Denne artikel er den anden i en serie om T-SQL-fejl, faldgruber og bedste praksis. Denne gang fokuserer jeg på klassiske fejl, der involverer underforespørgsler. Især dækker jeg substitutionsfejl og logiske problemer med tre værdier. Flere af de emner, som jeg dækker i serien, blev foreslået af andre MVP'ere i en diskussion, vi havde om emnet. Tak til Erland Sommarskog, Aaron Bertrand, Alejandro Mesa, Umachandar Jayachandran (UC), Fabiano Neves Amorim, Milos Radivojevic, Simon Sabin, Adam Machanic, Thomas Grohser, Chan Ming Man og Paul White for dine forslag!
Udskiftningsfejl
For at demonstrere den klassiske substitutionsfejl vil jeg bruge et simpelt kundeordrer-scenarie. Kør følgende kode for at oprette en hjælpefunktion kaldet GetNums og for at oprette og udfylde tabellerne Kunder og Ordrer:
SET NOCOUNT ON;
USE tempdb;
GO
DROP TABLE IF EXISTS dbo.Orders;
DROP TABLE IF EXISTS dbo.Customers;
DROP FUNCTION IF EXISTS dbo.GetNums;
GO
CREATE FUNCTION dbo.GetNums(@low AS BIGINT, @high AS BIGINT) RETURNS TABLE
AS
RETURN
WITH
L0 AS (SELECT c FROM (SELECT 1 UNION ALL SELECT 1) AS D(c)),
L1 AS (SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B),
L2 AS (SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B),
L3 AS (SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B),
L4 AS (SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B),
L5 AS (SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B),
Nums AS (SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5)
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum;
GO
CREATE TABLE dbo.Customers
(
custid INT NOT NULL
CONSTRAINT PK_Customers PRIMARY KEY,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100);
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
customerid INT NOT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (customerid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_customerid ON dbo.Orders(customerid); I øjeblikket har tabellen Kunder 100 kunder med på hinanden følgende kunde-id'er i intervallet 1 til 100. 98 af disse kunder har tilsvarende ordrer i tabellen Ordrer. Kunder med ID 17 og 59 har endnu ikke afgivet nogen ordrer og har derfor ingen tilstedeværelse i ordretabellen.
Du leder kun efter kunder, der har afgivet ordrer, og du forsøger at opnå dette ved at bruge følgende forespørgsel (kald det forespørgsel 1):
SET NOCOUNT OFF; SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT custid FROM dbo.Orders);
Du formodes at få 98 kunder tilbage, men i stedet får du alle 100 kunder, inklusive dem med ID 17 og 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 17 Cust 17 18 Cust 18 ... 58 Cust 58 59 Cust 59 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (100 rows affected)
Kan du finde ud af, hvad der er galt?
For at øge forvirringen skal du undersøge planen for forespørgsel 1 som vist i figur 1.
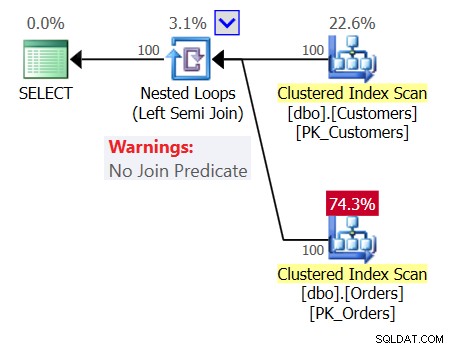 Figur 1:Plan for forespørgsel 1
Figur 1:Plan for forespørgsel 1
Planen viser en Nested Loops (Left Semi Join) operator uden join-prædikat, hvilket betyder, at den eneste betingelse for at returnere en kunde er at have en ikke-tom ordretabel, som om forespørgslen, du skrev, var følgende:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Du forventede sandsynligvis en plan, der ligner den, der er vist i figur 2.
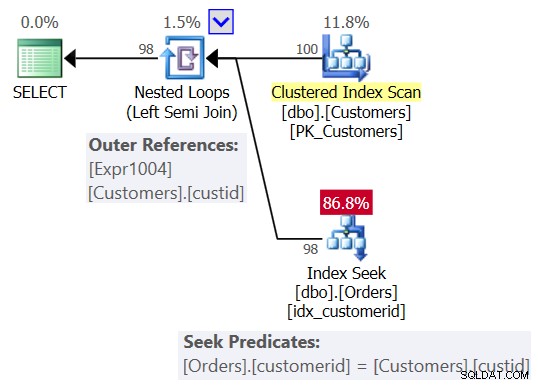 Figur 2:Forventet plan for forespørgsel 1
Figur 2:Forventet plan for forespørgsel 1
I denne plan ser du en Nested Loops (Left Semi Join) operatør med en scanning af det klyngede indeks på kunder som det ydre input og en søgning i indekset på kundeid-kolonnen i ordrerne som det indre input. Du ser også en ydre reference (korreleret parameter) baseret på custid-kolonnen i Customers, og søgeprædikatet Orders.customerid =Customers.custid.
Så hvorfor får du planen i figur 1 og ikke den i figur 2? Hvis du ikke har fundet ud af det endnu, så se nøje på definitionerne af begge tabeller – specifikt kolonnenavnene – og på kolonnenavnene, der bruges i forespørgslen. Du vil bemærke, at tabellen Kunder indeholder kunde-id'er i en kolonne kaldet custid, og at tabellen Ordrer indeholder kunde-id'er i en kolonne kaldet kunde-id. Koden bruger dog custid i både de ydre og indre forespørgsler. Da referencen til custid i den indre forespørgsel er ukvalificeret, skal SQL Server afgøre, hvilken tabel kolonnen kommer fra. Ifølge SQL-standarden er det meningen, at SQL Server skal søge efter kolonnen i tabellen, der søges i samme omfang først, men da der ikke er nogen kolonne kaldet custid i ordrer, skal den så lede efter den i tabellen i den ydre omfang, og denne gang er der match. Så utilsigtet bliver referencen til custid implicit en korreleret reference, som hvis du skrev følgende forespørgsel:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT Customers.custid FROM dbo.Orders);
Forudsat at ordrer ikke er tomme, og at den ydre custid-værdi ikke er NULL (kan ikke være i vores tilfælde, da kolonnen er defineret som NOT NULL), vil du altid få et match, fordi du sammenligner værdien med sig selv . Så forespørgsel 1 bliver ækvivalent til:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders);
Hvis den ydre tabel understøttede NULL'er i custid-kolonnen, ville forespørgsel 1 have svaret til:
SELECT custid, companyname FROM dbo.Customers WHERE EXISTS (SELECT * FROM dbo.Orders) AND custid IS NOT NULL;
Nu forstår du, hvorfor forespørgsel 1 blev optimeret med planen i figur 1, og hvorfor du fik alle 100 kunder tilbage.
For noget tid siden besøgte jeg en kunde, der havde en lignende fejl, men desværre med en DELETE-erklæring. Tænk et øjeblik, hvad det betyder. Alle tabelrækker blev slettet og ikke kun dem, som de oprindeligt havde til hensigt at slette!
Med hensyn til bedste praksis, der kan hjælpe dig med at undgå sådanne fejl, er der to primære. Først, så meget som du kan kontrollere det, skal du sørge for at bruge konsistente kolonnenavne på tværs af tabeller for attributter, der repræsenterer det samme. For det andet skal du sørge for, at du angiver kvalificerende kolonnereferencer i underforespørgsler, herunder i selvstændige, hvor dette ikke er almindelig praksis. Selvfølgelig kan du bruge tabelalias, hvis du helst ikke vil bruge fulde tabelnavne. Hvis du anvender denne praksis på vores forespørgsel, antag, at dit første forsøg brugte følgende kode:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.custid FROM dbo.Orders AS O);
Her tillader du ikke implicit opløsning af kolonnenavne, og derfor genererer SQL Server følgende fejl:
Msg 207, Level 16, State 1, Line 108 Invalid column name 'custid'.
Du går og tjekker metadataene for tabellen Ordrer, indser, at du brugte det forkerte kolonnenavn, og retter forespørgslen (kald denne forespørgsel 2), sådan:
SELECT custid, companyname FROM dbo.Customers WHERE custid IN (SELECT O.customerid FROM dbo.Orders AS O);
Denne gang får du det rigtige output med 98 kunder, eksklusive kunder med ID 17 og 59:
custid companyname ------- ------------ 1 Cust 1 2 Cust 2 3 Cust 3 ... 16 Cust 16 18 Cust 18 .. 58 Cust 58 60 Cust 60 ... 98 Cust 98 99 Cust 99 100 Cust 100 (98 rows affected)
Du får også den forventede plan vist tidligere i figur 2.
Som en sidebemærkning er det tydeligt, hvorfor Customers.custid er en ydre reference (korreleret parameter) i operatøren Nested Loops (Left Semi Join) i figur 2. Hvad der er mindre indlysende er, hvorfor Expr1004 også vises i planen som en ydre reference. Fellow SQL Server MVP Paul White teoretiserer, at det kunne være relateret til at bruge information fra det ydre inputs blad til at antyde lagermotoren for at undgå duplikeret indsats fra read-ahead-mekanismerne. Du kan finde detaljerne her.
Logikproblemer med tre værdier
En almindelig fejl, der involverer underforespørgsler, har at gøre med tilfælde, hvor den ydre forespørgsel bruger NOT IN-prædikatet, og underforespørgslen potentielt kan returnere NULLs blandt sine værdier. Antag for eksempel, at du skal kunne gemme ordrer i vores ordretabel med et NULL som kunde-id. Et sådant tilfælde vil repræsentere en ordre, der ikke er forbundet med nogen kunde; for eksempel en ordre, der kompenserer for uoverensstemmelser mellem faktiske produktoptællinger og optællinger registreret i databasen.
Brug følgende kode til at genskabe ordretabellen med custid-kolonnen, der tillader NULL-værdier, og foreløbig udfyld den med de samme eksempeldata som før (med ordrer efter kunde-id'er 1 til 100, ekskl. 17 og 59):
DROP TABLE IF EXISTS dbo.Orders;
GO
CREATE TABLE dbo.Orders
(
orderid INT NOT NULL IDENTITY
CONSTRAINT PK_Orders PRIMARY KEY,
custid INT NULL,
filler BINARY(100) NOT NULL -- representing other columns
CONSTRAINT DFT_Orders_filler DEFAULT(0x)
);
INSERT INTO dbo.Orders WITH (TABLOCK) (custid)
SELECT
C.n AS customerid
FROM dbo.GetNums(1, 10000) AS O
CROSS JOIN dbo.GetNums(1, 100) AS C
WHERE C.n NOT IN(17, 59);
CREATE INDEX idx_custid ON dbo.Orders(custid); Bemærk, at mens vi er i gang, fulgte jeg den bedste praksis, der blev diskuteret i det foregående afsnit, for at bruge konsistente kolonnenavne på tværs af tabeller for de samme attributter, og navngav kolonnen i ordretabellen custid ligesom i tabellen Kunder.
Antag, at du skal skrive en forespørgsel, der returnerer kunder, der ikke har afgivet ordrer. Du kommer med følgende forenklede løsning ved at bruge NOT IN-prædikatet (kald det forespørgsel 3, første udførelse):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Denne forespørgsel returnerer det forventede output med kunder 17 og 59:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Der foretages en opgørelse på virksomhedens lager, og der findes en uoverensstemmelse mellem den faktiske mængde af et produkt og den mængde, der er registreret i databasen. Så du tilføjer en dummy-kompenserende ordre for at tage højde for inkonsekvensen. Da der ikke er nogen faktisk kunde tilknyttet ordren, bruger du et NULL som kunde-id. Kør følgende kode for at tilføje en sådan ordreheader:
INSERT INTO dbo.Orders(custid) VALUES(NULL);
Kør forespørgsel 3 for anden gang:
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O);
Denne gang får du et tomt resultat:
custid companyname ------- ------------ (0 rows affected)
Det er klart, at der er noget galt. Du ved, at kunder 17 og 59 ikke afgav nogen ordrer, og de vises faktisk i tabellen Kunder, men ikke i tabellen Ordrer. Alligevel hævder forespørgselsresultatet, at der ikke er nogen kunde, der ikke har afgivet nogen ordre. Kan du finde ud af, hvor fejlen er, og hvordan den rettes?
Fejlen har selvfølgelig at gøre med NULL i tabellen Ordrer. For at SQL er en NULL en markør for en manglende værdi, der kunne repræsentere en relevant kunde. SQL ved ikke, at for os repræsenterer NULL en manglende og uanvendelig (irrelevant) kunde. For alle kunder i Kunder-tabellen, der er til stede i Ordrer-tabellen, finder IN-prædikatet et match, der giver TRUE, og NOT IN-delen gør det til FALSK, derfor kasseres kunderækken. Så langt så godt. Men for kunder 17 og 59 giver IN-prædikatet UNKENDT, da alle sammenligninger med ikke-NULL-værdier giver FALSE, og sammenligningen med NULL giver UNKNOWN. Husk, SQL antager, at NULL kan repræsentere enhver relevant kunde, så den logiske værdi UNKNOWN indikerer, at det er ukendt, om det ydre kunde-id er lig med det indre NULL-kunde-id. FALSK ELLER FALSK … ELLER UKENDT er UKENDT. Så den NOT IN-del, der er anvendt på UNKNOWN, giver stadig UNKNOWN.
I enklere engelske termer bad du om at returnere kunder, der ikke afgav ordrer. Så naturligvis kasserer forespørgslen alle kunder fra tabellen Kunder, der er til stede i ordretabellen, fordi det med sikkerhed vides, at de har afgivet ordrer. Med hensyn til resten (17 og 59 i vores tilfælde) kasserer forespørgslen dem siden til SQL, ligesom det er ukendt, om de har afgivet ordre, det er lige så ukendt, om de ikke har afgivet ordrer, og filteret har brug for sikkerhed (TRUE) i for at returnere en række. Hvilken pickle!
Så så snart den første NULL kommer ind i ordretabellen, får du fra det øjeblik altid et tomt resultat tilbage fra NOT IN-forespørgslen. Hvad med tilfælde, hvor du faktisk ikke har NULL'er i dataene, men kolonnen tillader NULL'er? Som du så i den første udførelse af forespørgsel 3, får du i et sådant tilfælde det korrekte resultat. Måske tænker du, at applikationen aldrig vil introducere NULLs i dataene, så der er ikke noget for dig at bekymre dig om. Det er en dårlig praksis af et par grunde. For det første, hvis en kolonne er defineret som at tillade NULL'er, er det stort set en sikkerhed, at NULL'erne i sidste ende vil komme dertil, selvom de ikke skal; det er bare et spørgsmål om tid. Det kan være resultatet af import af dårlige data, en fejl i applikationen og andre årsager. For en anden, selvom dataene ikke indeholder NULL'er, hvis kolonnen tillader dem, skal optimeringsværktøjet tage højde for muligheden for, at NULL'er vil være til stede, når den opretter forespørgselsplanen, og i vores NOT IN-forespørgsel medfører dette en præstationsstraf . For at demonstrere dette skal du overveje planen for den første udførelse af forespørgsel 3, før du tilføjede rækken med NULL, som vist i figur 3.
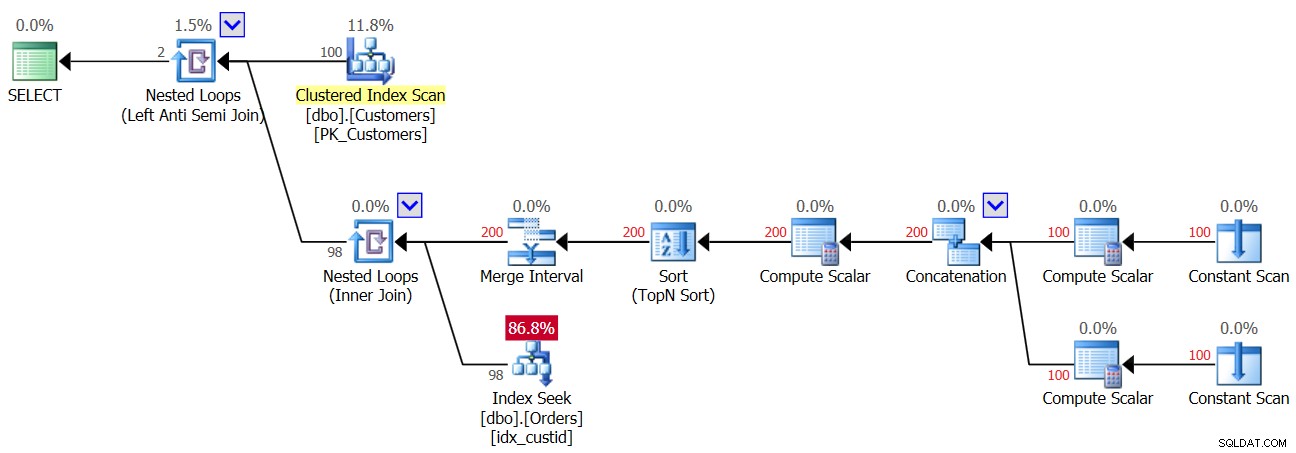 Figur 3:Plan for første udførelse af forespørgsel 3
Figur 3:Plan for første udførelse af forespørgsel 3
Den øverste Nested Loops-operatør håndterer Left Anti Semi Join-logikken. Det handler i bund og grund om at identificere ikke-matches og kortslutte den indre aktivitet, så snart en match er fundet. Den ydre del af løkken trækker alle 100 kunder fra kundetabellen, og derfor bliver den indre del af løkken udført 100 gange.
Den indre del af den øverste løkke udfører en Nested Loops (Inner Join) operator. Den ydre del af den nederste løkke opretter to rækker pr. kunde - én for et NULL-tilfælde og en anden for det aktuelle kunde-id, i denne rækkefølge. Lad ikke operatøren Merge Interval forvirre dig. Det bruges normalt til at flette overlappende intervaller, f.eks. bliver et prædikat som col1 MELLEM 20 OG 30 ELLER col1 MELLEM 25 OG 35 konverteret til col1 MELLEM 20 OG 35. Denne idé kan generaliseres for at fjerne dubletter i et IN-prædikat. I vores tilfælde kan der ikke rigtig være nogen dubletter. I forenklede termer, som nævnt, tænk på den ydre del af løkken som at skabe to rækker pr. kunde – den første for et NULL-case, og den anden for det aktuelle kunde-id. Så laver den indre del af løkken først en søgning i indekset idx_custid på ordrer for at lede efter en NULL. Hvis en NULL findes, aktiverer den ikke den anden søgning efter det aktuelle kunde-id (husk kortslutningen, der håndteres af den øverste Anti Semi Join-løkke). I et sådant tilfælde kasseres den ydre kunde. Men hvis en NULL ikke findes, aktiverer den nederste løkke en anden søgning for at lede efter det aktuelle kunde-id i ordrer. Hvis den findes, kasseres den ydre kunde. Hvis den ikke findes, returneres den ydre kunde. Hvad dette betyder er, at når NULL'er ikke er til stede i ordrer, udfører denne plan to søgninger pr. kunde! Dette kan observeres i planen som antallet af rækker 200 i den ydre input af bundløkken. Følgelig er her de I/O-statistikker, der rapporteres for den første udførelse:
Table 'Orders'. Scan count 200, logical reads 603
Planen for den anden udførelse af forespørgsel 3, efter at en række med en NULL blev tilføjet til ordretabellen, er vist i figur 4.
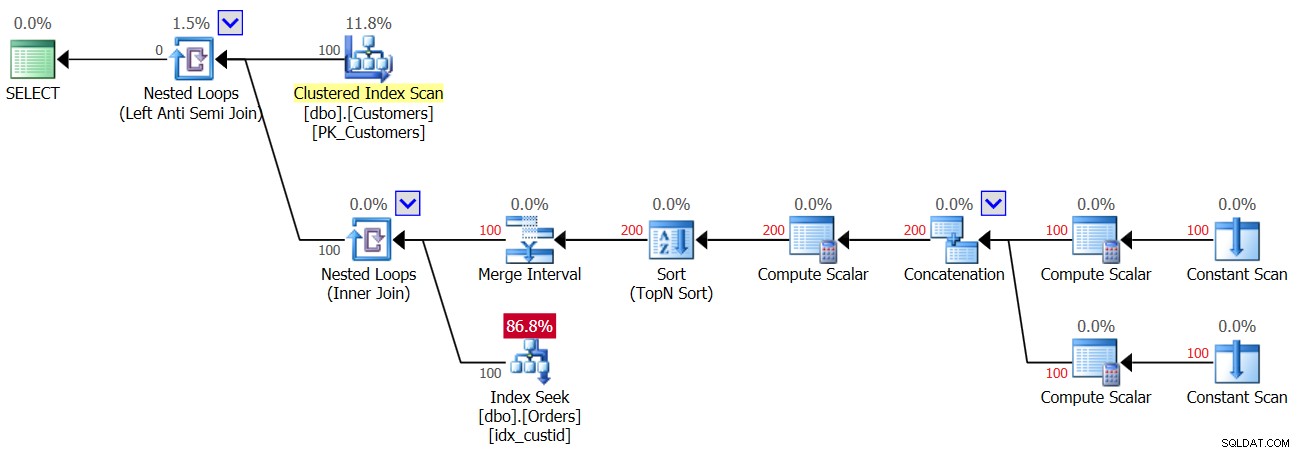 Figur 4:Plan for anden udførelse af forespørgsel 3
Figur 4:Plan for anden udførelse af forespørgsel 3
Da en NULL er til stede i tabellen for alle kunder, finder den første udførelse af Index Seek-operatøren et match, og derfor bliver alle kunder kasseret. Så yay, vi laver kun én søgning pr. kunde og ikke to, så denne gang får du 100 søgninger og ikke 200; men det betyder samtidig, at du får et tomt resultat tilbage!
Her er I/O-statistikken, der rapporteres for den anden udførelse:
Table 'Orders'. Scan count 100, logical reads 300
En løsning på denne opgave, når NULL'er er mulige blandt de returnerede værdier i underforespørgslen, er simpelthen at filtrere dem fra, som sådan (kald det Løsning 1/Forespørgsel 4):
SELECT custid, companyname FROM dbo.Customers WHERE custid NOT IN (SELECT O.custid FROM dbo.Orders AS O WHERE O.custid IS NOT NULL);
Denne kode genererer det forventede output:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Ulempen ved denne løsning er, at du skal huske at tilføje filteret. Jeg foretrækker en løsning, der bruger NOT EXISTS-prædikatet, hvor underforespørgslen har en eksplicit korrelation, der sammenligner ordrens kunde-id med kundens kunde-id, som sådan (kald det Løsning 2/Forespørgsel 5):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE NOT EXISTS (SELECT * FROM dbo.Orders AS O WHERE O.custid = C.custid);
Husk, at en lighedsbaseret sammenligning mellem en NULL og hvad som helst giver UNKNOWN, og UNKNOWN bliver kasseret af et WHERE-filter. Så hvis NULL'er findes i ordrer, bliver de elimineret af den indre forespørgsels filter, uden at du behøver at tilføje eksplicit NULL-behandling, og du behøver derfor ikke bekymre dig om, hvorvidt NULL'er findes eller ikke findes i dataene.
Denne forespørgsel genererer det forventede output:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Planerne for begge løsninger er vist i figur 5.
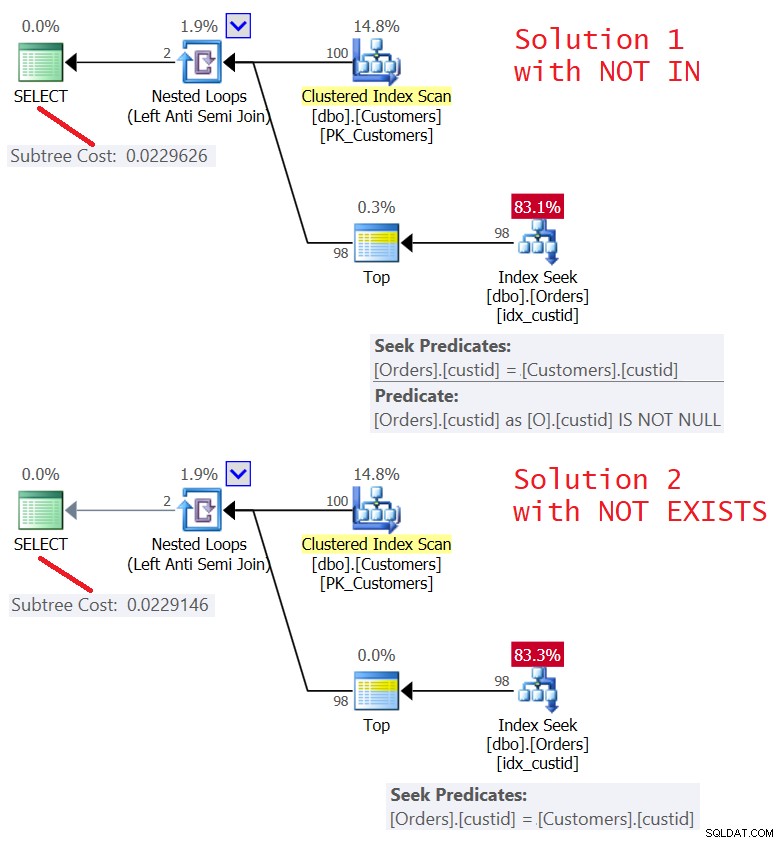 Figur 5:Planer for forespørgsel 4 (løsning 1) og forespørgsel 5 (løsning 2) )
Figur 5:Planer for forespørgsel 4 (løsning 1) og forespørgsel 5 (løsning 2) )
Som du kan se, er planerne næsten identiske. De er også ret effektive ved at bruge en Left Semi Join-optimering med en kortslutning. Begge udfører kun 100 søgninger i indekset idx_custid på ordrer, og med Top-operatoren påføres en kortslutning, efter at en række er berørt i bladet.
I/O-statistikken for begge forespørgsler er den samme:
Table 'Orders'. Scan count 100, logical reads 348
En ting at overveje er dog, om der er nogen chance for, at den ydre tabel har NULLs i den korrelerede kolonne (custid i vores tilfælde). Det er meget usandsynligt, at det er relevant i et scenario som kundeordrer, men det kan være relevant i andre scenarier. Hvis det faktisk er tilfældet, håndterer begge løsninger en ydre NULL forkert.
For at demonstrere dette skal du slippe og genskabe kundetabellen med et NULL som et af kunde-id'erne ved at køre følgende kode:
DROP TABLE IF EXISTS dbo.Customers;
GO
CREATE TABLE dbo.Customers
(
custid INT NULL
CONSTRAINT UNQ_Customers_custid UNIQUE CLUSTERED,
companyname VARCHAR(50) NOT NULL
);
INSERT INTO dbo.Customers WITH (TABLOCK) (custid, companyname)
SELECT CAST(NULL AS INT) AS custid, 'Cust NULL' AS companyname
UNION ALL
SELECT n AS custid, CONCAT('Cust ', CAST(n AS VARCHAR(10))) AS companyname
FROM dbo.GetNums(1, 100); Løsning 1 returnerer ikke en ydre NULL, uanset om en indre NULL er til stede eller ej.
Løsning 2 vil returnere en ydre NULL, uanset om en indre NULL er til stede eller ej.
Hvis du ønsker at håndtere NULL-værdier, som du håndterer ikke-NULL-værdier, dvs. returnere NULL-værdien, hvis den er til stede i Kunder, men ikke i Ordrer, og ikke returnere den, hvis den findes i begge, skal du ændre løsningens logik for at bruge en distinctness -baseret sammenligning i stedet for en ligestillingsbaseret sammenligning. Dette kan opnås ved at kombinere EXISTS-prædikatet og EXCEPT set-operatoren på samme måde (kald denne løsning 3/forespørgsel 6):
SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Da der i øjeblikket er NULL i både kunder og ordrer, returnerer denne forespørgsel korrekt ikke NULL. Her er forespørgselsoutputtet:
custid companyname ------- ------------ 17 Cust 17 59 Cust 59 (2 rows affected)
Kør følgende kode for at fjerne rækken med NULL fra ordretabellen, og kør løsning 3 igen:
DELETE FROM dbo.Orders WHERE custid IS NULL; SELECT C.custid, C.companyname FROM dbo.Customers AS C WHERE EXISTS (SELECT C.custid EXCEPT SELECT O.custid FROM dbo.Orders AS O);
Denne gang, da en NULL er til stede i kunder, men ikke i ordrer, inkluderer resultatet NULL:
custid companyname ------- ------------ NULL Cust NULL 17 Cust 17 59 Cust 59 (3 rows affected)
Planen for denne løsning er vist i figur 6:
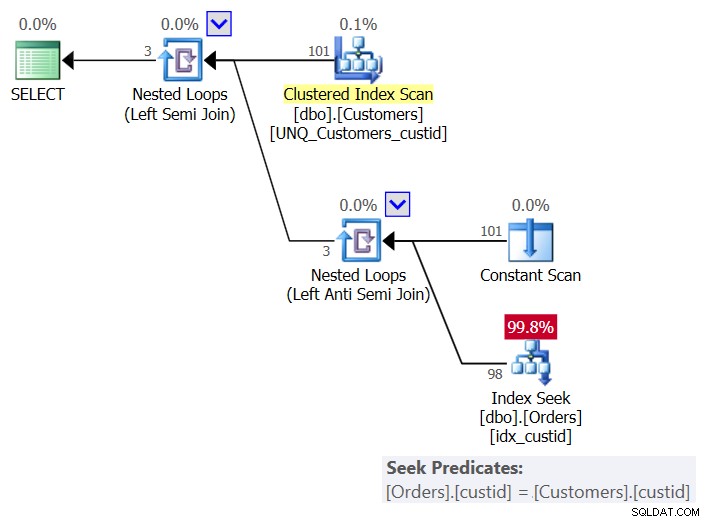 Figur 6:Plan for forespørgsel 6 (løsning 3)
Figur 6:Plan for forespørgsel 6 (løsning 3)
Per kunde bruger planen en konstant scanningsoperator til at oprette en række med den aktuelle kunde og anvender en enkelt søgning i indekset idx_custid på ordrer for at kontrollere, om kunden findes i ordrer. Du ender med én søgning pr. kunde. Da vi i øjeblikket har 101 kunder i tabellen, får vi 101 søgninger.
Her er I/O-statistikken for denne forespørgsel:
Table 'Orders'. Scan count 101, logical reads 415
Konklusion
Denne måned dækkede jeg underforespørgsler-relaterede fejl, faldgruber og bedste praksis. Jeg dækkede substitutionsfejl og logiske problemer med tre værdier. Husk at bruge konsistente kolonnenavne på tværs af tabeller og altid tabelkvalificerende kolonner i underforespørgsler, selv når de er selvstændige. Husk også at håndhæve en NOT NULL-begrænsning, når kolonnen ikke skal tillade NULLs, og at altid tage NULLs i betragtning, når de er mulige i dine data. Sørg for at inkludere NULL i dine eksempeldata, når de er tilladt, så du nemmere kan fange fejl i din kode, når du tester den. Vær forsigtig med NOT IN-prædikatet, når det kombineres med underforespørgsler. Hvis NULL'er er mulige i den indre forespørgsels resultat, er NOT EXISTS-prædikatet normalt det foretrukne alternativ.