[ Del 1 | Del 2 | Del 3 ]
For nylig bad en på arbejde om mere plads til et hurtigt voksende bord. På det tidspunkt havde den 3,75 milliarder rækker, præsenteret på 143 millioner sider og optog ~1,14TB. Selvfølgelig kan vi altid kaste mere disk på et bord, men jeg ville se, om vi kunne skalere dette mere effektivt end den nuværende lineære trend. Lyder som et godt job til kompression, ikke? Men jeg ville også prøve nogle andre løsninger, herunder columnstore – som folk er overraskende tilbageholdende med at prøve. Jeg er ingen Niko, men jeg ville gøre en indsats for at se, hvad det kunne gøre for os her.
Bemærk, at jeg ikke fokuserer på rapportering af arbejdsbyrde eller anden læseforespørgselsydeevne på nuværende tidspunkt – jeg vil blot se, hvilken indvirkning jeg kan have på disse datas lager (og hukommelse).
Her er den originale tabel. Jeg har ændret tabel- og kolonnenavne for at beskytte de uskyldige, men alt andet er relativt nøjagtigt.
CREATE TABLE dbo.tblOriginal
(
OID bigint IDENTITY(1,1) NOT NULL PRIMARY KEY, -- there are gaps!
IN1 int NOT NULL,
IN2 int NOT NULL,
VC1 varchar(3) NULL,
BI1 bigint NULL,
IN3 int NULL,
VC2 varchar(128) NOT NULL,
VC3 varchar(128) NOT NULL,
VC4 varchar(128) NULL,
NM1 numeric(24,12) NULL,
NM2 numeric(24,12) NULL,
NM3 numeric(24,12) NULL,
BI2 bigint NULL,
IN4 int NULL,
BI3 bigint NULL,
NM4 numeric(24,12) NULL,
IN5 int NULL,
NM5 numeric(24,12) NULL,
DT1 date NULL,
VC5 varchar(128) NULL,
BI4 bigint NULL,
BI5 bigint NULL,
BI6 bigint NULL,
BT1 bit NOT NULL,
NV1 nvarchar(512) NULL,
VB1 AS (HASHBYTES('MD5',VC2+VC3)),
IN6 int NULL,
IN7 int NULL,
IN8 int NULL
);
Der er nogle andre små ting derinde, der er bredere, end de burde være, og/eller som rækkekomprimering kan rydde op, såsom de numeric(24,12) og bigint kolonner, der kan være for tidligt overdimensionerede, men jeg vil ikke gå tilbage til applikationsteamet og finde ud af, om der er små effektivitetsgevinster der, og jeg vil springe rækkekomprimering over for denne øvelse og fokusere på side- og columnstore-komprimering.
Dette er en kopi af dataene på en inaktiv server (8 kerner, 64 GB RAM), med masser af diskplads (godt over 6 TB). Så lad os først tilføje et par filgrupper, en til standard clustered columnstore og en til en partitioneret version af tabellen (hvor alle undtagen den seneste partition vil blive komprimeret med COLUMNSTORE_ARCHIVE , da alle de ældre data nu er "læsebeskyttet og sjældent"):
ALTER DATABASE OCopy ADD FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILEGROUP FG_CCI_PARTITIONED;
Og så nogle filer til disse filgrupper (én fil pr. kerne, pæn og ensartet størrelse på 256 GB):
ALTER DATABASE OCopy ADD FILE (name = N'CCI_1', size = 250000, filename = 'K:\Data\o_cci_1.mdf') TO FILEGROUP FG_CCI; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_8', size = 250000, filename = 'K:\Data\o_cci_8.mdf') TO FILEGROUP FG_CCI; ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_1', size = 250000, filename = 'K:\Data\o_p_1.mdf') TO FILEGROUP FG_CCI_PARTITIONED; -- ... 6 more ... ALTER DATABASE OCopy ADD FILE (name = N'CCI_P_8', size = 250000, filename = 'K:\Data\o_p_8.mdf') TO FILEGROUP FG_CCI_PARTITIONED;
På denne særlige hardware (YMMV!) tog dette omkring 10 sekunder pr. fil og gav følgende:
For at generere partitionerne opdelte jeg naivt dataene "jævnt" - eller det troede jeg. Jeg tog lige de 3,75 milliarder rækker og delte op i noget, som jeg troede ville være overskueligt:38 partitioner med 100 millioner rækker i de første 37 partitioner, og resten i den sidste. (Husk, dette er kun del 1! Der er en iboende antagelse her om lige fordeling af værdier i kildetabellen, og også omkring hvad der er optimalt for rækkegruppepopulation i destinationstabellen.) Oprettelse af partitionsskemaet og funktionen for dette er som følger:
CREATE PARTITION FUNCTION PF_OID([bigint]) AS RANGE LEFT FOR VALUES (100000000, 200000000, /* ... 33 more ... */ , 3600000000, 3700000000); CREATE PARTITION SCHEME PS_OID AS PARTITION PF_OID ALL TO (FG_CCI_PARTITIONED);
Jeg bruger RANGE LEFT fordi, som Cathrine Wilhelmsen fortsætter med at minde mig om, betyder det, at grænseværdien er en del af skillevæggen til venstre for den. Med andre ord, de værdier, jeg angiver, er de maksimale værdier i hver partition (med datoer vil du normalt have RANGE RIGHT ).
Jeg oprettede derefter to kopier af tabellen, en på hver filgruppe. Den første havde et standard clustered columnstore indeks, de eneste forskelle var OID kolonne er ikke en IDENTITY og den beregnede kolonne er kun en varbinary(8000) :
CREATE TABLE dbo.tblCCI ( OID bigint NOT NULL, -- ... other columns ... ) ON FG_CCI; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_IX ON dbo.tblCCI;
Den anden blev bygget på partitionsskemaet, så først havde brug for en navngivet PK, som derefter skulle erstattes af et klynget kolonnelagerindeks (selvom Brent Ozar viser i dette korte indlæg, at der er noget uintuitivt syntaks, der vil opnå dette i færre trin ):
CREATE TABLE dbo.tblCCI_Partitioned ( OID bigint NOT NULL, -- ... other columns ..., CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID) ON PS_OID (OID) ); GO ALTER TABLE dbo.tblCCI_Partitioned DROP CONSTRAINT PK_CCI_Part; GO CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part ON dbo.tblCCI_Partitioned ON PS_OID (OID);
Derefter, for at sætte arkivkomprimering på alle undtagen den sidste partition, kørte jeg følgende:
ALTER TABLE dbo.tblCCI_Part
REBUILD PARTITION = ALL WITH
(
DATA_COMPRESSION = COLUMNSTORE ON PARTITIONS (38),
DATA_COMPRESSION = COLUMNSTORE_ARCHIVE ON PARTITIONS (1 TO 37)
); Nu var jeg klar til at udfylde disse tabeller med data, måle den tid, det tog og den resulterende størrelse og sammenligne. Jeg ændrede et nyttigt batching-script fra Andy Mallon og indsatte rækkerne i begge tabeller sekventielt med en batchstørrelse på 10 millioner rækker. Der er meget mere i det end dette i det rigtige script (inklusive opdatering af en køtabel med fremskridt), men dybest set:
DECLARE @BatchSize int = 10000000, @MaxID bigint, @LastID bigint = 0;
SELECT @MaxID = MAX(OID) FROM dbo.tblOriginal;
WHILE @LastID < @MaxID
BEGIN
INSERT dbo.tblCCI
(
-- all columns except the computed column
)
SELECT -- all columns except the computed column
FROM dbo.tblOriginal AS o
WHERE o.CostID >= @LastID
AND o.CostID < @LastID + @BatchSize;
SET @LastID += @BatchSize;
END Efter at jeg havde udfyldt begge kolonnelagertabeller fra den originale (ukomprimerede) kilde, genopbyggede jeg disse partitioner igen for at rydde op i rækkegrupper og ordbogsrod. Til sidst anvendte jeg sidekomprimering på plads på kildetabellen. Her var timingen og kompressionsresultaterne for hver type:
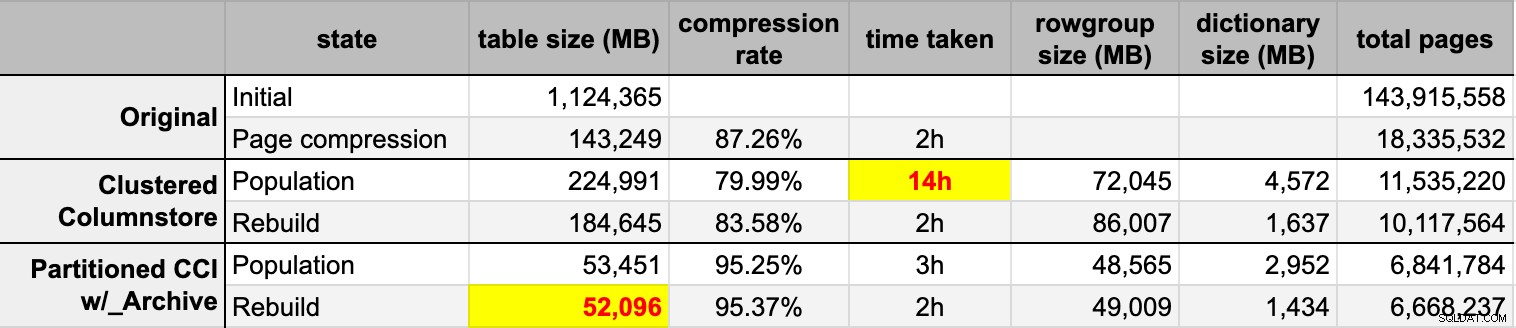
Jeg er både imponeret og skuffet. Imponeret, fordi disse data komprimeres rigtigt godt – at skrue ned på lagringsfodaftrykket til 5 % af den originale 1 TB er noget forbløffende. Skuffet fordi:
- Jeg lavede disse datafiler på måde for stor.
- Jeg forstår ikke, hvad der skete med den 14 timers indledende columnstore-komprimering:
- Jeg observerede ikke noget hukommelses- eller logtryk.
- Der var ingen filvæksthændelser.
- Desværre tænkte jeg ikke på at spore ventetider. Nej, jeg vil ikke prøve det igen. :-)
- Sidekomprimering klarede sig bedre end almindelig columnstore-komprimering – måske på grund af dataene.
- Genopbygning af columnstore-arkivpartitionerne brugte meget CPU-tid til næsten ingen forstærkning.
I kommende indlæg, og efter at have gennemgået mine noter fra en fantastisk columnstore-præsentation af Joe Obbish på PASS Summit (som jeg ville linke direkte til, hvis bare PASS vidste, hvordan man bruger brugergrænsefladen), vil jeg tale lidt om de ændringer, jeg vil foretag serverkonfigurationen og mit populationsscript for at se, om jeg kan få bedre ydeevne fra columnstore-populationen.
[ Del 1 | Del 2 | Del 3 ]