Dataprofessionelle får ikke altid brugt databaser, der har et optimalt design. Nogle gange er de ting, der får dig til at græde, ting, vi har gjort mod os selv, fordi de virkede som gode ideer på det tidspunkt. Nogle gange er de på grund af tredjepartsapplikationer. Nogle gange går de simpelthen før dig.
Den, jeg tænker på i dette indlæg, er, når din datetime (eller datetime2, eller endnu bedre, datetimeoffset) kolonne faktisk er to kolonner - en for datoen og en for tiden. (Hvis du har en separat spalte igen til forskydningen, så vil jeg give dig et kram næste gang, jeg ser dig, for du har sikkert skullet håndtere alle former for sår.)
Jeg lavede en undersøgelse på Twitter, og fandt ud af, at dette er et meget reelt problem, som omkring halvdelen af jer skal forholde sig til dato og tid fra tid til anden.
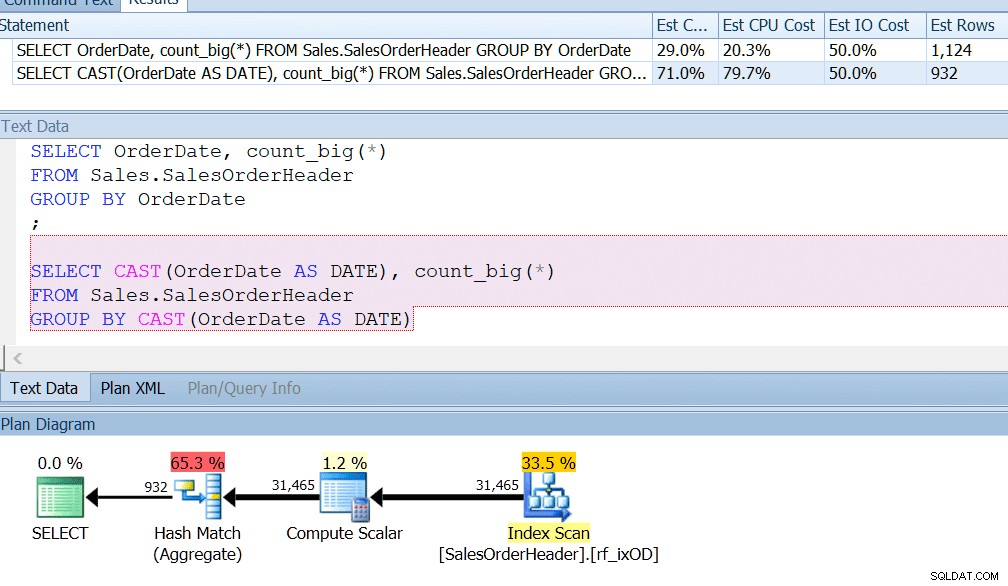
AdventureWorks gør næsten dette – hvis du kigger i Sales.SalesOrderHeader-tabellen, vil du se en datetime-kolonne kaldet OrderDate, som altid har nøjagtige datoer i sig. Jeg vil vædde på, at hvis du er rapportudvikler hos AdventureWorks, har du sikkert skrevet forespørgsler, der leder efter antallet af ordrer på en bestemt dag, ved at bruge GROUP BY OrderDate eller noget lignende. Selvom du vidste, at dette var en datetime-kolonne, og der var potentiale for, at den også kunne gemme en ikke-midnatstid, ville du stadig sige GROUP BY OrderDate bare for at bruge et indeks korrekt. GROUP BY CAST(OrderDate AS DATE) skærer det bare ikke.
Jeg har et indeks på OrderDate, som du ville, hvis du regelmæssigt forespurgte den kolonne, og jeg kan se, at gruppering efter CAST(OrderDate AS DATE) er omkring fire gange værre fra et CPU-perspektiv.
Så jeg forstår, hvorfor du ville være glad for at forespørge på din kolonne, som om det var en dato, blot ved at vide, at du vil have en verden af smerte, hvis brugen af den kolonne ændrer sig. Måske løser du dette ved at have en begrænsning på bordet. Måske putter du bare hovedet i sandet.
Og når nogen kommer og siger "Du ved, vi bør også gemme det tidspunkt, hvor ordrer sker", ja, du tænker på al den kode, der antager, at OrderDate simpelthen er en dato, og regner med, at der har en separat kolonne kaldet OrderTime (datatype tid, tak) vil være den mest fornuftige mulighed. Jeg forstår. Det er ikke ideelt, men det virker uden at gå i stykker for mange ting.
På dette tidspunkt anbefaler jeg, at du også laver OrderDateTime, som ville være en beregnet kolonne, der forbinder de to (hvilket du skal gøre ved at tilføje antallet af dage siden dag 0 til CAST(OrderDate som datotid2), i stedet for at forsøge at tilføje tiden til dato, som generelt er meget mere rodet). Og så indekser OrderDateTime, for det ville være fornuftigt.
Men ret ofte vil du finde dig selv med dato og klokkeslæt som separate kolonner, og du kan stort set ikke gøre noget ved det. Du kan ikke tilføje en beregnet kolonne, fordi det er et tredjepartsprogram, og du ved ikke, hvad der kan gå i stykker. Er du sikker på, at de aldrig gør SELECT *? En dag håber jeg, at de vil lade os tilføje kolonner og skjule dem, men indtil videre risikerer du helt sikkert at ødelægge ting.
Og du ved, selv msdb gør dette. De er begge heltal. Og det er på grund af bagudkompatibilitet, antager jeg. Men jeg tvivler på, at du overvejer at tilføje en beregnet kolonne til en tabel i msdb.
Så hvordan stiller vi spørgsmål til dette? Lad os antage, at vi vil finde de poster, der var inden for et bestemt dato- og tidsinterval?
Lad os eksperimentere lidt.
Lad os først oprette en tabel med 3 millioner rækker og indeksere de kolonner, vi holder af.
select identity(int,1,1) as ID, OrderDate,
dateadd(minute, abs(checksum(newid())) % (60 * 24), cast('00:00' as time)) as OrderTime
into dbo.Sales3M
from Sales.SalesOrderHeader
cross apply (select top 100 * from master..spt_values) v;
create index ixDateTime on dbo.Sales3M (OrderDate, OrderTime) include (ID); (Jeg kunne have lavet det til et klynget indeks, men jeg regner med, at et ikke-klynget indeks er mere typisk for dit miljø.)
Vores data ser sådan ud, og jeg vil gerne finde rækker mellem f.eks. 2. august 2011 kl. 8.30 og 5. august 2011 kl. 21.30.
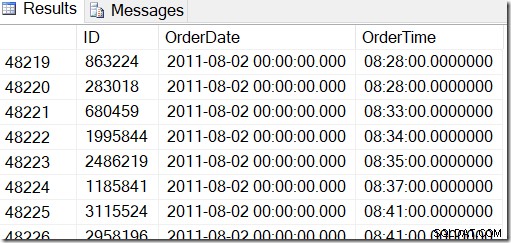
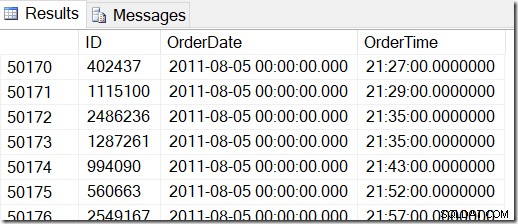
Ved at se dataene igennem kan jeg se, at jeg vil have alle rækkerne mellem 48221 og 50171. Det er 50171-48221+1=1951 rækker (+1'et er, fordi det er et inkluderende interval). Dette hjælper mig med at være sikker på, at mine resultater er korrekte. Du ville sandsynligvis have lignende på din maskine, men ikke nøjagtig, fordi jeg brugte tilfældige værdier, da jeg genererede min tabel.
Jeg ved godt, at jeg ikke bare kan gøre sådan noget her:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and OrderTime between '8:30' and '21:30';
…fordi dette ikke ville inkludere noget, der skete natten over den 4. Dette giver mig 1268 rækker - helt klart ikke rigtigt.
En mulighed er at kombinere kolonnerne:
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30';
Dette giver de rigtige resultater. Det gør det. Det er bare, at dette er fuldstændig ikke-sargerbart og giver os en scanning på tværs af alle rækkerne i vores tabel. På vores 3 millioner rækker kan det tage sekunder at køre dette.
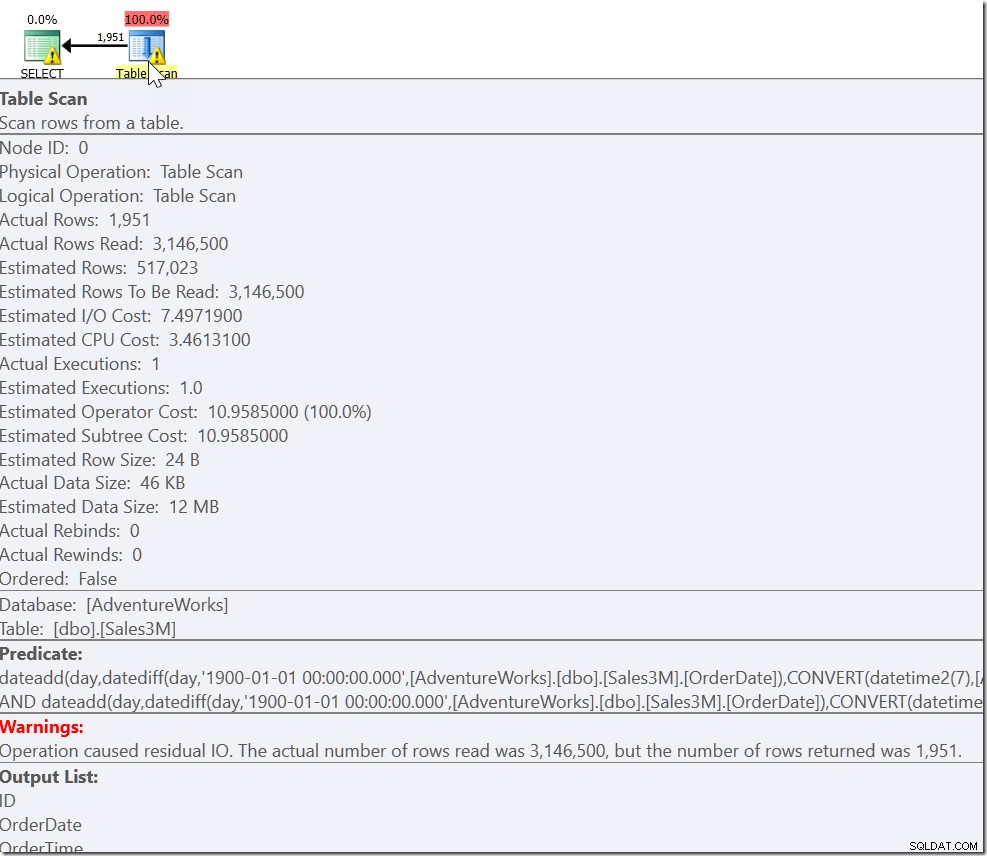
Vores problem er, at vi har en almindelig sag, og to specialsager. Vi ved, at hver række, der opfylder OrderDate> '20110802' OG OrderDate <'20110805', er en, vi ønsker. Men vi har også brug for hver række, der er på-eller-efter 8:30 på 20110802, og på-eller-før 21:30 på 20110805. Og det fører os til:
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') or (OrderDate = '20110802' and OrderTime >= '8:30') or (OrderDate = '20110805' and OrderTime <= '21:30');
OR er forfærdeligt, jeg ved det. Det kan også føre til scanninger, men ikke nødvendigvis. Her ser jeg tre indekssøgninger, der bliver sammenkædet og derefter kontrolleret for unikhed. Query Optimizer indser naturligvis, at den ikke bør returnere den samme række to gange, men er ikke klar over, at de tre betingelser er gensidigt udelukkende. Og faktisk, hvis du gjorde dette på et område inden for en enkelt dag, ville du få de forkerte resultater.
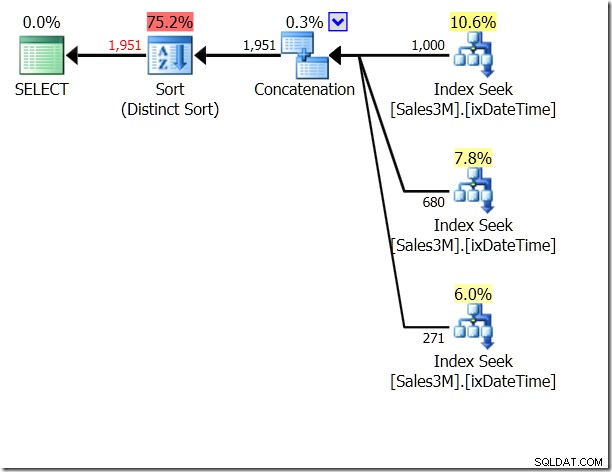
Vi kunne bruge UNION ALL på dette, hvilket ville betyde, at QO ville være ligeglad med, om betingelserne var gensidigt udelukkende. Dette giver os tre søgninger, der er sammenkædet - det er ret godt.
select * from dbo.Sales3M where (OrderDate > '20110802' and OrderDate < '20110805') union all select * from dbo.Sales3M where (OrderDate = '20110802' and OrderTime >= '8:30') union all select * from dbo.Sales3M where (OrderDate = '20110805' and OrderTime <= '21:30');

Men det er stadig tre søgninger. Statistik IO fortæller mig, at det er 20 aflæsninger på min maskine.

Når jeg nu tænker på sargability, tænker jeg ikke kun på at undgå at sætte indekskolonner inde i udtryk, jeg tænker også på, hvad der kan hjælpe noget synes sargerbar.
Tag for eksempel WHERE LastName LIKE 'Far%'. Når jeg ser på planen for dette, ser jeg en Seek, med et Seek-prædikat leder efter ethvert navn fra Langt op til (men ikke inklusive) FaS. Og så er der et restprædikat, der kontrollerer LIKE-tilstanden. Dette er ikke fordi QO'en mener, at LIKE er sargable. Hvis det var, ville det være i stand til at bruge LIKE i Seek-prædikatet. Det er fordi den ved, at alt, der er opfyldt af den LIKE-tilstand, skal være inden for det interval.
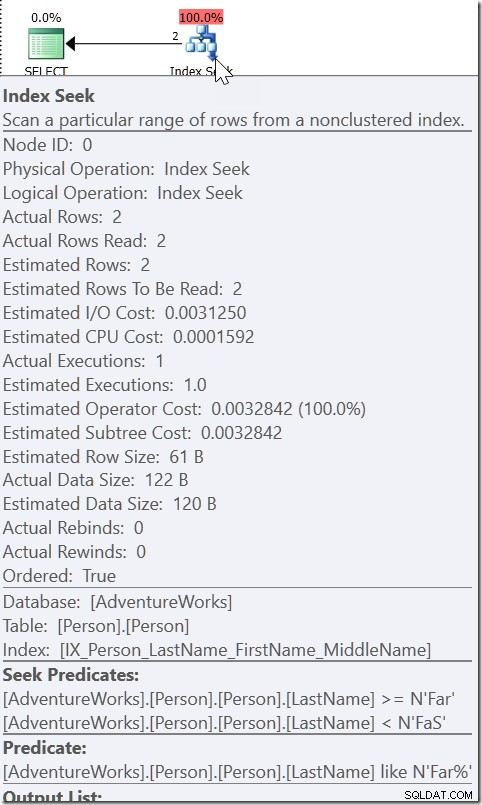
Tag WHERE CAST(OrderDate AS DATE) ='20110805'
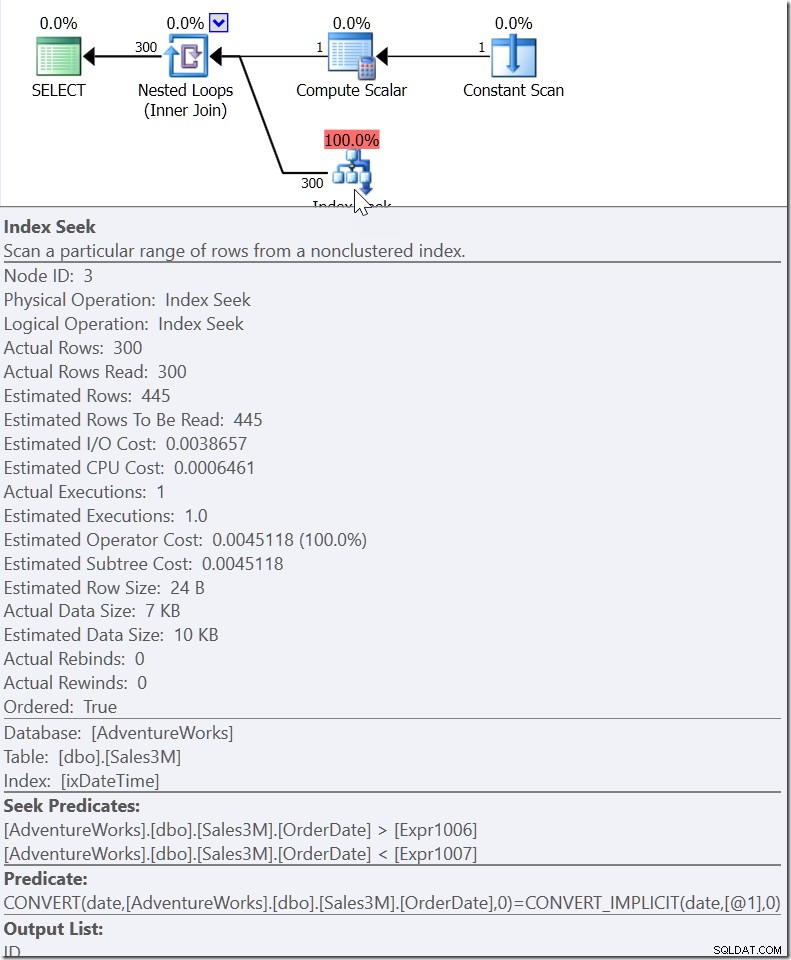
Her ser vi et Seek-prædikat, der leder efter OrderDate-værdier mellem to værdier, der er udarbejdet andre steder i planen, men som skaber et interval, hvori de rigtige værdier skal eksistere. Dette er ikke>=20110805 00:00 og <20110806 00:00 (hvilket er hvad jeg ville have lavet det), det er noget andet. Værdien for starten af dette område skal være mindre end 20110805 00:00, fordi det er>, ikke>=. Alt, hvad vi virkelig kan sige, er, at når nogen inden for Microsoft implementerede, hvordan QO'en skulle reagere på denne form for prædikat, gav de det nok information til at komme med det, jeg kalder et "hjælperprædikat."
Nu ville jeg elske, at Microsoft gjorde flere funktioner sargable, men den særlige anmodning blev lukket længe før de trak sig tilbage Connect.
Men det, jeg mener, er måske, at de laver flere hjælperprædikater.
Problemet med hjælpeprædikater er, at de næsten helt sikkert læser flere rækker, end du ønsker. Men det er stadig meget bedre end at se hele indekset igennem.
Jeg ved, at alle de rækker, jeg vil returnere, vil have OrderDate mellem 20110802 og 20110805. Det er bare, at der er nogle, jeg ikke vil have.
Jeg kunne bare fjerne dem, og dette ville være gyldigt:
select * from dbo.Sales3M where OrderDate between '20110802' and '20110805' and not (OrderDate = '20110802' and OrderTime < '8:30') and not (OrderDate = '20110805' and OrderTime > '21:30');
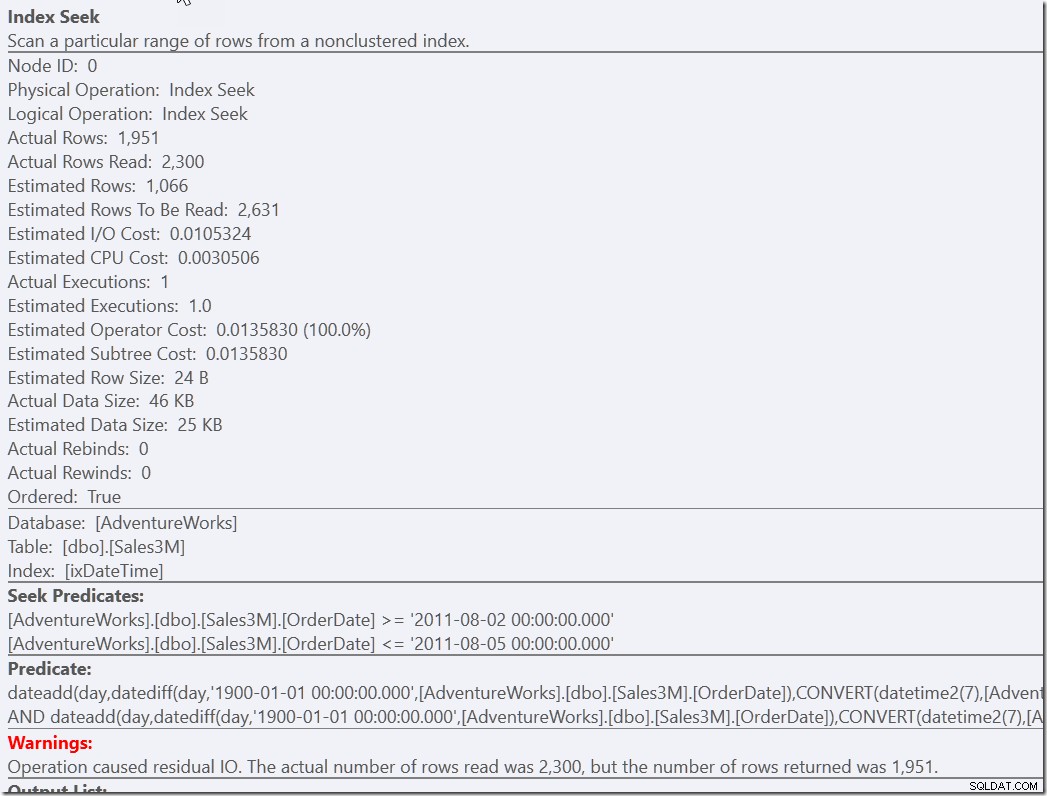
Men jeg føler, at det her er en løsning, som kræver en del omtanke at komme frem til. Mindre indsats fra udviklerens side er blot at give et hjælpeprædikat til vores korrekte-men-langsomme version.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' and OrderDate between '20110802' and '20110805';
Begge disse forespørgsler finder de 2300 rækker, der er på de rigtige dage, og skal derefter kontrollere alle disse rækker mod de andre prædikater. Den ene skal tjekke de to IKKE-betingelser, den anden skal lave noget typekonvertering og matematik. Men begge er meget hurtigere end hvad vi havde før, og gør en enkelt søgning (13 læsninger). Selvfølgelig får jeg advarsler om en ineffektiv RangeScan, men dette foretrækker jeg frem for at lave tre effektive.
På nogle måder er det største problem med dette sidste eksempel, at en velmenende person ville se, at hjælperprædikatet var overflødigt og måske slette det. Dette er tilfældet med alle hjælperprædikater. Så skriv en kommentar.
select * from dbo.Sales3M where dateadd(day,datediff(day,0,OrderDate),cast(OrderTime as datetime2)) between '20110802 8:30' and '20110805 21:30' /* This next predicate is just a helper to improve performance */ and OrderDate between '20110802' and '20110805';
Hvis du har noget, der ikke passer ind i et pænt sargerbart prædikat, skal du finde et, og derefter finde ud af, hvad du skal udelukke fra det. Måske kommer du bare med en bedre løsning.
@rob_farley