Introduktion
I SQL Server 2012 var grupperet (vektor) aggregering i stand til at bruge parallel batch-mode-udførelse, men kun for den delvise (per-thread) aggregat. Det tilknyttede globale aggregat kørte altid i rækketilstand efter en Ompartitionsstrømme udveksling.
SQL Server 2014 tilføjede muligheden for at udføre parallel batch-tilstand grupperet aggregering inden for et enkelt Hash Match Aggregate operatør. Dette eliminerede unødvendig rækketilstandsbehandling og fjernede behovet for en udveksling.
SQL Server 2016 introducerede seriel batch-tilstandsbehandling og samlet pushdown . Når pushdown lykkes, udføres aggregering i Søjlelagerscanningen operatøren selv, muligvis opererer direkte på komprimerede data og drager fordel af SIMD CPU-instruktioner.
De mulige præstationsforbedringer med samlet pushdown kan være meget betydelige. Dokumentationen angiver nogle af de betingelser, der kræves for at opnå pushdown, men der er tilfælde, hvor manglen på "lokalt aggregerede rækker" ikke kan forklares fuldt ud ud fra disse detaljer alene.
Denne artikel dækker yderligere faktorer, der påvirker samlet pushdown for GROUP BY kun forespørgsler . Skalær aggregeret pushdown (sammenlægning uden en GROUP BY klausul), filter pushdown og udtryk pushdown kan blive dækket i et fremtidigt indlæg.
Søjlelagerlager
Den første ting at sige er, at samlet pushdown kun gælder for komprimerede data, så rækker i et deltalager er ikke berettigede. Ud over det kan pushdown afhænge af den anvendte type kompression. For at forstå dette er det nødvendigt først at gennemgå, hvordan columnstore-lagring fungerer på et højt niveau:
En komprimeret rækkegruppe indeholder et kolonnesegment for hver kolonne. De rå kolonneværdier er kodede i et 4-byte eller 8-byte heltal ved hjælp af værdi eller ordbog kodning.
Værdikodning kan reducere antallet af bits, der kræves til lagring, ved at oversætte råværdier ved hjælp af en basisoffset- og størrelsesmodifikator. For eksempel kan værdierne {1100, 1200, 1300} lagres som (0, 1, 2) ved først at skalere med en faktor på 0,01 for at give {11, 12, 13}, og derefter rebasere ved 11 for at give {0, 1, 2}.
Ordbogskodning bruges, når der er duplikerede værdier. Det kan bruges med ikke-numeriske data. Hver unik værdi gemmes i en ordbog og tildeles et heltals-id. Segmentdataene refererer så til id-numre i ordbogen i stedet for de originale værdier.
Efter kodning kan segmentdata blive yderligere komprimeret ved hjælp af run-length encoding (RLE) og bit-packing:
RLE erstatter gentagne elementer med dataene og antallet af gentagelser, for eksempel kunne {1, 1, 1, 1, 1, 2, 2, 2} erstattes med {5×1, 3×2}. RLE pladsbesparelser øges med længden af de gentagne kørsler. Korte løbeture kan være kontraproduktive.
Bit-pakning gemmer den binære form af dataene i et så snævert fælles vindue som muligt. For eksempel er tallene {7, 9, 15} gemt i binære (single-byte for space) heltal som {00000111, 00001001, 00001111}. Pakning af disse bits i et fast fire-bit vindue giver streamen {011110011111}. At vide, at der er en fast vinduesstørrelse, betyder, at der ikke er behov for en afgrænsning.
Kodning og komprimering er separate trin, så RLE og bit-packing anvendes på resultatet af værdikodning eller ordbogskodning af rådata. Yderligere kan data inden for det samme kolonnesegment have en blanding af RLE og bitpakningskompression. RLE-komprimerede data kaldes rene , og bitpakkede komprimerede data kaldes urene . Et kolonnesegment kan indeholde både rene og urene data.
De pladsbesparelser, der kan opnås gennem kodning og komprimering, kan afhænge af bestilling. Alle kolonnesegmenter i en rækkegruppe skal implicit sorteres på samme måde, så SQL Server effektivt kan rekonstruere komplette rækker fra kolonnesegmenterne. At vide, at række 123 er gemt på samme position (123) i hvert kolonnesegment, betyder, at rækkenummeret ikke skal gemmes.
En ulempe ved dette arrangement er, at en almindelig sorteringsrækkefølge skal vælges for alle kolonnesegmenter i en rækkegruppe. En bestemt bestilling passer måske meget godt til én kolonne, men går glip af betydelige muligheder i andre kolonner. Dette er tydeligst tilfældet med RLE-kompression. SQL Server bruger Vertipaq-teknologi til at bestemme en god måde at sortere kolonner i hver rækkegruppe på for at give et godt samlet komprimeringsresultat.
SQL Server bruger i øjeblikket kun RLE inden for et kolonnesegment, når der er minimum 64 sammenhængende gentagne værdier. De resterende værdier i segmentet er bitpakkede. Som nævnt afhænger om gentagne værdier vises som sammenhængende i et kolonnesegment af den valgte rækkefølge for rækkegruppen.
SQL Server understøtter specialiseret SIMD bitudpakning for bitbredder fra 1 til 10 inklusive, 12 og 21 bit. SQL Server kan også bruge standard heltalstørrelser f.eks. 16, 32 og 64 bit med bit-pakning. Disse tal er valgt, fordi de passer godt i en 64-bit enhed. For eksempel kan en enhed indeholde tre 21-bit underenheder eller 5 12-bit underenheder. SQL Server ikke krydse en 64-bit grænse ved pakning af bits.
SIMD bruger 256-bit registre, når processoren understøtter AVX2-instruktioner, og 128-bit-registre, når SSE4.2-instruktioner er tilgængelige. Ellers kan ikke-SIMD-udpakning bruges.
Grupperte samlede pushdown-betingelser
De fleste planer med et Hash Match Aggregate operatør direkte over en Columnstore Scan operatør vil potentielt kvalificere sig til grupperet samlet pushdown, underlagt de generelle betingelser, der er angivet i dokumentationen.
Ekstra filtre og udtryk kan også nogle gange tilføjes uden at forhindre grupperet aggregeret pushdown. Den generelle regel er, at filteret eller udtrykket også skal kunne pushdown (selvom kompatible udtryk stadig kan forekomme i en separat Compute Scalar ). Som nævnt i indledningen kan disse aspekter blive dækket i detaljer i separate artikler.
Der er i øjeblikket intet i udførelsesplanerne, der indikerer, om et bestemt aggregat blev betragtet som generelt kompatibelt med grupperet aggregeret pushdown eller ej. Stadig, når planen generelt kvalificerer for grupperet samlet pushdown er både pushdown (hurtig) og ikke-pushdown (langsom) kodestier gjort tilgængelige.
Hver scanningsoutputbatch (på op til 900 rækker) træffer en runtime-beslutning mellem de hurtige og langsomme kodestier. Denne fleksibilitet gør det muligt for så mange partier som muligt at drage fordel af pushdown. I værste fald vil ingen batches bruge den hurtige sti under kørsel, på trods af en 'generelt kompatibel' plan.
Udførelsesplanen viser resultatet af fast-path pushdown-behandling som 'lokalt aggregerede rækker' uden tilsvarende rækkeoutput fra scanningen. Langsom sti-batches vises som outputrækker fra kolonnelagerscanningen som sædvanlig, med aggregeringen udført af en separat operatør i stedet for ved scanningen.
En enkelt grupperet aggregat- og scanningskombination kan sende nogle batches ned ad den hurtige sti og nogle ned ad den langsomme sti, så det er perfekt muligt at se nogle, men ikke alle, rækker lokalt aggregeret. Når grupperet samlet pushdown er vellykket, indeholder hver outputbatch fra scanningen grupperingsnøgler og en delvis aggregation, der repræsenterer de rækker, der bidrager.
Detaljerede kontroller
Der er en række runtime-tjek for at afgøre, om pushdown-behandling kan bruges. Blandt de let dokumenterede kontroller er:
- Der må ikke være mulighed for samlet overløb .
- Enhver uren (bitpakkede) grupperingsnøgler må ikke bredere end 10 bit . Rene (RLE-kodede) grupperingsnøgler behandles som havende en uren bredde på nul, så disse udgør normalt få forhindringer.
- Pushdown-behandling skal fortsat anses for at være umværdigt , ved hjælp af en 'fordelsmål', der opdateres i slutningen af hver outputbatch.
Muligheden for samlet overløb vurderes konservativt for hver batch baseret på typen af aggregat, resultatdatatype, aktuelle partielle aggregeringsværdier og information om inputdata. SQL Server kender f.eks. minimum- og maksimumværdier fra segmentmetadata som eksponeret i DMV sys.column_store_segments . Hvor der er risiko for overløb, vil partiet bruge langsom vejbehandling. Dette er for det meste en risiko for SUM samlet.
Begrænsningen for uren grupperingsnøglebredde er værd at fremhæve. Det gælder kun for kolonner i GROUP BY klausuler, der faktisk anvendes i udførelsesplanen som grundlag for gruppering. Disse sæt er ikke altid helt ens, fordi optimeringsværktøjet har frihed til at fjerne overflødige grupperingskolonner eller på anden måde omskrive aggregater, så længe de endelige forespørgselsresultater er garanteret at matche den oprindelige forespørgselsspecifikation. Hvor der er ulighed, er det grupperingskolonnerne vist i udførelsesplanen, der betyder noget.
Den største vanskelighed er at vide, om nogen af grupperingskolonnerne er gemt ved hjælp af bit-pakning, og i så fald hvilken bredde der blev brugt. Det ville også være nyttigt at vide, hvor mange værdier der blev kodet ved hjælp af RLE. Disse oplysninger kan være i column_store_segments DMV, men det er ikke tilfældet i dag. Så vidt jeg ved, er der ingen dokumenteret måde lige nu at få bit-packing og RLE information fra metadata. Det efterlader os med at lede efter udokumenterede alternativer.
Sådan finder du RLE- og bitpakningsoplysninger
Den udokumenterede DBCC CSINDEX kan give os de oplysninger, vi har brug for. Sporingsflag 3604 skal være slået til, for at denne kommando kan producere output på fanen SSMS-meddelelser. Givet information om det kolonnesegment, vi er interesseret i, returnerer denne kommando:
- Segment attributter (svarende til
column_store_segments) - RLE-oplysninger
- Bogmærker til RLE-data
- Bitpack-oplysninger
At være udokumenteret, er der et par særheder (såsom at skulle tilføje en til kolonne-id'er for klyngede kolonnelager, men ikke ikke-klyngede kolonnelager), og endda et par mindre fejl. Du bør ikke bruge det på andet end et personligt testsystem. Forhåbentlig vil der en dag blive leveret en understøttet metode til at få adgang til disse data i stedet.
Eksempler
Den bedste måde at vise DBCC CSINDEX på og demonstrere de pointer, der er fremsat hidtil i denne tekst, er at arbejde gennem nogle eksempler. De scripts, der følger, antager, at der er en tabel kaldet dbo.Numbers i den aktuelle database, der indeholder heltal fra 1 til mindst 16.384. Her er et script til at skabe min standardversion af denne tabel med ti millioner heltal:
IF OBJECT_ID(N'dbo.Numbers', N'U') IS NOT NULL
BEGIN
DROP TABLE dbo.Numbers;
END;
GO
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1
)
SELECT
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten AS T10
CROSS JOIN Ten AS T100
CROSS JOIN Ten AS T1000
CROSS JOIN Ten AS T10000
CROSS JOIN Ten AS T100000
CROSS JOIN Ten AS T1000000
CROSS JOIN Ten AS T10000000
ORDER BY n
OFFSET 0 ROWS
FETCH FIRST 10 * 1000 * 1000 ROWS ONLY
OPTION
(MAXDOP 1);
GO
ALTER TABLE dbo.Numbers
ADD CONSTRAINT [PK dbo.Numbers n]
PRIMARY KEY CLUSTERED (n)
WITH
(
SORT_IN_TEMPDB = ON,
MAXDOP = 1,
FILLFACTOR = 100
);
Eksemplerne bruger alle den samme grundlæggende testtabel:Den første kolonne c1 indeholder et unikt nummer for hver række. Den anden kolonne c2 er udfyldt med et antal dubletter for hver af et lille antal forskellige værdier.
Et klynget kolonnelagerindeks oprettes efter datapopulation, så alle testdata ender i en enkelt komprimeret rækkegruppe (ingen deltalager). Det er bygget til at erstatte et b-træ klynget indeks på kolonne c2 at tilskynde VertiPaq-algoritmen til at overveje nytten af at sortere på den kolonne tidligt. Dette er den grundlæggende testopsætning:
USE Sandpit;
GO
DROP TABLE IF EXISTS dbo.Test;
GO
CREATE TABLE dbo.Test
(
c1 integer NOT NULL,
c2 integer NOT NULL
);
GO
DECLARE
@values integer = 512,
@dupes integer = 63;
INSERT dbo.Test
(c1, c2)
SELECT
N.n,
N.n % @values
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND @values * @dupes;
GO
-- Encourage VertiPaq
CREATE CLUSTERED INDEX CCSI ON dbo.Test (c2);
GO
CREATE CLUSTERED COLUMNSTORE INDEX CCSI
ON dbo.Test
WITH (MAXDOP = 1, DROP_EXISTING = ON);
De to variable er for antallet af forskellige værdier, der skal indsættes i kolonne c2 , og antallet af dubletter for hver af disse værdier.
Testforespørgslen er en meget enkel grupperet COUNT_BIG aggregering ved hjælp af kolonne c2 som nøglen:
-- The test query
SELECT
T.c2,
numrows = COUNT_BIG(*)
FROM dbo.Test AS T
GROUP BY
T.c2;
Columnstore indeksoplysninger vil blive vist ved hjælp af DBCC CSINDEX efter udførelse af hver testforespørgsel:
DECLARE
@dbname sysname = DB_NAME(),
@objectid integer = OBJECT_ID(N'dbo.Test', N'U');
DECLARE
@rowsetid bigint =
(
SELECT
P.hobt_id
FROM sys.partitions AS P
WHERE
P.[object_id] = @objectid
AND P.index_id = 1
AND P.partition_number = 1
),
@rowgroupid integer = 0,
@columnid integer =
COLUMNPROPERTY(@objectid, N'c2', 'ColumnId') + 1;
DBCC CSINDEX
(
@dbname,
@rowsetid,
@columnid,
@rowgroupid,
1, -- show segment data
2, -- print option
0, -- start bitpack unit (inclusive)
2 -- end bitpack unit (exclusive)
); Test blev kørt på den seneste udgivne version af SQL Server, der var tilgængelig på tidspunktet for skrivningen:Microsoft SQL Server 2017 RTM-CU13-OD build 14.0.3049 Developer Edition (64-bit) på Windows 10 Pro. Tingene burde også fungere fint på den seneste build af SQL Server 2016.
Test 1:Pushdown, 9-bit urene nøgler
Denne test bruger testdatapopulationsscriptet nøjagtigt som skrevet lige ovenfor, og producerer en tabel med 32.256 rækker. Kolonne c1 indeholder tal fra 1 til 32.256.
Kolonne c2 indeholder 512 forskellige værdier fra 0 til 511 inklusive. Hver værdi i c2 er duplikeret 63 gange , men de vises ikke som sammenhængende blokke, når de ses i c1 bestille; de cykler 63 gange gennem værdierne 0 til 511.
I betragtning af den foregående diskussion forventer vi, at SQL Server gemmer c2 kolonnedata ved hjælp af:
- Ordbogskodning da der er et betydeligt antal duplikerede værdier.
- Ingen RLE . Antallet af dubletter (63) pr. værdi når ikke den tærskel på 64, der kræves for RLE.
- Bit-pakning størrelse 9 . De 512 forskellige ordbogsposter vil nøjagtigt passe i 9 bits (2^9 =512). Hver 64-bit enhed vil indeholde op til syv 9-bit underenheder.
Alt dette bekræftes som korrekt ved hjælp af DBCC CSINDEX forespørgsel:
Segmentattributter sektion af output viser ordbogskodning (type 2; værdierne for encodingType er som dokumenteret på sys.column_store_segments ).
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId => 511
OnDisk =37944 RowCount =32256
RLE-sektionen viser ingen RLE-data , kun en pegepind til det bitpakkede område og en tom indtastning for værdi nul:
RLE Header:
Lob-type =3 RLE-arrayantal (i form af indfødte enheder) =2
RLE-arrayindtastningsstørrelse =8
RLE-data:
Indeks =0 Bitpack Array Index =0 Antal =32256
Indeks =1 Værdi =0 Antal =0
Bitpack Data Header afsnittet viser bitpack størrelse 9 og 4.608 brugte bitpack-enheder:
Bitpack Data Header:
Bitpack Entry Size =9 Bitpack Unit Count =4608 Bitpack MinId =3
Bitpack DataSize =36864
Bitpack-data sektionen viser værdierne gemt i de første to bitpack-enheder som anmodet af de sidste to parametre til DBCC CSINDEX kommando. Husk, at hver 64-bit enhed kan indeholde 7 underenheder (nummereret 0 til 6) på 9 bit hver (7 x 9 =63 bit). De 4.608 enheder har samlet 4.608 * 7 =32.256 rækker:
Enhed 0 UnderEnhed 0 =383
Enhed 0 UnderEnhed 1 =255
Enhed 0 UnderEnhed 2 =127
Enhed 0 UnderEnhed 3 =510
Enhed 0 UnderEnhed 4 =381
Enhed 0 Underenhed 5 =253
Enhed 0 Underenhed 6 =125
Enhed 1 UnderEnhed 0 =508
Enhed 1 UnderEnhed 1 =379
Enhed 1 UnderEnhed 2 =251
Enhed 1 UnderEnhed 3 =123
Enhed 1 UnderEnhed 4 =506
Enhed 1 underenhed 5 =377
Enhed 1 underenhed 6 =249
Da grupperingsnøglerne bruger bit-packing med en størrelse mindre end eller lig med 10 , forventer vi grupperet samlet pushdown at arbejde her. Faktisk viser udførelsesplanen, at alle rækker blev aggregeret lokalt ved Søjlelagerindeksscanningen operatør:

Planens xml indeholder ActualLocallyAggregatedRows="32256" i runtime-oplysningerne for indeksscanningen.
Test 2:Ingen pushdown, 12-bit urene nøgler
Denne test ændrer @values parameter til 1025, idet du beholder @dupes ved 63. Dette giver en tabel med 64.575 rækker med 1.025 forskellige værdier i kolonne c2 kører fra 0 til 1024 inklusive. Hver værdi i c2 er duplikeret 63 gange .
SQL Server gemmer c2 kolonnedata ved hjælp af:
- Ordbogskodning da der er et betydeligt antal duplikerede værdier.
- Ingen RLE . Antallet af dubletter (63) pr. værdi når ikke den tærskel på 64, der kræves for RLE.
- Bitpakket med størrelse 12 . De 1.025 forskellige ordbogsposter passer ikke helt i 10 bit (2^10 =1.024). De ville passe i 11 bit, men SQL Server understøtter ikke den bit-pakningsstørrelse som tidligere nævnt. Den næstmindste størrelse er 12 bit. Ved at bruge 64-bit enheder med hårde kanter til bitpakning kunne der ikke passe flere 11-bit underenheder i 64 bit, end 12-bit underenheder ville. Uanset hvad, vil 5 underenheder passe i en 64-bit enhed.
DBCC CSINDEX output bekræfter ovenstående analyse:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1.000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1024 OnDalize =1024 OnDalize =104400 RowCount =64575
RLE Header:
Lob type =3 RLE Array Count (i form af indfødte enheder) =2
RLE Array Entry Size =8
RLE-data:
Indeks =0 Bitpack Array Index =0 Antal =64575
Indeks =1 Værdi =0 Antal =0
Bitpack Data Header:
Bitpack Entry Size =12 Bitpack Unit Count =12915 Bitpack MinId =3
Bitpack DataSize =103320
Bitpack Data:
Enhed 0 UnderEnhed 0 =767
Enhed 0 UnderEnhed 1 =510
Enhed 0 UnderEnhed 2 =254
Enhed 0 UnderEnhed 3 =1021
Enhed 0 UnderEnhed 4 =765
Enhed 1 UnderEnhed 0 =507
Enhed 1 UnderEnhed 1 =250
Enhed 1 UnderEnhed 2 =1019
Enhed 1 UnderEnhed 3 =761
Enhed 1 UnderEnhed 4 =505
Siden den urene grupperingsnøgler har en størrelse over 10 , forventer vi grupperet samlet pushdown ikke at arbejde her. Dette bekræftes af udførelsesplanen, der viser nul rækker lokalt aggregeret ved Kolumnbutikindeksscanning operatør:
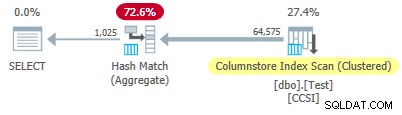
Alle 64.575 rækker udsendes (i batches) af Columnstore Index Scan og aggregeret i batch-tilstand af Hash Match Aggregate operatør. ActualLocallyAggregatedRows attribut mangler fra xml-planens runtime-information for indeksscanningen.
Test 3:Pushdown, Pure Keys
Denne test ændrer @dupes parameter fra 63 til 64 for at tillade RLE. @values parameter ændres til 16.384 (maksimum for det samlede antal rækker, der stadig passer i en enkelt rækkegruppe). Det nøjagtige tal valgt for @values er ikke vigtigt - pointen er at generere 64 dubletter af hver unik værdi, så RLE kan bruges.
SQL Server gemmer c2 kolonnedata ved hjælp af:
- Ordbogskodning på grund af de duplikerede værdier.
- RLE. Bruges for hver enkelt værdi, da hver af dem når tærsklen på 64.
- Ingen bitpakkede data . Hvis der var nogen, ville den bruge størrelse 16. Størrelse 12 er ikke stor nok (2^12 =4.096 forskellige værdier), og størrelse 21 ville være spild. De 16.384 forskellige værdier ville passe i 14 bit, men som før kan ikke flere af disse passe i en 64-bit enhed end 16-bit underenheder.
DBCC CSINDEX output bekræfter ovenstående (kun nogle få RLE-poster og bogmærker vist af pladshensyn):
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1638OnDalS =131648 RowCount =1048576
RLE Header:
Lob-type =3 RLE-arrayantal (i form af indfødte enheder) =16385
RLE-arrayindtastningsstørrelse =8
RLE-data:
Indeks =0 Værdi =3 Antal =64
Indeks =1 Værdi =1538 Antal =64
Indeks =2 Værdi =3072 Antal =64
Indeks =3 Værdi =4608 Antal =64
Indeks =4 Værdi =6142 Antal =64
…
Indeks =16381 Værdi =8954 Antal =64
Indeks =16382 Værdi =10489 Antal =64
Indeks =16383 =12025 Antal =64
Indeks =16384 Værdi =0 Antal =0
Bogmærkehoved:
Antal bogmærker =65 Bogmærkeafstand =16384 Bogmærkestørrelse =520
Bogmærkedata:
Position =0 Indeks =64
Position =512 Indeks =16448
Position =1024 Indeks =32832
…
Position =31744 Indeks =1015872
Position =32256 Indeks =1032256
Position =32768 Indeks =1048577
Bitpack Data Header:
Bitpack Entry Size =16 Bitpack Unit Count =0 Bitpack MinId =3
Bitpack DataSize =0
Da grupperingsnøglerne er rene (RLE bruges), grupperet samlet pushdown forventes her. Udførelsesplanen bekræfter dette ved at vise alle rækker lokalt aggregeret ved Kolumnbutikindeksscanning operatør:
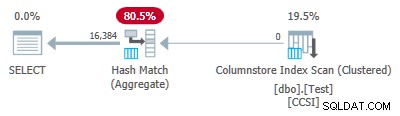
Planens xml indeholder ActualLocallyAggregatedRows="1048576" i runtime-oplysningerne for indeksscanningen.
Test 4:10-bit urene nøgler
Denne test indstiller @values til 1024 og @dupes til 63, hvilket giver en tabel med 64.512 rækker med 1.024 forskellige værdier i kolonne c2 med værdier fra 0 til 1.023 inklusive. Hver værdi i c2 er duplikeret 63 gange .
Vigtigst af alt , b-tree-klyngeindekset er nu oprettet i kolonne c1 i stedet for kolonne c2 . Det klyngede kolonnelager erstatter stadig b-træets klyngeindeks. Dette er den ændrede del af scriptet:
-- Note column c1 now! CREATE CLUSTERED INDEX CCSI ON dbo.Test (c1); GO CREATE CLUSTERED COLUMNSTORE INDEX CCSI ON dbo.Test WITH (MAXDOP = 1, DROP_EXISTING = ON);
SQL Server gemmer c2 kolonnedata ved hjælp af:
- Ordbogskodning på grund af dubletterne.
- Ingen RLE . Antallet af dubletter (63) pr. værdi når ikke den tærskel på 64, der kræves for RLE.
- Bit-pakning med størrelse 10 . De 1.024 forskellige ordbogsposter passer nøjagtigt i 10 bit (2^10 =1.024). Seks underenheder på hver 10 bit kan lagres i hver 64-bit enhed.
DBCC CSINDEX output er:
Version =1 encodingType =2 hasNulls =0
BaseId =-1 Magnitude =-1,000000e+000 PrimaryDictId =0
SecondaryDictId =-1 MinDataId =0 MaxDataId =1023 OnDalize =1023 OnDalize =87096 RowCount =64512
RLE Header:
Lob type =3 RLE Array Count (i form af indfødte enheder) =2
RLE Array Entry Size =8
RLE-data:
Indeks =0 Bitpack Array Index =0 Antal =64512
Indeks =1 Værdi =0 Antal =0
Bitpack Data Header:
Bitpack Entry Size =10 Bitpack Unit Count =10752 Bitpack MinId =3
Bitpack DataSize =86016
Bitpack Data:
Enhed 0 UnderEnhed 0 =766
Enhed 0 UnderEnhed 1 =509
Enhed 0 UnderEnhed 2 =254
Enhed 0 UnderEnhed 3 =1020
Enhed 0 UnderEnhed 4 =764
Enhed 0 Underenhed 5 =506
Enhed 1 UnderEnhed 0 =250
Enhed 1 UnderEnhed 1 =1018
Enhed 1 UnderEnhed 2 =760
Enhed 1 UnderEnhed 3 =504
Enhed 1 UnderEnhed 4 =247
Enhed 1 Underenhed 5 =1014
Siden den urene grupperingsnøgler bruger en størrelse mindre end eller lig med 10, ville vi forvente grupperet samlet pushdown at arbejde her. Men det er ikke hvad der sker . Udførelsesplanen viser, at 54.612 af de 64.512 rækker blev samlet ved Hash Match Aggregate operatør:
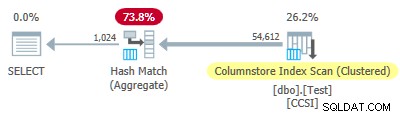
Planens xml indeholder ActualLocallyAggregatedRows="9900" i runtime-oplysningerne for indeksscanningen. Dette betyder grupperet samlet pushdown blev brugt til 9.900 rækker, men ikke brugt til de andre 54.612!
Feedbackmekanismen
SQL Server startede med at bruge grupperet samlet pushdown for denne udførelse, fordi de urene grupperingsnøgler opfyldte 10-bits-eller-mindre-kriterierne. Dette varede i i alt 11 batches (på 900 rækker hver =9.900 rækker i alt). På det tidspunkt, en feedbackmekanisme, der måler effektiviteten af grupperet samlet pushdown besluttede, at det ikke fungerede, og deaktiverede det . De resterende batches blev alle behandlet med pushdown deaktiveret.
Feedbacken sammenligner i det væsentlige antallet af aggregerede rækker med antallet af producerede grupper. Den starter med en værdi på 100 og justeres i slutningen af hver pushdown-outputbatch. Hvis værdien falder til 10 eller derunder, er pushdown deaktiveret for den aktuelle grupperingsoperation.
’Pushdown-ydelsesforanstaltningen’ reduceres mere eller mindre afhængig af, hvor dårligt det går med den pressede sammenlægningsindsats. Hvis der i gennemsnit er færre end 8 rækker pr. grupperingsnøgle i outputbatchen, reduceres den aktuelle ydelsesværdi med 22 %. Hvis der er mere end 8, men færre end 16, reduceres metrikken med 11 %.
På den anden side, hvis tingene forbedres, og der efterfølgende stødes på 16 eller flere rækker pr. grupperingsnøgle for en outputbatch, nulstilles metrikken til 100 og fortsætter med at blive justeret, efterhånden som delvise samlede batches produceres af scanningen.
Dataene i denne test blev præsenteret i en særlig uhensigtsmæssig rækkefølge til pushdown på grund af det originale b-træ-klyngeindeks i kolonne c1 . Når de præsenteres på denne måde, er værdierne i kolonne c2 begynder ved 0 og stiger med 1, indtil de når 1.023, hvorefter de starter cyklussen igen. De 1.023 forskellige værdier er mere end nok til at sikre, at hver 900-rækkers outputbatch kun indeholder én delvist aggregeret række for hver nøgle. Dette er ikke en lykkelig tilstand.
Hvis der havde været 64 dubletter pr. værdi i stedet for 63, ville SQL Server have overvejet at sortere efter c2 mens du byggede columnstore-indekset, og så producerede RLE-komprimering. Som det er, sparker 22%-straffen ind efter hver batch. Startende ved 100 og ved hjælp af den samme afrundede heltal-aritmetik går sekvensen af metriske værdier:
-- @metric := FLOOR(@metric * 0.78 + 0.5); -- 100, 78, 61, 48, 37, 29, 23, 18, 14, 11, *9*
Den ellevte batch reducerer metrikken til 10 eller derunder, og pushdown er deaktiveret. De 11 batches af 900 rækker tegner sig for de 9.900 lokalt aggregerede rækker vist i udførelsesplanen.
Variation med 900 forskellige værdier
Den samme adfærd kan ses i test 4 med så få som 901 forskellige værdier, forudsat at rækkerne tilfældigvis er præsenteret i samme uhensigtsmæssige rækkefølge.
Ændring af @values parameter til 900, mens alt andet holdes ved lige har en dramatisk effekt på udførelsesplanen:
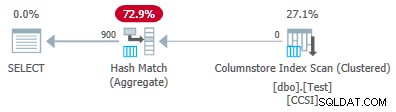
Nu er alle 900 grupper samlet ved scanningen! XML-planegenskaberne viser ActualLocallyAggregatedRows="56700" . Dette fordi grupperet samlet pushdown opretholder 900 grupperingsnøgler og delvise aggregater i en enkelt batch. It never encounters a new key value not in the batch, so there is no reason to start a fresh output batch.
Only ever producing one batch means the feedback mechanism never gets chance to reduce the “pushdown benefit measure” to the point where grouped aggregate pushdown is disabled. It never would anyway, since the pushdown is very successful — 56,700 rows for 900 grouping keys is 63 per key, well above the threshold for benefit measure reduction.
Extended Event
There is very little information available in execution plans to help determine why grouped aggregation pushdown was either not tried, or was not successful. There is, however, an Extended Event named query_execution_dynamic_push_down_statistics in the execution category of the Analytic channel.
It provides the following Event Fields:
rows_not_pushed_down_due_to_encoding
Description:Number of rows not pushed to scan because of the the total encoded key length.
This identifies impure data over the 10-bit limit as shown in test 2.
rows_not_pushed_down_due_to_possible_overflow
Description:Number of rows not pushed to scan because of a possible overflow
rows_not_pushed_down_due_to_pushdown_disabled
Description:Number of rows not pushed to scan (only) because dynamic pushdown was disabled
This occurs when the pushdown benefit measure drops below 10 as described in test 4.
rows_pushed_down_in_thread
Description:Number of locally aggregated rows in thread
This corresponds with the value for ‘locally aggregated rows’ shown in execution plans.
Bemærk: No event is recorded if grouped aggregation pushdown is specifically disabled using trace flag 9373. All types of pushdown to a nonclustered columnstore index can be specifically disabled with trace flag 9386. All types of pushdown activity can be disabled with trace flag 9354.