @a VARCHAR(10) ='TEKST' , @b VARCHAR(10) ='tekst'VÆLG IIF(@a =@b, 'SAND', 'FALSK')
Er disse rækker lige store? For at kontrollere dette skal vi udtrykkeligt angive COLLATE:
DECLARE @a VARCHAR(10) ='TEKST' , @b VARCHAR(10) ='tekst'SELECT IIF(@a COLLATE Latin1_General_CS_AS =@b COLLATE Latin1_General_CS_AS, 'TRUE', 'FALSE')
Da der er de store og små bogstaver (CS) og store og små bogstaver (CI) COLLATE, når man sammenligner og vælger rækker, kan vi ikke med sikkerhed sige, om de er ens. Derudover er der forskellige COLLATEs både på en testserver og en klientside.
Der er et tilfælde, hvor COLLATEs af en målbase og tempdb stemmer ikke overens.
Opret en database med COLLATE:
BRUG [master]GOIF DB_ID('test') IS NOT NULL BEGIN ÆNDRING DATABASE-test SÆT SINGLE_USER MED ROLLBACK STRAKS DROP DATABASE-testENDGOCREATE DATABASE-test COLLATE Albanian_100_CS_ASGOUSE testGOCREATE CHERTTO(1t)c VALUE CHERTTO(1t) ')GOIF OBJECT_ID('tempdb.dbo.#t1') IS NOT NULL DROP TABLE #t1IF OBJECT_ID('tempdb.dbo.#t2') IS NOT NULL DROP TABLE #t2IF OBJECT_ID('tempdb.dbo.#t3') ER IKKE NULL DROP TABEL #t3GOCREATE TABLE #t1 (c CHAR(1))INSERT INTO #t1 VALUES ('a')CREATE TABEL #t2 (c CHAR(1) COLLATE database_default)INSERT INTO #t2 VALUES ('a') SELECT c =CAST('a' AS CHAR(1))INTO #t3DECLARE @t TABLE (c VARCHAR(100))INSERT INTO @t VALUES ('a')SELECT 'tempdb', DATABASEPROPERTYEX('tempdb', 'collation' ')UNION ALLSELECT 'test', DATABASEPROPERTYEX(DB_NAME(), 'collation')UNION ALLSELECT 't', SQL_VARIANT_PROPERTY(c, 'collation') FRA tUNION ALLSELECT '#t1', SQL_VARIANT_PROPERTY(c, 'collation') FRA # t1UNION ALLSELECT '#t2', SQL_VARIANT_PROPERTY(c, 'collation') FRA # t2UNION ALLSELECT '#t3', SQL_VARIANT_PROPERTY(c, 'collation') FRA #t3UNION ALLSELECT '@t', SQL_VARIANT_PROPERTY(c, 'collation') FRA @t Når du opretter en tabel, arver den COLLATE fra en database. Den eneste forskel for den første midlertidige tabel, for hvilken vi bestemmer en struktur eksplicit uden COLLATE, er, at den arver COLLATE fra tempdb database.
------ --------------------------tempdb Cyrillic_General_CI_AStest Albanian_100_CS_ASt Albanian_100_CS_AS#t1 Cyrillic_General_CI_AS#t2 Albanian_100_CS_AS#t3 Albanian_100_CS_AS@t Albansk_100_CS_AS
Jeg vil beskrive tilfældet, hvor COLLATEs ikke stemmer overens i det bestemte eksempel med #t1.
For eksempel er data ikke filtreret korrekt ud, da COLLATE muligvis ikke tager højde for en sag:
VÆLG *FROM #t1WHERE c ='A'
Alternativt kan vi have en konflikt om at forbinde tabeller med forskellige COLLATEs:
VÆLG *FRA #t1JOIN t ON [#t1].c =t.c
Alt ser ud til at fungere perfekt på en testserver, hvorimod vi på en klientserver får en fejl:
Besked 468, niveau 16, tilstand 9, linje 93Kan ikke løse kollationskonflikten mellem "Albanian_100_CS_AS" og "Cyrillic_General_CI_AS" i lig med operationen.
For at omgå det, er vi nødt til at sætte hacks overalt:
VÆLG *FRA #t1JOIN t ON [#t1].c =t.c COLLATE database_default
BINÆR SÆTNING
Nu vil vi finde ud af, hvordan du bruger COLLATE til din fordel.
Overvej eksemplet med forekomsten af en understreng i en streng:
VÆLG AddressLine1FROM Person.[Address]WHERE AddressLine1 LIKE '%100%'
Det er muligt at optimere denne forespørgsel og reducere dens udførelsestid.
Først skal vi generere en stor tabel:
BRUG [master]GOIF DB_ID('test') IS NOT NULL BEGIN ÆNDRING DATABASE-test SÆT SINGLE_USER MED ROLLBACK STRAKS DROP DATABASE-testENDGOCREATE DATABASE-test COLLATE Latin1_General_100_CS_ASGOALTER DATABASE-test =MBYFIZEGO-test =MBYFIZE'(MODUSNAVN NSI-FIZE-test, 4) DATABASE-test ÆNDRE FIL (NAVN =N'test_log', STØRRELSE =64MB)GOUSE testGOCREATE TABLE t ( ansi VARCHAR(100) NOT NULL, unicod NVARCHAR(100) NOT NULL)GO;WITH E1(N) AS ( SELECT * FROM ( VÆRDIER (1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ) t(N) ), E2(N ) AS (VÆLG 1 FRA E1 a, E1 b), E4(N) AS (VÆLG 1 FRA E2 a, E2 b), E8(N) AS (VÆLG 1 FRA E4 a, E4 b)INSERT INTO tSELECT v, vFROM ( SELECT TOP(50000) v =REPLACE(CAST(NEWID() AS VARCHAR(36)) + CAST(NEWID() AS VARCHAR(36)), '-', '') FRA E8) t Opret beregnede kolonner med binære COLLATEs og indekser:
ALTER TABLE t TILFØJ ansi_bin AS UPPER(ansi) COLLATE Latin1_General_100_Bin2ALTER TABLE t TILFØJ unicod_bin AS UPPER(unicod) COLLATE Latin1_General_100_BIN2CREATE NONCLUSTERED INDEX nEXLUSTERED INDEX nEXLUSTERED INDEX (EXLUSTERED INDEX) INGENICOD ansi_bin)OPRET IKKE-KLUSTERET INDEX unicod_bin ON t (unicod_bin)
Udfør filtreringsprocessen:
INDSTIL STATISTIK TID, IO ONSELECT COUNT_BIG(*)FROM tWHERE ansi LIKE '%AB%'SELECT COUNT_BIG(*)FROM tWHERE unicod LIKE '%AB%'SELECT COUNT_BIG(*)FROM TWHERE ansi_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SELECT COUNT_BIG(*)FROM tWHERE unicod_bin LIKE '%AB%' --COLLATE Latin1_General_100_BIN2SET STATISTICS TID, IO OFF
Som du kan se, returnerer denne forespørgsel følgende resultat:
SQL-server-udførelsestider:CPU-tid =350 ms, forløbet tid =354 ms. SQL-serverudførelsestider:CPU-tid =335 ms, forløbet tid =355 ms. SQL-serverudførelsestider:CPU-tid =16 ms, forløbet tid =18 ms.SQL-serverudførelsestider:CPU-tid =17 ms, forløbet tid =18 ms.
Pointen er, at filter baseret på den binære sammenligning tager mindre tid. Således, hvis du har brug for at filtrere forekomsten af strenge ofte og hurtigt, så er det muligt at gemme data med COLLATE, der slutter med BIN. Det skal dog bemærkes, at alle binære COLLATEs er store og små bogstaver.
Kodestil
En kodningsstil er strengt individuel. Alligevel skal denne kode simpelthen vedligeholdes af andre udviklere og matche visse regler.
Opret en separat database og en tabel inde i:
BRUG [master]GOIF DB_ID('test') IS NOT NULL START ÆNDRING DATABASE-test SÆT SINGLE_USER MED ROLLBACK STRAKS DROP DATABASE-testENDGOCREATE DATABASE-test COLLATE Latin1_General_CI_ASGOUSE testGOCREATE TABLE-dploye-ansat.
Skriv derefter forespørgslen:
vælg medarbejder-id fra medarbejder
Skift nu COLLATE til en vilkårlig forskel mellem store og små bogstaver:
ALTER DATABASE test COLLATE Latin1_General_CS_AI
Prøv derefter at udføre forespørgslen igen:
Besked 208, niveau 16, tilstand 1, linje 19. Ugyldigt objektnavn 'medarbejder'.
En optimering bruger regler for den aktuelle COLLATE i bindingstrinnet, når den tjekker for tabeller, kolonner og andre objekter, ligesom den sammenligner hvert objekt i syntakstræet med et reelt objekt i et systemkatalog.
Hvis du vil generere forespørgsler manuelt, skal du altid bruge det korrekte store og små bogstaver i objektnavne.
Hvad angår variabler, arves COLLATEs fra masterdatabasen. Derfor skal du også bruge den korrekte sag for at arbejde med dem:
SELECT DATABASEPROPERTYEX('master', 'collation')DECLARE @EmpID INT =1SELECT @empid
I dette tilfælde vil du ikke få en fejlmeddelelse:
-----------------------Kyrillisk_General_CI_AS-----1
Alligevel kan der forekomme en sagsfejl på en anden server:
--------------------------Latin1_General_CS_ASMsg 137, niveau 15, tilstand 2, linje 4 Skal erklære den skalarvariable "@empid".
[var]char
Som du ved, er der faste (CHAR , NCHAR ) og variabel (VARCHAR , NVARCHAR ) datatyper:
DECLARE @a CHAR(20) ='tekst' , @b VARCHAR(20) ='tekst'VÆLG LEN(@a) , LEN(@b) , DATALENGTH(@a) , DATALENGTH(@b) , '"' + @a + '"' , '"' + @b + '"'VÆLG [a =b] =IIF(@a =@b, 'TRUE', 'FALSE'), [b =a] =IIF(@b =@a, 'SAND', 'FALSK') , [a LIKE b] =IIF(@a LIKE @b, 'SAND', 'FALSK') , [b LIKE a] =IIF(@ b LIKE @a, 'TRUE', 'FALSE')
Hvis en række har en fast længde, f.eks. 20 symboler, men du kun har skrevet 4 symboler, vil SQL Server som standard tilføje 16 tomme felter til højre:
--- --- ---- ---- ---------------------------- ----------- -----------4 4 20 4 "tekst" "tekst"
In addition, it is important to understand that when comparing rows with =, blanks on the right are not taken into account:
a =b b =a a LIKE b b LIKE a----- ----- -------- --------TRUE TRUE TRUE FALSE
As for the LIKE operator, blanks will be always inserted.
SELECT 1WHERE 'a ' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a ' -- !!!SELECT 1WHERE 'a' LIKE 'a'SELECT 1WHERE 'a' LIKE 'a%'
Data length
It is always necessary to specify type length.
Consider the following example:
DECLARE @a DECIMAL , @b VARCHAR(10) ='0.1' , @c SQL_VARIANTSELECT @a =@b , @c =@aSELECT @a , @c , SQL_VARIANT_PROPERTY(@c,'BaseType') , SQL_VARIANT_PROPERTY(@c,'Precision') , SQL_VARIANT_PROPERTY(@c,'Scale')
As you can see, the type length was not specified explicitly. Thus, the query returned an integer instead of a decimal value:
---- ---- ---------- ----- -----0 0 decimal 18 0
As for rows, if you do not specify a row length explicitly, then its length will contain only 1 symbol:
----- ------------------------------------------ ---- ---- ---- ----40 123456789_123456789_123456789_123456789_ 1 1 30 30
In addition, if you do not need to specify a length for CAST/CONVERT, then only 30 symbols will be used.
ISNULL vs COALESCE
There are two functions:ISNULL and COALESCE. On the one hand, everything seems to be simple. If the first operator is NULL, then it will return the second or the next operator, if we talk about COALESCE. On the other hand, there is a difference – what will these functions return?
DECLARE @a CHAR(1) =NULLSELECT ISNULL(@a, 'NULL'), COALESCE(@a, 'NULL')DECLARE @i INT =NULLSELECT ISNULL(@i, 7.1), COALESCE(@i, 7.1)
The answer is not obvious, as the ISNULL function converts to the smallest type of two operands, whereas COALESCE converts to the largest type.
---- ----N NULL---- ----7 7.1
As for performance, ISNULL will process a query faster, COALESCE is split into the CASE WHEN operator.
Math
Math seems to be a trivial thing in SQL Server.
SELECT 1 / 3SELECT 1.0 / 3
However, it is not. Everything depends on the fact what data is used in a query. If it is an integer, then it returns the integer result.
-----------0-----------0.333333
Also, let’s consider this particular example:
SELECT COUNT(*) , COUNT(1) , COUNT(val) , COUNT(DISTINCT val) , SUM(val) , SUM(DISTINCT val)FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)SELECT AVG(val) , SUM(val) / COUNT(val) , AVG(val * 1.) , AVG(CAST(val AS FLOAT))FROM ( VALUES (1), (2), (2), (NULL), (NULL)) t (val)
This query COUNT(*)/COUNT(1) will return the total amount of rows. COUNT on the column will return the amount of non-NULL rows. If we add DISTINCT, then it will return the amount of non-NULL unique values.
The AVG operation is divided into SUM and COUNT. Thus, when calculating an average value, NULL is not applicable.
UNION vs UNION ALL
When the data is not overridden, then it is better to use UNION ALL to improve performance. In order to avoid replication, you may use UNION.
Still, if there is no replication, it is preferable to use UNION ALL:
SELECT [object_id]FROM sys.system_objectsUNIONSELECT [object_id]FROM sys.objectsSELECT [object_id]FROM sys.system_objectsUNION ALLSELECT [object_id]FROM sys.objects
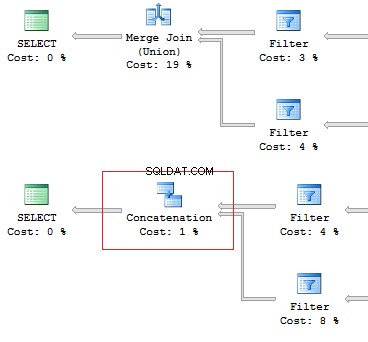
Also, I would like to point out the difference of these operators:the UNION operator is executed in a parallel way, the UNION ALL operator – in a sequential way.
Assume, we need to retrieve 1 row on the following conditions:
DECLARE @AddressLine NVARCHAR(60)SET @AddressLine ='4775 Kentucky Dr.'SELECT TOP(1) AddressIDFROM Person.[Address]WHERE AddressLine1 =@AddressLine OR AddressLine2 =@AddressLine
As we have OR in the statement, we will receive IndexScan:
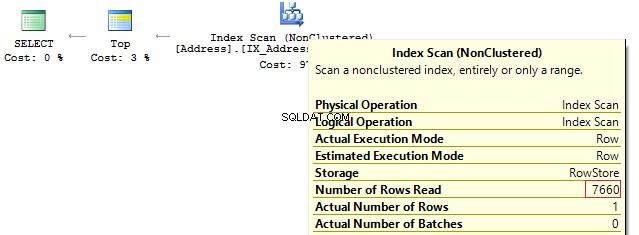
Table 'Address'. Scan count 1, logical reads 90, ...
Now, we will re-write the query using UNION ALL:
SELECT TOP(1) AddressIDFROM ( SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine1 =@AddressLine UNION ALL SELECT TOP(1) AddressID FROM Person.[Address] WHERE AddressLine2 =@AddressLine) t
When the first subquery had been executed, it returned 1 row. Thus, we have received the required result, and SQL Server stopped looking for, using the second subquery:
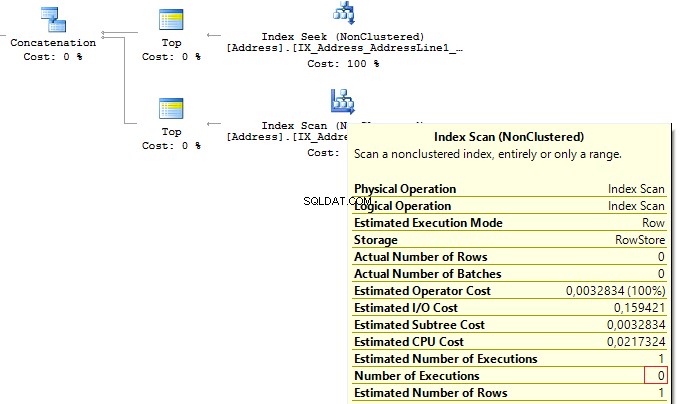
Table 'Worktable'. Scan count 0, logical reads 0, ...Table 'Address'. Scan count 1, logical reads 3, ...
Re-read
Very often, I faced the situation when the data can be retrieved with one JOIN. In addition, a lot of subqueries are created in this query:
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT e.BusinessEntityID , ( SELECT p.LastName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID ) , ( SELECT p.FirstName FROM Person.Person p WHERE e.BusinessEntityID =p.BusinessEntityID )FROM HumanResources.Employee eSELECT e.BusinessEntityID , p.LastName , p.FirstNameFROM HumanResources.Employee eJOIN Person.Person p ON e.BusinessEntityID =p.BusinessEntityID
The fewer there are unnecessary table lookups, the fewer logical readings we have:
Table 'Person'. Scan count 0, logical reads 1776, ...Table 'Employee'. Scan count 1, logical reads 2, ...Table 'Person'. Scan count 0, logical reads 888, ...Table 'Employee'. Scan count 1, logical reads 2, ...
SubQuery
The previous example works only if there is a one-to-one connection between tables.
Assume tables Person.Person and Sales.SalesPersonQuotaHistory were directly connected. Thus, one employee had only one record for a share size.
USE AdventureWorks2014GOSET STATISTICS IO ONSELECT p.BusinessEntityID , ( SELECT s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID )FROM Person.Person p
However, as settings on the client server may differ, this query may lead to the following error:
Msg 512, Level 16, State 1, Line 6Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=,>,>=or when the subquery is used as an expression.
It is possible to solve such issues by adding TOP(1) and ORDER BY. Using the TOP operation makes an optimizer force using IndexSeek. The same refers to using OUTER/CROSS APPLY with TOP:
SELECT p.BusinessEntityID , ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC )FROM Person.Person pSELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pOUTER APPLY ( SELECT TOP(1) s.SalesQuota FROM Sales.SalesPersonQuotaHistory s WHERE s.BusinessEntityID =p.BusinessEntityID ORDER BY s.QuotaDate DESC) t
When executing these queries, we will get the same issue – multiple IndexSeek operators:
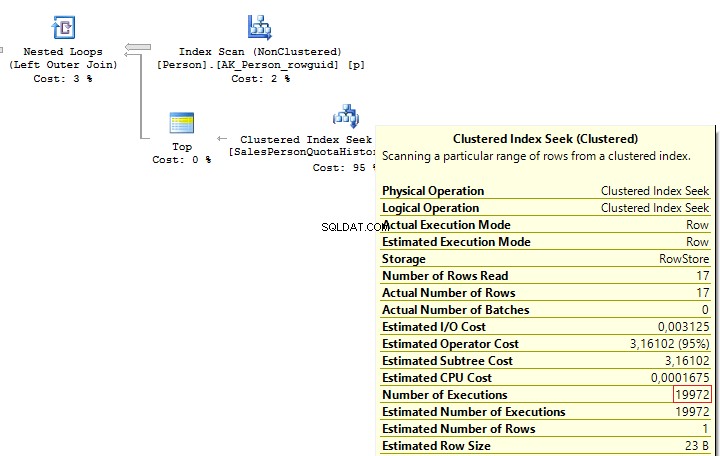
Table 'SalesPersonQuotaHistory'. Scan count 19972, logical reads 39944, ...Table 'Person'. Scan count 1, logical reads 67, ...
Re-write this query with a window function:
SELECT p.BusinessEntityID , t.SalesQuotaFROM Person.Person pLEFT JOIN ( SELECT s.BusinessEntityID , s.SalesQuota , RowNum =ROW_NUMBER() OVER (PARTITION BY s.BusinessEntityID ORDER BY s.QuotaDate DESC) FROM Sales.SalesPersonQuotaHistory s) t ON p.BusinessEntityID =t.BusinessEntityID AND t.RowNum =1
We get the following result:
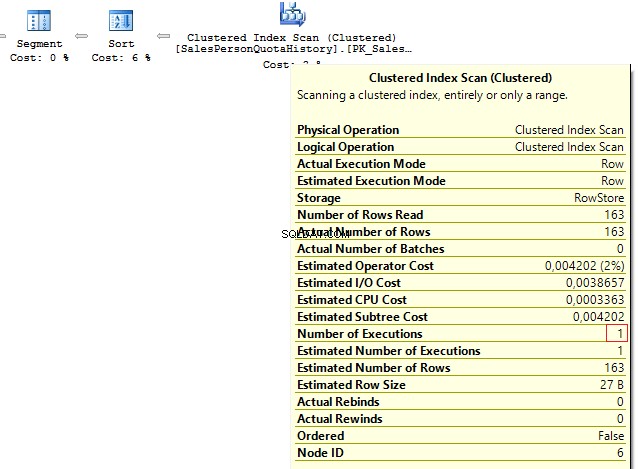
Table 'Person'. Scan count 1, logical reads 67, ...Table 'SalesPersonQuotaHistory'. Scan count 1, logical reads 4, ...
CASE WHEN
Since this operator is used very often, I would like to specify its features. Regardless, how we wrote the CASE WHEN operator:
USE AdventureWorks2014GOSELECT BusinessEntityID , Gender , Gender =CASE Gender WHEN 'M' THEN 'Male' WHEN 'F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
SQL Server will decompose the statement to the following:
SELECT BusinessEntityID , Gender , Gender =CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='F' THEN 'Female' ELSE 'Unknown' ENDFROM HumanResources.Employee
Thus, this will lead to the main issue:each condition will be executed in a sequential order until one of them returns TRUE or ELSE.
Consider this issue on a particular example. To do this, we will create a scalar-valued function which will return the right part of a postal code:
IF OBJECT_ID('dbo.GetMailUrl') IS NOT NULL DROP FUNCTION dbo.GetMailUrlGOCREATE FUNCTION dbo.GetMailUrl( @Email NVARCHAR(50))RETURNS NVARCHAR(50)AS BEGIN RETURN SUBSTRING(@Email, CHARINDEX('@', @Email) + 1, LEN(@Email))END
Then, configure SQL Profiler to build SQL events:StmtStarting / SP:StmtCompleted (if you want to do this with XEvents :sp_statement_starting / sp_statement_completed ).
Execute the query:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) --WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
The function will be executed for 10 times. Now, delete a comment from the condition:
SELECT TOP(10) EmailAddressID , EmailAddress , CASE dbo.GetMailUrl(EmailAddress) WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM Person.EmailAddress
In this case, the function will be executed for 20 times. The thing is that it is not necessary for a statement to be a must function in CASE. It may be a complicated calculation. As it is possible to decompose CASE, it may lead to multiple calculations of the same operators.
You may avoid it by using subqueries:
SELECT EmailAddressID , EmailAddress , CASE MailUrl WHEN 'microsoft.com' THEN 'Microsoft' WHEN 'adventure-works.com' THEN 'AdventureWorks' ENDFROM ( SELECT TOP(10) EmailAddressID , EmailAddress , MailUrl =dbo.GetMailUrl(EmailAddress) FROM Person.EmailAddress) t
In this case, the function will be executed 10 times.
In addition, we need to avoid replication in the CASE operator:
SELECT DISTINCT CASE WHEN Gender ='M' THEN 'Male' WHEN Gender ='M' THEN '...' WHEN Gender ='M' THEN '......' WHEN Gender ='F' THEN 'Female' WHEN Gender ='F' THEN '...' ELSE 'Unknown' ENDFROM HumanResources.Employee
Though statements in CASE are executed in a sequential order, in some cases, SQL Server may execute this operator with aggregate functions:
DECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE 1/0 ENDGODECLARE @i INT =1SELECT CASE WHEN @i =1 THEN 1 ELSE MIN(1/0) END
Scalar func
It is not recommended to use scalar functions in T-SQL queries.
Consider the following example:
USE AdventureWorks2014GOUPDATE TOP(1) Person.[Address]SET AddressLine2 =AddressLine1GOIF OBJECT_ID('dbo.isEqual') IS NOT NULL DROP FUNCTION dbo.isEqualGOCREATE FUNCTION dbo.isEqual( @val1 NVARCHAR(100), @val2 NVARCHAR(100))RETURNS BITAS BEGIN RETURN CASE WHEN (@val1 IS NULL AND @val2 IS NULL) OR @val1 =@val2 THEN 1 ELSE 0 ENDEND
The queries return the identical data:
SET STATISTICS TIME ONSELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE dbo.IsEqual(AddressLine1, AddressLine2) =1SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE (AddressLine1 IS NULL AND AddressLine2 IS NULL) OR AddressLine1 =AddressLine2SELECT AddressID, AddressLine1, AddressLine2FROM Person.[Address]WHERE AddressLine1 =ISNULL(AddressLine2, '')SET STATISTICS TIME OFF
However, as each call of the scalar function is a resource-intensive process, we can monitor this difference:
SQL Server Execution Times:CPU time =63 ms, elapsed time =57 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.SQL Server Execution Times:CPU time =0 ms, elapsed time =1 ms.
In addition, when using a scalar function, it is not possible for SQL Server to build parallel execution plans, which may lead to poor performance in a huge volume of data.
Sometimes scalar functions may have a positive effect. For example, when we have SCHEMABINDING in the statement:
IF OBJECT_ID('dbo.GetPI') IS NOT NULL DROP FUNCTION dbo.GetPIGOCREATE FUNCTION dbo.GetPI ()RETURNS FLOATWITH SCHEMABINDINGAS BEGIN RETURN PI()ENDGOSELECT dbo.GetPI()FROM Sales.Currency
In this case, the function will be considered as deterministic and executed 1 time.
VIEWs
Here I would like to talk about features of views.
Create a test table and view on its base:
IF OBJECT_ID('dbo.tbl', 'U') IS NOT NULL DROP TABLE dbo.tblGOCREATE TABLE dbo.tbl (a INT, b INT)GOINSERT INTO dbo.tbl VALUES (0, 1)GOIF OBJECT_ID('dbo.vw_tbl', 'V') IS NOT NULL DROP VIEW dbo.vw_tblGOCREATE VIEW dbo.vw_tblAS SELECT * FROM dbo.tblGOSELECT * FROM dbo.vw_tbl
As you can see, we get the correct result:
a b----------- -----------0 1
Now, add a new column in the table and retrieve data from the view:
ALTER TABLE dbo.tbl ADD c INT NOT NULL DEFAULT 2GOSELECT * FROM dbo.vw_tbl
We receive the same result:
a b----------- -----------0 1
Thus, we need either to explicitly set columns or recompile a script object to get the correct result:
EXEC sys.sp_refreshview @viewname =N'dbo.vw_tbl'GOSELECT * FROM dbo.vw_tbl
Result:
a b c----------- ----------- -----------0 1 2
When you directly refer to the table, this issue will not take place.
Now, I would like to discuss a situation when all the data is combined in one query as well as wrapped in one view. I will do it on this particular example:
ALTER VIEW HumanResources.vEmployeeAS SELECT e.BusinessEntityID , p.Title , p.FirstName , p.MiddleName , p.LastName , p.Suffix , e.JobTitle , pp.PhoneNumber , pnt.[Name] AS PhoneNumberType , ea.EmailAddress , p.EmailPromotion , a.AddressLine1 , a.AddressLine2 , a.City , sp.[Name] AS StateProvinceName , a.PostalCode , cr.[Name] AS CountryRegionName , p.AdditionalContactInfo FROM HumanResources.Employee e JOIN Person.Person p ON p.BusinessEntityID =e.BusinessEntityID JOIN Person.BusinessEntityAddress bea ON bea.BusinessEntityID =e.BusinessEntityID JOIN Person.[Address] a ON a.AddressID =bea.AddressID JOIN Person.StateProvince sp ON sp.StateProvinceID =a.StateProvinceID JOIN Person.CountryRegion cr ON cr.CountryRegionCode =sp.CountryRegionCode LEFT JOIN Person.PersonPhone pp ON pp.BusinessEntityID =p.BusinessEntityID LEFT JOIN Person.PhoneNumberType pnt ON pp.PhoneNumberTypeID =pnt.PhoneNumberTypeID LEFT JOIN Person.EmailAddress ea ON p.BusinessEntityID =ea.BusinessEntityID
What should you do if you need to get only a part of information? For example, you need to get Fist Name and Last Name of employees:
SELECT BusinessEntityID , FirstName , LastNameFROM HumanResources.vEmployeeSELECT p.BusinessEntityID , p.FirstName , p.LastNameFROM Person.Person pWHERE p.BusinessEntityID IN ( SELECT e.BusinessEntityID FROM HumanResources.Employee e )
Look at the execution plan in the case of using a view:
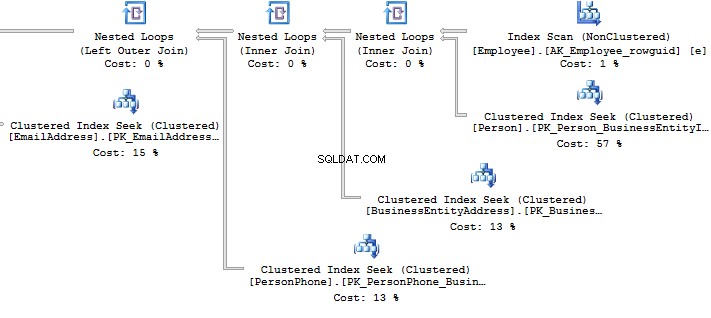
Table 'EmailAddress'. Scan count 290, logical reads 640, ...Table 'PersonPhone'. Scan count 290, logical reads 636, ...Table 'BusinessEntityAddress'. Scan count 290, logical reads 636, ...Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
Now, we will compare it with the query we have written manually:
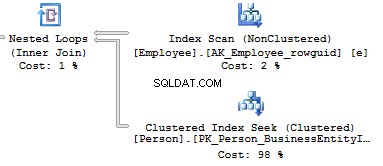
Table 'Person'. Scan count 0, logical reads 897, ...Table 'Employee'. Scan count 1, logical reads 2, ...
When creating an execution plan, an optimizer in SQL Server drops unused connections.
However, sometimes when there is no valid foreign key between tables, it is not possible to check whether a connection will impact the sample result. It may also be applied to the situation when tables are connecteCURSORs
I recommend that you do not use cursors for iteration data modification.
You can see the following code with a cursor:
DECLARE @BusinessEntityID INTDECLARE cur CURSOR FOR SELECT BusinessEntityID FROM HumanResources.EmployeeOPEN curFETCH NEXT FROM cur INTO @BusinessEntityIDWHILE @@FETCH_STATUS =0 BEGIN UPDATE HumanResources.Employee SET VacationHours =0 WHERE BusinessEntityID =@BusinessEntityID FETCH NEXT FROM cur INTO @BusinessEntityIDENDCLOSE curDEALLOCATE cur
Though, it is possible to re-write the code by dropping the cursor:
UPDATE HumanResources.EmployeeSET VacationHours =0WHERE VacationHours <> 0
In this case, it will improve performance and decrease the time to execute a query.
STRING_CONCAT
To concatenate rows, the STRING_CONCAT could be used. However, as there is no such a function in the SQL Server, we will do this by assigning a value to the variable.
To do this, create a test table:
IF OBJECT_ID('tempdb.dbo.#t') IS NOT NULL DROP TABLE #tGOCREATE TABLE #t (i CHAR(1))INSERT INTO #tVALUES ('1'), ('2'), ('3')
Then, assign values to the variable:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tSELECT @txt--------123
Everything seems to be working fine. However, MS hints that this way is not documented and you may get this result:
DECLARE @txt VARCHAR(50) =''SELECT @txt +=iFROM #tORDER BY LEN(i)SELECT @txt--------3
Alternatively, it is a good idea to use XML as a workaround:
SELECT [text()] =iFROM #tFOR XML PATH('')--------123
It should be noted that it is necessary to concatenate rows per each data, rather than into a single set of data:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('.', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'------------------------ ------------------------------------ScrapReason ScrapReasonID, Name, ModifiedDateShift ShiftID, Name, StartTime, EndTime
In addition, it is recommended that you should avoid using the XML method for parsing as it is a high-runner process:
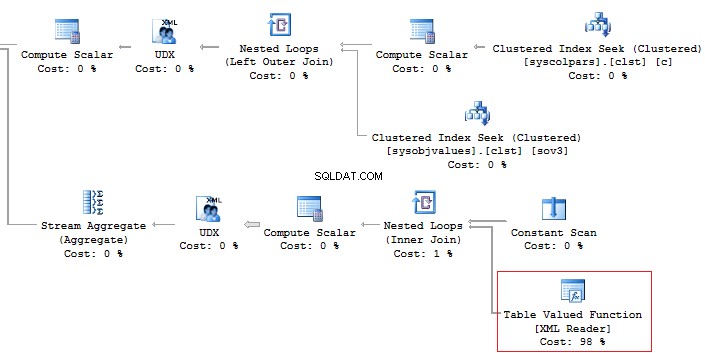
Alternatively, it is possible to do this less time-consuming:
SELECT [name], STUFF(( SELECT ', ' + c.[name] FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH(''), TYPE).value('(./text())[1]', 'NVARCHAR(MAX)'), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
But, it does not change the main point.
Now, execute the query without using the value method:
SELECT t.name , STUFF(( SELECT ', ' + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
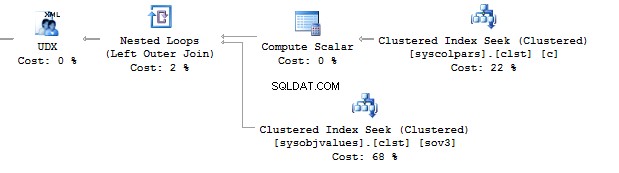
This option would work perfect. However, it may fail. If you want to check it, execute the following query:
SELECT t.name , STUFF(( SELECT ', ' + CHAR(13) + c.name FROM sys.columns c WHERE c.[object_id] =t.[object_id] FOR XML PATH('')), 1, 2, '')FROM sys.objects tWHERE t.[type] ='U'
If there are special symbols in rows, such as tabulation, line break, etc., then we will get incorrect results.
Thus, if there are no special symbols, you can create a query without the value method, otherwise, use value(‘(./text())[1]’… .
SQL Injection
Assume we have a code:
DECLARE @param VARCHAR(MAX)SET @param =1DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =' + @paramPRINT @SQLEXEC (@SQL)
Create the query:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1
If we add any additional value to the property,
SET @param ='1; select ''hack'''
Then our query will be changed to the following construction:
SELECT TOP(5) name FROM sys.objects WHERE schema_id =1; select 'hack'
This is called SQL injection when it is possible to execute a query with any additional information.
If the query is formed with String.Format (or manually) in the code, then you may get SQL injection:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( string.Format("SELECT TOP(5) name FROM sys.objects WHERE schema_id ={0}", value), conn); using (SqlDataReader reader =command.ExecuteReader()) { while (reader.Read()) {} }}
When you use sp_executesql and properties as shown in this code:
DECLARE @param VARCHAR(MAX)SET @param ='1; select ''hack'''DECLARE @SQL NVARCHAR(MAX)SET @SQL ='SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id'PRINT @SQLEXEC sys.sp_executesql @SQL , N'@schema_id INT' , @schema_id =@param
It is not possible to add some information to the property.
In the code, you may see the following interpretation of the code:
using (SqlConnection conn =new SqlConnection()){ conn.ConnectionString =@"Server=.;Database=AdventureWorks2014;Trusted_Connection=true"; conn.Open(); SqlCommand command =new SqlCommand( "SELECT TOP(5) name FROM sys.objects WHERE schema_id =@schema_id", conn); command.Parameters.Add(new SqlParameter("schema_id", value)); ...} Summary
Working with databases is not as simple as it may seem. There are a lot of points you should keep in mind when writing T-SQL queries.
Of course, it is not the whole list of pitfalls when working with SQL Server. Still, I hope that this article will be useful for newbies.