
Gæsteforfatter:Andy Mallon (@AMtwo)
Nej, seriøst. Hvad er en DTU?
Når du implementerer en applikation, er et af de første spørgsmål, der dukker op, "Hvad vil det koste?" De fleste af os har været igennem denne form for øvelse for at dimensionere en SQL Server-installation på et tidspunkt, men hvad nu hvis du implementerer til skyen? Med Azure IaaS-implementeringer er ikke meget ændret – du bygger stadig en server baseret på CPU-antal, en vis mængde hukommelse og konfigurerer lagerplads til at give dig nok IOPS til din arbejdsbyrde. Men når du springer til PaaS, er Azure SQL Database størrelse med forskellige service-tiers, hvor ydeevnen måles i DTU'er. Hvad pokker er en DTU?
Jeg ved, hvad en BTU er. Måske står DTU for Database Thermal Unit? Er det mængden af processorkraft, der skal til for at hæve temperaturen i datacentret med én grad? I stedet for at gætte, lad os tjekke dokumentationen og se, hvad Microsoft har at sige:
En [Database Transaction Unit] er et blandet mål for CPU, hukommelse og data I/O og transaktionslog I/O i et forhold, der bestemmes af en OLTP-benchmark-arbejdsbelastning, der er designet til at være typisk for OLTP-arbejdsbelastninger i den virkelige verden. Fordobling af DTU'erne ved at øge ydelsesniveauet for en database svarer til en fordobling af det ressourcesæt, der er tilgængeligt for den pågældende database.OK, det var mit andet gæt – men hvad er det "blandede mål"? Hvordan kan jeg oversætte, hvad jeg ved om størrelsen på en server til størrelsen på en Azure SQL-database? Desværre er der ikke nogen ligetil måde at oversætte "2 CPU-kerner og 4 GB hukommelse" til en DTU-måling.
Er der ikke en DTU Lommeregner?
Ja! Microsoft giver os en DTU-beregner til estimering det korrekte serviceniveau i Azure SQL Database. For at bruge det skal du downloade og køre et PowerShell-script (sql-perfmon.ps1) på serveren, mens du kører en arbejdsbelastning i SQL Server. Scriptet udsender en CSV, som indeholder fire perfmon-tællere:(1) total % processortid, (2) total disklæsning/sekund, (3) total diskskrivning pr. sekund og (4) total logbytes skyllet/sekund. Dette CSV-output uploades derefter til DTU-beregneren, som estimerer, hvilket serviceniveau der bedst opfylder dine behov. De eneste data, som DTU-beregneren tager ud over CSV'en, er antallet af CPU-kerner på den server, der har genereret filen. DTU Lommeregneren er stadig lidt af en sort boks – det er ikke nemt at kortlægge, hvad vi kender fra vores lokale databaser til Azure.
Jeg vil gerne påpege, at definitionen af en DTU er, at det er "et blandet mål for CPU, hukommelse , og data I/O og transaktionslog I/O..." Ingen af de perfmon-tællere, der bruges af DTU-beregneren, tager højde for hukommelse, men det er tydeligt angivet i definitionen som værende en del af beregningen. Dette er ikke nødvendigvis en problem, men det er bevis på, at DTU Lommeregneren ikke bliver perfekt.
Jeg uploader noget syntetisk belastning i DTU Lommeregneren, og ser om jeg kan finde ud af hvordan den sorte boks virker. Faktisk fabrikerer jeg CSV'erne fuldstændigt, så jeg fuldstændig kan kontrollere de perfmonnumre, som vi indlæser i DTU-beregneren. Lad os gå gennem én metrik ad gangen. For hver metrik uploader vi 25 minutters (1500 sekunder – jeg kan godt lide runde tal) af fabrikerede data og ser, hvordan disse perfmondata konverteres til DTU'er.
CPU
Jeg vil oprette en CSV, der simulerer en 16-kerne server, der langsomt øger CPU-udnyttelsen, indtil den er fastgjort til 100 %. Da jeg skal simulere ramp-up på en 16-kerne server, vil jeg oprette min CSV for at stige 1/16 ad gangen – i det væsentlige simulerer en kerne maxing out, derefter en anden maxing out, derefter den tredje, osv. Hele tiden vil CSV'en vise nul læsninger, skrivninger og log skylninger. En server ville faktisk aldrig generere en arbejdsbyrde som denne – men det er pointen. Jeg isolerer CPU-udnyttelsen fuldstændigt, så jeg kan se, hvordan CPU'en påvirker DTU'er.
Jeg opretter en CSV-fil, der har en række pr. sekund, og hvert 94. sekund øger jeg tælleren for Total % processortid med ~6%. De andre tre tællere vil i alle tilfælde være nul. Nu uploader jeg denne fil til DTU-beregneren (og beder DTU-beregneren om at overveje 16 kerner), og her er outputtet:
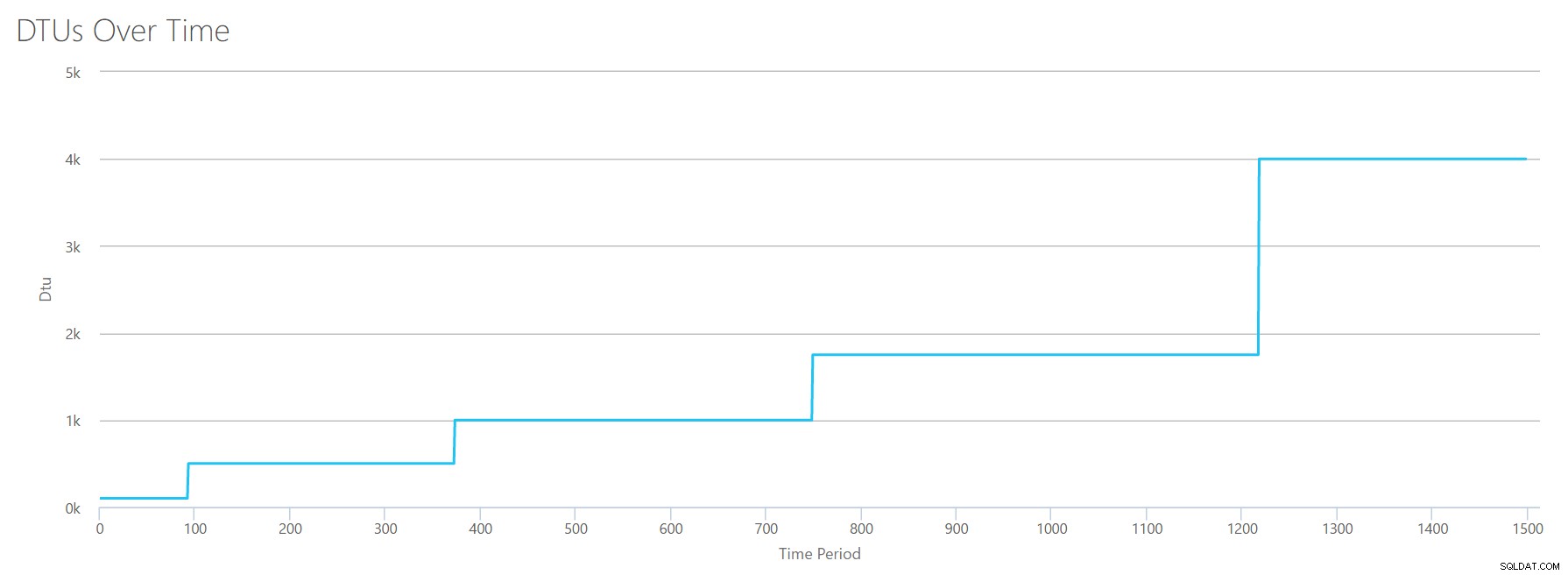
Vente? Har jeg ikke øget CPU-udnyttelsen i 16 lige trin? Denne DTU-graf viser kun fem trin. Jeg må have rodet. Nej – min CSV havde 16 lige trin, men det oversættes (tilsyneladende) ikke ligeligt til DTU'er. I hvert fald ikke ifølge DTU Lommeregneren. Baseret på vores maxed-out CPU-test ville vores CPU-til-DTU-til-Service Tier-mapping se sådan ud:
| Antal kerner | DTU'er | Serviceniveau |
|---|---|---|
| 1 | 100 | Standard – S3 |
| 2-4 | 500 | Premium – P4 |
| 5-8 | 1000 | Premium – P6 |
| 9-13 | 1750 | Premium – P11 |
| 14-16 | 4000 | Premium – P15 |
At se på disse data fortæller os et par ting:
- Én CPU-kerne, 100 % brugt svarer til 100 DTU'er.
- DTU'er stiger en smule lineært efterhånden som CPU'en øges, men tilsyneladende i anfald og ryk.
- Basis- og Standard-serviceniveauerne er lig med mindre end en enkelt CPU-kerne.
- Enhver multi-core-server vil oversætte til en vis størrelse inden for Premium-serviceniveauet.
Læser
Denne gang vil jeg bruge den samme metode. Jeg vil generere en CSV med stigende tal for læse/sekund-tælleren, med de andre perfmon-tællere på nul. Jeg vil langsomt øge antallet over tid. Lad os denne gang stige op i bidder af 2000, hvert 100. sekund, indtil vi rammer 30000. Dette giver os den samme 25-minutters samlede tid – men denne gang har jeg 15 trin i stedet for 16. (Jeg kan godt lide runde tal).
Når vi uploader denne CSV til DTU-beregneren, giver den os denne DTU-graf:
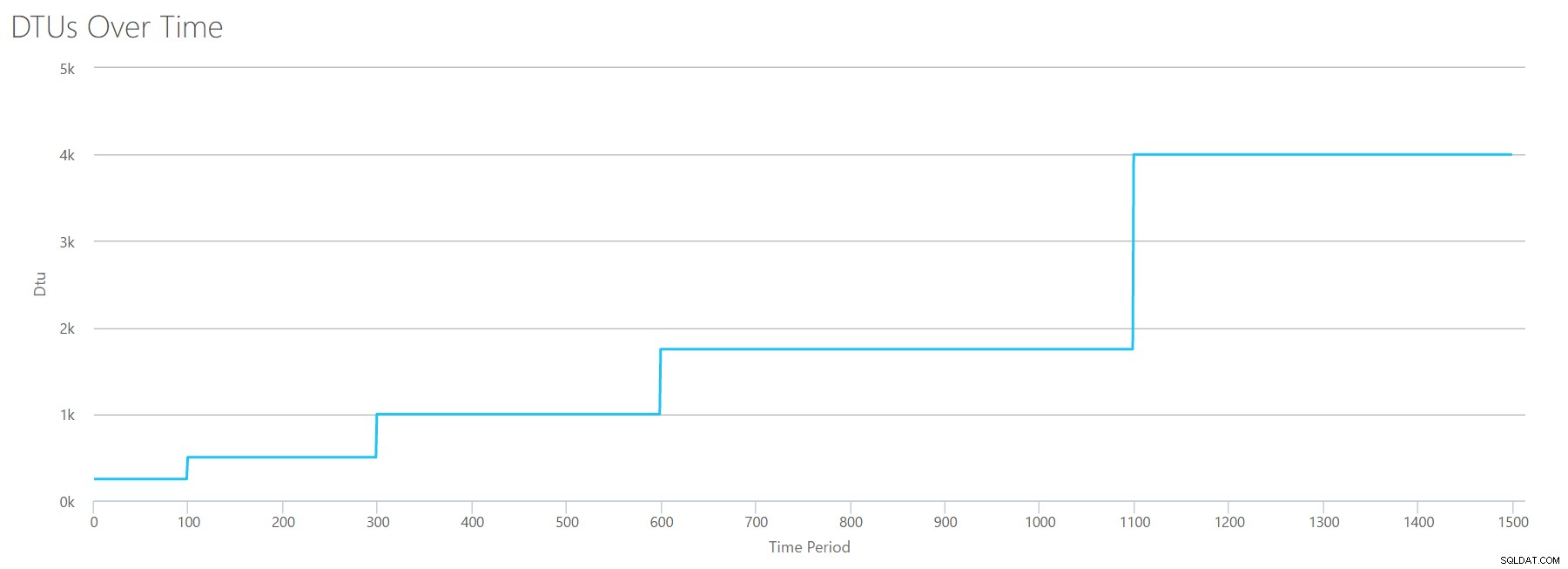
Vent et øjeblik ... det ligner den første graf. Igen, det går op i 5 ujævne trin, selvom jeg havde 15 lige trin i min fil. Lad os se på det i et tabelformat:
| Læsninger/sek. | DTU'er | Serviceniveau |
|---|---|---|
| 2000 | 250 | Premium – P2 |
| 4000-6000 | 500 | Premium – P4 |
| 8000-12000 | 1000 | Premium – P6 |
| 14000-22000 | 1750 | Premium – P11 |
| 24000-30000 | 4000 | Premium – P15 |
Igen ser vi, at Basic- og Standard-niveauerne springes over ret hurtigt (mindre end 2000 læsninger/sek.), men så er Premium-niveauet ret bredt og spænder over 2000 til 30000 læsninger i sekundet. I ovenstående tabel kunne "Reads/sek" sandsynligvis opfattes som "IOPS" … eller teknisk set bare "OPS", da der ikke er nogen skrivninger, der udgør "input"-delen af IOPS.
Skriver
Hvis vi opretter en CSV med den samme formel, som vi brugte til Reads, og uploader den CSV til DTU Lommeregneren, får vi en graf, der er identisk med grafen for Reads:
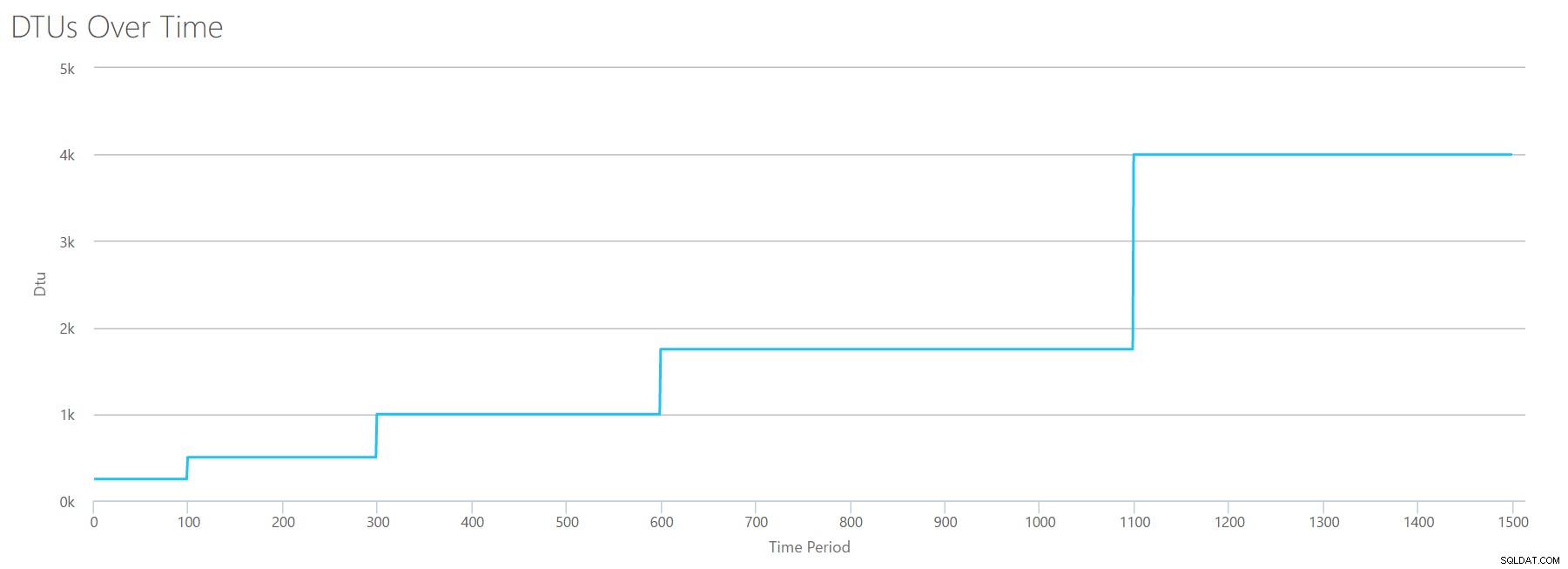
IOPS er IOPS, så uanset om det er en læsning eller en skrivning, ser det ud til, at DTU-beregningen betragter det lige meget. Alt, hvad vi ved (eller tror, vi ved) om læser, synes at gælde lige så meget for skrivninger.
Logbytes tømmes
Vi er oppe til den sidste perfmon-tæller:logbytes tømmes pr. sekund. Dette er et andet mål for IO, men specifikt for SQL Server-transaktionsloggen. Hvis du ikke har fanget det nu, opretter jeg disse CSV'er, så de høje værdier vil blive beregnet som en P15 Azure DB, og derefter opdele værdien for at opdele den i lige trin. Denne gang går vi fra 5 millioner til 75 millioner i trin på 5 millioner. Som vi gjorde ved alle tidligere test, vil de andre perfmon-tællere være nul. Da denne perfmon-tæller er i bytes per sekund, og vi måler i millioner, kan vi tænke på dette i den enhed, vi er mere komfortable med:Megabyte per sekund.
Vi uploader denne CSV til DTU-beregneren, og vi får følgende graf:
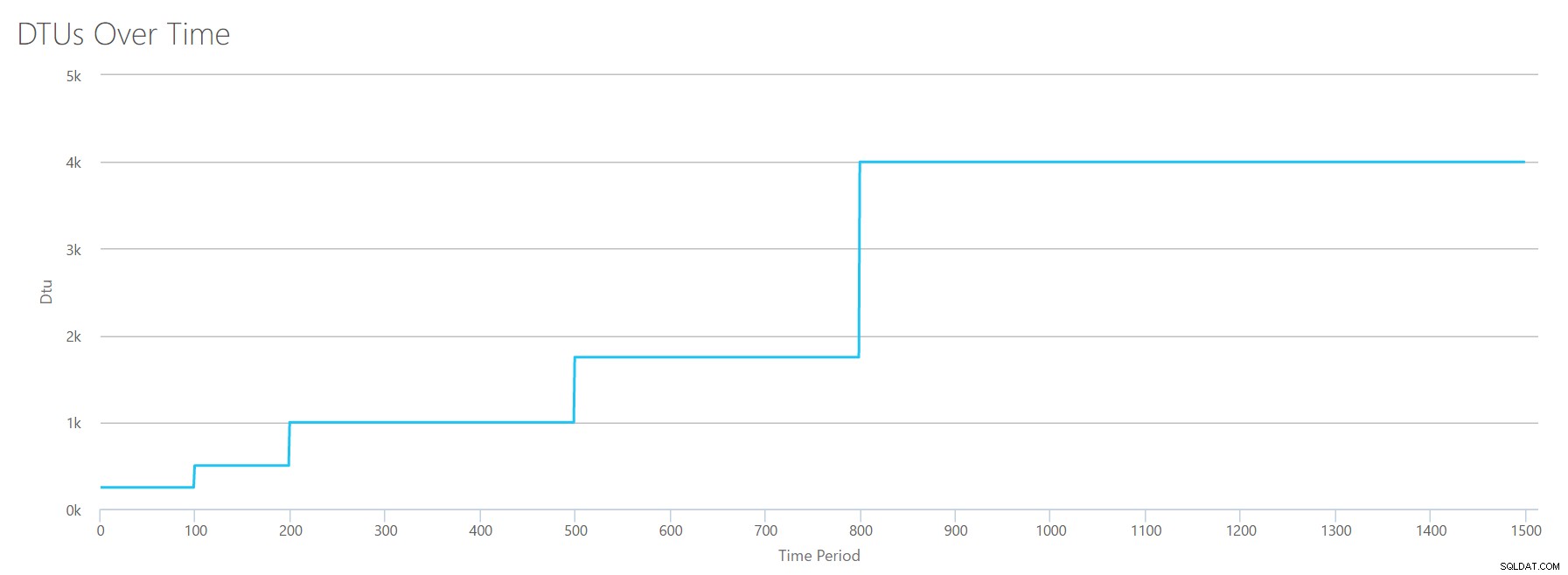
| Log megabyte skylles/sek. | DTU'er | Serviceniveau |
|---|---|---|
| 5 | 250 | Premium – P2 |
| 10 | 500 | Premium – P4 |
| 15-25 | 1000 | Premium – P6 |
| 30-40 | 1750 | Premium – P11 |
| 45-75 | 4000 | Premium – P15 |
Formen af denne graf bliver ret forudsigelig. Bortset fra denne gang går vi op gennem niveauerne en smule hurtigere og rammer P15 efter kun 8 trin (sammenlignet med 11 for IO og 12 for CPU). Dette kan få dig til at tænke:"Dette bliver min smalleste flaskehals!" men det ville jeg ikke være så sikker på. Hvor ofte genererer du 75 MB log på et sekund ? Det er 4,5 GB i minuttet . Det er meget databaseaktivitet. Min syntetiske arbejdsbyrde er ikke nødvendigvis en realistisk arbejdsbyrde.
Kombinering af alt
OK, nu hvor vi har set, hvor nogle af de øvre grænser er isoleret, vil jeg kombinere dataene og se, hvordan de sammenlignes, når CPU, I/O og transaktionslog IO alle sker på én gang – trods alt , er det ikke sådan tingene faktisk sker?
For at bygge denne CSV tog jeg simpelthen de eksisterende værdier, vi brugte til hver enkelt test ovenfor, og kombinerede disse værdier til en enkelt CSV, hvilket giver denne smukke graf:
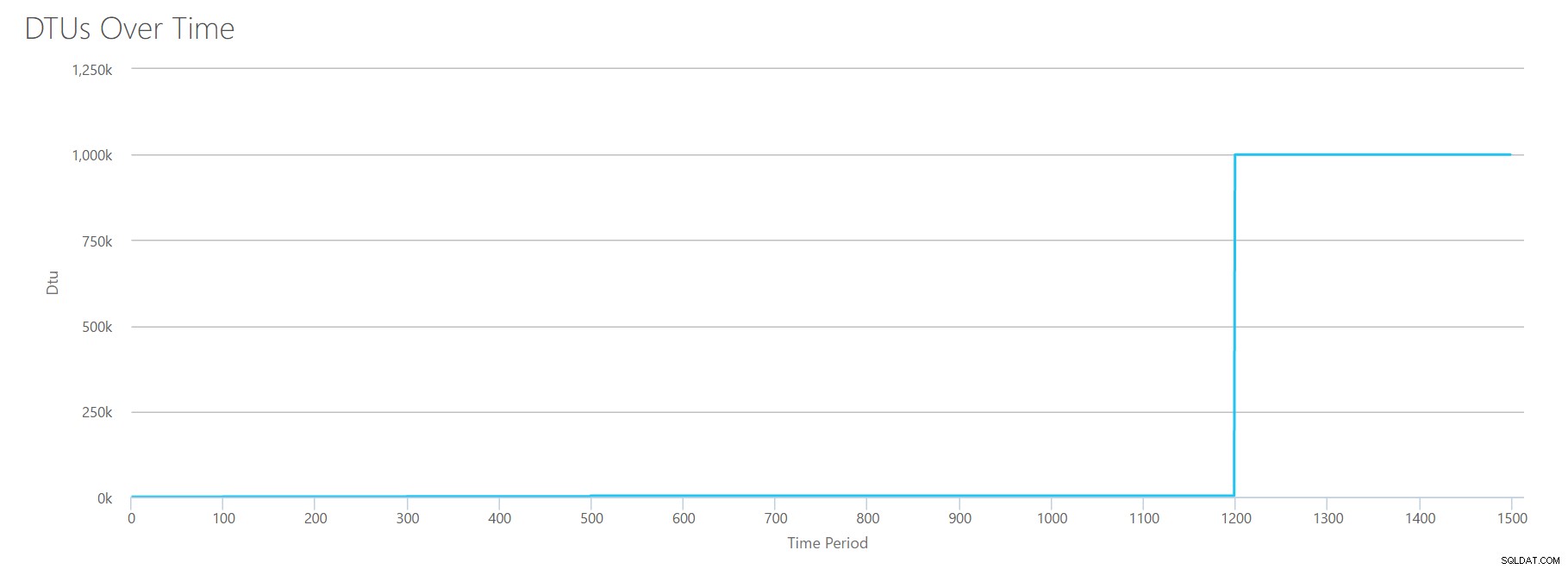
Det giver også beskeden:
Baseret på din databaseudnyttelse er din SQL Server-arbejdsbelastning Udenfor rækkevidde . På nuværende tidspunkt er der ikke et serviceniveau/ydelsesniveau, der dækker din brug.Hvis du ser på Y-aksen, vil du se, at vi rammer "1.000k" (dvs. 1 million) DTU'er ved 1200 sekunders mærket. Det virker...uhh...forkert? Hvis vi ser på ovenstående tests, var 1200 sekunder-mærket, når alle 4 individuelle målinger ramte mærket for 4000 DTU, P15-niveau. Det giver mening, at vi ville være uden for rækkevidde, men formen på grafen giver ikke helt mening for mig – jeg tror, at DTU-beregneren bare slog hænderne op og sagde:"Hvad som helst, Andy. Det er meget. Det er også meget. Det er en bajillion DTU'er. Denne arbejdsbelastning passer ikke til Azure SQL Database."
OK, så hvad sker der før 1200 sekunders mærket? Lad os skære ned på CSV'en og genindsende den til lommeregneren med kun de første 1200 sekunder. De maksimale værdier for hver kolonne er:81 % CPU (eller ca. 13 kerner ved 100 %), 24.000 læsninger/sek., 24.000 skrivninger/sek. og 60 MB log skyllet/sek.
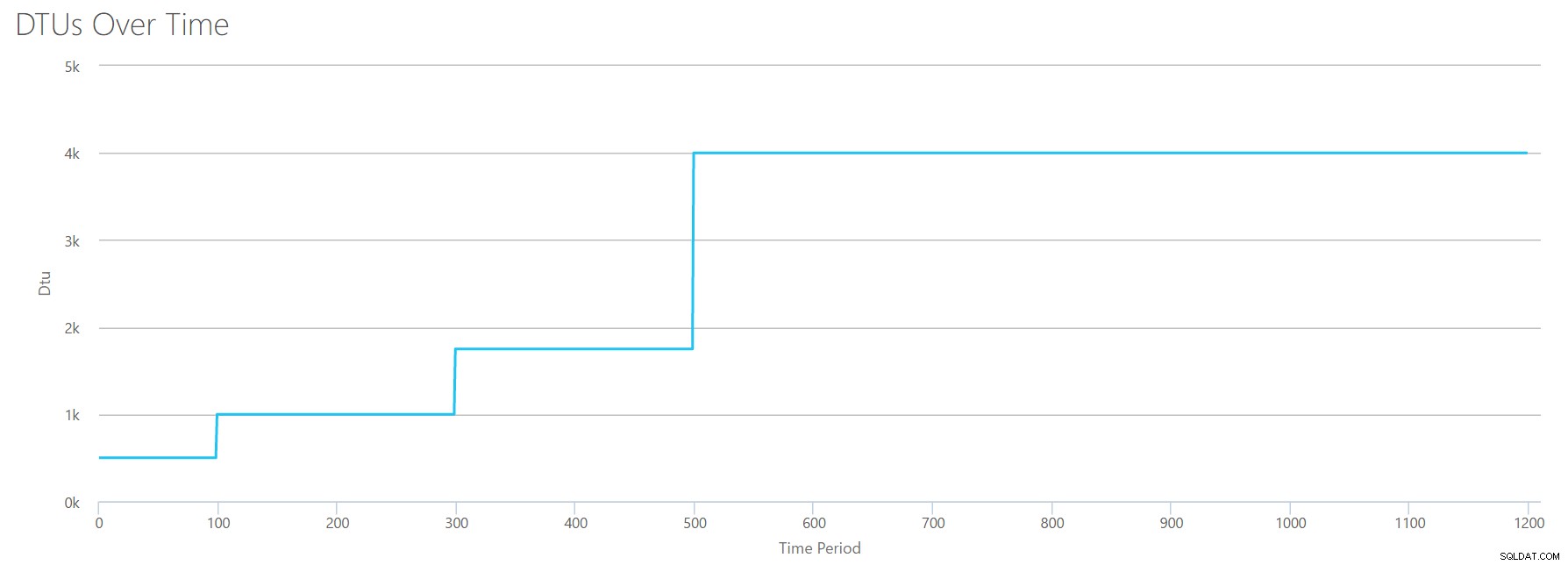
Hej gamle ven... Den velkendte form er tilbage igen. Her er en oversigt over dataene fra CSV'en, og hvad DTU-beregneren estimerer for det samlede DTU-forbrug og serviceniveau.
| Antal kerner | Læsninger/sek. | Skriver/sek. | Log megabyte skylles/sek. | DTU'er | Serviceniveau |
|---|---|---|---|---|---|
| 1 | 2000 | 2000 | 5 | 500 | Premium – P4 |
| 2-3 | 4000-6000 | 4000-6000 | 10 | 1000 | Premium – P6 |
| 4-5 | 8000-10000 | 8000-10000 | 15-25 | 1750 | Premium – P11 |
| 6-13 | 12000-24000 | 12000-24000 | 30-40 | 4000 | Premium – P15 |
Lad os nu se på, hvordan de individuelle DTU-beregninger (når vi evaluerede dem isoleret) sammenlignes med DTU-beregningerne fra denne seneste kontrol:
| CPU DTU'er | Læs DTU'er | Skriv DTU'er | Log skylle DTU'er | Sum i alt DTU'er | DTU Lommeregner estimat | Serviceniveau |
|---|---|---|---|---|---|---|
| 100 | 250 | 250 | 250 | 850 | 500 | Premium – P4 |
| 500 | 500 | 500 | 500 | 2000 | 1000 | Premium – P6 |
| 500-1000 | 1000 | 1000 | 1000 | 3500-4000 | 1750 | Premium – P11 |
| 1000-1750 | 1000-1750 | 1000-1750 | 1750 | 4750-7000 | 4000 | Premium – P15 |
Du vil bemærke, at DTU-beregningen ikke er så simpel som at lægge dine separate DTU'er sammen. Som definitionen, jeg citerede i starten, angiver, er det et "blandet mål" af disse separate metrikker. Formlen, der bruges til at "blande" er kompliceret, og den formel har vi faktisk ikke. Hvad vi kan se er, at DTU Lommeregner-estimaterne er lavere end summen af de separate DTU-beregninger.
Kortlægning af DTU'er til traditionel hardware
Lad os tage dataene fra DTU-beregneren og prøve at sammensætte nogle bud på, hvordan traditionel hardware kan knyttes til nogle Azure SQL Database-niveauer.
Lad os først antage, at "reads/sec" og "writes/sec" oversættes til IOPS direkte, uden behov for oversættelse. For det andet, lad os antage, at tilføjelse af disse to tællere vil give os vores samlede IOPS. For det tredje, lad os indrømme, at vi ikke har nogen idé om, hvad hukommelsesbrug er, og vi har ingen måde at drage nogen konklusioner på den front.
Mens jeg estimerer hardwarespecifikationer, vil jeg også vælge en mulig Azure VM-størrelse, der passer til hver hardwarekonfiguration. Der er mange lignende Azure VM-størrelser, hver optimeret til forskellige ydeevnemålinger, men jeg er gået videre og har begrænset mine valg til A-serien og DSv2-serien.
| Antal kerner | IOPS | Hukommelse | DTU'er | Serviceniveau | Sammenlignelig Azure VM-størrelse |
|---|---|---|---|---|---|
| 1 kerne, 5 % udnyttelse | 10 | ??? | 5 | Grundlæggende | Standard_A0, næsten ikke brugt |
| <1 kerne | 150 | ??? | 100 | Standard S0-S3 | Standard_A0, ikke fuldt udnyttet |
| 1 kerne | op til 4000 | ??? | 500 | Premium – P4 | Standard_DS1_v2 |
| 2-3 kerner | op til 12000 | ??? | 1000 | Premium – P6 | Standard_DS3_v2 |
| 4-5 kerner | op til 20.000 | ??? | 1750 | Premium – P11 | Standard_DS4_v2 |
| 6-13 | op til 48000 | ??? | 4000 | Premium – P15 | Standard_DS5_v2 |
Basic-niveauet er utroligt begrænset. Den er god til lejlighedsvis/afslappet brug, og det er en billig måde at "parkere" din database på, når du ikke bruger den. Men hvis du kører en rigtig applikation, vil Basic-niveauet ikke fungere for dig.
Standardniveauet er også ret begrænset, men til små applikationer er det i stand til at opfylde dine behov. Hvis du har en 2-core server, der kører en håndfuld databaser, kan disse databaser individuelt passe ind i standardniveauet. Tilsvarende, hvis du har en server med kun én database, der kører 1 CPU-kerne på 100 % (eller 2 kerner, der kører på 50%), er det sandsynligvis lige nok hestekræfter til at vippe skalaen ind i Premium-P1-serviceniveauet.
Hvis du ville bruge en multi-core-server i en lokal (eller IaaS), så ville du kigge inden for Premium-tjenesteniveauet på Azure SQL Database. Det er bare et spørgsmål om at bestemme, hvor mange CPU &I/O hestekræfter du har brug for til din arbejdsbyrde. Din 2-core, 4GB server lander dig sandsynligvis et sted omkring en P6 Azure SQL DB. I en ren CPU-arbejdsbelastning (med nul I/O) kunne en P15-database håndtere 16 kerner til behandling, men når du først tilføjer IO til blandingen, passer noget større end ~12 kerner ikke ind i Azure SQL Database.
Næste gang vil jeg tage nogle faktiske arbejdsbelastninger og sammenligne ydeevne på tværs af serviceniveauer. Vil DTU Lommeregnerens skøn være korrekte? Det finder vi ud af.
Om forfatteren
 Andy Mallon er en SQL Server DBA og Microsoft Data Platform MVP, der har administreret databaser inden for sundhedssektoren, finans, e. -handel og non-profit sektorer. Siden 2003 har Andy understøttet højvolumen, meget tilgængelige OLTP-miljøer med krævende ydeevnebehov. Andy er grundlæggeren af BostonSQL, medarrangør af SQLSaturday Boston, og blogger på am2.co.
Andy Mallon er en SQL Server DBA og Microsoft Data Platform MVP, der har administreret databaser inden for sundhedssektoren, finans, e. -handel og non-profit sektorer. Siden 2003 har Andy understøttet højvolumen, meget tilgængelige OLTP-miljøer med krævende ydeevnebehov. Andy er grundlæggeren af BostonSQL, medarrangør af SQLSaturday Boston, og blogger på am2.co.