Det allerførste blogindlæg på dette websted, helt tilbage i juli 2012, talte om de bedste metoder til at køre totaler. Siden da er jeg blevet spurgt ved flere lejligheder, hvordan jeg ville gribe problemet an, hvis de løbende totaler var mere komplekse – specifikt hvis jeg skulle beregne løbende totaler for flere enheder – f.eks. hver kundes ordrer.
Det originale eksempel brugte et fiktivt tilfælde af en by, der udstedte fartbøder; den løbende sum var simpelthen at aggregere og holde en løbende optælling af antallet af fartbøder om dagen (uanset hvem billetten blev udstedt til, eller hvor meget den var til). Et mere komplekst (men praktisk) eksempel kunne være at samle den løbende samlede værdi af fartbøder, grupperet efter kørekort, pr. dag. Lad os forestille os følgende tabel:
CREATE TABLE dbo.SpeedingTickets( IncidentID INT IDENTITY(1,1) PRIMARY KEY, LicenseNumber INT NOT NULL, IncidentDate DATE NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL); OPRET UNIKT INDEKS x PÅ dbo.SpeedingTickets(LicenseNumber, IncidentDate) INCLUDE(TicketAmount);
Du spørger måske, DECIMAL(7,2) , virkelig? Hvor hurtigt kører disse mennesker? Nå, i Canada, for eksempel, er det ikke så svært at få en fartbøde på 10.000 USD.
Lad os nu udfylde tabellen med nogle eksempeldata. Jeg vil ikke komme ind på alle detaljerne her, men dette skulle give omkring 6.000 rækker, der repræsenterer flere chauffører og flere billetbeløb over en måneds lang periode:
;WITH TicketAmounts(ID,Value) AS ( -- 10 vilkårlige billetbeløb VÆLG i,p FRA ( VALUES(1,32,75),(2,75), (3,109),(4,175),(5,295), (6,68.50),(7.125),(8.145),(9.199),(10.250) ) AS v(i,p)),LicenseNumbers(LicenseNumber,[nyt]) AS ( -- 1000 tilfældige licensnumre VÆLG TOP ( 1000) 7000000 + tal, n =NEWID() FRA [master].dbo.spt_values WHERE nummer MELLEM 1 OG 999999 BESTIL EFTER n),JanuaryDates([dag]) AS ( -- hver dag i januar 2014 VÆLG TOP (31) DATEADD(DAY, number, '20140101') FRA [master].dbo.spt_values WHERE [type] =N'P' ORDER BY number),Tickets(LicenseNumber,[day],s) AS( -- match *nogle* licenser til dage, de fik billetter SELECT DISTINCT l.LicenseNumber, d.[dag], s =RTRIM(l.LicenseNumber) FROM LicenseNumbers AS l CROSS JOIN JanuaryDates AS d WHERE CHECKSUM(NEWID()) % 100 =l.LicenseNumber % OG (RTRIM(l.LicenseNumber) LIKE '%' + RIGHT(CONVERT(CHAR(8), d.[dag], 112),1) + '%') OR (RTRIM(l.LicenseNumber+1) LIKE ' %' + HØJRE( KONVERTER(CHAR(8), d.[dag], 112),1) + '%'))INSERT dbo.SpeedingTickets(LicenseNumber,IncidentDate,TicketAmount)SELECT t.LicenseNumber, t.[day], ta.Value FROM Billetter AS t INNER JOIN Billetbeløb AS ta ON ta.ID =KONVERTER(INT,HØJRE(t.s,1))-CONVERT(INT,VENSTRE(HØJRE(t.s,2),1)) BESTIL SEN. t.[dag], t .LicenseNumber;
Dette virker måske lidt for involveret, men en af de største udfordringer, jeg ofte har, når jeg komponerer disse blogindlæg, er at konstruere en passende mængde realistisk "tilfældig" / vilkårlig data. Hvis du har en bedre metode til vilkårlig datapopulation, så lad være med at bruge mine mumler som eksempel – de er perifere til pointen med dette indlæg.
Tilgange
Der er forskellige måder at løse dette problem på i T-SQL. Her er syv tilgange sammen med deres tilhørende planer. Jeg har udeladt teknikker som markører (fordi de unægtelig vil være langsommere) og datobaserede rekursive CTE'er (fordi de afhænger af sammenhængende dage).
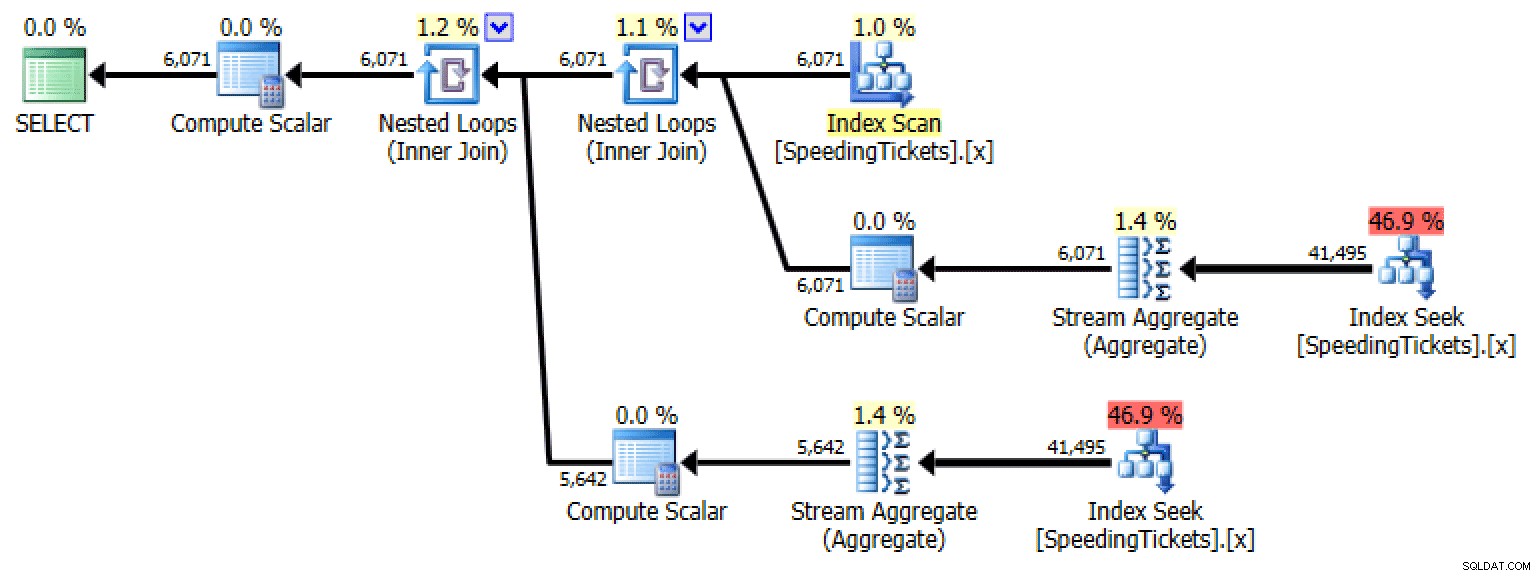
Underforespørgsel #1
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =TicketAmount + COALESCE( ( SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets AS s WHERE s.LicenseNumber =o.LicenseNumber AND s.IncidentDate)
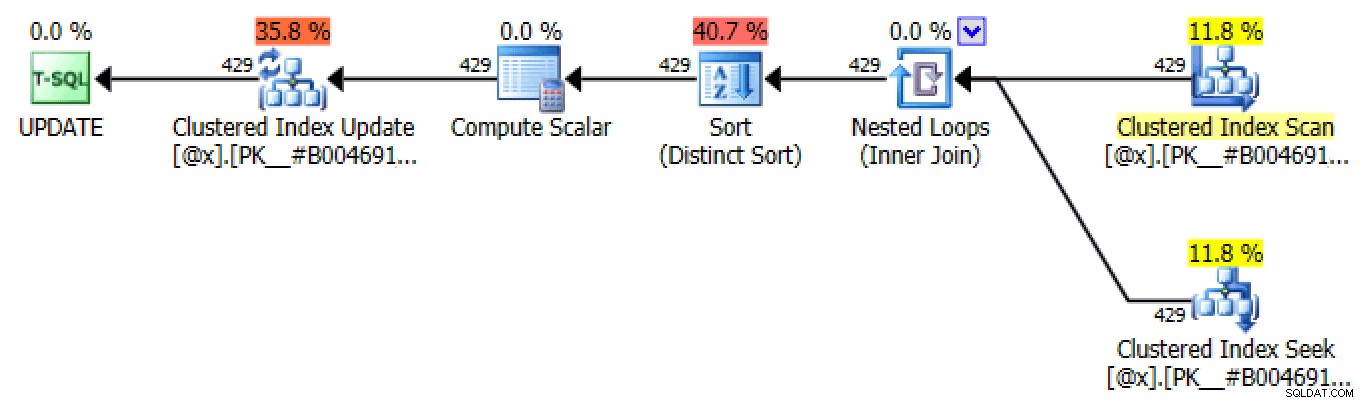
Plan for underforespørgsel #1Underforespørgsel #2
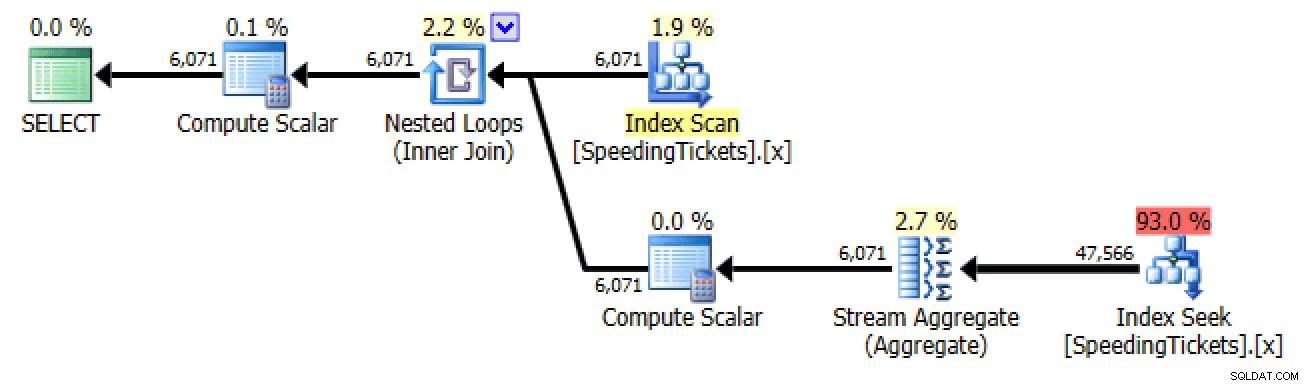
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =( SELECT SUM(TicketAmount) FROM dbo.SpeedingTickets WHERE LicenseNumber =t.LicenseNumber AND IncidentDate <=t.IncidentDate )FROM dbo.SpeedingTickets BY AS>
Plan for underforespørgsel #2Tilmeld dig selv
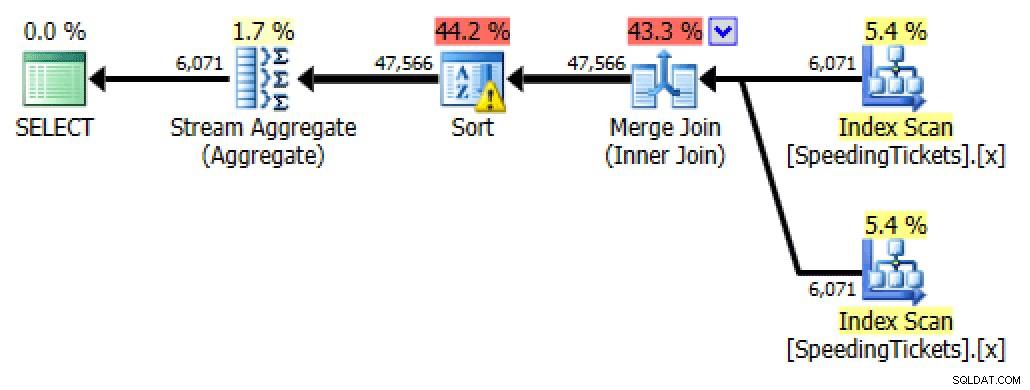
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal =SUM(t2.TicketAmount)FRA dbo.SpeedingTickets AS t1INNER JOIN dbo.SpeedingTickets AS t2 ON t1.Licenicent.Indent.License. t2.IncidentDateGROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmountORDER BY t1.LicenseNumber, t1.IncidentDate;
Plan for selvtilmeldingYdre gælder
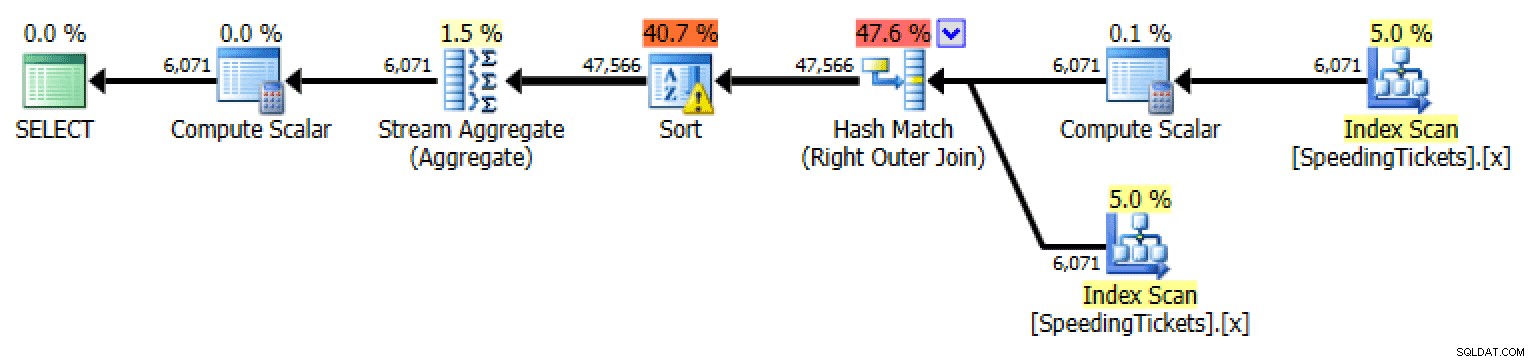
SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal =SUM(t2.TicketAmount)FRA dbo.SpeedingTickets AS t1OUTER APPLY( SELECT TicketAmount FRA dbo.SpeedingTicketsseNumber LicentTickets Where.DateLicentseNumber Licent.DataLicentseNumber Licent IncidentDate) SOM t2GROUP BY t1.LicenseNumber, t1.IncidentDate, t1.TicketAmountORDER BY t1.LicenseNumber, t1.IncidentDate;
Plan for ydre ansøgningSUM OVER() ved hjælp af RANGE (kun 2012+)
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =SUM(TicketAmount) OVER ( PARTITION BY LicenseNumber ORDER BY IncidentDate RANGE UNBOUNDED PRECEDING ) FRA dbo.SpeedingTickets BESTILLING BY LicenseNumber;pre>
Plan for SUM OVER() ved hjælp af RANGESUM OVER() ved hjælp af RÆKKER (kun 2012+)
SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =SUM(TicketAmount) OVER ( PARTITION BY LicenseNumber ORDER BY IncidentDate RÆKKER UBEGRÆNSET FOREGÅENDE ) FRA dbo.SpeedingTickets BESTIL EFTER LicenseNumber,
Planlæg SUM OVER() ved hjælp af RÆKKERSæt-baseret iteration
Med ære til Hugo Kornelis (@Hugo_Kornelis) for kapitel #4 i SQL Server MVP Deep Dives Volume #1, kombinerer denne tilgang en sæt-baseret tilgang og en markørtilgang.
DECLARE @x TABLE( Licensnummer INT IKKE NULL, IncidentDate DATE NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL, RunningTotal DECIMAL(7,2) NOT NULL, rn INT NOT NULL, PRIMARY KEY(LicensDataNumber) ); INSERT @x(LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)SELECT LicenseNumber, IncidentDate, TicketAmount, TicketAmount, ROW_NUMBER() OVER (PARTITION BY LicenseNumber ORDER BY IncidentDate) FROM dbo.SpeedingTickets; DEKLARE @rn INT =1, @rc INT =1; WHILE @rc> 0BEGIN SÆT @rn +=1; OPDATERING [current] SET RunningTotal =[sidste].RunningTotal + [current].TicketBeløb FRA @x AS [current] INNER JOIN @x AS [sidste] PÅ [current].LicenseNumber =[sidste].LicenseNumber OG [sidste]. rn =@rn - 1 WHERE [aktuel].rn =@rn; SET @rc =@@ROWCOUNT;END SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal FROM @x ORDER BY LicenseNumber, IncidentDate;På grund af dens natur producerer denne tilgang mange identiske planer i processen med at opdatere tabelvariablen, som alle ligner planerne for selvsammenføjning og ydre anvendelse, men er i stand til at bruge en søgning:
En af mange OPDATERINGsplaner produceret gennem sæt-baseret iterationDen eneste forskel mellem hver plan i hver iteration er rækkeantallet. Gennem hver efterfølgende iteration bør antallet af berørte rækker forblive det samme eller falde, da antallet af rækker, der påvirkes ved hver iteration, repræsenterer antallet af chauffører med billetter på dette antal dage (eller mere præcist antallet af dage kl. den "rang").
Ydeevneresultater
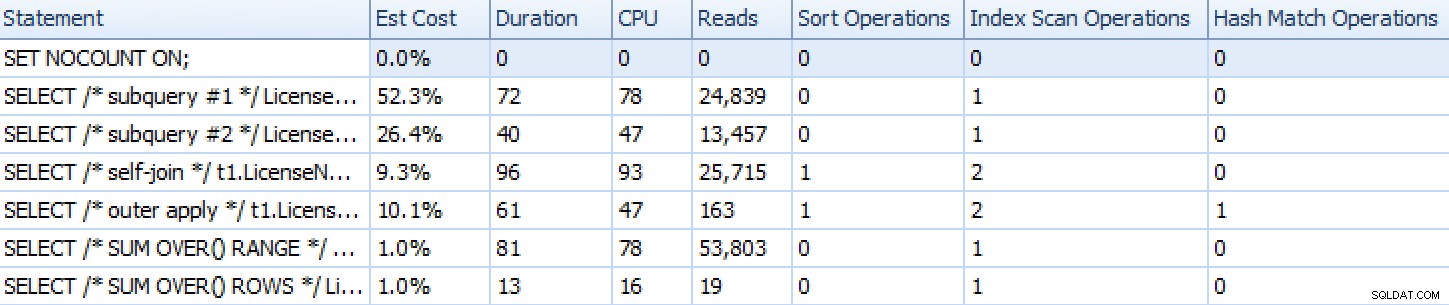
Her er, hvordan tilgangene er stablet op, som vist af SQL Sentry Plan Explorer, med undtagelse af den sæt-baserede iterationstilgang, som, fordi den består af mange individuelle sætninger, ikke repræsenterer godt sammenlignet med resten.
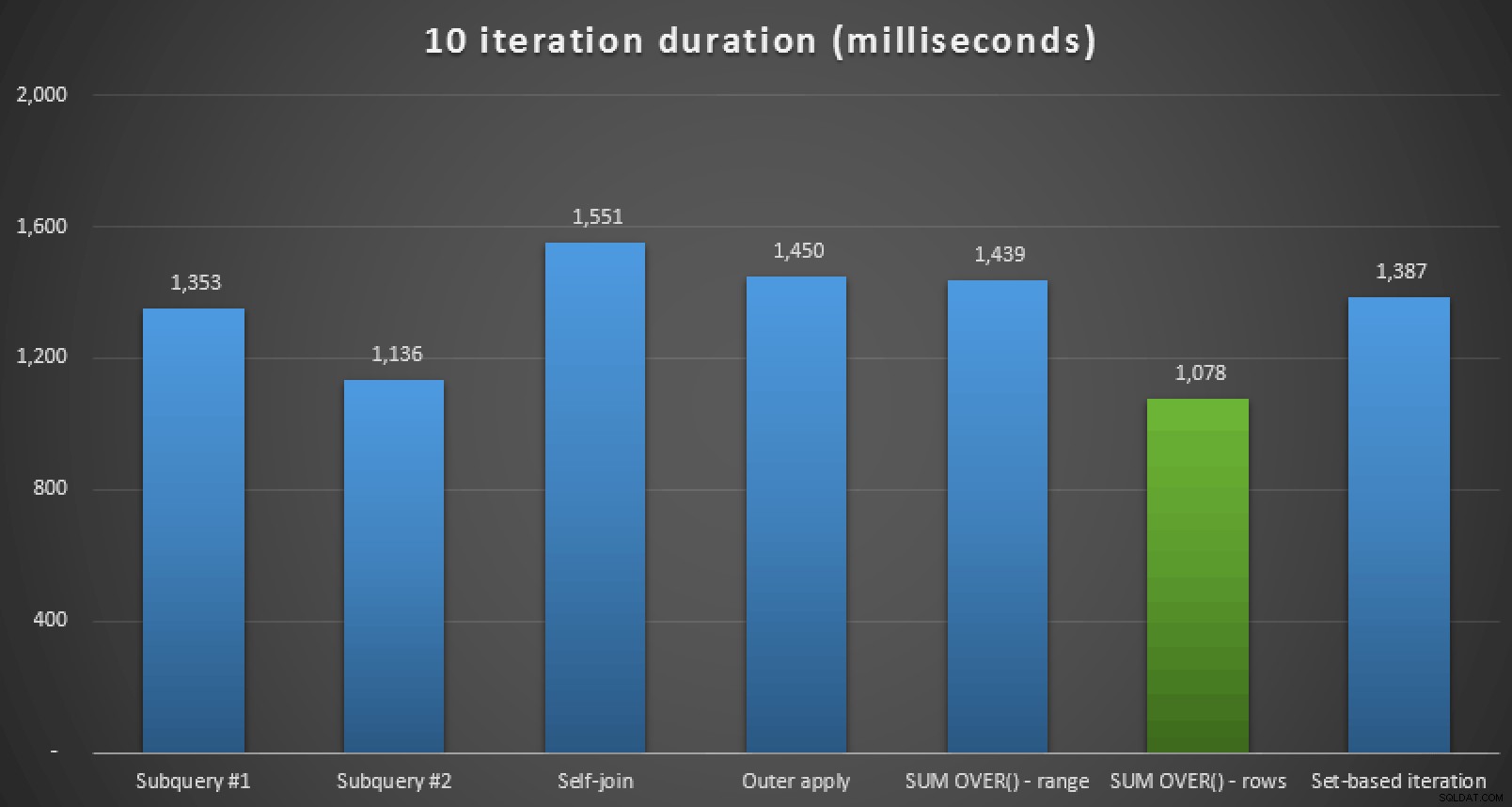
Planlæg Explorer runtime-metrics for seks af de syv tilgangeUdover at gennemgå planerne og sammenligne runtime-metrics i Plan Explorer, målte jeg også rå runtime i Management Studio. Her er resultaterne af at køre hver forespørgsel 10 gange, husk på, at dette også inkluderer gengivelsestid i SSMS:
Køretidsvarighed, i millisekunder, for alle syv tilgange (10 iterationer) )Så hvis du er på SQL Server 2012 eller bedre, ser den bedste tilgang ud til at være
SUM OVER()ved hjælp afROWS UNBOUNDED PRECEDING. Hvis du ikke er på SQL Server 2012, så den anden underforespørgselstilgang ud til at være optimal med hensyn til kørselstid, på trods af det høje antal læsninger sammenlignet med f.eks.OUTER APPLYforespørgsel. I alle tilfælde bør du selvfølgelig teste disse tilgange, tilpasset dit skema, mod dit eget system. Dine data, indekser og andre faktorer kan føre til, at en anden løsning er mest optimal i dit miljø.Andre kompleksiteter
Nu betyder det unikke indeks, at enhver kombination af LicenseNumber + IncidentDate vil indeholde en enkelt kumulativ total i det tilfælde, hvor en specifik chauffør får flere billetter på en given dag. Denne forretningsregel hjælper med at forenkle vores logik en smule og undgår behovet for en tie-breaker til at producere deterministiske løbende totaler.
Hvis du har tilfælde, hvor du kan have flere rækker for en given kombination af licensnummer + hændelsesdato, kan du bryde båndet ved hjælp af en anden kolonne, der hjælper med at gøre kombinationen unik (naturligvis ville kildetabellen ikke længere have en unik begrænsning på disse to kolonner) . Bemærk, at dette er muligt selv i tilfælde, hvor
DATEkolonnen er faktiskDATETIME– mange mennesker antager, at dato/tidsværdier er unikke, men det er bestemt ikke altid garanteret, uanset granularitet.I mit tilfælde kunne jeg bruge
IDENTITYkolonne,IncidentID; her er, hvordan jeg ville justere hver løsning (ved at anerkende, at der kan være bedre måder; bare smide ideer ud):/* --------- underforespørgsel #1 ---------- */ SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =TicketAmount + COALESCE( ( SELECT SUM(TicketAmount) FROM dbo. SpeedingTickets AS s WHERE s.LicenseNumber =o.LicenseNumber AND (s.IncidentDate=t2.IncidentDate -- tilføjet denne linje:OG t1.IncidentID>=t2.IncidentID1UP,LIncidentID1UP,LIncidentID1UP. .TicketAmountORDER AF t1.LicenseNumber, t1.IncidentDate; /* ---------- ydre gælder ---------- */ SELECT t1.LicenseNumber, t1.IncidentDate, t1.TicketAmount, RunningTotal =SUM(t2.TicketAmount)FROM dbo.SpeedingTickets AS t1UDRE APPLY( SELECT TicketAmount FRA dbo.SpeedingTickets WHERE LicenseNumber =t1.LicenseNumber AND IncidentDate <=t1.IncidentDate -- tilføjet denne linje:AND IncidentID <=t1.IncidentID) AS t2GROUP BY t2GROUP BY t1N1cident.Incident.Incident.Ind. AF t1.LicenseNumber, t1.IncidentDate; /* --------- SUM() OVER ved hjælp af RANGE --------- */ SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =SUM(TicketAmount) OVER ( PARTITION BY LicenseNumber ORDER BY IncidentDate, IncidentID RANGE UBEGRÆNSET FOREGÅENDE -- tilføjet denne kolonne ^^^^^^^^^^^^ ) FRA dbo.SpeedingTickets BESTIL EFTER LicenseNumber, IncidentDate; /* --------- SUM() OVER using ROWS --------- */ SELECT LicenseNumber, IncidentDate, TicketAmount, RunningTotal =SUM(TicketAmount) OVER ( PARTITION BY LicenseNumber ORDER BY IncidentDate, IncidentID ROWS UNBOUNDED PRECEDING -- tilføjede denne kolonne ^^^^^^^^^^^^ ) FRA dbo.SpeedingTickets BESTIL EFTER LicenseNumber, IncidentDate; /* ---------- sætbaseret iteration ---------- */ DECLARE @x TABLE( -- tilføjede denne kolonne og gjorde den til PK:IncidentID INT PRIMARY KEY, LicenseNumber INT NOT NULL, IncidentDate DATE NOT NULL, TicketAmount DECIMAL(7,2) NOT NULL, RunningTotal DECIMAL(7,2) NOT NULL, rn INT NOT NULL); -- tilføjede den ekstra kolonne til INSERT/SELECT:INSERT @x(IncidentID, LicenseNumber, IncidentDate, TicketAmount, RunningTotal, rn)SELECT IncidentID, LicenseNumber, IncidentDate, TicketAmount, TicketAmount, ROW_NUMBER() OVER (PARTITION BY IncidentOReDatoNumber) , IncidentID) -- og tilføjede denne tie-breaker kolonne ------------------------------^^^^^^^^ ^^^^ FRA dbo.SpeedingTickets; -- resten af den sæt-baserede iterationsløsning forblev uændret En anden komplikation, du kan støde på, er, når du ikke er ude efter hele bordet, men snarere en delmængde (f.eks. i dette tilfælde den første uge af januar). Du bliver nødt til at foretage justeringer ved at tilføje
WHEREklausuler, og husk disse prædikater, når du også har korrelerede underforespørgsler.