Introduktion
Opnå minimal logning ved hjælp af INSERT...SELECT ind i en tom clustered index target er ikke helt så simpelt som beskrevet i Data Performance Loading Guide .
Dette indlæg giver nye detaljer om kravene til minimal logning når indsættelsesmålet er et tomt traditionelt klynget indeks. (Ordet "traditionel" der udelukker columnstore og hukommelsesoptimeret (‘Hekaton’) klyngede tabeller). For de betingelser, der gælder, når måltabellen er en bunke, se den forrige artikel i denne serie.
Oversigt over grupperede tabeller
Vejledning til ydeevne for dataindlæsning indeholder en oversigt på højt niveau af de betingelser, der kræves for minimal logning i grupperede tabeller:
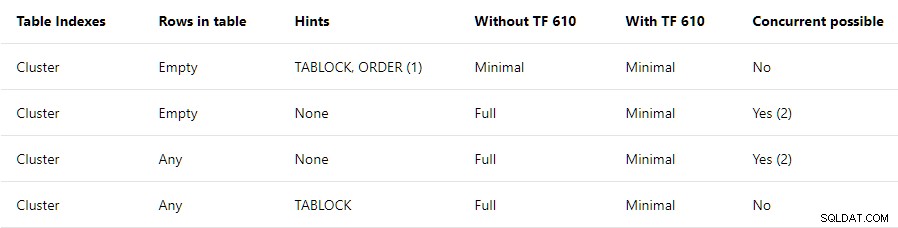
Dette indlæg vedrører kun den øverste række . Det står at TABLOCK og ORDER tip er påkrævet, med en note, der siger:
Hvis du bruger BULK INSERT, skal ordretipset bruges.
Tøm mål med bordlås
Opsummeringen øverste række antyder, at alle indsættelser til et tomt klynget indeks bliver minimalt logget så længe TABLOCK og ORDER hints er angivet. TABLOCK tip er påkrævet for at aktivere RowSetBulk facilitet, som bruges til bulklaster i bunkebord. En ORDER tip er påkrævet for at sikre, at rækker ankommer til Clustered Index Insert planoperatør i målindeks nøglerækkefølge . Uden denne garanti kan SQL Server tilføje indeksrækker, der ikke er sorteret korrekt, hvilket ikke ville være godt.
I modsætning til andre masseindlæsningsmetoder er det ikke muligt for at angive den nødvendige ORDER tip om en INSERT...SELECT udmelding. Dette tip er ikke det samme som ved at bruge en ORDER BY klausul på INSERT...SELECT udmelding. En ORDER BY klausul på en INSERT garanterer kun måden enhver identitet værdier er tildelt, ikke rækkeindsættelsesrækkefølge.
For INSERT...SELECT , SQL Server træffer sin egen beslutning om det skal sikres, at rækker præsenteres for Clustered Index Insert operatør i nøglerækkefølge eller ej. Resultatet af denne vurdering er synligt i udførelsesplaner gennem DMLRequestSort egenskaben for Indsæt operatør. DMLRequestSort ejendom skal indstilles til sand for INSERT...SELECT ind i et indeks for at minimalt logges . Når den er indstillet til falsk , minimal logning kan ikke forekomme.
Med DMLRequestSort indstillet til sand er den eneste acceptable garanti af indsæt inputbestilling til SQL Server. Man kan inspicere udførelsesplanen og forudsige at rækker bør/vil/skal ankomme i klynget indeksrækkefølge, men uden de specifikke interne garantier leveret af DMLRequestSort , den vurdering tæller ikke noget.
Når DMLRequestSort er sandt , SQL Server kan indføre en eksplicit Sortering operatør i udførelsesplanen. Hvis det internt kan garantere bestilling på andre måder, Sortér kan udelades. Hvis både sorterings- og ikke-sorteringsalternativer er tilgængelige, vil optimeringsværktøjet lave en omkostningsbaseret valg. Omkostningsanalysen tager ikke højde for minimal logning direkte; det er drevet af de forventede fordele ved sekventiel I/O og undgåelse af sideopdeling.
DMLRequestSort-betingelser
Begge følgende test skal bestå, for at SQL Server kan vælge at indstille DMLRequestSort til sand ved indsættelse i et tomt klynget indeks med tabellåsning angivet:
- Et estimat på mere end 250 rækker på inputsiden af Clustered Index Insert operatør; og
- En estimeret datastørrelse på mere end 2 sider . Den estimerede datastørrelse er ikke et heltal, så et resultat på 2.001 sider ville opfylde denne betingelse.
(Dette kan minde dig om betingelserne for heap minimal logning , men den nødvendige estimerede datastørrelsen her er to sider i stedet for otte.)
Beregning af datastørrelse
Den estimerede datastørrelse beregning her er underlagt de samme særheder beskrevet i den forrige artikel for heaps, bortset fra at 8-byte RID er ikke til stede.
For SQL Server 2012 og tidligere betyder det 5 ekstra bytes række er inkluderet i datastørrelsesberegningen:En byte for en intern bit flag og fire bytes til uniquifier (bruges i beregningen selv for unikke indekser, som ikke gemmer en uniquifier ).
Til SQL Server 2014 og nyere, uniquifier er korrekt udeladt for unik indekser, men den en ekstra byte for den interne bit flag bibeholdes.
Demo
Følgende script skal køres på en udviklings-SQL Server-instans i en ny testdatabase indstillet til at bruge SIMPLE eller BULK_LOGGED gendannelsesmodel.
Demoen indlæser 268 rækker i en helt ny klynget tabel ved hjælp af INSERT...SELECT med TABLOCK , og rapporter om de genererede transaktionslogposter.
IF OBJECT_ID(N'dbo.Test', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Test;
END;
GO
CREATE TABLE dbo.Test
(
id integer NOT NULL IDENTITY
CONSTRAINT [PK dbo.Test (id)]
PRIMARY KEY,
c1 integer NOT NULL,
padding char(45) NOT NULL
DEFAULT ''
);
GO
-- Clear the log
CHECKPOINT;
GO
-- Insert rows
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (268)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV;
GO
-- Show log entries
SELECT
FD.Operation,
FD.Context,
FD.[Log Record Length],
FD.[Log Reserve],
FD.AllocUnitName,
FD.[Transaction Name],
FD.[Lock Information],
FD.[Description]
FROM sys.fn_dblog(NULL, NULL) AS FD;
GO
-- Count the number of fully-logged rows
SELECT
[Fully Logged Rows] = COUNT_BIG(*)
FROM sys.fn_dblog(NULL, NULL) AS FD
WHERE
FD.Operation = N'LOP_INSERT_ROWS'
AND FD.Context = N'LCX_CLUSTERED'
AND FD.AllocUnitName = N'dbo.Test.PK dbo.Test (id)';
(Hvis du kører scriptet på SQL Server 2012 eller tidligere, skal du ændre TOP klausul i scriptet fra 268 til 252, af årsager, der vil blive forklaret om et øjeblik.)
Outputtet viser, at alle indsatte rækker var fuldt logget på trods af den tomme målgruppetabel og TABLOCK tip:
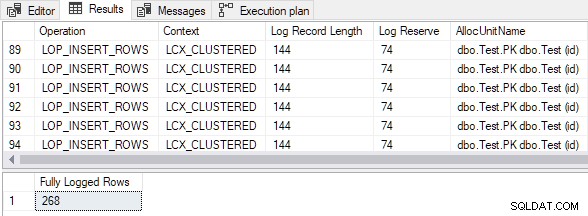
Beregnet størrelse på indsæt data
Udførelsesplanegenskaberne for Clustered Index Insert operatør viser, at DMLRequestSort er indstillet til falsk . Dette skyldes, at selvom det anslåede antal rækker, der skal indsættes, er mere end 250 (opfylder det første krav), er beregnet datastørrelse ikke overstige to 8KB sider.
Beregningsdetaljerne (for SQL Server 2014 og frem) er som følger:
- Samlet fast længde kolonnestørrelse =54 bytes :
- Typ id 104
bit=1 byte (intern). - Typ id 56
heltal=4 bytes (idkolonne). - Typ id 56
heltal=4 bytes (c1kolonne). - Typ id 175
char(45)=45 bytes (udfyldningkolonne).
- Typ id 104
- Nul bitmap =3 bytes .
- Rækkeoverskrift overhead =4 bytes .
- Beregnet rækkestørrelse =54 + 3 + 4 =61 bytes .
- Beregnet datastørrelse =61 bytes * 268 rækker =16.348 bytes .
- Beregnede datasider =16.384 / 8192 =1,99560546875 .
Den beregnede rækkestørrelse (61 bytes) adskiller sig fra den sande rækkelagerstørrelse (60 bytes) med den ekstra byte af interne metadata, der er til stede i indsættelsesstrømmen. Beregningen tager heller ikke højde for de 96 bytes, der bruges på hver side af sidehovedet, eller andre ting som rækkeversionering overhead. Den samme beregning på SQL Server 2012 tilføjer yderligere 4 bytes pr. række for uniquiifier (som ikke er til stede i unikke indekser som tidligere nævnt). De ekstra bytes betyder, at færre rækker forventes at passe på hver side:
- Beregnet rækkestørrelse =61 + 4 =65 bytes .
- Beregnet datastørrelse =65 bytes * 252 rækker =16.380 bytes
- Beregnede datasider =16.380 / 8192 =1,99951171875 .
Ændring af TOP klausul fra 268 rækker til 269 (eller fra 252 til 253 for 2012) gør den forventede datastørrelsesberegning kun vippe over minimumstærsklen på 2 sider:
- SQL Server 2014
- 61 bytes * 269 rækker =16.409 bytes.
- 16.409 / 8192 =2,0030517578125 sider.
- SQL Server 2012
- 65 bytes * 253 rækker =16.445 bytes.
- 16.445 / 8192 =2,0074462890625 sider.
Med den anden betingelse nu også opfyldt, DMLRequestSort er indstillet til true , og minimal logning er opnået, som vist i outputtet nedenfor:
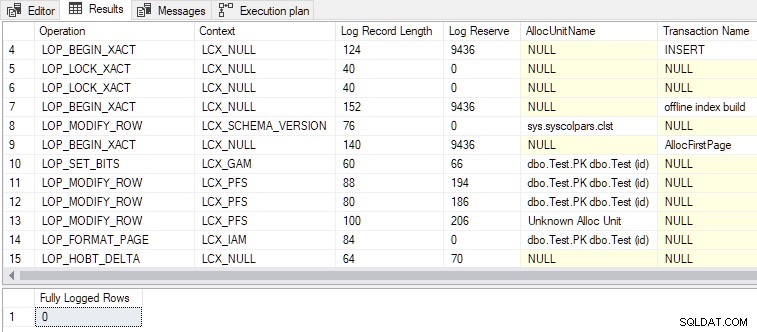
Nogle andre interessepunkter:
- Der genereres i alt 79 logposter sammenlignet med 328 for den fuldt loggede version. Færre logposter er det forventede resultat af minimal logning.
LOP_BEGIN_XACT poster i minimalt logget records reserverer en forholdsvis stor mængde logplads (9436 bytes hver). - Et af transaktionsnavnene, der er angivet i logposterne er "offline indeks build" . Selvom vi ikke bad om at oprette et indeks som sådan, er masseindlæsning af rækker i et tomt indeks stort set den samme operation.
- Den fuldt loggede Insert tager en eksklusiv lås på tabelniveau (
Tab-X), mens den minimalt loggede insert tager skemaændring (Sch-M) ligesom en 'rigtig' offline indeksbygning gør. - Masseindlæsning af en tom klynget tabel ved hjælp af
INSERT...SELECTmedTABLOCKogDMRequestSortindstillet til sand brugerRowsetBulkmekanisme, ligesom den minimalt loggede heap loads gjorde i den forrige artikel.
Kardinalitetsestimater
Pas på lave kardinalitetsestimater ved Clustered Index Insert operatør. Hvis en af tærsklerne kræves for at indstille DMLRequestSort til sand ikke nås på grund af unøjagtig kardinalitetsestimat, vil indsættelsen blive fuldstændig logget , uanset det faktiske antal rækker og den samlede datastørrelse, der er fundet på udførelsestidspunktet.
For eksempel at ændre TOP klausul i demoscriptet for at bruge en variabel resulterer i en fast kardinalitet gæt på 100 rækker, hvilket er under minimum 251 rækker:
-- Insert rows
DECLARE @NumRows bigint = 269;
INSERT dbo.Test WITH (TABLOCK)
(c1)
SELECT TOP (@NumRows)
CHECKSUM(NEWID())
FROM master.dbo.spt_values AS SV; Planlæg cache
DMLRequestSort egenskaben gemmes som en del af den cachelagrede plan. Når en cachelagret plan genbruges , værdien af DMLRequestSort er ikke genberegnet på udførelsestidspunktet, medmindre der sker en rekompilering. Bemærk, at genkompilering ikke forekommer for TRIVIAL planer baseret på ændringer i statistik eller tabelkardinalitet.
En måde at undgå uventet adfærd på grund af caching er at bruge en OPTION (RECOMPILE) antydning. Dette vil sikre den passende indstilling for DMLRequestSort genberegnes på bekostning af en kompilering på hver udførelse.
Sporingsflag
Det er muligt at tvinge DMLRequestSort skal indstilles til true ved at indstille udokumenteret og ikke understøttet spor flag 2332, som jeg skrev i Optimering af T-SQL-forespørgsler, der ændrer data. Desværre gør dette ikke påvirke minimal logning berettigelse til tomme klyngetabeller — indsættelsen skal stadig estimeres til mere end 250 rækker og 2 sider. Dette sporingsflag påvirker anden minimal-logning scenarier, som er dækket i den sidste del af denne serie.
Oversigt
Masseindlæsning af en tom klyngede indeks ved hjælp af INSERT...SELECT genbruger RowsetBulk mekanisme, der bruges til at samle bunkeborde. Dette kræver bordlåsning (normalt opnået med en TABLOCK). tip) og en ORDER antydning. Der er ingen måde at tilføje en ORDER tip til en INSERT...SELECT udmelding. Som en konsekvens opnås minimal logning ind i en tom klynget tabel kræver, at DMLRequestSort egenskaben for Clustered Index Insert operator er indstillet til true . Dette garanti til SQL Server, der rækker præsenteret for Indsæt operatøren ankommer i målindeksnøglerækkefølge. Effekten er den samme som ved brug af ORDER hint tilgængeligt for andre masseindsættelsesmetoder som BULK INSERT og bcp .
For at DMLRequestSort skal indstilles til true , der skal være:
- Mere end 250 rækker estimeret skal indsættes; og
- En estimeret indsæt datastørrelse på mere end to sider .
Den estimerede indsæt beregning af datastørrelse ikke matche resultatet af at gange udførelsesplanens estimerede antal rækker og estimeret rækkestørrelse egenskaber ved input til Indsæt operatør. Den interne beregning (forkert) inkluderer en eller flere interne kolonner i indsættelsesstrømmen, som ikke er fastholdt i det endelige indeks. Den interne beregning tager heller ikke højde for sidehoveder eller andre omkostninger som rækkeversionering.
Når du tester eller fejlretter minimal logning problemer, pas på med lave vurderinger af kardinalitet, og husk at indstillingen af DMLRequestSort cachelagres som en del af udførelsesplanen.
Den sidste del af denne serie beskriver de betingelser, der kræves for at opnå minimal logning uden at bruge RowsetBulk mekanisme. Disse svarer direkte til de nye faciliteter, der er tilføjet under sporingsflag 610 til SQL Server 2008, og derefter ændret til at være slået til som standard fra SQL Server 2016 og fremefter.