I februar skrev jeg et blogindlæg om Automatic Plan Correction i SQL Server, og i dette indlæg vil jeg tale om Automatic Index Management, den anden komponent i Automatic Tuning-funktionen. Automatisk indeksstyring er kun tilgængelig i Azure SQL Database, og den er i øjeblikket ikke på køreplanen til at være tilgængelig i den næste udgivelse af SQL Server on-premises. Denne mulighed er aktiveret uafhængigt af automatisk plankorrektion, og som navnet antyder, vil den administrere indekser i din database. Specifikt kan det oprette indekser, der mangler, og det kan fjerne indekser, der ikke bruges, og dem, der er dubletter. Lad os tage et kig på, hvordan dette sker.
Under dynen
Automatisk indeksstyring er afhængig af data for at træffe sin beslutning. Til potentiel indeksoprettelse bruger den information om det manglende indeks DMV og sporer det over tid og kombinerer disse data med en intern model for at bestemme fordelen ved indekset. Den bruger også Query Store til at bestemme, om indekset giver fordele, så det skal være aktiveret for databasen, ligesom med Automatisk plankorrektion. Med hensyn til at droppe indekser anvendes data fra indeksbrug DMV (sys.dm_db_index_usage_stats) samt indeksmetadata (f.eks. antal kolonner, kolonnedatatyper).
Aktivering af automatisk indeksstyring
Som nævnt skal Query Store være aktiveret for databasen. Dette kan gøres i SSMS, med T-SQL og med REST API til Azure SQL Database. Bemærk, at Query Store er aktiveret som standard for databaser i Azure og har været det siden 2016 Q4.
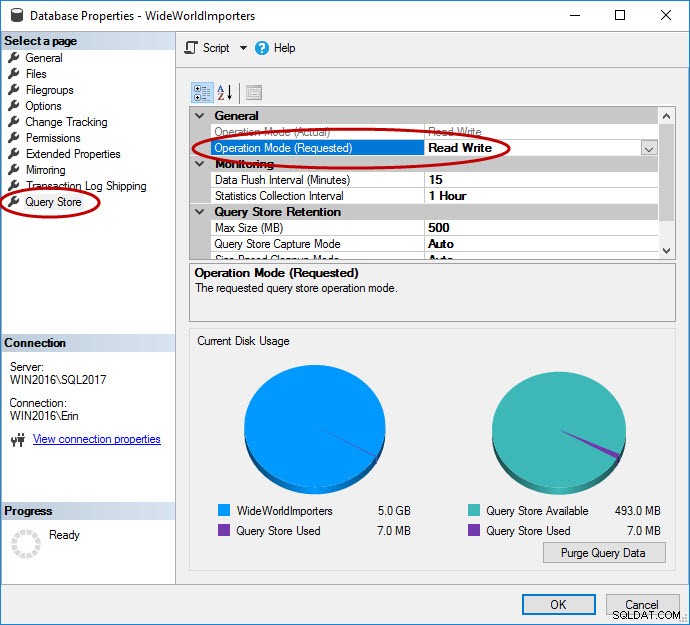
USE [master]; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE = ON; GO ALTER DATABASE [WideWorldImporters] SET QUERY_STORE (OPERATION_MODE = READ_WRITE); GO
Når Query Store er aktiveret, kan du bruge Azure Portal, T-SQL eller EST API til at aktivere Automatic Index Management i Azure SQL Database (C# og PowerShell er under arbejde).
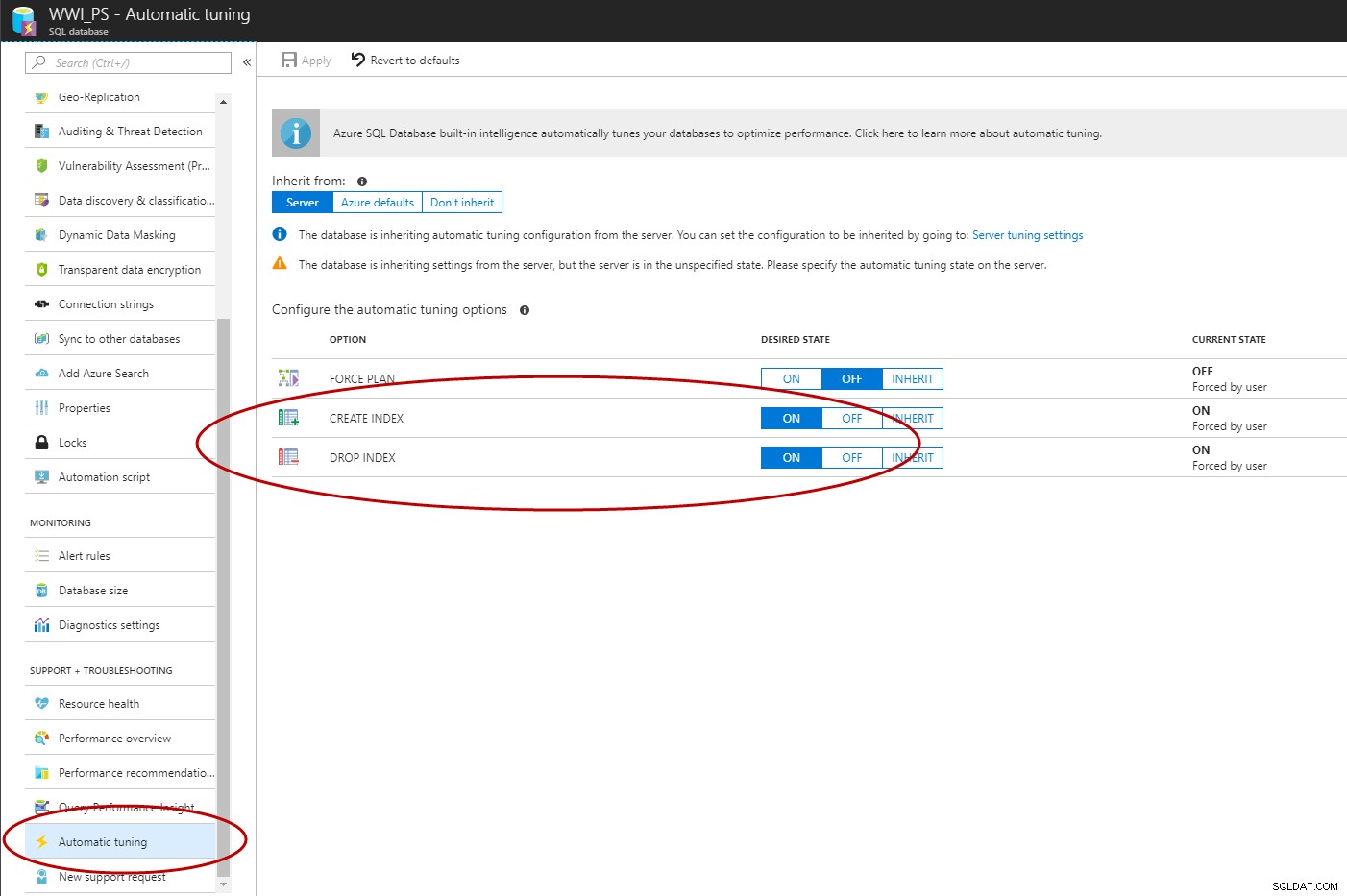
ALTER DATABASE [WWI_PS] SET AUTOMATIC_TUNING (CREATE_INDEX = ON, DROP_INDEX = ON); GO
Automatisk indeksstyring vil blive aktiveret som standard for nye databaser i Azure (https://azure.microsoft.com/en-us/blog/automatic-tuning-will-be-a-new-default/) i den nærmeste fremtid. Fra januar 2018 startede Microsoft udrulningen for at aktivere Automatisk tuning for Azure SQL-databaser, der ikke allerede havde det aktiveret, med meddelelser sendt til administratorer, så muligheden kan deaktiveres, hvis det ønskes. Denne proces tager flere måneder, så hvis du ikke har fået en notifikation endnu, skal du ikke gå i panik!
Sådan fungerer det
Til oprettelse af indeks er der i øjeblikket et rullende vindue på syv (7) dage*, som dataene spores over, og som minimum har modellen brug for ni (9) timers* data for at anbefale et indeks sammen med med 12 timers* data i Query Store, der vil blive brugt som en baseline. Hvis det er fastslået, at et indeks vil give en betydelig fordel, vil SQL Server oprette indekset.
*Disse værdier kan ændre sig i fremtiden, efterhånden som modellen udvikler sig.
Bemærk:på nuværende tidspunkt kombinerer modellen anbefalinger. Det vil sige, at hvis der anbefales flere indekser til en tabel, men der kan oprettes et indeks til at dække alle muligheder, kan det oprette det ene indeks i øjeblikket. Modellen er dog i øjeblikket ikke intelligent nok til at fusionere et anbefalet indeks med et, der allerede eksisterer.
Når et indeks er oprettet, verificerer SQL Server, at det giver fordele ved hjælp af Query Store (det skal derfor være aktiveret for databasen). Den overvåger ydeevnen af enhver forespørgsel, der bruger det nye indeks, og sammenligner forespørgslens CPU, før indekset blev tilføjet, og når indekset blev brugt. Hvis der er en regression i forespørgselsydeevne som et resultat af indekset, vil det vende tilbage (drop) indekset. SQL Server overvåger forespørgselsydeevne i op til tre (3) dage, eller indtil 100 % af den relevante arbejdsbyrde er blevet analyseret. Efter denne tidsperiode, hvis indekset ikke viser nogen tegn på regression, vil det ikke gennemgå ydeevnen for det igen.
Forstå, at hvis Automatic Index Management opretter et indeks og derefter to måneder senere ændrer din arbejdsbyrde sig, og det ville drage fordel af det samme indeks, der blev oprettet automatisk tidligere, men med en ekstra kolonne, så vil SQL Server i øjeblikket oprette et nyt indeks. I øjeblikket er der ingen logik til at ændre et eksisterende automatisk oprettet indeks, men den funktionalitet er på køreplanen for funktionen.
Med hensyn til at slette indekser, hvis et indeks ikke har nogen søgninger eller scanninger i 90 dage, men har en vedligeholdelsesomkostning (hvilket betyder, at der er indsættelser, opdateringer eller sletninger), så vil det blive slettet. Duplikerede indekser vil også blive fjernet, forudsat at de er en nøjagtig dublet (og skemaet bruges til at bestemme, om indekser er nøjagtigt ens). Hvis der er duplikerede indekser med hensyn til nøglekolonner og inkluderede kolonner (hvis relevant), men en eller flere af dem har et filter, så er de ikke ægte duplikerede, og ingen indekser vil blive slettet.
Til reference er der to gange så mange DROP INDEX-anbefalinger i Azure SQL Database, som der er CREATE INDEX-anbefalinger.
Når du aktiverer indstillingen DROP INDEX, vil SQL Server slette brugeroprettede indekser. Når du aktiverer CREATE INDEX-indstillingen, har SQL Server mulighed for at oprette indekser automatisk og kan også droppe disse indekser (men vil ikke droppe brugeroprettede indekser). Til sidst oprettes og droppes indekser i perioder med ikke-spidsbelastning, som bestemt af DTU. Hvis arbejdsbelastningen er over 80 % DTU, vil SQL Server vente med at oprette eller slette indekset, indtil systembelastningen falder.
Skal jeg virkelig lade SQL Server have kontrol?
Måske. Min anbefaling om denne funktion kræver i første omgang en "trust but verify"-tilgang.
Som med automatisk plankorrektion er Automatic Index Management blevet udviklet med en betydelig mængde data, der er indsamlet fra næsten to millioner Azure SQL-databaser. Funktionen Automatic Index Management har været tilgængelig i Azure SQL Database siden 1. kvartal 2016, som en del af Index Advisor.
Algoritmerne, der bruges af funktionen, har udviklet sig og fortsætter med at udvikle sig over tid, efterhånden som flere databaser bruger den, og flere data bliver fanget og analyseret. Der er dog nogle begrænsninger i øjeblikket.
- Indeks-anbefalinger evalueres ikke i forhold til eksisterende indekser, så indekskonsolidering mellem nye og eksisterende indekser er ikke tilgængelig i øjeblikket.
- Hvis et indeks ville give fordele for en SELECT, er overheaden af ændringer på grund af INSERTs, UPDATEs og DELETEs ikke kendt før oprettelsen. SQL Server overvåger denne overhead under verifikationsprocessen, efter at indekset er implementeret.
Der er fordele ved automatisk indeksstyring, som er værd at nævne:
- For alle, der skal administrere en SQL Server-database, men ikke er en DBA, kan indeksanbefalinger være yderst nyttige.
- Indeks-anbefalinger er fanget i sys.dm_db_tuning_recommendations DMV, selvom CREATE og DROP indeksindstillingerne ikke er aktiveret. Derfor, hvis du er usikker på de ændringer, SQL Server kan foretage, kan du gennemgå, hvad der er fanget i DMV'en og derefter træffe en beslutning om manuelt at implementere anbefalingen.
Bemærk:Hvis du implementerer anbefalingen manuelt, udfører SQL Server ingen validering. Hvis du implementerer anbefalingen via portalen (ved hjælp af knappen Anvend) eller REST API, vil den blive eksekveret, som om det var en automatisk handling, og validering vil blive udført (og indekset kan automatisk vendes tilbage, hvis der er en regression).
- Funktionen bliver ved med at blive bedre. Som jeg har sagt før, forsøger Microsoft ikke at kode DBA'er eller udviklere uden arbejde, det forsøger at adressere de lavthængende frugter, så du har mere tid til de opgaver og projekter, der ikke kan automatiseres intelligent.
Oversigt
Hvis du ikke er klar til at overlade tøjlerne til indeksstyring, så forstår jeg det. Men hvis du som minimum har en Azure SQL-database, bør du tjekke sys.dm_db_tuning_recommendations DMV regelmæssigt for at se, hvad SQL Server anbefaler, og sammenligne det med data, du eller dit tredjepartsovervågningsværktøj muligvis fanger om indeksbrug. Når alt kommer til alt, hvornår har du sidst lavet en fuldstændig og grundig gennemgang af dine indekser for at forstå, hvad der mangler, hvad der virkelig bliver brugt, og hvad der simpelthen genererer overhead i databasen?