En simpel definition af medianen er:
Medianen er den midterste værdi i en sorteret liste over talFor at uddybe det lidt, kan vi finde medianen af en liste med tal ved at bruge følgende procedure:
- Sortér tallene (i stigende eller faldende rækkefølge, det er lige meget hvilket).
- Det midterste tal (efter position) i den sorterede liste er medianen.
- Hvis der er to "lige mellemste" tal, er medianen gennemsnittet af de to midterste værdier.
Aaron Bertrand har tidligere præstationstestet flere måder at beregne medianen på i SQL Server:
- Hvad er den hurtigste måde at beregne medianen på?
- Bedste tilgange til grupperet median
Rob Farley tilføjede for nylig en anden tilgang rettet mod installationer før 2012:
- Medianer før SQL 2012
Denne artikel introducerer en ny metode ved hjælp af en dynamisk markør.
2012 OFFSET-FETCH-metoden
Vi starter med at se på den bedst ydende implementering, skabt af Peter Larsson. Den bruger SQL Server 2012 OFFSET udvidelse til ORDER BY klausul for effektivt at lokalisere den ene eller to midterste rækker, der er nødvendige for at beregne medianen.
OFFSET Enkelt median
Aarons første artikel testede at beregne en enkelt median over en tabel med ti millioner rækker:
CREATE TABLE dbo.obj
(
id integer NOT NULL IDENTITY(1,1),
val integer NOT NULL
);
INSERT dbo.obj WITH (TABLOCKX)
(val)
SELECT TOP (10000000)
AO.[object_id]
FROM sys.all_columns AS AC
CROSS JOIN sys.all_objects AS AO
CROSS JOIN sys.all_objects AS AO2
WHERE AO.[object_id] > 0
ORDER BY
AC.[object_id];
CREATE UNIQUE CLUSTERED INDEX cx
ON dbo.obj(val, id);
Peter Larssons løsning ved hjælp af OFFSET udvidelsen er:
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT
Median = AVG(1.0 * SQ1.val)
FROM
(
SELECT O.val
FROM dbo.obj AS O
ORDER BY O.val
OFFSET (@Count - 1) / 2 ROWS
FETCH NEXT 1 + (1 - @Count % 2) ROWS ONLY
) AS SQ1;
SELECT Peso = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME()); Koden ovenfor hardkoder resultatet af optælling af rækkerne i tabellen. Alle testede metoder til beregning af medianen har brug for denne optælling for at beregne medianrækkenumrene, så det er en konstant omkostning. Ved at udelade rækketællingsoperationen uden for timingen undgås en mulig kilde til variation.
Udførelsesplanen for OFFSET løsning er vist nedenfor:

Den øverste operatør springer hurtigt over de unødvendige rækker og sender kun den ene eller to rækker, der er nødvendige for at beregne medianen, videre til Stream Aggregate. Når den køres med en varm cache og udførelsesplansamling slået fra, kører denne forespørgsel i 910 ms i gennemsnit på min bærbare computer. Dette er en maskine med en Intel i7 740QM-processor, der kører ved 1,73 GHz med Turbo deaktiveret (for at opnå konsistens).
OFFSET grupperet median
Aarons anden artikel testede ydelsen ved at beregne en median pr. gruppe ved at bruge en salgstabel på en million rækker med ti tusinde poster for hver af hundrede sælgere:
CREATE TABLE dbo.Sales
(
SalesPerson integer NOT NULL,
Amount integer NOT NULL
);
WITH X AS
(
SELECT TOP (100)
V.number
FROM master.dbo.spt_values AS V
GROUP BY
V.number
)
INSERT dbo.Sales WITH (TABLOCKX)
(
SalesPerson,
Amount
)
SELECT
X.number,
ABS(CHECKSUM(NEWID())) % 99
FROM X
CROSS JOIN X AS X2
CROSS JOIN X AS X3;
CREATE CLUSTERED INDEX cx
ON dbo.Sales
(SalesPerson, Amount);
Igen bruger den bedst ydende løsning OFFSET :
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
INSERT @Result
SELECT d.SalesPerson, w.Median
FROM
(
SELECT SalesPerson, COUNT(*) AS y
FROM dbo.Sales
GROUP BY SalesPerson
) AS d
CROSS APPLY
(
SELECT AVG(0E + Amount)
FROM
(
SELECT z.Amount
FROM dbo.Sales AS z WITH (PAGLOCK)
WHERE z.SalesPerson = d.SalesPerson
ORDER BY z.Amount
OFFSET (d.y - 1) / 2 ROWS
FETCH NEXT 2 - d.y % 2 ROWS ONLY
) AS f
) AS w(Median);
SELECT Peso = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Den vigtige del af udførelsesplanen er vist nedenfor:

Den øverste række i planen handler om at finde grupperækkeantal for hver sælger. Den nederste række bruger de samme planelementer, der ses for enkelt-gruppe medianløsningen til at beregne medianen for hver sælger. Når den køres med en varm cache og deaktiverede eksekveringsplaner, udføres denne forespørgsel på 320 ms i gennemsnit på min bærbare computer.
Brug af en dynamisk markør
Det kan virke skørt overhovedet at tænke på at bruge en markør til at beregne medianen. Transact SQL-markører har et (for det meste velfortjent) ry for at være langsomme og ineffektive. Det menes også ofte, at dynamiske markører er den værste type markør. Disse punkter er gyldige under nogle omstændigheder, men ikke altid.
Transact SQL-markører er begrænset til at behandle en enkelt række ad gangen, så de kan faktisk være langsomme, hvis mange rækker skal hentes og behandles. Det er dog ikke tilfældet for medianberegningen:alt, hvad vi skal gøre, er at finde og hente de ene eller to midterste værdier effektivt . En dynamisk markør er meget velegnet til denne opgave, som vi skal se.
Enkelt median dynamisk markør
Den dynamiske markørløsning til en enkelt medianberegning består af følgende trin:
- Opret en dynamisk rullebar markør over den ordnede liste over elementer.
- Beregn placeringen af den første medianrække.
- Flyt markøren ved hjælp af
FETCH RELATIVE. - Beslut om en anden række er nødvendig for at beregne medianen.
- Hvis ikke, returner den enkelte medianværdi med det samme.
- Ellers skal du hente den anden værdi ved hjælp af
FETCH NEXT. - Beregn gennemsnittet af de to værdier og afkast.
Læg mærke til, hvor tæt denne liste afspejler den enkle procedure til at finde medianen, der er angivet i starten af denne artikel. En komplet Transact SQL-kodeimplementering er vist nedenfor:
-- Dynamic cursor
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE
@RowCount bigint, -- Total row count
@Row bigint, -- Median row number
@Amount1 integer, -- First amount
@Amount2 integer, -- Second amount
@Median float; -- Calculated median
SET @RowCount = 10000000;
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
DECLARE Median CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
O.val
FROM dbo.obj AS O
ORDER BY
O.val;
OPEN Median;
-- Calculate the position of the first median row
SET @Row = (@RowCount + 1) / 2;
-- Move to the row
FETCH RELATIVE @Row
FROM Median
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value we have
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Median
INTO @Amount2;
-- Calculate the median value from the two values
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
SELECT Median = @Median;
SELECT DynamicCur = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());
Udførelsesplanen for FETCH RELATIVE sætning viser, at den dynamiske markør effektivt flytter til den første række, der kræves til medianberegningen:
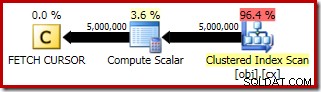
Planen for FETCH NEXT (kun påkrævet, hvis der er en anden midterste række, som i disse test) er en enkelt række hente fra den gemte position af markøren:
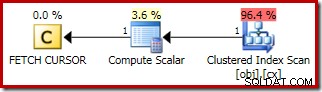
Fordelene ved at bruge en dynamisk markør her er:
- Den undgår at krydse hele sættet (læsningen stopper, efter at medianrækkerne er fundet); og
- Der laves ingen midlertidig kopi af dataene i tempdb , som det ville være for en statisk eller keyset-markør.
Bemærk, at vi ikke kan angive en FAST_FORWARD markøren her (overlader valget af en statisk-lignende eller dynamisk-lignende plan til optimizeren), fordi markøren skal kunne rulles for at understøtte FETCH RELATIVE . Dynamisk er alligevel det optimale valg her.
Når den køres med en varm cache og udførelsesplansamling slået fra, kører denne forespørgsel i 930 ms i gennemsnit på min testmaskine. Dette er lidt langsommere end 910 ms for OFFSET løsning, men den dynamiske markør er betydeligt hurtigere end de andre metoder, Aaron og Rob testede, og den kræver ikke SQL Server 2012 (eller nyere).
Jeg vil ikke gentage at teste de andre metoder fra før 2012 her, men som et eksempel på størrelsen af ydeevnegabet tager den følgende rækkenummereringsløsning 1550 ms i gennemsnit (70 % langsommere):
DECLARE @Start datetime2 = SYSUTCDATETIME();
DECLARE @Count bigint = 10000000
--(
-- SELECT COUNT_BIG(*)
-- FROM dbo.obj AS O
--);
SELECT AVG(1.0 * SQ1.val) FROM
(
SELECT
O.val,
rn = ROW_NUMBER() OVER (
ORDER BY O.val)
FROM dbo.obj AS O WITH (PAGLOCK)
) AS SQ1
WHERE
SQ1.rn BETWEEN (@Count + 1)/2 AND (@Count + 2)/2;
SELECT RowNumber = DATEDIFF(MILLISECOND, @Start, SYSUTCDATETIME());

Grupper median dynamisk markørtest
Det er nemt at udvide den dynamiske cursorløsning med enkelt median til at beregne grupperede medianer. For konsekvensens skyld vil jeg bruge indlejrede markører (ja, virkelig):
- Åbn en statisk markør over sælgerne og rækker.
- Beregn medianen for hver person ved at bruge en ny dynamisk markør hver gang.
- Gem hvert resultat i en tabelvariabel undervejs.
Koden er vist nedenfor:
-- Timing
DECLARE @s datetime2 = SYSUTCDATETIME();
-- Holds results
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median float NOT NULL
);
-- Variables
DECLARE
@SalesPerson integer, -- Current sales person
@RowCount bigint, -- Current row count
@Row bigint, -- Median row number
@Amount1 float, -- First amount
@Amount2 float, -- Second amount
@Median float; -- Calculated median
-- Row counts per sales person
DECLARE SalesPersonCounts
CURSOR
LOCAL
FORWARD_ONLY
STATIC
READ_ONLY
FOR
SELECT
SalesPerson,
COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
ORDER BY SalesPerson;
OPEN SalesPersonCounts;
-- First person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
WHILE @@FETCH_STATUS = 0
BEGIN
-- Records for the current person
-- Note dynamic cursor
DECLARE Person CURSOR
LOCAL
SCROLL
DYNAMIC
READ_ONLY
FOR
SELECT
S.Amount
FROM dbo.Sales AS S
WHERE
S.SalesPerson = @SalesPerson
ORDER BY
S.Amount;
OPEN Person;
-- Calculate median row 1
SET @Row = (@RowCount + 1) / 2;
-- Move to median row 1
FETCH RELATIVE @Row
FROM Person
INTO @Amount1;
IF @Row = (@RowCount + 2) / 2
BEGIN
-- No second row, median is the single value
SET @Median = @Amount1;
END
ELSE
BEGIN
-- Get the second row
FETCH NEXT
FROM Person
INTO @Amount2;
-- Calculate the median value
SET @Median = (@Amount1 + @Amount2) / 2e0;
END;
-- Add the result row
INSERT @Result (SalesPerson, Median)
VALUES (@SalesPerson, @Median);
-- Finished with the person cursor
CLOSE Person;
DEALLOCATE Person;
-- Next person
FETCH NEXT
FROM SalesPersonCounts
INTO @SalesPerson, @RowCount;
END;
---- Results
--SELECT
-- R.SalesPerson,
-- R.Median
--FROM @Result AS R;
-- Tidy up
CLOSE SalesPersonCounts;
DEALLOCATE SalesPersonCounts;
-- Show elapsed time
SELECT NestedCur = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME()); Den ydre markør er bevidst statisk, fordi alle rækker i det sæt vil blive berørt (også er en dynamisk markør ikke tilgængelig på grund af grupperingsoperationen i den underliggende forespørgsel). Der er ikke noget særligt nyt eller interessant at se i udførelsesplanerne denne gang.
Det interessante er præstationen. På trods af den gentagne oprettelse og deallokering af den indre dynamiske markør, klarer denne løsning sig rigtig godt på testdatasættet. Med en varm cache og deaktiverede eksekveringsplaner afsluttes markørscriptet på 330 ms i gennemsnit på min testmaskine. Dette er igen en lille smule langsommere end 320 ms optaget med OFFSET grupperet median, men det slår de andre standardløsninger, der er anført i Aarons og Robs artikler med stor margin.
Igen, som et eksempel på ydeevnegabet til de andre metoder, der ikke er fra 2012, kører følgende rækkenummereringsløsning i 485 ms i gennemsnit på min testrig (50 % dårligere):
DECLARE @s datetime2 = SYSUTCDATETIME();
DECLARE @Result AS table
(
SalesPerson integer PRIMARY KEY,
Median numeric(38, 6) NOT NULL
);
INSERT @Result
SELECT
S.SalesPerson,
CA.Median
FROM
(
SELECT
SalesPerson,
NumRows = COUNT_BIG(*)
FROM dbo.Sales
GROUP BY SalesPerson
) AS S
CROSS APPLY
(
SELECT AVG(1.0 * SQ1.Amount) FROM
(
SELECT
S2.Amount,
rn = ROW_NUMBER() OVER (
ORDER BY S2.Amount)
FROM dbo.Sales AS S2 WITH (PAGLOCK)
WHERE
S2.SalesPerson = S.SalesPerson
) AS SQ1
WHERE
SQ1.rn BETWEEN (S.NumRows + 1)/2 AND (S.NumRows + 2)/2
) AS CA (Median);
SELECT RowNumber = DATEDIFF(MILLISECOND, @s, SYSUTCDATETIME());

Resultatoversigt
I den enkelte mediantest kørte den dynamiske markør i 930 ms versus 910 ms for OFFSET metode.
I den grupperede mediantest kørte den indlejrede markør i 330 ms versus 320 ms for OFFSET .
I begge tilfælde var markørmetoden betydeligt hurtigere end den anden ikke-OFFSET metoder. Hvis du har brug for at beregne en enkelt eller grupperet median på en forekomst før 2012, kunne en dynamisk markør eller indlejret markør virkelig være det optimale valg.
Cold Cache-ydelse
Nogle af jer undrer sig måske over den kolde cache-ydelse. Kører følgende før hver test:
CHECKPOINT; DBCC DROPCLEANBUFFERS;
Dette er resultaterne for den enkelte mediantest:
OFFSET metode:940 ms
Dynamisk markør:955 ms
For den grupperede median:
OFFSET metode:380 ms
Indlejrede markører:385 ms
Sidste tanker
De dynamiske markørløsninger er virkelig betydeligt hurtigere end ikke-OFFSET metoder for både enkelte og grupperede medianer, i det mindste med disse stikprøvedatasæt. Jeg valgte bevidst at genbruge Aarons testdata, så datasættene ikke var bevidst skævt mod den dynamiske markør. Der måske være andre datadistributioner, hvor den dynamiske markør ikke er en god mulighed. Ikke desto mindre viser det, at der stadig er tidspunkter, hvor en markør kan være en hurtig og effektiv løsning på den rigtige slags problem. Selv dynamiske og indlejrede markører.
Ørneøjede læsere har muligvis bemærket PAGLOCK tip i OFFSET grupperet mediantest. Dette er påkrævet for den bedste ydeevne, af grunde jeg vil dække i min næste artikel. Uden det taber 2012-løsningen faktisk til den indlejrede markør med en anstændig margen (590ms versus 330 ms ).