Jeg har haft mange samtaler på det seneste om typer af arbejdsbelastninger - specifikt at forstå, om en arbejdsbelastning er parametriseret, adhoc eller en blanding. Det er en af de ting, vi kigger på under en sundhedsaudit, og Kimberly har en god forespørgsel fra hendes Plan-cache og optimering til adhoc-arbejdsbelastninger, som er en del af vores værktøjskasse. Jeg har kopieret forespørgslen nedenfor, og hvis du aldrig har kørt den mod nogen af dine produktionsmiljøer før, skal du helt sikkert finde lidt tid til at gøre det.
SELECT objtype AS [CacheType],
COUNT_BIG(*) AS [Total Plans],
SUM(CAST(size_in_bytes AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs],
AVG(usecounts) AS [Avg Use Count],
SUM(CAST((CASE WHEN usecounts = 1 THEN size_in_bytes
ELSE 0
END) AS DECIMAL(18, 2))) / 1024 / 1024 AS [Total MBs – USE Count 1],
SUM(CASE WHEN usecounts = 1 THEN 1
ELSE 0
END) AS [Total Plans – USE Count 1]
FROM sys.dm_exec_cached_plans
GROUP BY objtype
ORDER BY [Total MBs – USE Count 1] DESC; Hvis jeg kører denne forespørgsel mod et produktionsmiljø, får vi muligvis output som følgende:
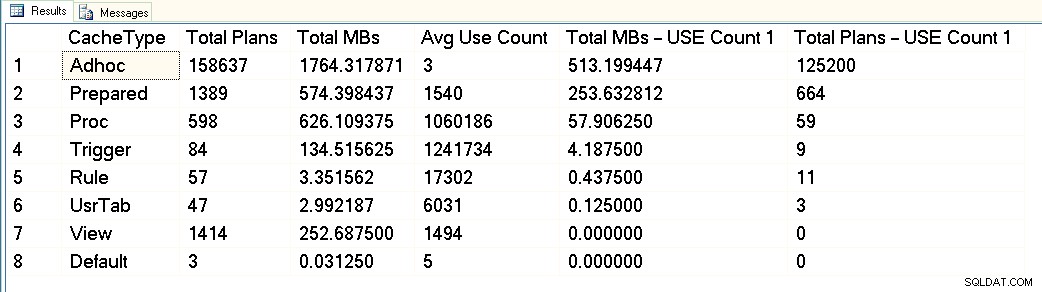
Fra dette skærmbillede kan du se, at vi har omkring 3 GB i alt dedikeret til plancachen, og af det er 1,7 GB til planerne med over 158.000 adhoc-forespørgsler. Af de 1,7 GB bruges cirka 500 MB til 125.000 planer, der udfører ÉN kun tid. Cirka 1 GB af planens cache er til udarbejdede og procedureplaner, og de fylder kun omkring 300 MB plads. Men bemærk det gennemsnitlige brugsantal - langt over 1 million for procedurer. Når jeg ser på dette output, vil jeg kategorisere denne arbejdsbyrde som blandet – nogle parameteriserede forespørgsler, nogle adhoc.
Kimberlys blogindlæg diskuterer muligheder for at administrere en plancache fyldt med en masse adhoc-forespørgsler. Plan cache bloat er bare et problem, du skal kæmpe med, når du har en adhoc-arbejdsbelastning, og i dette indlæg vil jeg undersøge, hvilken effekt det kan have på CPU som et resultat af alle de kompileringer, der skal forekomme. Når en forespørgsel udføres i SQL Server, gennemgår den kompilering og optimering, og der er overhead forbundet med denne proces, som ofte viser sig som CPU-omkostninger. Når en forespørgselsplan er i cachen, kan den genbruges. Forespørgsler, der er parameteriseret, kan ende med at genbruge en plan, der allerede er i cachen, fordi forespørgselsteksten er nøjagtig den samme. Når en adhoc-forespørgsel udføres, genbruger den kun planen i cachen, hvis den har den nøjagtige samme tekst og inputværdi(er) .
Opsætning
Til vores test vil vi generere en tilfældig streng i TSQL og sammenkæde den til en forespørgsel, så hver udførelse har en anden bogstavelig værdi. Jeg har pakket dette ind i en lagret procedure, der kalder forespørgslen ved hjælp af Dynamic String Execution (EXEC @QueryString), så den opfører sig som en adhoc-sætning. At kalde det inde fra en lagret procedure betyder, at vi kan udføre det et kendt antal gange.
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[RandomSelects];
GO
CREATE PROCEDURE dbo.[RandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50));
SELECT @QueryString = N'SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = ''' + @ConcatString + ''';';
EXEC (@QueryString);
SELECT @RowLoop = @RowLoop + 1;
END
GO
DBCC FREEPROCCACHE;
GO
EXEC dbo.[RandomSelects] @NumRows = 10;
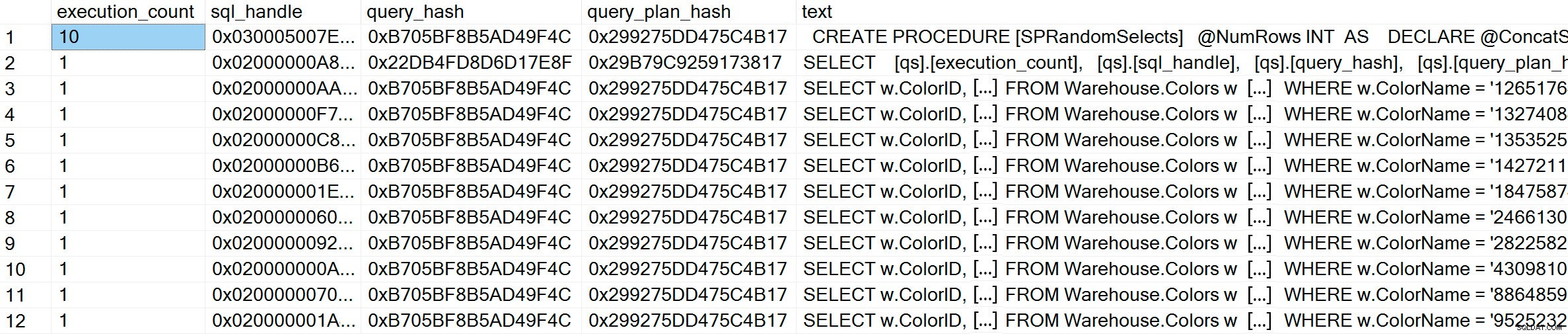
GO Efter eksekvering, hvis vi tjekker planens cache, kan vi se, at vi har 10 unikke poster, hver med en execution_count på 1 (zoom ind på billedet, hvis det er nødvendigt for at se de unikke værdier for prædikatet):
SELECT [qs].[execution_count], [qs].[sql_handle], [qs].[query_hash], [qs].[query_plan_hash], [st].[text] FROM sys.dm_exec_query_stats AS [qs] CROSS APPLY sys.dm_exec_sql_text ([qs].[sql_handle]) AS [st] CROSS APPLY sys.dm_exec_query_plan ([qs].[plan_handle]) AS [qp] WHERE [st].[text] LIKE '%Warehouse%' ORDER BY [st].[text], [qs].[execution_count] DESC; GO

Nu opretter vi en næsten identisk lagret procedure, der udfører den samme forespørgsel, men parametriseret:
USE [WideWorldImporters];
GO
DROP PROCEDURE IF EXISTS dbo.[SPRandomSelects];
GO
CREATE PROCEDURE dbo.[SPRandomSelects]
@NumRows INT
AS
DECLARE @ConcatString NVARCHAR(200);
DECLARE @QueryString NVARCHAR(1000);
DECLARE @RowLoop INT = 0;
WHILE (@RowLoop < @NumRows)
BEGIN
SET @ConcatString = CAST((CONVERT (INT, RAND () * 2500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1000) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 500) + 1) AS NVARCHAR(50))
+ CAST((CONVERT (INT, RAND () * 1500) + 1) AS NVARCHAR(50))
SELECT w.ColorID, s.StockItemName
FROM Warehouse.Colors w
JOIN Warehouse.StockItems s
ON w.ColorID = s.ColorID
WHERE w.ColorName = @ConcatString;
SELECT @RowLoop = @RowLoop + 1;
END
GO
EXEC dbo.[SPRandomSelects] @NumRows = 10;
GO I plan-cachen ser vi, ud over de 10 adhoc-forespørgsler, én indgang for den parameteriserede forespørgsel, der er blevet udført 10 gange. Fordi inputtet er parametriseret, selvom meget forskellige strenge sendes ind i parameteren, er forespørgselsteksten nøjagtig den samme:
Test
Nu hvor vi forstår, hvad der sker i plancachen, lad os skabe mere belastning. Vi vil bruge en kommandolinjefil, der kalder den samme .sql-fil på 10 forskellige tråde, hvor hver fil kalder den lagrede procedure 10.000 gange. Vi rydder planens cache, før vi starter, og fanger Total CPU% og SQL Compilations/sek med PerfMon, mens scripts udføres.
Adhoc.sql-filindhold:
EXEC [WideWorldImporters].dbo.[RandomSelects] @NumRows = 10000;
Parameterized.sql filindhold:
EXEC [WideWorldImporters].dbo.[SPRandomSelects] @NumRows = 10000;
Eksempel på kommandofil (set i Notesblok), der kalder .sql-filen:
Eksempel på kommandofil (set i Notesblok), der opretter 10 tråde, der hver kalder filen Run_Adhoc.cmd:
Efter at have kørt hvert sæt forespørgsler 100.000 gange i alt, hvis vi ser på planens cache, ser vi følgende:

Der er mere end 10.000 adhoc-planer i planens cache. Du undrer dig måske over, hvorfor der ikke er en plan for alle 100.000 adhoc-forespørgsler, der blev udført, og det har at gøre med, hvordan plancachen fungerer (den er størrelse baseret på tilgængelig hukommelse, når ubrugte planer er forældet osv.). Det afgørende er, at så der findes mange adhoc-planer, sammenlignet med hvad vi ser for resten af cachetyperne.
PerfMon-dataene, som er vist nedenfor, er mest sigende. Udførelsen af de 100.000 parametriserede forespørgsler blev fuldført på mindre end 15 sekunder, og der var en lille stigning i Compilations/sek i begyndelsen, som knap kan mærkes på grafen. Det samme antal adhoc-udførelser tog lidt over 60 sekunder at fuldføre, med kompileringer/sek. steg tæt på 2000, før de faldt tættere på 1000 omkring 45 sekunders mærket, med CPU tæt på eller på 100 % i størstedelen af tiden.
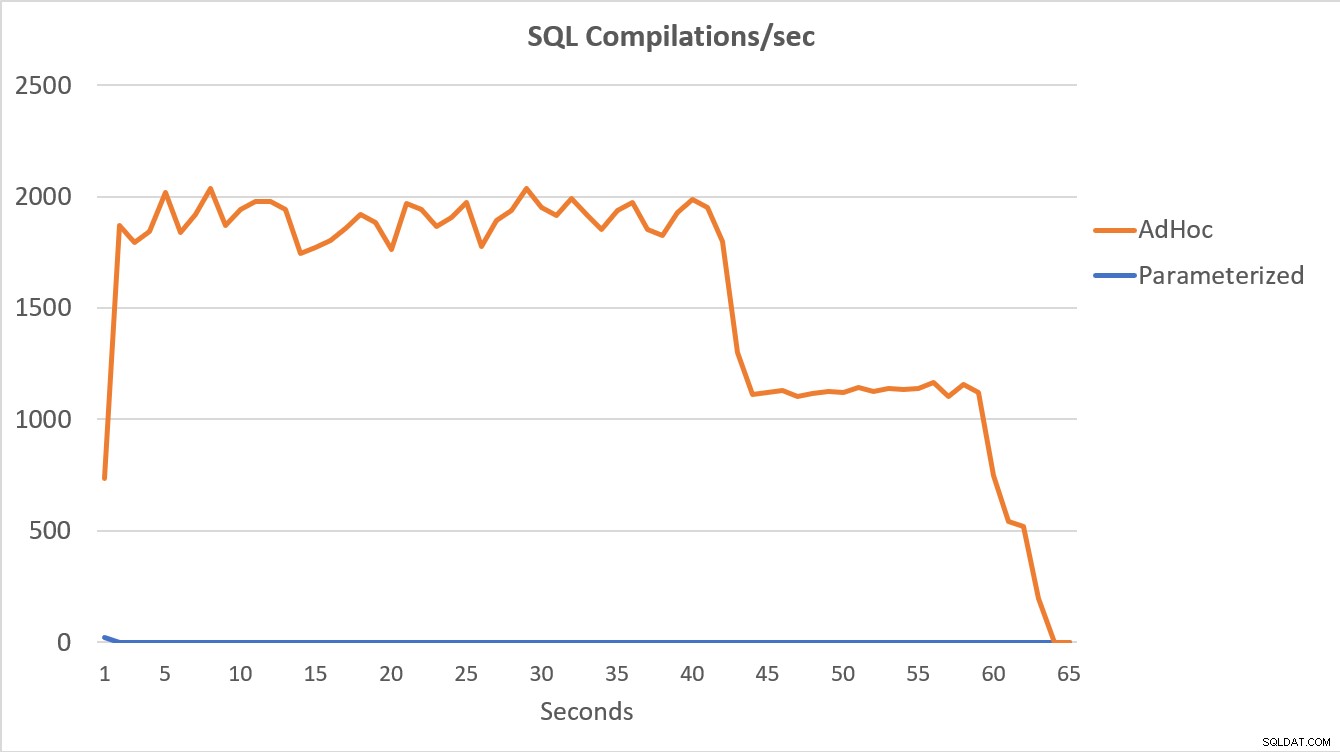
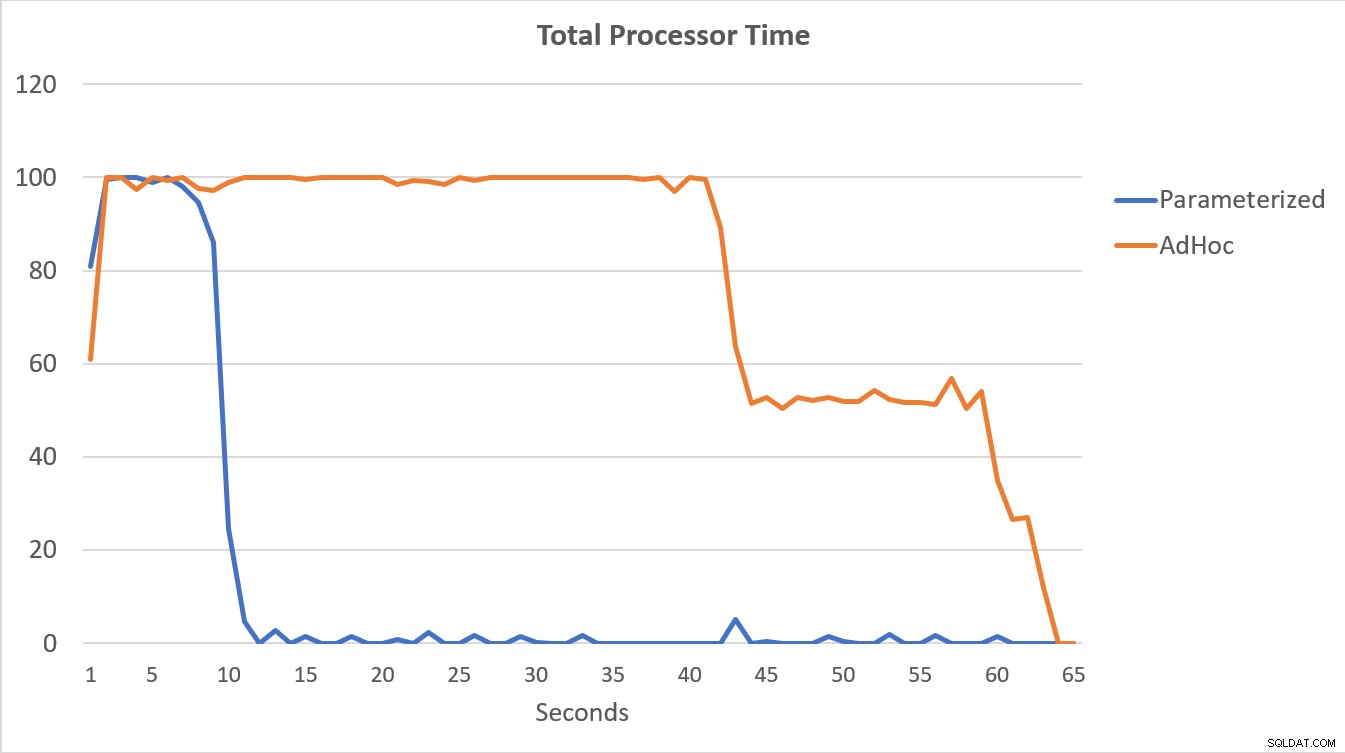
Oversigt
Vores test var ekstremt enkel, idet vi kun indsendte variationer for én adhoc-forespørgsel, hvorimod vi i et produktionsmiljø kunne have hundreder eller tusinder af forskellige variationer for hundrede eller tusinder af forskellige adhoc-forespørgsler. Ydeevnepåvirkningen af disse adhoc-forespørgsler er ikke kun planens cache-bloat, der opstår, selvom kig på plancachen er et godt sted at starte, hvis du ikke er bekendt med den type arbejdsbyrde, du har. En stor mængde adhoc-forespørgsler kan drive kompileringer og derfor CPU, som nogle gange kan maskeres ved at tilføje mere hardware, men der kan absolut komme et punkt, hvor CPU bliver en flaskehals. Hvis du mener, at dette kan være et problem eller potentielt problem i dit miljø, så se efter, hvilke adhoc-forespørgsler, der kører oftest, og se, hvilke muligheder du har for at parametrere dem. Misforstå mig ikke – der er potentielle problemer med parametriserede forespørgsler (f.eks. planstabilitet på grund af dataskævhed), og det er et andet problem, du måske skal arbejde igennem. Uanset din arbejdsbyrde, er det vigtigt at forstå, at der sjældent er en "indstil det og glem det"-metode til kodning, konfiguration, vedligeholdelse osv. SQL Server-løsninger er levende, åndende enheder, der altid ændrer sig og sørger for konstant omsorg og fodring til udføre pålideligt. En af DBA's opgaver er at holde sig på toppen af den forandring og styre ydeevnen bedst muligt - uanset om det er relateret til adhoc eller parameteriserede præstationsudfordringer.