Er SQL DISTINCT god (eller dårlig), når du skal fjerne dubletter i resultater?
Nogle siger, at det er godt og tilføjer DISTINCT, når dubletter vises. Nogle siger, at det er dårligt og foreslår at bruge GROUP BY uden en samlet funktion. Andre siger, at DISTINCT og GROUP BY er de samme, når du skal fjerne dubletter.
Dette indlæg vil dykke ned i detaljerne for at få korrekte svar. Så til sidst vil du bruge det bedste søgeord baseret på behovet. Lad os begynde.
En kort påmindelse om det grundlæggende i SQL SELECT DISTINCT-sætningen
Før vi dykker dybere, lad os huske, hvad SQL SELECT DISTINCT-sætningen er. En databasetabel kan indeholde duplikerede værdier af mange årsager, men vi ønsker måske kun at få de unikke værdier. I dette tilfælde kommer SELECT DISTINCT praktisk. Denne DISTINCT-sætning gør, at SELECT-sætningen kun henter unikke poster.
Syntaksen for sætningen er enkel:
SELECT DISTINCT column
FROM table_name
WHERE [condition];Her er WHERE-betingelsen valgfri.
Udsagnet gælder både for en enkelt kolonne og flere kolonner. Syntaksen for denne sætning anvendt på flere kolonner er som følger:
SELECT DISTINCT
column_name1,
column_name2,
column_nameN.
FROM
table_name;Bemærk, at scenariet med at forespørge flere kolonner vil foreslå at bruge kombinationen af værdier i alle kolonner, der er defineret af sætningen, for at bestemme unikheden.
Og lad os nu udforske den praktiske brug og mulighederne ved at anvende SELECT DISTINCT-sætningen.
Sådan fungerer SQL DISTINCT for at fjerne dubletter
At få svar er ikke så svært at finde. SQL Server gav os eksekveringsplaner for at se, hvordan en forespørgsel vil blive behandlet for at give os de nødvendige resultater.
Det følgende afsnit fokuserer på udførelsesplanen ved brug af DISTINCT. Du skal trykke på Ctrl-M i SQL Server Management Studio, før du udfører forespørgslerne nedenfor. Eller klik på Inkluder faktisk eksekveringsplan fra værktøjslinjen.
Forespørgselsplaner i SQL DISTINCT
Lad os starte med at sammenligne 2 forespørgsler. Den første vil ikke bruge DISTINCT, og den anden forespørgsel vil.
USE AdventureWorks
GO
-- Without DISTINCT. Duplicates included
SELECT Lastname FROM Person.Person;
-- With DISTINCT. Duplicates removed
SELECT DISTINCT Lastname FROM Person.Person;
Her er udførelsesplanen:
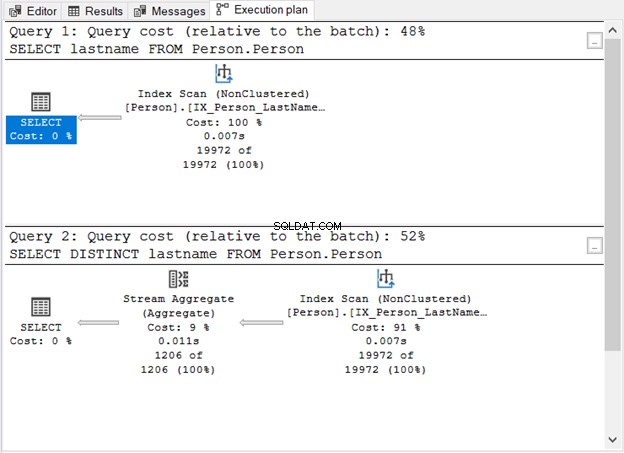
Hvad viste figur 1 os?
- Uden DISTINCT-søgeordet er forespørgslen enkel.
- Et ekstra trin vises efter tilføjelse af DISTINCT.
- Forespørgselsomkostningerne ved at bruge DISTINCT er højere end uden.
- Begge har indeksscanningsoperatorer. Dette er forståeligt, fordi der ikke er nogen specifik WHERE-klausul i vores forespørgsler.
- Det ekstra trin, Stream Aggregate-operatøren, bruges til at fjerne dubletterne.
Antallet af logiske læsninger er det samme (107), hvis du tjekker STATISTICS IO. Alligevel er antallet af rekorder meget forskelligt. 19.972 rækker returneres af den første forespørgsel. I mellemtiden returneres 1.206 rækker af den anden forespørgsel.
Derfor kan du ikke tilføje DISTINCT når som helst du vil. Men hvis du har brug for unikke værdier, er dette en nødvendig overhead.
Der er operatører, der bruges til at udlæse unikke værdier. Lad os undersøge nogle af dem.
STREAMSAMMEL
Dette er den operator, du så i figur 1. Den accepterer et enkelt input og udsender et aggregeret resultat. I figur 1 kommer inputtet fra Index Scan-operatøren. Stream Aggregate har dog brug for et sorteret input.
Som du kan se i figur 1, bruger den IX_Person_LastName_FirstName_MiddleName , et ikke-unik indeks over navne. Da indekset allerede sorterer posterne efter navn, accepterer Stream Aggregate inputtet. Uden indekset kan forespørgselsoptimeringsværktøjet vælge at bruge en ekstra sorteringsoperator i planen. Og det bliver dyrere. Eller den kan bruge et Hash Match.
HASH MATCH (AGGREGAT)
En anden operatør, der bruges af DISTINCT, er Hash Match. Denne operator bruges til sammenføjninger og sammenlægninger.
Når du bruger DISTINCT, samler Hash Match resultaterne for at producere unikke værdier. Her er et eksempel.
USE AdventureWorks
GO
-- Get unique first names
SELECT DISTINCT Firstname FROM Person.Person;
Og her er udførelsesplanen:
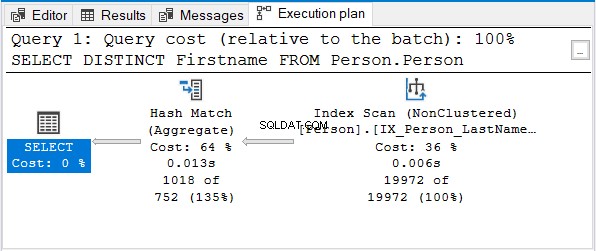
Men hvorfor ikke Stream Aggregate?
Bemærk, at det samme navneindeks er brugt. Det indeks sorterer efter Efternavn først. Altså et Fornavn kun forespørgsel bliver usorteret.
Hash Match (Aggregate) er det næste logiske valg for at fjerne dubletterne.
HASH MATCH (FLOW DISTINCT)
Hash Match (Aggregate) er en blokerende operatør. Det vil således ikke producere det output, det har behandlet hele inputstrømmen. Hvis vi begrænser antallet af rækker (som at bruge TOP med DISTINCT), vil det producere et unikt output, så snart disse rækker er tilgængelige. Det er, hvad Hash Match (Flow Distinct) handler om.
USE AdventureWorks
GO
SELECT DISTINCT TOP 100
sod.ProductID
,soh.OrderDate
,soh.ShipDate
FROM Sales.SalesOrderDetail sod
INNER JOIN Sales.SalesOrderHeader soh ON sod.SalesOrderID = soh.SalesOrderID;
Forespørgslen bruger TOP 100 sammen med DISTINCT. Her er udførelsesplanen:
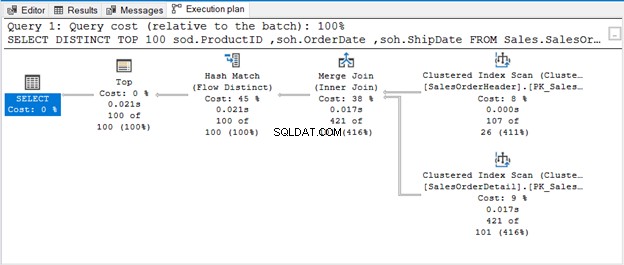
NÅR DER INGEN OPERATØR ER TIL AT FJERNE DUBLIKATER
Jep. Dette kan ske. Overvej eksemplet nedenfor.
USE AdventureWorks
GO
SELECT DISTINCT
BusinessEntityID
FROM Person.Person;
Tjek derefter udførelsesplanen:
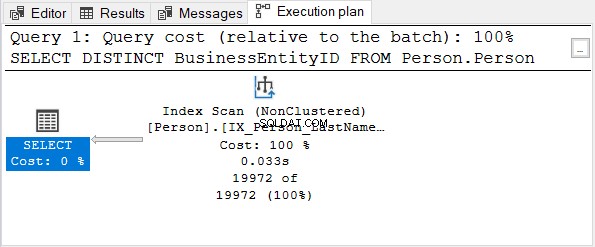
BusinessEntityID kolonne er den primære nøgle. Da den kolonne allerede er unik, nytter det ikke at anvende DISTINCT. Prøv at fjerne DISTINCT fra SELECT-sætningen – udførelsesplanen er den samme som i figur 4.
Det samme gælder, når du bruger DISTINCT på kolonner med et unikt indeks.
SQL DISTINCT virker på ALLE kolonner i SELECT-listen
Indtil videre har vi kun brugt 1 kolonne i vores eksempler. DISTINCT virker dog på ALLE kolonner, du angiver i SELECT-listen.
Her er et eksempel. Denne forespørgsel vil sikre, at værdierne for alle 3 kolonner vil være unikke.
USE AdventureWorks
GO
SELECT DISTINCT
Lastname
,FirstName
,MiddleName
FROM Person.Person;
Læg mærke til de første par rækker i resultatsættet i figur 5.
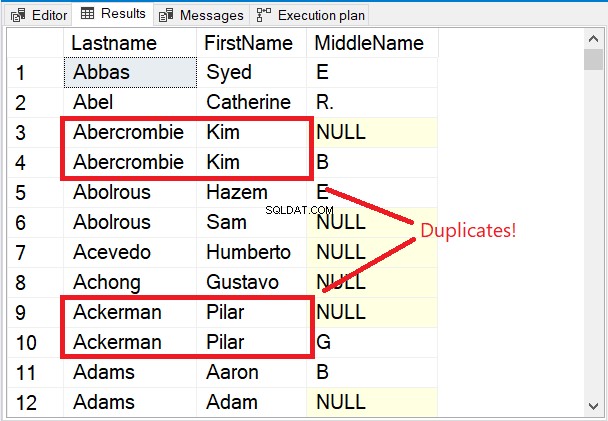
De første par rækker er alle unikke. Nøgleordet DISTINCT sørgede for, at Mellemnavn kolonne overvejes også. Læg mærke til de 2 navne indrammet i rødt. I betragtning af Efternavn og Fornavn kun vil gøre dem duplikater. Men tilføjelse af Mellemnavn til blandingen ændrede alt.
Hvad hvis du vil have unikke for- og efternavne, men inkludere mellemnavnet i resultatet?
Du har 2 muligheder:
- Tilføj en WHERE-sætning for at fjerne NULL mellemnavne. Dette vil fjerne alle navne med et NULL mellemnavn.
- Eller tilføj en GROUP BY-sætning på Efternavn og Fornavn kolonner. Brug derefter MIN aggregatfunktionen på Mellemnavn kolonne. Dette vil få 1 mellemnavn med samme efternavn og fornavn.
SQL DISTINCT vs. GROUP BY
Når du bruger GROUP BY uden en aggregeret funktion, fungerer det som DISTINCT. Hvordan ved vi det? En måde at finde ud af det på er at bruge et eksempel.
USE AdventureWorks
GO
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID;
-- using GROUP BY
SELECT
soh.TerritoryID
,st.Name
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesTerritory st ON soh.TerritoryID = st.TerritoryID
GROUP BY
soh.TerritoryID
,st.Name;
Kør dem og tjek udførelsesplanen. Er det ligesom skærmbilledet nedenfor?
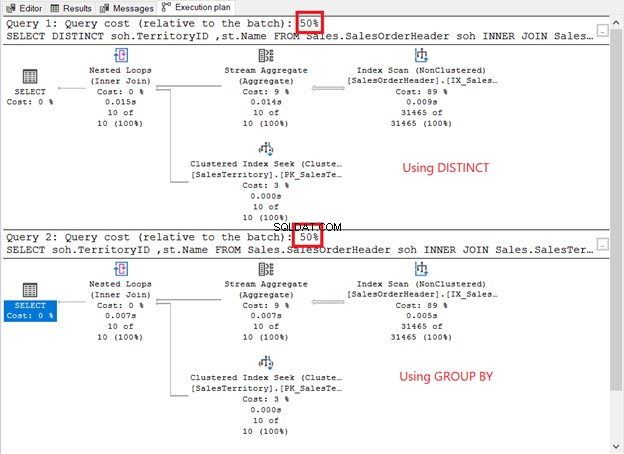
Hvordan sammenlignes de?
- De har samme planoperatorer og sekvens.
- Operatøromkostningerne for hver og forespørgselsomkostningerne er de samme.
Hvis du tjekker QueryPlanHash egenskaberne for de 2 SELECT-operatorer, er de de samme. Derfor brugte forespørgselsoptimeringsværktøjet den samme proces til at returnere de samme resultater.
I sidste ende kan vi ikke sige, at brugen af GROUP BY er bedre end DISTINCT til at returnere unikke værdier. Du kan bevise dette ved at bruge ovenstående eksempler til at erstatte DISTINCT med GROUP BY.
Det er nu et spørgsmål om præference, hvilken du vil bruge. Jeg foretrækker DISTINCT. Det fortæller eksplicit hensigten med forespørgslen - at producere unikke resultater. Og for mig er GROUP BY til at gruppere resultater ved hjælp af en aggregeret funktion. Denne hensigt er også klar og i overensstemmelse med selve søgeordet. Jeg ved ikke, om nogen anden vil vedligeholde mine forespørgsler en dag. Så koden skal være klar.
Men det er ikke slutningen på historien.
Når SQL DISTINCT ikke er det samme som GROUP BY
Jeg har lige udtrykt min mening, og så det her?
Det er sandt. De vil ikke være ens hele tiden. Overvej dette eksempel.
-- using DISTINCT
SELECT DISTINCT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh;
-- using GROUP BY
SELECT
soh.TerritoryID
,(SELECT name FROM Sales.SalesTerritory st WHERE st.TerritoryID = soh.TerritoryID) AS TerritoryName
FROM Sales.SalesOrderHeader soh
GROUP BY
soh.TerritoryID;
Selvom resultatsættet er usorteret, er rækkerne de samme som i det foregående eksempel. Den eneste forskel er brugen af en underforespørgsel:
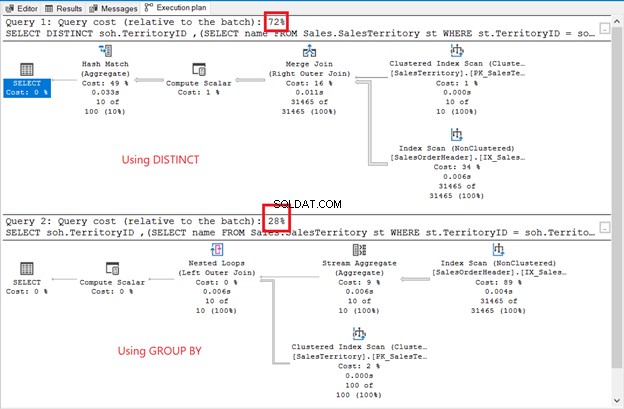
Forskellene er indlysende:operatører, forespørgselsomkostninger, overordnet plan. Denne gang vinder GROUP BY med kun 28 % forespørgselsomkostninger. Men her er sagen.
Målet er at vise dig, at de kan være forskellige. Det er alt. Dette er på ingen måde en anbefaling. Brug af en join har en bedre udførelsesplan (se figur 6 igen).
Bundlinjen
Her er, hvad vi har lært indtil videre:
- DISTINCT tilføjer en planoperatør for at fjerne dubletter.
- DISTINCT og GROUP BY uden en aggregeret funktion resulterer i den samme plan. Kort sagt, de er de samme det meste af tiden.
- Nogle gange kan DISTINCT og GROUP BY have forskellige planer, når en underforespørgsel er involveret i SELECT-listen.
Så er SQL DISTINCT god eller dårlig til at fjerne dubletter i resultater?
Resultaterne siger, at det er godt. Det er ikke bedre eller værre end GROUP BY, fordi planerne er de samme. Men det er en god vane at tjekke udførelsesplanen. Tænk på optimering fra starten. På den måde, hvis du støder på forskelle i DISTINCT og GROUP BY, vil du opdage dem.
Desuden gør de moderne værktøjer denne opgave meget enklere. For eksempel har et populært produkt dbForge SQL Complete fra Devart en specifik funktion, der beregner værdier i de samlede funktioner i det færdige resultatsæt i SSMS-resultatgitteret. DISTINCT-værdierne er også til stede der.
Like opslaget? Så spred venligst ordet ved at dele det på dine foretrukne sociale medieplatforme.
Relaterede artikler for mere information
- SQL GROUP BY:3 nemme tips til at gruppere resultater som en professionel
- SQL INSERT INTO SELECT:5 nemme måder at håndtere dubletter på
- Hvad er SQL-aggregatfunktioner? (Nemte tips til nybegyndere)
- SQL-forespørgselsoptimering:5 kernefakta til at øge forespørgsler