Har du nogensinde kontaktet Microsoft eller en Microsoft-partner og diskuteret med dem, hvad det ville koste at flytte til skyen? Hvis det er tilfældet, har du måske hørt om Azure SQL Database DTU-beregneren, og du har måske også læst om, hvordan den er blevet omvendt udviklet af Andy Mallon. DTU-beregneren er et gratis værktøj, du kan bruge til at uploade ydeevnemålinger fra din server og bruge dataene til at bestemme det passende serviceniveau, hvis du skulle migrere den server til en Azure SQL-database (eller til en elastisk SQL-database-pool).
For at gøre dette skal du enten planlægge eller manuelt køre et script (kommandolinje eller Powershell, tilgængelig til download på DTU-beregnerens hjemmeside) i en periode med en typisk produktionsbelastning.
Hvis du prøver at analysere et stort miljø eller ønsker at analysere data fra bestemte tidspunkter, kan dette blive en opgave. I mange tilfælde har mange DBA'er en smag af overvågningsværktøj, der allerede fanger ydeevnedata for dem. I mange tilfælde er det sandsynligvis enten allerede at fange de nødvendige metrics, eller det kan nemt konfigureres til at fange de data, du har brug for. I dag skal vi se på, hvordan man kan udnytte SentryOne, så vi kan levere de relevante data til DTU-beregneren.
For at starte, lad os se på informationen hentet af kommandolinjeværktøjet og PowerShell-scriptet, der er tilgængeligt på DTU-beregnerens websted; der er 4 ydeevnemonitortællere, som den fanger:
- Processor – % processortid
- Logisk disk – Disk læser/sek.
- Logisk disk – Diskskrivning/sek.
- Database – Log Bytes tømmes/sek.
Det første trin er at bestemme, om disse metrics allerede er fanget som en del af dataindsamlingen i SQL Sentry. Til opdagelse foreslår jeg, at du læser dette blogindlæg af Jason Hall, hvor han fortæller, hvordan dataene er lagt ud, og hvordan du kan forespørge på dem. Jeg vil ikke gennemgå hvert trin i dette her, men opfordrer dig til at læse og bogmærke hele blogserien.
Da jeg kiggede SentryOne-databasen igennem, fandt jeg ud af, at 3 af de 4 tællere allerede blev fanget som standard. Den eneste, der manglede, var [Database – Log Bytes Flushed/sec] , så jeg havde brug for at kunne slå det til. Der var et andet blogindlæg af Justin Randall, der forklarer, hvordan man gør det.
Kort sagt kan du forespørge på [PerformanceAnalysisCounter] tabel.
SELECT ID, PerformanceAnalysisCounterCategoryID, PerformanceAnalysisSampleIntervalID, CounterResourceName, CounterName FROM dbo.PerformanceAnalysisCounter WHERE CounterResourceName = N'LOG_BYTES_FLUSHED_PER_SEC';
Du vil bemærke, at [PerformanceAnalysisSampleIntervalID] som standard er sat til 0 – det betyder, at den er deaktiveret. Du skal køre følgende kommando for at aktivere dette. Bare træk ID'et fra den SELECT-forespørgsel, du lige har kørt, og brug det i denne OPDATERING:
UPDATE dbo.PerformanceAnalysisCounter SET PerformanceAnalysisSampleIntervalID = 1 WHERE ID = 166;
Efter at have kørt opdateringen, skal du genstarte SentryOne-overvågningstjenesterne, der er relevante for dette mål, så de nye tællerdata kan indsamles.
Bemærk, at jeg indstillede [PerformanceAnalysisSampleIntervalID] til 1, så dataene fanges hvert 10. sekund, men du kan fange disse data sjældnere for at minimere størrelsen af de indsamlede data på bekostning af mindre nøjagtighed. Se [PerformanceAnalysisSampleInterval] tabel for en liste over værdier, som du kan bruge.
Forvent ikke, at dataene begynder at strømme ind i tabellerne med det samme; det vil tage tid at finde vej gennem systemet. Du kan tjekke for population med følgende forespørgsel:
SELECT TOP (100) * FROM dbo.PerformanceAnalysisDataDatabaseCounter WHERE PerformanceAnalysisCounterID = 166;
Når du har bekræftet, at dataene vises, bør du have data for hver af de metrikker, der kræves af DTU-beregneren, selvom du måske vil vente med at udtrække dem, indtil du har et repræsentativt udsnit fra en fuld arbejdsbyrde eller forretningscyklus.
Hvis du læser Jasons blogindlæg igennem, vil du se, at dataene er gemt i forskellige oversigtstabeller, og at hver af disse oversigtstabeller har varierende opbevaringsrater. Mange af disse er lavere end hvad jeg ville ønske, hvis jeg analyserer arbejdsbelastninger over en periode. Selvom det kan være muligt at ændre disse, er det måske ikke det klogeste. Fordi det, jeg viser dig, ikke understøttes, vil du måske undgå at pille for meget med SentryOne-indstillingerne, da det kan have en negativ indvirkning på ydeevne, vækst eller begge dele.
For at kompensere for dette oprettede jeg et script, der giver mig mulighed for at udtrække de data, jeg har brug for til de forskellige rollup-tabeller, og gemmer disse data på deres egen placering, så jeg kunne kontrollere min egen opbevaring og ikke forstyrre SentryOne-funktionaliteten.
TABEL:dbo.AzureDatabaseDTUData
Jeg oprettede en tabel kaldet [AzureDatabaseDTUData] og gemte det i SentryOne-databasen. Den procedure, jeg oprettede, vil automatisk generere denne tabel, hvis den ikke eksisterer, så der er ingen grund til at gøre dette manuelt, medmindre du vil tilpasse, hvor den er gemt. Du kan gemme dette i en separat database, hvis du vil, du skal blot redigere scriptet for at gøre det. Tabellen ser således ud:
CREATE TABLE dbo.AzureDatabaseDTUdata ( ID bigint identity(1,1) not null, DeviceID smallint not null, [TimeStamp] datetime not null, CounterName nvarchar(256) not null, [Value] float not null, InstanceName nvarchar(256) not null, CONSTRAINT PK_AzureDatabaseDTUdata PRIMARY KEY (ID) );
Procedure:dbo.Custom_CollectDTUDataForDevice
Dette er den lagrede procedure, som du kan bruge til at trække alle DTU-specifikke data på én gang (forudsat at du har indsamlet logbyte-tælleren i tilstrækkelig lang tid), eller planlægge den til periodisk at tilføje til de indsamlede data indtil du er klar til at indsende output til DTU-beregneren. Ligesom tabellen ovenfor er proceduren oprettet i SentryOne-databasen, men du kan nemt oprette den andre steder, blot tilføje tre- eller firedelte navne til objektreferencer. Grænsefladen til proceduren er som følger:
CREATE PROCEDURE [dbo].[Custom_CollectDTUDataForDevice] @DeviceID smallint = -1, @DaysToPurge smallint = 14, -- These define the CounterIDs in case they ever change. @ProcessorCounterID smallint = 1858, -- Processor (Default) @DiskReadCounterID smallint = 64, -- Disk Read/Sec (DiskCounter) @DiskWritesCounterID smallint = 67, -- Disk Writes/Sec (Diskcounter) @LogBytesFlushCounterID smallint = 166, -- Log Bytes Flushed/Sec (DatabaseCounter) AS ...
Bemærk :Hele proceduren er lidt lang, så den er vedhæftet dette indlæg (dbo.Custom_CollectDTUDataForDevice.sql_.zip).
Der er et par parametre, du kan bruge. Hver har en standardværdi, så du behøver ikke at angive dem, hvis du har det fint med standardværdierne.
- @DeviceID – Dette giver dig mulighed for at angive, om du vil indsamle data til en specifik SQL Server eller alt. Standarden er -1, hvilket betyder kopiering af alle overvågede SQL-servere. Hvis du kun ønsker at eksportere oplysninger for en bestemt instans, skal du finde
DeviceIDsvarende til værten i[dbo].[Device]tabel, og videregive denne værdi. Du kan kun sende én@DeviceIDad gangen, så hvis du vil passere gennem et sæt servere, kan du kalde proceduren flere gange, eller du kan ændre proceduren, så den understøtter et sæt enheder. - @DaysToPurge – Dette repræsenterer den alder, hvor du vil fjerne data. Standarden er 14 dage, hvilket betyder, at du kun vil trække data op til 14 dage gamle, og alle data, der er ældre end 14 dage i din tilpassede tabel, vil blive slettet.
De andre fire parametre er til for fremtidssikring, hvis SentryOne-enums for tæller-id'er nogensinde ændres.
Et par noter om scriptet:
- Når dataene trækkes, tager det maks. værdien fra det trunkerede minut og eksporterer det. Det betyder, at der er én værdi pr. metrisk pr. minut, men det er den maksimale værdi, der registreres. Dette er vigtigt på grund af den måde, dataene skal præsenteres for DTU-beregneren.
- Første gang du kører eksporten, kan det tage lidt længere tid. Dette skyldes, at den trækker alle de data, den kan baseret på dine parameterværdier. For hver ekstra kørsel er de eneste data, der uddrages, hvad der er nyt siden sidste kørsel, så det burde være meget hurtigere.
- Du bliver nødt til at planlægge denne procedure til at køre efter en tidsplan, der er foran SentryOne-rensningsprocessen. Det, jeg har gjort, er lige oprettet et SQL Agent-job til at køre om natten, som indsamler alle de nye data siden aftenen før.
- Fordi udrensningsprocessen i SentryOne kan variere baseret på metrik, kan du ende med rækker i din kopi, der ikke indeholder alle 4 tællere i en periode. Du vil måske først begynde at analysere dine data fra det tidspunkt, du starter din ekstraktionsproces.
- Jeg brugte en kodeblok fra eksisterende SentryOne-procedurer til at bestemme rollup-tabellen for hver tæller. Jeg kunne have hårdkodet de nuværende navne på tabellerne, men ved at bruge SentryOne-metoden skulle den være fremadkompatibel med eventuelle ændringer af de indbyggede rollup-processer.
Når dine data er ved at blive flyttet til en selvstændig tabel, kan du bruge en PIVOT-forespørgsel til at transformere dem til den form, som DTU-beregneren forventer.
Procedure:dbo.Custom_ExportDataForDTUCalculator
Jeg oprettede en anden procedure til at udtrække dataene til CSV-format. Koden til denne procedure er også vedhæftet (dbo.Custom_ExportDataForDTUCalculator.sql_.zip).
Der er tre parametre:
- @DeviceID – Smallint svarende til en af de enheder, du indsamler, og som du vil indsende til lommeregneren.
- @BeginTime – Datotid repræsenterer starttidspunktet i lokal tid; f.eks.
'2018-12-04 05:47:00.000'. Proceduren vil oversættes til UTC. Hvis den udelades, samles den fra den tidligste værdi i tabellen. - @EndTime – Datotid repræsenterer sluttidspunktet, igen i lokal tid; f.eks.
'2018-12-06 12:54:00.000'. Hvis den udelades, samles den op til den seneste værdi i tabellen.
Et eksempel på udførelse for at få alle data indsamlet til SQLInstanceA mellem den 4. december kl. 05.47 og den 6. december kl. 12:54.
EXEC SentryOne.dbo.custom_ExportDataForDTUCalculator @DeviceID = 12, @BeginTime = '2018-12-04 05:47:00.000', @EndTime = '2018-12-06 12:54:00.000';
Dataene skal eksporteres til en CSV-fil. Vær ikke bekymret over selve dataene; Jeg sørgede for at udlæse resultater, så der ikke er nogen identificerende oplysninger om din server i csv-filen, kun datoer og metrics.
Hvis du kører forespørgslen i SSMS, kan du højreklikke og eksportere resultater; Du har dog begrænsede muligheder her, og du bliver nødt til at manipulere outputtet for at få det format, som DTU-beregneren forventer. (Du er velkommen til at prøve at fortælle mig, hvis du finder en måde at gøre dette på.)
Jeg anbefaler bare at bruge eksportguiden bagt i SSMS. Højreklik på databasen og gå til Opgaver -> Eksporter data. Brug "SQL Server Native Client" til din datakilde, og peg den mod din SentryOne-database (eller hvor du nu har din kopi af dataene gemt). For din destination vil du gerne vælge "Flad fildestination." Gå til en placering, giv filen et navn, og gem filen som en CSV.
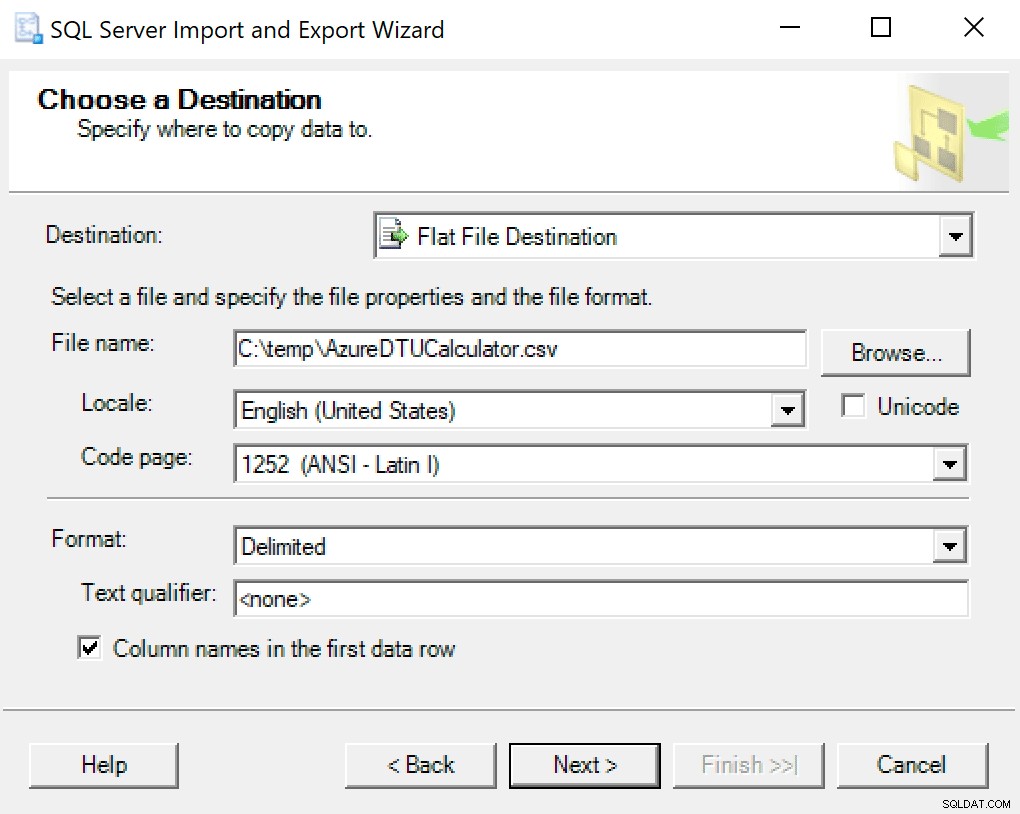
Sørg for at lade kodesiden være i fred; nogle kan returnere fejl. Jeg ved, at 1252 fungerer fint. Resten af værdierne forlader som standard.
På den næste skærm skal du vælge muligheden Skriv en forespørgsel for at angive de data, der skal overføres .
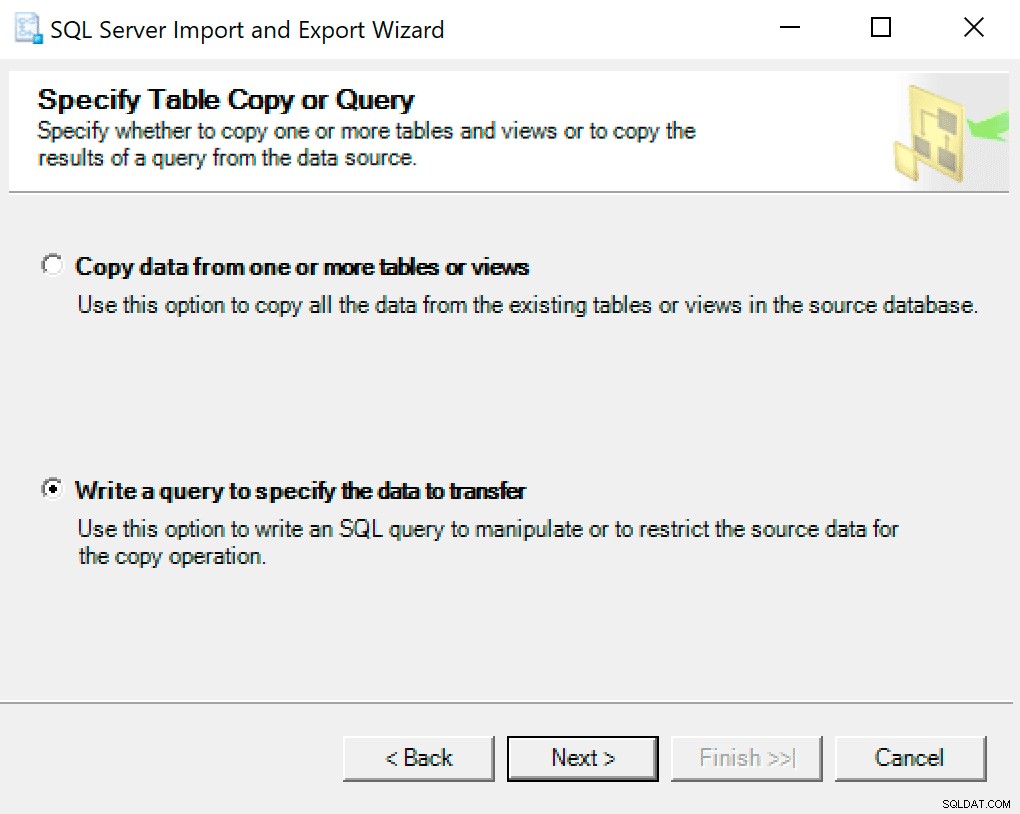
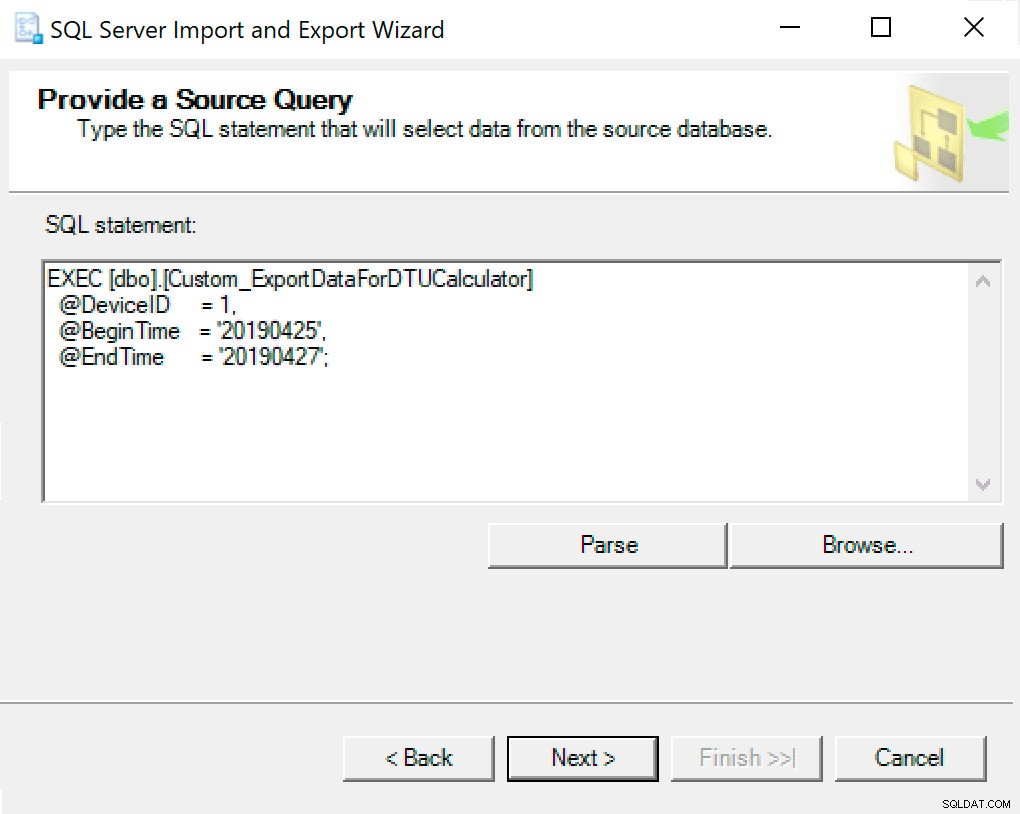
I det næste vindue skal du kopiere procedurekaldet med dine parametre indstillet i det. Tryk på næste.
Når du kommer til Configure Flat File Destination, lader jeg indstillingerne være standard. Her er et skærmbillede, hvis dit er anderledes:
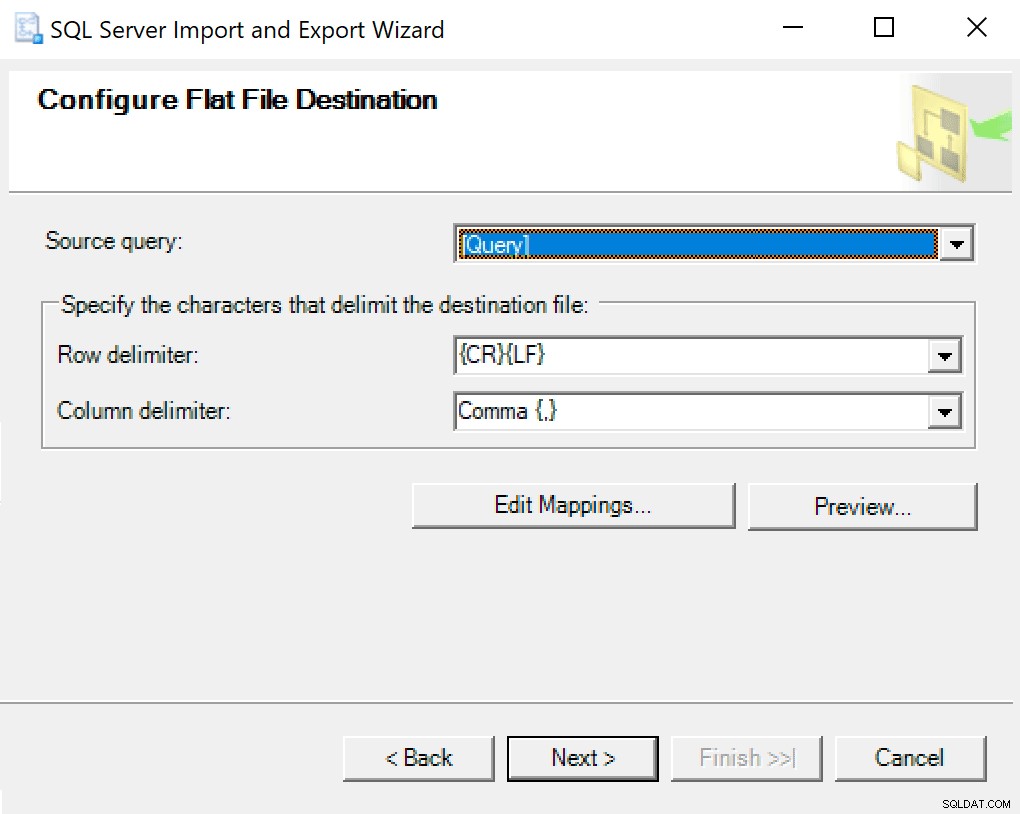
Tryk på næste og løb med det samme. Der oprettes en fil, som du vil bruge på det sidste trin.
BEMÆRK :Du kan oprette en SSIS-pakke til at bruge til dette og derefter sende dine parameterværdier til SSIS-pakken, hvis du kommer til at gøre dette meget. Dette ville forhindre dig i at skulle gennemgå guiden hver gang.
Naviger til det sted, hvor du gemte filen, og bekræft, at den er der. Når du åbner den, skal den se sådan ud:
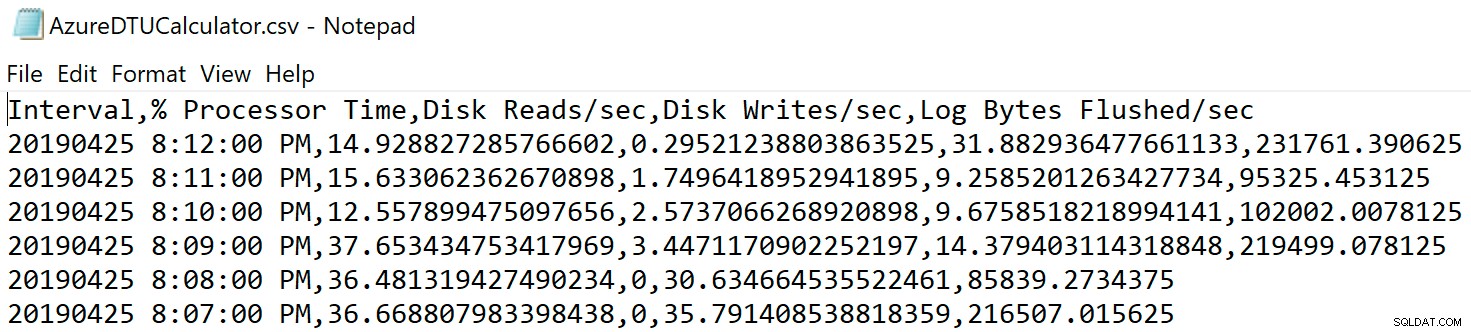
Åbn DTU-beregnerens websted, og rul ned til den del, der siger, "Upload CSV-filen og beregn." Indtast antallet af kerner, som serveren har, upload CSV-filen, og klik på Beregn. Du får et sæt resultater som dette (klik på et billede for at zoome):
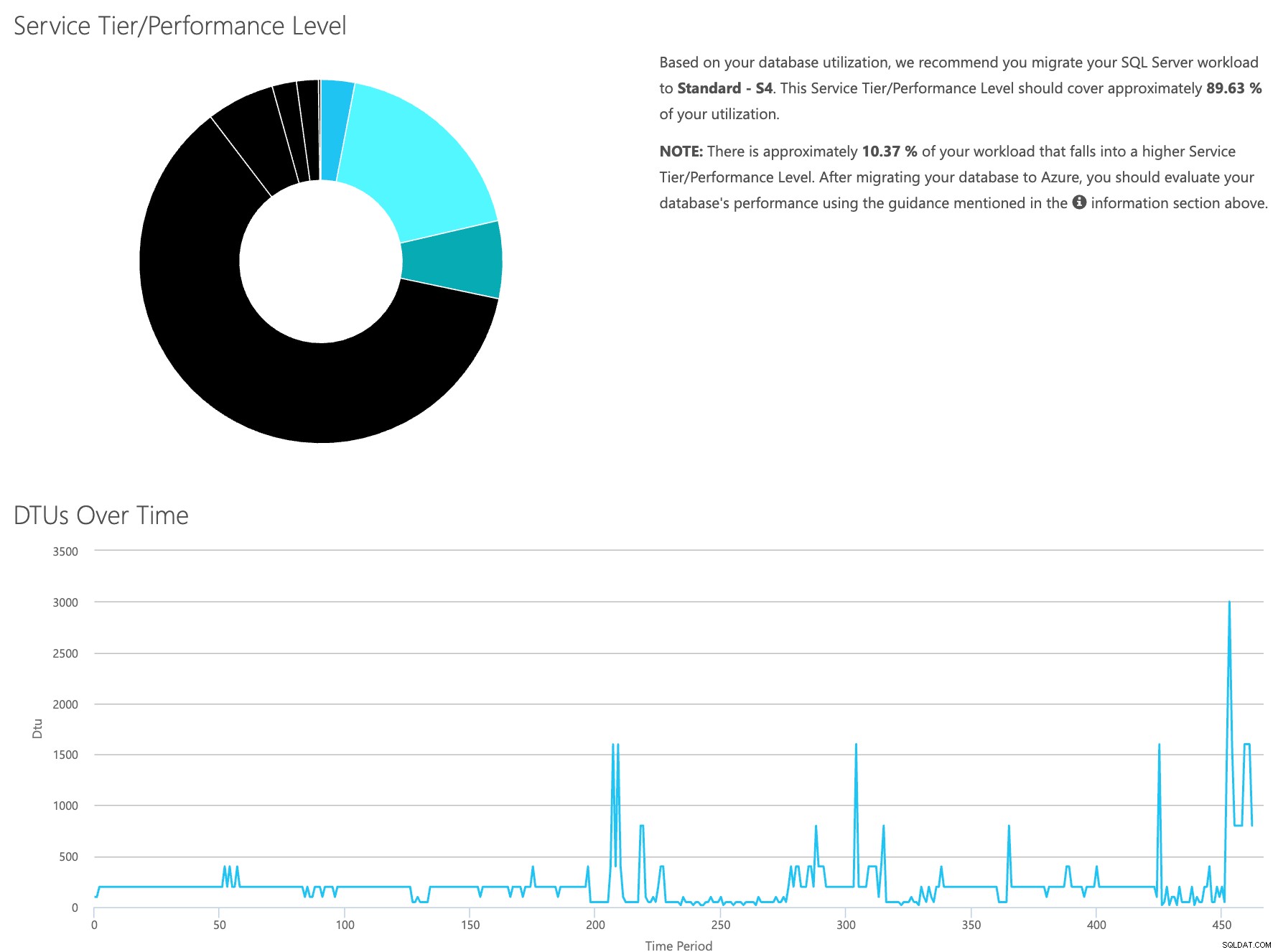
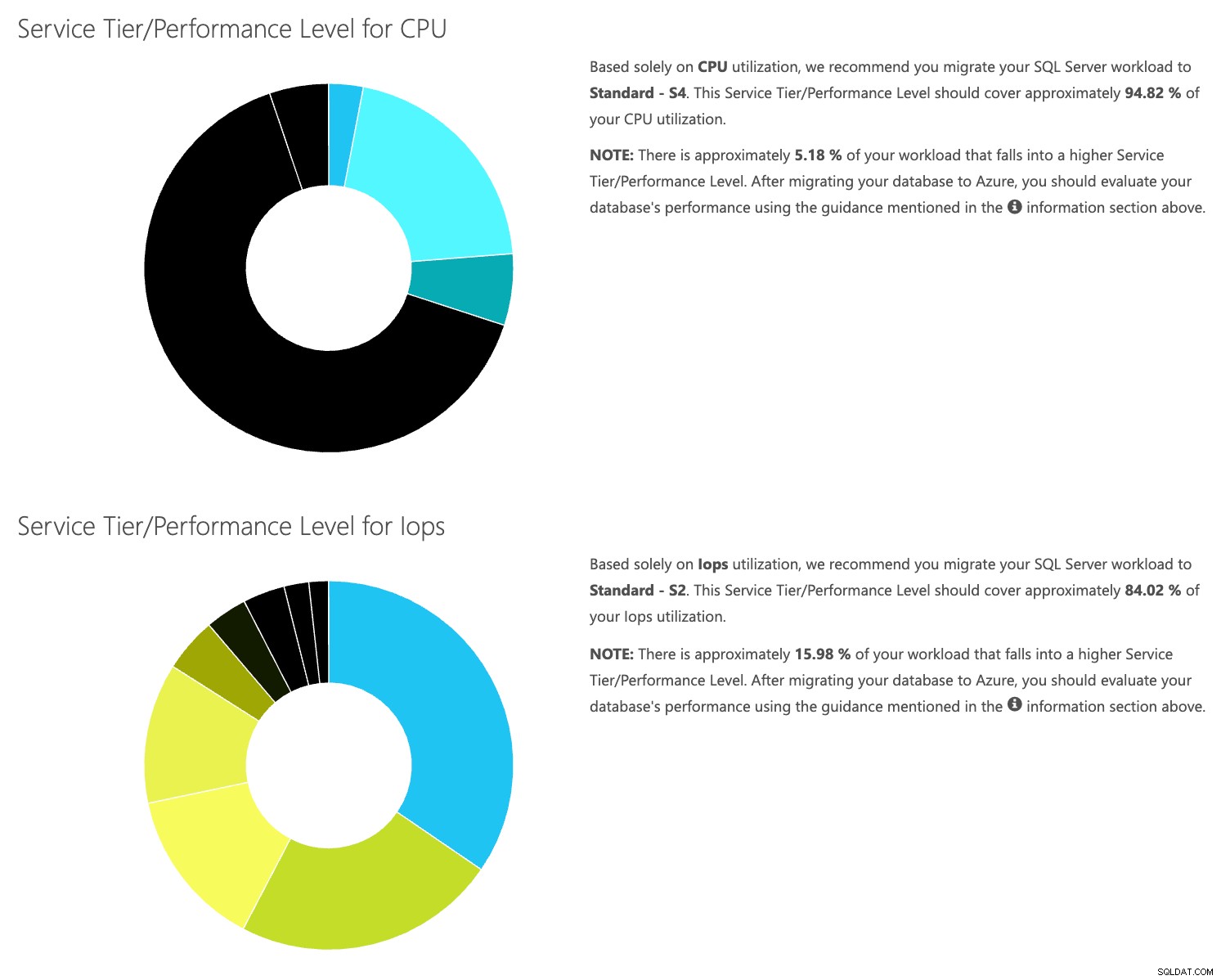
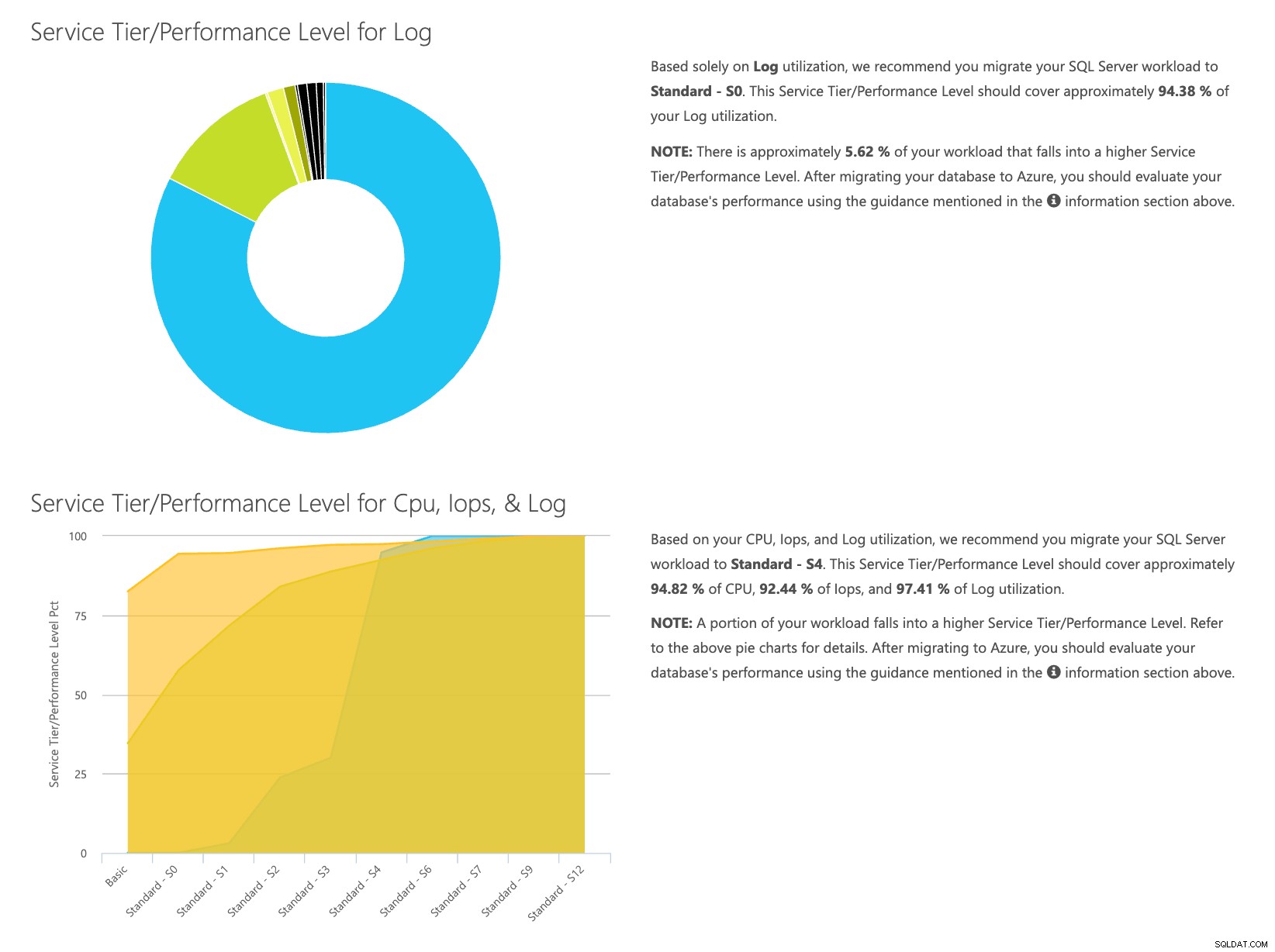
Da du har dataene gemt separat, kan du analysere arbejdsbelastninger fra forskellige tidspunkter, og du kan gøre dette uden manuelt at skulle køre\planlægge kommandoværktøjet\powershell-script for enhver server, du allerede bruger SentryOne til at overvåge.
For kort at opsummere trinene er her, hvad der skal gøres:
- Aktiver tælleren [Database – Log Bytes Flushed/sek], og bekræft, at dataene indsamles
- Kopiér dataene fra SentryOne-tabellerne til din egen tabel (og planlæg det, hvor det er relevant).
- Eksporter data fra ny tabel i det rigtige format til DTU-beregneren
- Upload CSV'en til DTU Lommeregneren
For enhver server/instans, du overvejer at migrere til skyen, og som du i øjeblikket overvåger med SQL Sentry, er dette en relativt smertefri måde at estimere både hvilken type serviceniveau du har brug for, og hvor meget det vil koste. Du skal dog stadig overvåge det, når det er deroppe; for det, tjek SentryOne DB Sentry.
Om forfatteren
 Dustin Dorsey er i øjeblikket Managing Database Engineer for LifePoint Health, hvor han leder et team, der er ansvarlig for administration og konstruktion af løsninger i databaseteknologier til 90 hospitaler. Han har arbejdet med og understøttet SQL Server overvejende i sundhedssektoren siden 2008 i en administrations-, arkitektur-, udviklings- og BI-kapacitet. Han brænder for at finde måder at løse problemer, der plager hverdagens DBA, og elsker at dele dette med andre. Han kan findes taler ved SQL-fællesskabsbegivenheder, såvel som blogger på DustinDorsey.com.
Dustin Dorsey er i øjeblikket Managing Database Engineer for LifePoint Health, hvor han leder et team, der er ansvarlig for administration og konstruktion af løsninger i databaseteknologier til 90 hospitaler. Han har arbejdet med og understøttet SQL Server overvejende i sundhedssektoren siden 2008 i en administrations-, arkitektur-, udviklings- og BI-kapacitet. Han brænder for at finde måder at løse problemer, der plager hverdagens DBA, og elsker at dele dette med andre. Han kan findes taler ved SQL-fællesskabsbegivenheder, såvel som blogger på DustinDorsey.com.