Oversigt
Denne artikel diskuterer to forskellige tilgængelige tilgange til at fjerne duplikerede rækker fra SQL-tabeller, hvilket ofte bliver svært over tid, efterhånden som data vokser, hvis dette ikke gøres til tiden.
Tilstedeværelsen af duplikerede rækker er et almindeligt problem, som SQL-udviklere og -testere oplever fra tid til anden, men disse duplikerede rækker falder ind under en række forskellige kategorier, som vi vil diskutere i denne artikel.
Denne artikel fokuserer på et specifikt scenarie, når data indsat i en databasetabel, fører til introduktionen af duplikerede poster, og så vil vi se nærmere på metoder til at fjerne dubletter og til sidst fjerne dubletterne ved hjælp af disse metoder.
Forberedelse af prøvedata
Før vi begynder at udforske de forskellige tilgængelige muligheder for at fjerne dubletter, er det værd på dette tidspunkt at oprette en prøvedatabase, som vil hjælpe os med at forstå situationerne, hvor duplikerede data kommer ind i systemet, og de metoder, der skal bruges til at udrydde dem .
Opsæt Sample Database (UniversityV2)
Start med at lave en meget simpel database, som kun består af en elev tabel i begyndelsen.
-- (1) Opret UniversityV2 eksempeldatabaseCREATE DATABASE UniversityV2;GOUSE UniversityV2CREATE TABLE [dbo].[Student] ( [StudentId] INT IDENTITY (1, 1) IKKE NULL, [Navn] VARCHAR (30) NULL , [Kursus] VARCHAR (30) NULL, [Mærker] INT NULL, [Eksamensdato] DATETIME2 (7) NULL, BEGRÆNSNING [PK_Student] PRIMÆR NØGLE KLUSTERET ([StudentId] ASC)); Populér elevtabel
Lad os kun tilføje to poster til elevtabellen:
-- Tilføjelse af to poster til elevtabellenSET IDENTITY_INSERT [dbo].[Student] ONINSERT INTO [dbo].[Student] ([StudentId], [Navn], [Kursus], [Marks], [ ExamDate]) VALUES (1, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')INSERT INTO [dbo].[Student] ([StudentId], [ Navn], [Kursus], [Karakterer], [Eksamensdato]) VALUES (2, N'Peter', N'Database Management System', 85, N'2016-01-01 00:00:00')SET IDENTITY_INSERT [ dbo].[Student] FRA Datatjek
Se tabellen, som indeholder to forskellige poster i øjeblikket:
-- Se elevtabeldata VÆLG [StudentId] ,[Navn],[Kursus],[Karakterer] ,[Eksamensdato] FRA [UniversityV2].[dbo].[Student] 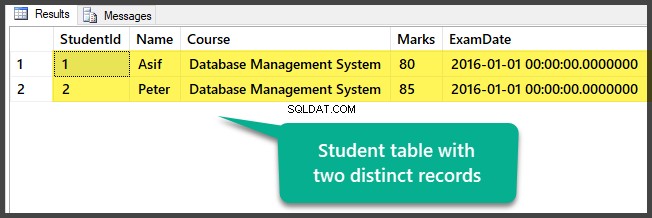
Du har klargjort prøvedataene ved at oprette en database med én tabel og to forskellige (forskellige) poster.
Vi vil nu diskutere nogle potentielle scenarier, hvor dubletter blev introduceret og slettet fra simple til lidt komplekse situationer.
Case 01:Tilføjelse og fjernelse af dubletter
Nu skal vi introducere dublerede række(r) i elevtabellen.
Forudsætninger
I dette tilfælde siges en tabel at have duplikerede poster, hvis en elevs navn , Kursus , Mærker og Eksamensdato falder sammen i mere end én post, selvom elevens ID er anderledes.
Så vi antager, at ikke to studerende kan have samme navn, kursus, karakterer og eksamensdato.
Tilføjelse af dublerede data for Student Asif
Lad os bevidst indsætte en dubletpost for Student:Asif til eleven tabel som følger:
-- Tilføjelse af Student Asif duplikatpost til Student-tabellenSET IDENTITY_INSERT [dbo].[Student] ONINSERT INTO [dbo].[Student] ([StudentId], [Navn], [Kursus], [Marks] , [ExamDate]) VALUES (3, N'Asif', N'Database Management System', 80, N'2016-01-01 00:00:00')SET IDENTITY_INSERT [dbo].[Student] FRA Se dublerede elevdata
Se eleven tabel for at se dublerede poster:
-- Se elevtabeldata VÆLG [StudentId] ,[Navn],[Kursus],[Karakterer] ,[Eksamensdato] FRA [UniversityV2].[dbo].[Student] 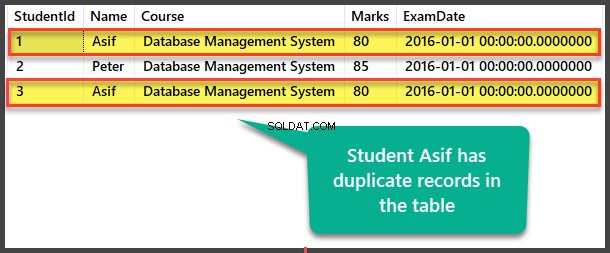
Find dubletter ved hjælp af selvhenvisningsmetode
Hvad hvis der er tusindvis af poster i denne tabel, så vil det ikke være megen hjælp at se tabellen.
I selvreferencemetoden tager vi to referencer til den samme tabel og forbinder dem ved hjælp af kolonne-for-kolonne mapping med undtagelse af ID'et, som er mindre end eller større end det andet.
Lad os se på selvreferencemetoden for at finde dubletter, der ser sådan ud:
BRUG UniversityV2-- Selvreferencemetode til at finde dobbeltstuderende med samme navn, kursus, karakterer, eksamensdato. VÆLG S1.[StudentId] som S1_StudentId,S2.StudentId as S2_StudentID ,S1.Name AS S1_Name, S2. Navn som S2_Navn ,S1.Kursus AS S1_Kursus, S2.Kursus som S2_Kursus ,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate FROM [dbo].[Student] S1,[dbo].[Student] S.2 S2.StudentId OG S1.Name=S2.Name OG S1.Course=S2.Course OG S1.Marks=S2.Marks OG S1.ExamDate=S2.ExamDate Outputtet af ovenstående script viser os kun de duplikerede poster:

Find dubletter ved hjælp af selvreferencemetode-2
En anden måde at finde dubletter ved hjælp af selvreference er at bruge INNER JOIN som følger:
-- Selvreferencemetode 2 til at finde dubletstuderende med samme navn, kursus, karakterer, eksamensdatoSELECT S1.[StudentId] as S1_StudentId,S2.StudentId as S2_StudentID ,S1.Name AS S1_Name, S2.Name as S2_Name ,S1.Course AS S1_Course, S2.Course as S2_Course ,S1.ExamDate as S1_ExamDate, S2.ExamDate AS S2_ExamDate FRA [dbo].[Student] S1 INDRE JOIN [dbo].[Navn S1].[Student] S2.Name AND S1.Course=S2.Course AND S1.Marks=S2.Marks AND S1.ExamDate=S2.ExamDate WHERE S1.StudentId<S2.StudentId 
Fjernelse af dubletter ved hjælp af selvhenvisningsmetode
Vi kan fjerne dubletterne ved at bruge den samme metode, som vi brugte til at finde dubletter med undtagelse af at bruge DELETE i overensstemmelse med dets syntaks som følger:
BRUG UniversityV2-- Fjernelse af dubletter ved hjælp af selvreferencemetodeDELETE S2 FROM [dbo].[Student] S1, [dbo].[Student] S2WHERE S1.StudentId < S2.StudentId OG S1.Name =S2.Name AND S1.Course =S2.Course AND S1.Marks =S2.Marks AND S1.ExamDate =S2.ExamDate Datakontrol efter fjernelse af dubletter
Lad os hurtigt tjekke registreringerne, efter at vi har fjernet dubletterne:
BRUG UniversityV2-- Se studerendes data, efter dubletter er blevet fjernet. VÆLG [StudentId],[Navn] ,[Kursus],[Karakterer] ,[ExamDate]FRA [UniversityV2].[dbo].[Student] 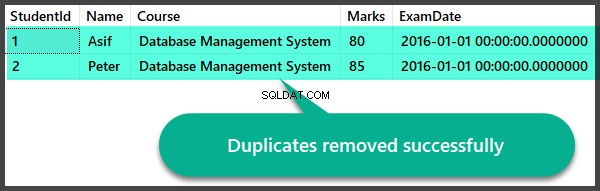
Oprettelse af dubletter, visning og fjernelse af dubletter, lagret procedure
Nu hvor vi ved, at vores scripts med succes kan finde og slette duplikerede rækker i SQL, er det bedre at omdanne dem til visning og lagret procedure for at lette brugen:
USE UniversityV2;GO-- Oprettelse af visning find dobbelte studerende med samme navn, kursus, karakterer, eksamensdato ved hjælp af selvreferencemetodeCREATE VIEW dbo.DuplicatesASSELECT S1.[StudentId] AS S1_StudentId ,S2.StudentId AS S2_Studen S1.Name AS S1_Name ,S2.Name AS S2_Name ,S1.Course AS S1_Course ,S2.Course AS S2_Course ,S1.ExamDate AS S1_ExamDate ,S2.ExamDate AS S2_ExamDateFROM [dbo].]1[Student]Studentbo S.]1 ] S2WHERE S1.StudentId < S2.StudentIdAND S1.Name =S2.Name [dbo].[Student] S1, [dbo].[Student] S2 WHERE S1.StudentId < S2.StudentId OG S1.Name =S2.Name AND S1.Course =S2.Course AND S1.Marks =S2.Marks AND S1.ExamDate =S2.ExamDateEND
Tilføjelse og visning af flere duplikerede poster
Lad os nu føje yderligere fire poster til Studenten tabel og alle posterne er dubletter på en sådan måde, at de har samme navn, kursus, karakterer og eksamensdato:
--Tilføjelse af flere dubletter til elevtabelINSERT INTO Student (navn, kursus, karakterer, eksamensdato) VÆRDIER ('Peter', 'Database Management System', 85, '2016-01-01'), (' Peter', 'Database Management System', 85, '2016-01-01'), ('Peter', 'Database Management System', 85, '2016-01-01'), ('Peter', 'Database Management System' System', 85, '2016-01-01');-- Visning af elevtabel efter flere poster er blevet tilføjet til elevtabel.VÆLG [StudentId],[Navn] ,[Kursus],[Karakterer] ,[Eksamensdato]FRA [UniversityV2 ].[dbo].[Student] 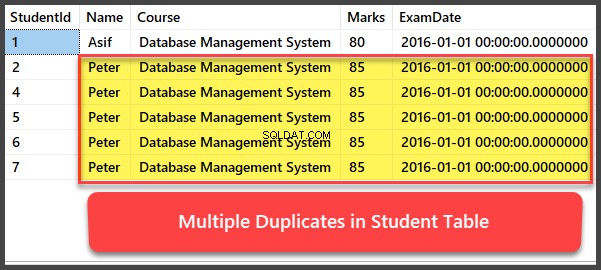
Fjernelse af dubletter ved hjælp af UspRemoveDuplicates-proceduren
BRUG UniversityV2-- Fjernelse af flere dubletterEXEC UspRemoveDuplicates
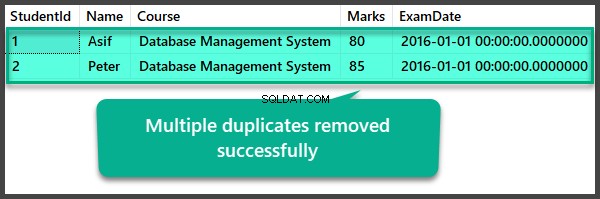
Datakontrol efter fjernelse af flere dubletter
BRUG UniversityV2--Se elevtabel efter fjernelse af flere dubletter.VÆLG [StudentId] ,[Navn] ,[Kursus] ,[Karakterer] ,[ExamDate]FRA [UniversityV2].[dbo].[Student]
Case 02:Tilføjelse og fjernelse af dubletter med samme id'er
Indtil videre har vi identificeret duplikerede poster med forskellige ID'er, men hvad nu hvis ID'erne er de samme.
Tænk f.eks. på scenariet, hvor en tabel for nylig er blevet importeret fra en tekst- eller Excel-fil, der ikke har nogen primær nøgle.
Forudsætninger
I dette tilfælde siges en tabel at have duplikerede poster, hvis alle kolonneværdierne er nøjagtigt ens, inklusive en eller anden ID-kolonne, og den primære nøgle mangler, hvilket gjorde det nemmere at indtaste dubletposterne.
Opret kursustabel uden primærnøgle
For at reproducere scenariet, hvor duplikerede poster i fravær af en primær nøgle falder ind i en tabel, lad os først oprette et nyt Kursus tabel uden nogen primær nøgle i University2-databasen som følger:
BRUG UniversityV2-- Oprettelse af kursustabel uden primær nøgleCREATE TABLE [dbo].[Course] ( [CourseId] INT NOT NULL, [Name] VARCHAR (30) NOT NULL, [Detaljer] VARCHAR (200) NULL , ); Udfyld kursustabel
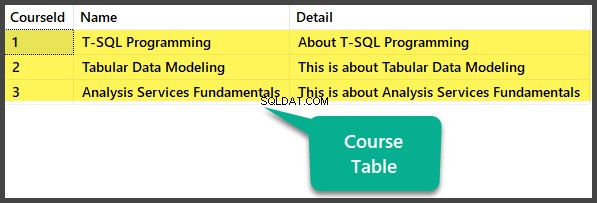
-- Udfylder kursustabelINDSÆT I [dbo].[Kursus] ([CourseId], [Navn], [Detalje]) VÆRDIER (1, N'T-SQL-programmering', N'Om T-SQL Programmering')INSERT INTO [dbo].[Kursus] ([CourseId], [Navn], [Detaljer]) VÆRDIER (2, N'Tabular Data Modeling', N'Dette handler om tabelular Data Modeling')INSERT INTO [dbo ].[Kursus] ([CourseId], [Navn], [Detaljer]) VÆRDIER (3, N'Analysis Services Fundamentals', N'This is about Analysis Services Fundamentals') Datatjek
Se Kurset tabel:
BRUG UniversityV2-- Visning af kursustabelSELECT CourseId ,Name , Detail FROM dbo.Course
Tilføjelse af dublerede data i kursustabel
Indsæt nu dubletter i Kurset tabel:
BRUG UniversityV2-- Indsættelse af duplikerede poster i kursustabelINSERT INTO [dbo].[Course] ([CourseId], [Name], [Detalje]) VALUES (1, N'T-SQL Programmering', N 'Om T-SQL-programmering')INDSÆT I [dbo].[Kursus] ([CourseId], [Navn], [Detaljer]) VÆRDIER (1, N'T-SQL-programmering', N'Om T-SQL-programmering' ) Se dublerede kursusdata
Vælg alle kolonnerne for at se tabellen:
BRUG UniversityV2-- Visning af dublerede data i kursustabelSELECT CourseId ,Name ,Detail FROM dbo.Course

Sådan finder du dubletter ved hjælp af aggregeret metode
Vi kan finde nøjagtige dubletter ved at bruge aggregatmetoden ved at gruppere alle kolonnerne med i alt mere end én efter at have valgt alle kolonnerne sammen med at tælle alle rækkerne ved hjælp af funktionen aggregat count(*):
-- Finde dubletter ved hjælp af aggregeret metodeVÆLG <kolonne1>,<kolonne2>,<kolonne3>… ,COUNT(*) AS Total_RecordsFROM <Tabel>GROUP BY <column1><column2 ,<kolonne3>...HAR ANTAL(*)>1
Dette kan anvendes som følger:
BRUG UniversityV2-- Find dubletter ved hjælp af aggregeret metodeSELECT c.CourseId ,c.Name ,c.Detail ,COUNT(*) AS Duplicate_RecordsFROM dbo.Course cGROUP BY c.CourseId ,c.Name ,c.DetailHAVING COUNT (*) > 1 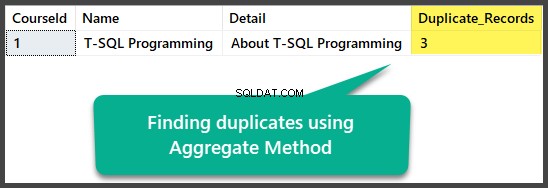
Fjernelse af dubletter ved hjælp af aggregeret metode
Lad os fjerne dubletterne ved at bruge den samlede metode som følger:
BRUG UniversityV2-- Fjernelse af dubletter ved hjælp af Aggregate-metoden-- (1) Find dubletter og læg dem i en ny tabel (CourseNew) som en enkelt rækkeSELECT c.CourseId ,c.Name ,c.Detail ,COUNT( *) AS Duplicate_Records INTO CourseNewFROM dbo.Course cGROUP BY c.CourseId ,c.Name ,c.DetailHAVING COUNT(*) > 1-- (2) Omdøb kursus (som indeholder dubletter) som Course_OLD EXEC sys.sp_rename @objname =N'Course' ,@newname =N'Course_OLD'-- (3) Omdøb CourseNew (som ikke indeholder dubletter) som Course EXEC sys.sp_rename @objname =N'CourseNew' ,@newname =N'Course'-- (4) Indsæt originale distinkte poster i kursustabellen fra Course_OLD tableINSERT INTO Course (CourseId, Name, Detail) SELECT co.CourseId ,co.Name ,co.Detail FROM Course_OLD co WHERE co.CourseId <> (SELECT c.CourseId FROM Course c) ORDER BY CO.CourseId-- (4) DatacheckSELECT cn.CourseId ,cn.Name ,cn.DetailFROM Course cn -- Clean up -- (5) Du kan droppe Course_OLD-tabellen bagefter -- (6) Du kan fjerne Duplicate_Records-kolonnen fra kursustabellen bagefter
Datatjek
BRUG UniversityV2
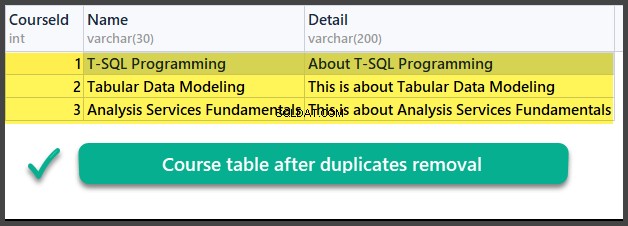
Så vi har med succes lært, hvordan man fjerner dubletter fra en databasetabel ved hjælp af to forskellige metoder baseret på to forskellige scenarier.
Ting at gøre
Du kan nu nemt identificere og fritage en databasetabel fra dubletværdi.
1. Prøv at oprette UspRemoveDuplicatesByAggregate lagret procedure baseret på metoden nævnt ovenfor og fjern dubletter ved at kalde den lagrede procedure
2. Prøv at ændre den lagrede procedure, der er oprettet ovenfor (UspRemoveDuplicatesByAggregates), og implementer oprydningstip nævnt i denne artikel.
DROP TABLE CourseNew-- (5) Du kan droppe Course_OLD-tabellen bagefter-- (6) Du kan fjerne Duplicate_Records-kolonnen fra Course-tabellen bagefter
3. Kan du være sikker på, at UspRemoveDuplicatesByAggregate lagret procedure kan udføres så mange gange som muligt, selv efter at dubletterne er fjernet, for at vise, at proceduren forbliver konsistent i første omgang?
4. Se venligst min tidligere artikel Gå til start testdrevet databaseudvikling (TDDD) – del 1 og prøv at indsætte dubletter i SQLDevBlog-databasetabellerne, prøv derefter at fjerne dubletterne ved at bruge begge metoderne nævnt i dette tip.
5. Prøv at oprette en anden eksempeldatabase EmployeesSample henviser til min tidligere artikel Art of Isolating Dependencies and Data in Database Unit Testing og indsæt dubletter i tabellerne og prøv at fjerne dem ved hjælp af begge de metoder, du lærte af dette tip.
Nyttigt værktøj:
dbForge Data Compare til SQL Server – kraftfuldt SQL-sammenligningsværktøj, der kan arbejde med big data.