Mens Jeff Atwood og Joe Celko synes at mene, at prisen på GUID'er ikke er nogen big deal (se Jeffs blogindlæg, "Primary Keys:IDs versus GUIDs," og denne nyhedsgruppetråd med titlen "Identity vs. Uniqueidentifier"), andre eksperter – mere specifikt indeks- og arkitektureksperter, der fokuserer på SQL Server-pladsen – er tilbøjelige til at være uenige. For eksempel gennemgår Kimberly Tripp nogle detaljer i sit indlæg, "Diskplads er billig – DET ER IKKE POINT!", hvor hun forklarer, at virkningen ikke kun er på diskplads og fragmentering, men endnu vigtigere på indeksstørrelse og hukommelse fodspor.
Det, Kimberly siger, er virkelig sandt – jeg støder på "diskplads er billig"-begrundelsen for GUID'er hele tiden (eksempel fra blot sidste uge). Der er andre begrundelser for GUID'er, herunder behovet for at generere unikke identifikatorer uden for databasen (og nogle gange før rækken faktisk oprettes), og behovet for unikke identifikatorer på tværs af separate distribuerede systemer (og hvor identitetsintervaller ikke er praktiske). Men jeg vil virkelig gerne aflive myten om, at GUID'er ikke koster så meget, for det gør de, og du skal afveje disse omkostninger i din beslutning.
Jeg begav mig ud på denne mission for at teste ydeevnen af forskellige nøglestørrelser, givet de samme data på tværs af det samme antal rækker, med de samme indekser og nogenlunde den samme arbejdsbyrde (at afspille den *præcis* samme arbejdsbyrde kan være ret udfordrende). Ikke kun ønskede jeg at måle de grundlæggende ting som indeksstørrelse og indeksfragmentering, men også de effekter, som disse har nedadgående, såsom:
- påvirkning af brugen af bufferpuljen
- hyppigheden af "dårlige" sideopdelinger
- samlet indvirkning på realistisk arbejdsbelastningsvarighed
- påvirkning af gennemsnitlige kørselstider for individuelle forespørgsler
- påvirkning af kørselsvarighed af efter-triggere
- påvirkning af tempdb-brug
Jeg vil bruge en række forskellige teknikker til at undersøge disse data, herunder udvidede hændelser, standardsporingen, tempdb-relaterede DMV'er og SQL Sentry Performance Advisor.
Opsætning
Først oprettede jeg en million kunder til at sætte ind i en seed-tabel ved hjælp af nogle indbyggede SQL Server-metadata; dette ville sikre, at de "tilfældige" kunder ville bestå af de samme naturlige data gennem hver test.
CREATE TABLE dbo.CustomerSeeds( rn INT PRIMÆR NØGLE KLUSTERET, Fornavn NVARCHAR(64), Efternavn NVARCHAR(64), E-mail NVARCHAR(320) IKKE NULL UNIK, Active BIT); INSERT dbo.CustomerSeeds WITH (TABLOCKX) (rn, FirstName, LastName, EMail, [Active])SELECT rn =ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, aFROM ( SELECT TOP (1000000) fn, ln , em, a =MAKS(a), n =MAKS(NEWID()) FRA ( VÆLG fn, ln, em, a, r =ROW_NUMBER() OVER (OPDELING EFTER em BESTILLING AF em) FRA ( VÆLG TOP (2000000) fn =VENSTRE(o.navn, 64), ln =VENSTRE(c.navn, 64), em =VENSTRE(o.navn, LEN(c.navn)%5+1) + '.' + VENSTRE(c. navn, LEN(o.navn)%5+2) + '@' + HØJRE(c.navn, LEN(o.navn+c.navn)%12 + 1) + VENSTRE(RTRIM(CHECKSUM(NEWID()) ),3) + '.com', a =TILFÆLDE, NÅR c.navn SOM '%y%' SÅ 0 ANDEN 1 SLUT FRA sys.all_objects AS o CROSS JOIN sys.all_columns SOM C ORDER BY NEWID() ) AS x ) AS y WHERE r =1 GRUPPER EFTER fn, ln, em BESTIL EFTER n) AS z BESTIL EFTER rn;GO VÆLG TOP (10) * FRA dbo.CustomerSeeds BESTIL EFTER rn;GO
Dit kilometertal kan variere, men på mit system tog denne population 86 sekunder. Ti repræsentative rækker (klik for at forstørre):
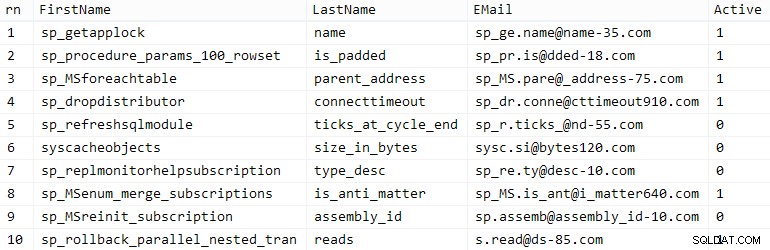 Eksempelkunder
Eksempelkunder
Dernæst havde jeg brug for tabeller til at rumme basisdataene for hver brugssag, med et par ekstra indekser til at simulere en slags virkelighed, og jeg fandt på korte suffikser for at gøre alle former for diagnostik lettere senere:
| datatype | standard | komprimering | brug kasussuffiks |
|---|---|---|---|
| INT | IDENTITET | ingen | I |
| INT | IDENTITET | side + række | Ic |
| STORT | IDENTITET | ingen | B |
| STORT | IDENTITET | side + række | Bc |
| UNIQUEIDENTIFIER | NEWID() | ingen | G |
| UNIQUEIDENTIFIER | NEWID() | side + række | Gc |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | ingen | S |
| UNIQUEIDENTIFIER | NEWSEQUENTIALID() | side + række | Sc |
Tabel 1:Brugstilfælde, datatyper og suffikser
Otte tabeller alle fortalt, alle båret fra den samme skabelon (jeg ville bare ændre kommentarerne til at matche use casen og erstatte $use_case$ med det relevante suffiks fra tabellen ovenfor):
CREATE TABLE dbo.Customers_$use_case$ -- I,Ic,B,Bc,G,Gc,S,Sc( Kunde-ID INT NOT NULL IDENTITY(1,1), --CustomerID BIGINT NOT NULL IDENTITY(1, 1), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWID(), --CustomerID UNIQUEIDENTIFIER NOT NULL DEFAULT NEWSEQUENTIALID(), Fornavn NVARCHAR(64) NOT NULL, Efternavn NVARCHAR(64) NOT NULL, E-mail NVARCHAR(320) NOT Active BIT NOT NULL DEFAULT 1, Oprettet DATETIME NOT NULL DEFAULT SYSDATETIME(), Opdateret DATETIME NULL, CONSTRAINT C_PK_Customers_$use_case$ PRIMÆR NØGLE (Kunde-ID)) --WITH (DATA_COMPRESSION =PAGE)GO;CREATE UNIQUE_$__Cusse dboers. Customers_$use_case$(EMail) --WITH (DATA_COMPRESSION =PAGE);GOCREATE INDEX C_Active_Customers_$use_case$ PÅ dbo.Customers_$use_case$(FirstName, LastName, EMail) WHERE Active =1 --GOCIONRE =DATA_COMPRESS); INDEX C_Name_Customers_$use_case$ ON dbo.Customers_$use_case$(LastName, FirstName) INCLUDE (EMail) --WITH (DATA_COMPRESSION =PAGE);GODa tabellerne var oprettet, fortsatte jeg med at udfylde tabellerne og måle mange af de målinger, jeg hentydede til ovenfor. Jeg genstartede SQL Server-tjenesten mellem hver test for at være sikker på, at de alle startede fra den samme baseline, at DMV'er ville blive nulstillet osv.
Ubestridte indlæg
Mit endelige mål var at fylde tabellen med 1.000.000 rækker, men først ville jeg se indvirkningen af datatypen og komprimeringen på rå-indsæt uden uenighed. Jeg genererede følgende forespørgsel – som ville udfylde tabellen med de første 200.000 kontakter, 2000 rækker ad gangen – og kørte den mod hver tabel:
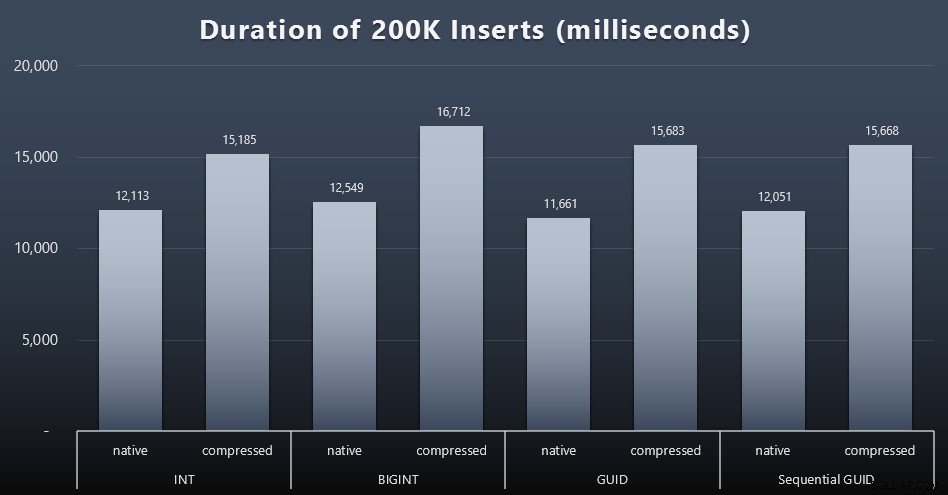
DECLARE @i INT =1;MENS @i <=100BEGIN INSERT dbo.Customers_$use_case$(FirstName, LastName, Email, Active) VÆLG Fornavn, Efternavn, Email, Aktiv FRA dbo.CustomerSeeds AS c ORDER BY rn OFFSET 2000 * (@i-1) RÆKKER HENTES KUN NÆSTE 2000 RÆKKER; SET @i +=1;ENDResultater (klik for at forstørre):
Hver sag tog omkring 12 sekunder (uden komprimering) og 16 sekunder (med komprimering), uden nogen klar vinder i nogen af lagringstilstandene. Effekten af komprimering (hovedsageligt på CPU-overhead) er ret konsistent, men da dette kører på en hurtig SSD, er I/O-påvirkningen af de forskellige datatyper ubetydelig. Faktisk så komprimeringen mod BIGINT ud til at have den største indvirkning (og det giver mening, da hver enkelt værdi på mindre end 2 milliarder ville blive komprimeret).
Mere omstridt arbejdsbyrde
Dernæst ville jeg se, hvordan en blandet arbejdsbyrde ville konkurrere om ressourcer og generelt præstere mod hver datatype. Så jeg oprettede disse procedurer (erstatter
$use_case$og$data_type$passende for hver test):-- tilfældige singleton-opdateringer til data i mere end ét indeks OPRET PROCEDURE [dbo].[Customers_$use_case$_RandomUpdate] @Customers_$use_case$ $data_type$ASBEGIN INDSTILL INGEN TÆLLING TIL; OPDATERING dbo.Customers_$use_case$ SET Efternavn =COALESCE(STUFF(Efternavn, 4, 1, 'x'),'x') WHERE CustomerID =@Customers_$use_case$;ENDGO -- læser ("paginering") - understøtter flere sorterer-- brug dynamisk SQL til at spore forespørgselsstatistik separat OPRET PROCEDURE [dbo].[Customers_$use_case$_Page] @PageNumber INT =1, @PageSize INT =100, @sort SYSNAMEASBEGIN SET NOCOUNT ON; DECLARE @sql NVARCHAR(MAX) =N'SELECT Kunde-ID, Fornavn, Efternavn, E-mail, Aktiv, Oprettet, Opdateret FRA dbo.Customers_$use_case$ BESTIL VED ' + @sort + N' OFFSET ((@pn-1)*@ ps) RÆKKER FETCH NEXT @ps KUN RÆKKER;'; EXEC sys.sp_executesql @sql, N'@pn INT, @ps INT', @PageNumber, @PageSize;ENDGODerefter skabte jeg job, der ville kalde disse procedurer gentagne gange, med små forsinkelser, og også – samtidig – færdiggøre de resterende 800.000 kontakter. Dette script opretter alle 32 job og udskriver også output, der kan bruges senere til at kalde alle jobs til en specifik test asynkront:
USE msdb;GO DECLARE @typ TABLE(use_case VARCHAR(2), data_type SYSNAME);INSERT @typ(use_case, data_type) VALUES('I', N'INT'), ('Ic',N'INT '),('B', N'BIGINT'), ('Bc', N'BIGINT'),('G', N'UNIQUEIDENTIFIER'), ('Gc', N'UNIQUEIDENTIFIER'),('S ', N'UNIQUEIDENTIFIER'), ('Sc', N'UNIQUEIDENTIFIER'); DECLARE @jobs TABLE(navn SYSNAME, cmd NVARCHAR(MAX));INSERT @jobs(navn, cmd) VALUES(N'Random update workload', N'DECLARE @CustomerID $data_type$, @i INT =1; WHILE @i <=500 BEGIN VÆLG TOP (1) @CustomerID =Kunde-ID FRA dbo.Customers_$use_case$ BESTILLING AF NEWID(); EXEC dbo.Customers_$use_case$_RandomUpdate @Customers_$use_case$ =@Customer00DELAY:''0TFOR :01''; SET @i +=1; END'),( N'Populate customers', N'SET QUOTED_IDENTIFIER ON; DECLARE @i INT =101; WHILE @i <=500 BEGIN INSERT dbo.Customers_$use_case$ (Fornavn, Efternavn, E-mail, Aktiv) VÆLG Fornavn, Efternavn, E-mail, Aktiv FRA dbo.CustomerSeeds SOM ORDNER EFTER rn OFFSET 2000 * (@i-1) RÆKKER HENT KUN NÆSTE 2000 RÆKKER; WAITFORSSINKELSE:'00:00 01''; SET @i +=1; END'),( N'Paging arbejdsbelastning 1', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- sorter efter Kunde-ID SET @sql =N ''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''Kunde-ID'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; WAITFOR DELAY ''00:00:01''; SET @i +=2; END'),( N'Paging workload 2', N'DECLARE @i INT =1, @sql NVARCHAR(MAX); WHILE @i <=1001 BEGIN -- sorter efter Efternavn, Fornavn SET @sql =N''EXEC dbo.Customers_$use_case$_Page @PageNumber =@i, @sort =N''''Efternavn, Fornavn'''';''; EXEC sys.sp_executesql @sql, N''@i INT'', @i; WAITFOR DELAY ''00:00:01''; SET @i +=2; END'); DECLARE @n SYSNAME, @c NVARCHAR(MAX); ERKLÆR c MARKØR LOKAL FAST_FORWARD FORSELECT navn =t.use_case + N' ' + j.name, cmd =REPLACE(REPLACE(j.cmd, N'$use_case$', t.use_case), N'$data_type$', t .data_type) FRA @typ AS t CROSS JOIN @jobs AS j; ÅBEN c; FETCH c INTO @n, @c; MENS @@FETCH_STATUS <> -1BEGIN HVIS FINNES (VÆLG 1 FRA msdb.dbo.sysjobs HVOR navn =@n) BEGIN EXEC msdb.dbo.sp_delete_job @job_name =@n; END EXEC msdb.dbo.sp_add_job @job_name =@n, @enabled =0, @notify_level_eventlog =0, @category_id =0, @owner_login_name =N'sa'; EXEC msdb.dbo.sp_add_jobstep @job_name =@n, @step_name =@n, @command =@c, @database_name =N'ID'er'; EXEC msdb.dbo.sp_add_jobserver @job_name =@n, @server_name =N'(lokal)'; UDSKRIV 'EXEC msdb.dbo.sp_start_job @job_name =N''' + @n + ''';'; FETCH c INTO @n, @c;ENDDet var trivielt at måle jobtidspunkterne i hvert enkelt tilfælde – jeg kunne tjekke start-/slutdatoer i
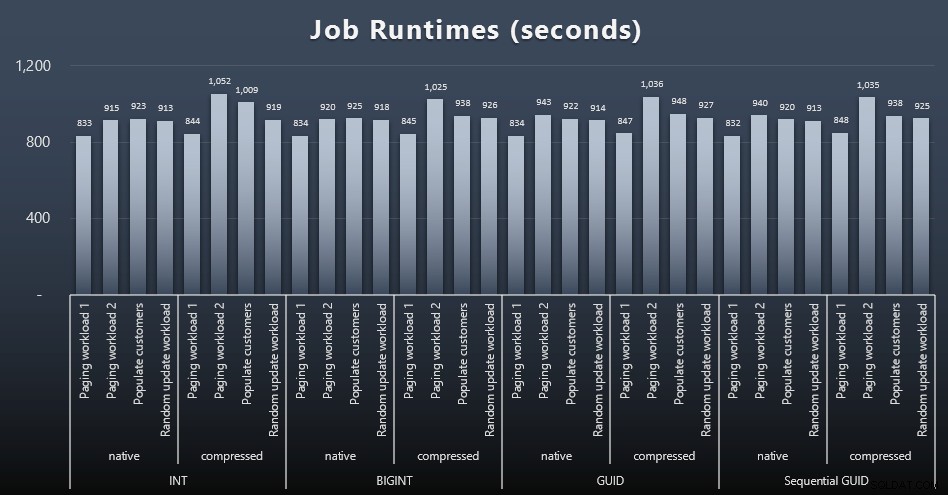
msdb.dbo.sysjobhistoryeller træk dem fra SQL Sentry Event Manager. Her er resultaterne (klik for at forstørre):
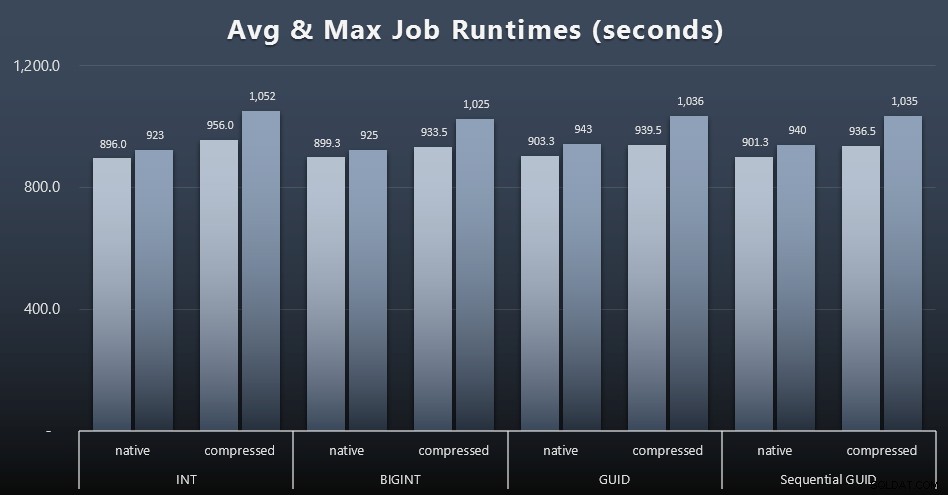
Og hvis du gerne vil have lidt mindre at fordøje, skal du bare se på den gennemsnitlige og maksimale køretid på tværs af de fire job (klik for at forstørre):
Men selv i denne anden graf er der ikke rigtig nok varians til at argumentere for eller imod nogen af tilgangene.
Forespørgselskørselstider
Jeg tog nogle metrics fra
sys.dm_exec_query_statsogsys.dm_exec_trigger_statsfor at bestemme, hvor lang tid individuelle forespørgsler tog i gennemsnit.
Befolkning
De første 200.000 kunder blev indlæst ret hurtigt – under 20 sekunder – på grund af ingen konkurrerende arbejdsbelastninger. Da de fire job kørte samtidigt, var der dog en betydelig indflydelse på skrivevarigheden på grund af samtidighed. De resterende 800.000 rækker krævede i gennemsnit mindst en størrelsesorden mere tid at fuldføre. Her er resultaterne af gennemsnittet af hver 2.000 kundeindlæg (klik for at forstørre):
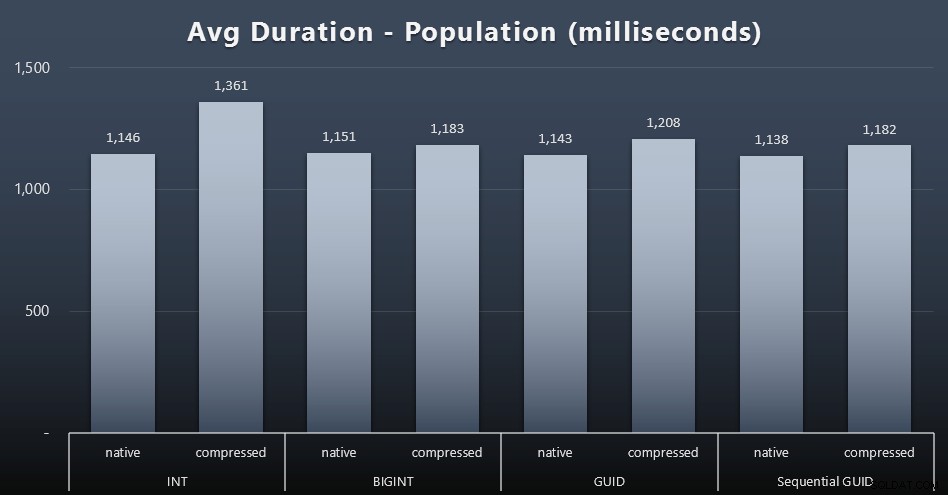
Vi ser her, at komprimering af en INT var den eneste virkelige outlier – jeg har nogle teorier om det, men intet afgørende endnu.
Paging-arbejdsbelastninger
De gennemsnitlige kørselstider for personsøgningsforespørgslerne ser også ud til at have været væsentligt påvirket af samtidighed sammenlignet med mine testkørsler isoleret. Her er resultaterne (klik for at forstørre):
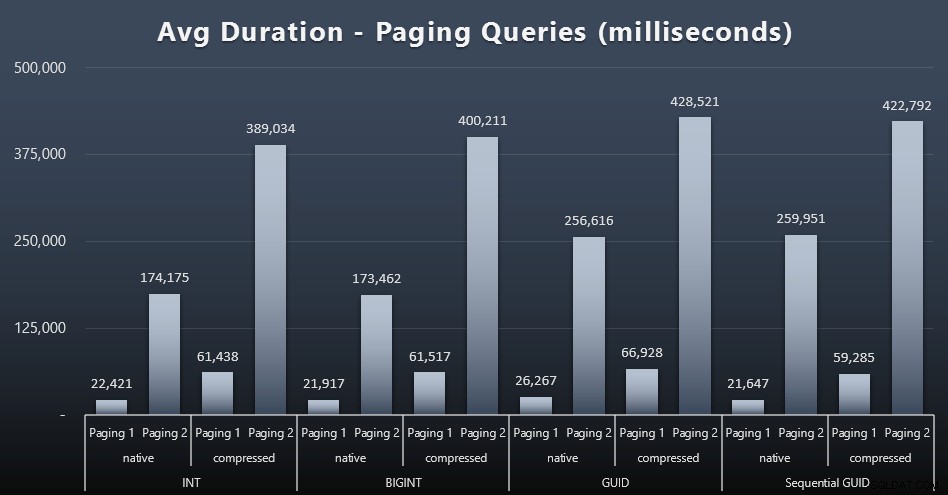
(Paging 1 =bestilling efter kunde-ID, Paging 2 =bestilling efter efternavn, fornavn.)
Vi ser, at for både Paging 1 (bestilling efter kunde-ID) og Paging 2 (rækkefølge efter navne), er der en betydelig indvirkning på kørselstiden på grund af komprimering (op til ~700%). Begge GUID'er ser ud til at være de langsomste heste i dette løb, hvor NEWID() klarer sig dårligst.
Opdater arbejdsbelastninger
Singleton-opdateringerne var ret hurtige selv under kraftig samtidighed, men der var stadig nogle mærkbare forskelle på grund af komprimering og endda nogle overraskende forskelle på tværs af datatyper (klik for at forstørre):
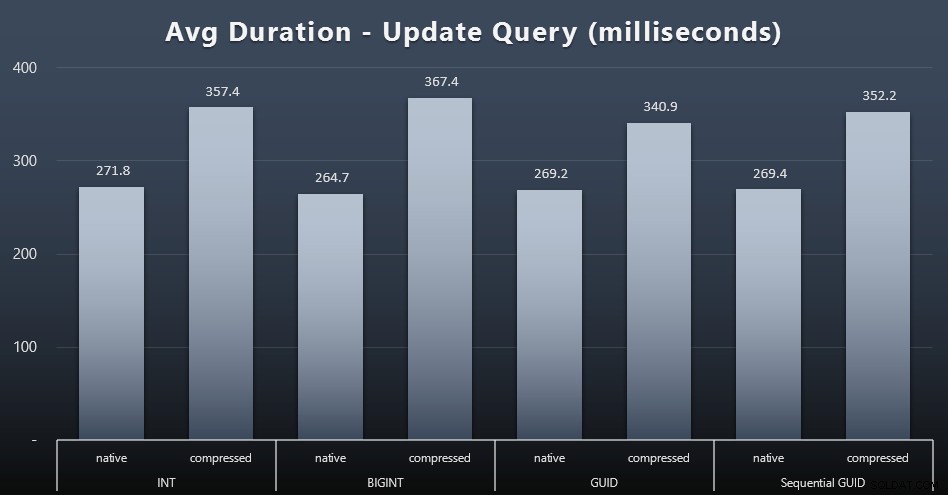
Mest bemærkelsesværdigt var opdateringerne til rækkerne med GUID-værdier faktisk hurtigere end opdateringerne indeholdende INT/BIGINT, når komprimering var i brug. Med native storage var forskellene mindre bemærkelsesværdige (men INT var stadig en taber der).
Triggerstatistik
Her er de gennemsnitlige og maksimale køretider for den simple trigger i hvert tilfælde (klik for at forstørre):
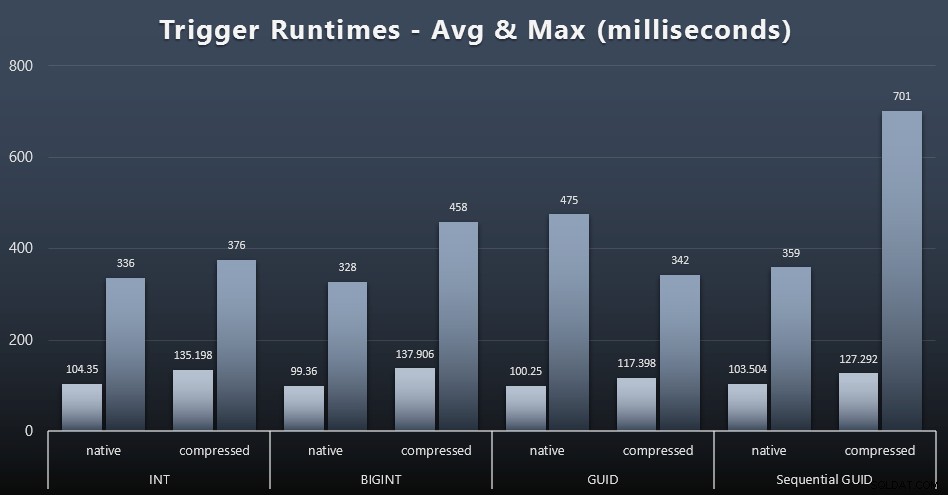
Komprimering ser ud til at have en meget større indvirkning her end valg af datatype (selvom dette sandsynligvis ville være mere udtalt, hvis noget af min opdateringsbelastning havde opdateret mange rækker i stedet for udelukkende at bestå af enkeltrække-søgninger). Maksimumsværdien for sekventiel GUID er helt klart en afvigelse af en slags, som jeg ikke har undersøgt (du kan se, at det er ubetydeligt baseret på, at gennemsnittet stadig er på linje over hele linjen).
Hvad ventede disse forespørgsler på?
Efter hver arbejdsbyrde tog jeg også et kig på de øverste ventetider på systemet, og smed åbenlyse kø-/timerventer (som beskrevet af Paul Randal) og irrelevant aktivitet fra overvågningssoftware (som TRACEWRITE) væk ). Her var de 3 bedste ventetider i hvert tilfælde (klik for at forstørre):
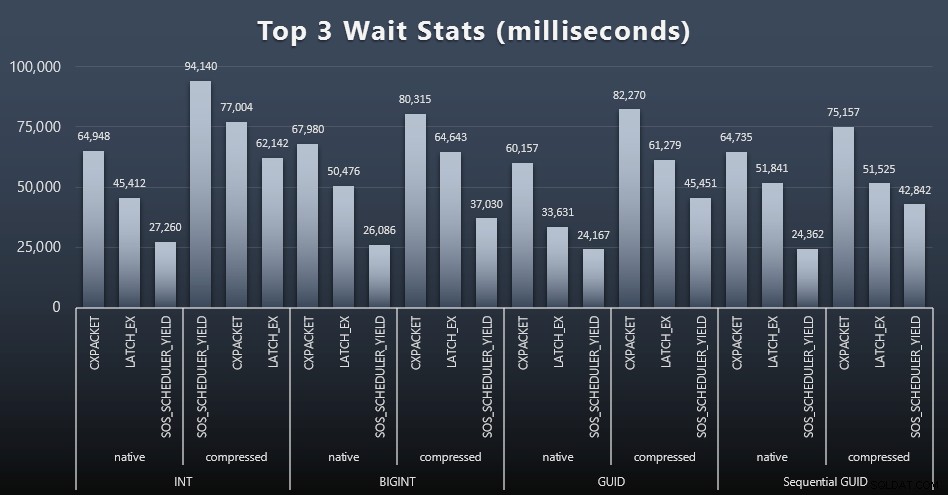
I de fleste tilfælde var ventetiden CXPACKET, derefter LATCH_EX og derefter SOS_SCHEDULER_YIELD. I brugssagen, der involverer heltal og komprimering, tog SOS_SCHEDULER_YIELD dog over, hvilket for mig indebærer en vis ineffektivitet i algoritmen til at komprimere heltal (som kan være fuldstændig uden relation til den algoritme, der bruges til at presse BIGINTs ind i INT'er). Jeg har ikke undersøgt dette yderligere, og jeg fandt heller ikke begrundelse for at spore ventetider pr. individuel forespørgsel.
Diskplads / Fragmentering
Selvom jeg plejer at være enig i, at det ikke handler om diskplads, er det stadig en metrik, der er værd at præsentere. Selv i dette meget forenklede tilfælde, hvor der kun er én tabel, og nøglen ikke er til stede i alle de andre relaterede tabeller (som helt sikkert ville eksistere i en rigtig applikation), er forskellen betydelig. Lad os først lige se på den reserved kolonne fra sp_spaceused (klik for at forstørre):
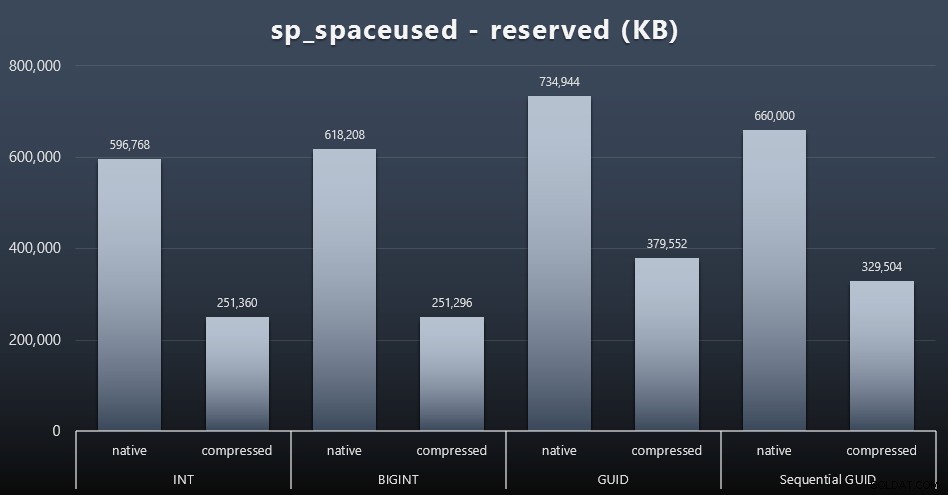
Her tog BIGINT kun lidt mere plads end INT, og GUID havde (som forventet) et større spring. Sekventiel GUID havde en mindre signifikant stigning i pladsforbruget og komprimerede også meget bedre end traditionel GUID. Igen, ingen overraskelser her – en GUID er større end et tal, punktum. Nu kan GUID-tilhængere hævde, at prisen, du betaler i form af diskplads, ikke er så meget (18 % over BIGINT uden komprimering, omkring 50 % med komprimering). Men husk, at dette er en enkelt tabel med 1 million rækker. Forestil dig, hvordan det vil ekstrapolere, når du har 10 millioner kunder, og mange af dem har 10, 30 eller 500 ordrer – disse nøgler kan gentages i et dusin andre borde og optager den samme ekstra plads i hver række.
Da jeg så på fragmentering efter hver arbejdsbyrde (husk, der udføres ingen indeksvedligeholdelse) ved hjælp af denne forespørgsel:
SELECT index_id, FROM sys.dm_db_index_physical_stats (DB_ID(), OBJECT_ID('dbo.Customers_$use_case$'), -1, 0, 'DETAILED'); Resultaterne gav meget mindre interessante billeder; alle ikke-klyngede indekser var fragmenteret over 99 %. De klyngede indekser var imidlertid enten meget stærkt fragmenterede eller slet ikke fragmenterede (klik for at forstørre):
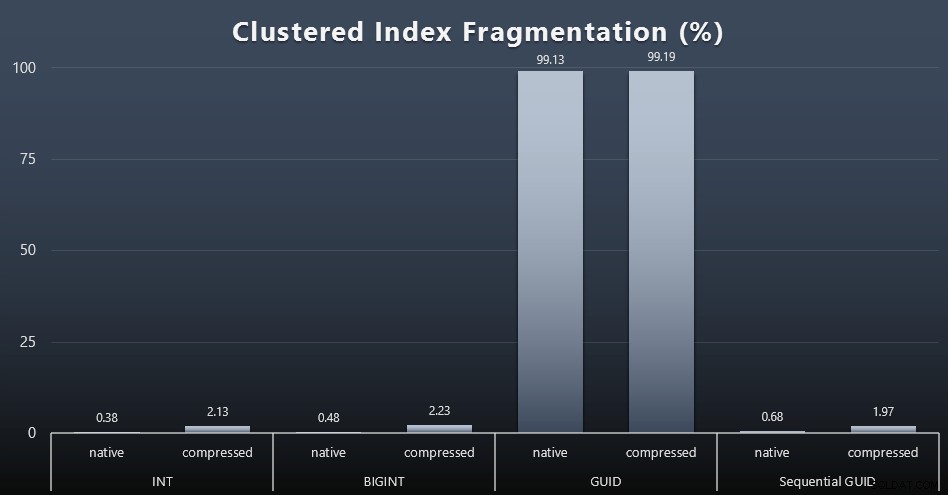
Fragmentering er en anden metrik, der ofte betyder meget mindre, når vi taler om SSD'er, men det er vigtigt at bemærke alligevel, da ikke alle systemer har råd til at være lykkeligt uvidende om den indvirkning, fragmentering kan have på I/O-mønstre. Jeg tror, at ved at bruge ikke-sekventielle GUID'er på et mere I/O-bundet system, vil virkningen af denne fragmentering alene blive drastisk forstærket på de fleste af de andre målinger i denne test.
Brug af bufferpool
Det er her, at det virkelig betaler sig at være bevidst om mængden af diskplads, der bruges af dine borde – jo større dine borde er, jo mere plads fylder de i bufferpuljen. Det er dyrt at flytte data ind og ud af bufferpuljen, og igen er dette et meget forenklet tilfælde, hvor testene blev kørt isoleret, og der ikke var andre applikationer og databaser på instansen, der konkurrerede om dyrebar hukommelse.
Dette er et simpelt mål for følgende forespørgsel i slutningen af hver arbejdsbyrde:
SELECT total_kb FROM sys.dm_os_memory_broker_clerks WHERE clerk_name =N'Buffer Pool';
Resultater (klik for at forstørre):
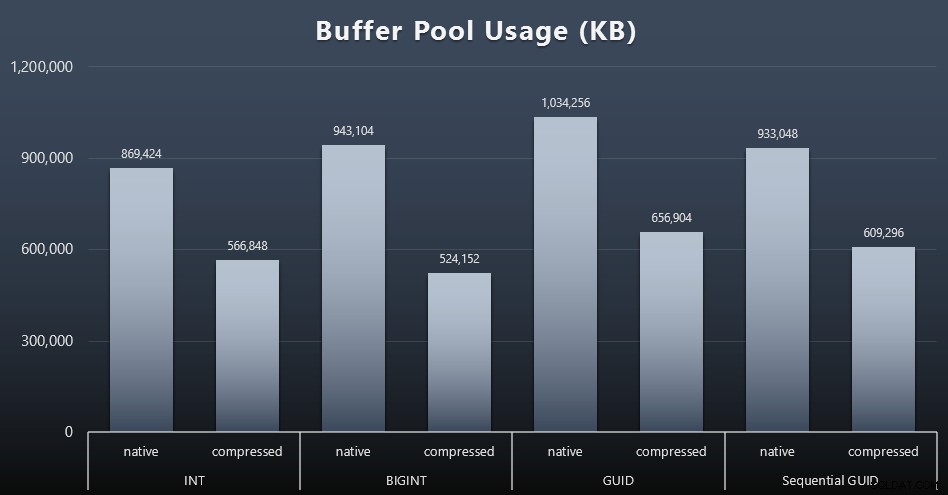
Selvom det meste af denne graf overhovedet ikke er overraskende - GUID tager mere plads end BIGINT, BIGINT mere end INT - fandt jeg det interessant, at en sekventiel GUID optog mindre plads end en BIGINT, selv uden komprimering. Jeg har noteret mig, at jeg skal udføre efterforskning på sideniveau for at afgøre, hvilken slags effektivitet der finder sted her under dynen.
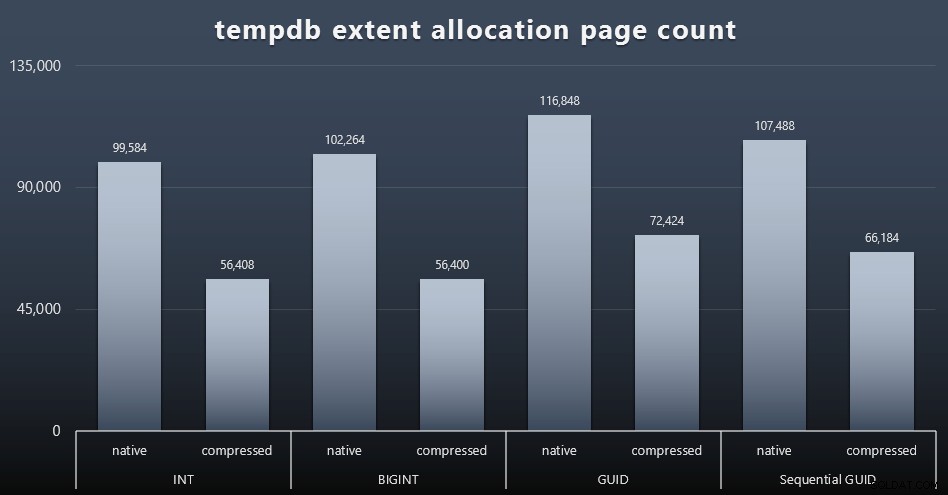
tempdb-brug
Jeg er ikke sikker på, hvad jeg forventede her, men efter hver arbejdsbyrde samlede jeg indholdet af de tre tempdb-relaterede DMV'er for pladsforbrug, sys.dm_db_file|session|task_space_usage . Den eneste, der så ud til at vise nogen volatilitet baseret på datatype, var sys.dm_db_file_space_usage 's extent_allocation_page_count . Dette viser, at - i det mindste i min konfiguration og denne specifikke arbejdsbyrde - GUID'er vil sætte tempdb igennem en lidt mere grundig træning (klik for at forstørre):
"Dårlige" sideopdelinger
En af de ting, jeg ville måle, var effekten på sideopdelinger – ikke normale sideopdelinger (når du tilføjer en ny side), men når du faktisk skal flytte data mellem siderne for at give plads til flere rækker. Jonathan Kehayias fortæller mere om dette i sit blogindlæg, "Tracking Problematic Pages Splits in SQL Server 2012 Extended Events – No Really This Time!", som også giver grundlaget for den udvidede begivenhedssession, jeg brugte til at fange dataene:
CREATE EVENT SESSION [BadPageSplits] PÅ SERVER ADD EVENT sqlserver.transaction_log (WHERE operation =11 AND database_id =10) ADD TARGET package0.histogram (SET filtering_event_name ='sqlserver.transaction_log', source_type ='alloc0', source_type ='alloc0', source_type );GOALTER EVENT SESSION [BadPageSplits] PÅ SERVER STATE =START;GO
Og forespørgslen, jeg brugte til at plotte den:
SELECT t.name, SUM(tab.split_count)FROM ( SELECT n.value('(value)[1]', 'bigint') AS alloc_unit_id, n.value('(@count)[1]' , 'bigint') AS split_count FROM ( SELECT CAST(target_data as XML) target_data FROM sys.dm_xe_sessions AS s INNER JOIN sys.dm_xe_session_targets AS t ON s.address =t.event_session_address ='t.event_session_address ='t.event_session_address HVOR gettar s.Page_name . ='histogram' ) AS x CROSS APPLY target_data.nodes('HistogramTarget/Slot') som q(n)) AS tabINNER JOIN sys.allocation_units AS au ON tab.alloc_unit_id =au.allocation_unit_idINNER JOIN sys.partitions AS p ON. container_id =p.partition_idINNER JOIN sys.tables AS t ON p.object_id =t.[object_id]GRUPPER EFTER t.name; Og her er resultaterne (klik for at forstørre):
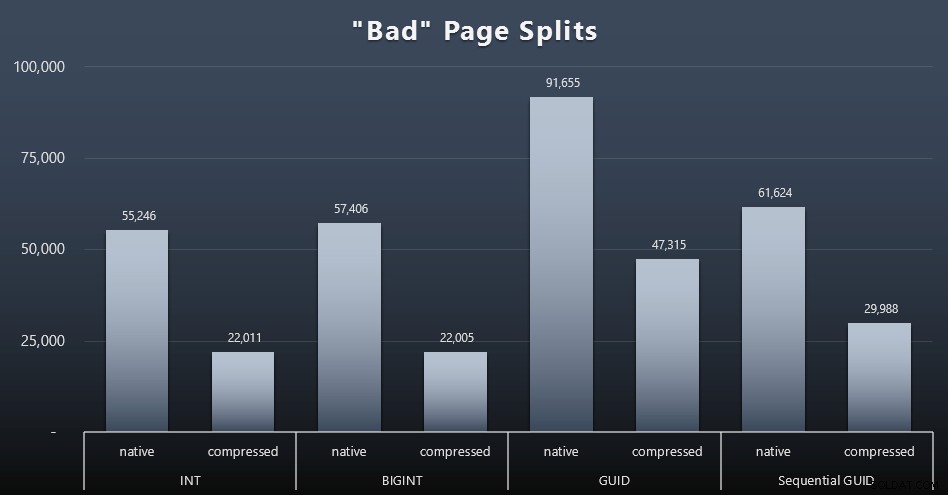
Selvom jeg allerede har bemærket, at i mit scenarie (hvor jeg kører på hurtige SSD'er) har den ubestridelige forskel i I/O-aktivitet ikke direkte indflydelse på den samlede køretid, er dette stadig en metrik, du bør overveje – især hvis du ikke har SSD'er, eller hvis din arbejdsbyrde allerede er I/O-bundet.
Konklusion
Selvom disse tests har åbnet mine øjne lidt bredere om, hvordan langvarige opfattelser, jeg har haft, er blevet ændret af mere moderne hardware, er jeg stadig temmelig overbevist om at spilde plads på disken eller i hukommelsen. Mens jeg forsøgte at demonstrere en vis balance og lade GUID'er skinne, er der meget lidt her fra et præstationsperspektiv til at understøtte skift fra INT/BIGINT til begge former for UNIQUEIDENTIFIER – medmindre du har brug for det af andre mindre håndgribelige årsager (såsom oprettelse af nøglen i applikationen eller opretholdelse af unikke nøgleværdier på tværs af forskellige systemer). En hurtig opsummering, der viser, at NEWID() er det dårligste valg på tværs af mange af de metrics, hvor der var en væsentlig forskel (og i de fleste af disse tilfælde var NEWSEQUENTIALID() en tæt andenplads)):
| Metric | Ryd taber(e)? |
|---|---|
| Ubestridte indsættelser | – tegne – |
| Samtidig arbejdsbelastning | – tegne – |
| Individuelle forespørgsler – Population | INT (komprimeret) |
| Individuelle forespørgsler – personsøgning | NEWID() / NEWSEQUENTIALID() |
| Individuelle forespørgsler – Opdater | INT (native) / BIGINT (komprimeret) |
| Individuelle forespørgsler – EFTER trigger | – tegne – |
| Diskplads | NEWID() |
| Klyngeret indeksfragmentering | NEWID() |
| Brug af bufferpool | NEWID() |
| tempdb-brug | NEWID() |
| "Dårlige" sideopdelinger | NEWID() |
Tabel 2:Største tabere
Du er velkommen til at teste disse ting af selv; Jeg kan samle mit fulde sæt af scripts, hvis du gerne vil køre dem i dit eget miljø. Det kortfattede formål med hele dette indlæg er ret simpelt:Der er mange vigtige målinger at overveje bortset fra den forudsigelige indvirkning på diskplads, så det bør ikke bruges alene som et argument i begge retninger.
Nu ønsker jeg ikke, at denne tankegang skal være begrænset til nøgler i sig selv. Det bør virkelig tænkes over, når der foretages et datatypevalg. Jeg ser datetime bliver valgt ofte, for eksempel når kun en date eller smalldatetime er nødvendig. På transaktionstabeller kan dette også give efter for en masse spildt diskplads, og dette risler også ned til nogle af disse andre ressourcer.
I en fremtidig test vil jeg gerne sammenligne resultater for en meget større tabel (> 2 milliarder rækker). Jeg kan simulere dette med INT ved at sætte identitetskernen til -2 milliarder, hvilket giver mulighed for ~4 milliarder rækker. Og jeg vil gerne have, at sammenligningen af arbejdsbyrden og diskplads/hukommelsesfodaftryk involverer mere end en enkelt tabel, da en af fordelene ved en tynd nøgle er, når denne nøgle er repræsenteret i snesevis af relaterede tabeller. Jeg overvågede for autogrow-hændelser, men der var ingen, da databasen var på forhånd stor nok til at rumme væksten, og jeg tænkte ikke på at måle det faktiske logforbrug inde i den eksisterende logfil, så jeg vil gerne teste igen med standardindstillingerne for logstørrelse og autovækst, og denne gang måles DBCC SQLPERF(LOGSPACE); . Det ville også være interessant at tage tid på genopbygninger og måle logbrug som et resultat af disse operationer. Til sidst vil jeg gerne gøre I/O til en mere relevant faktor ved at finde en server med mekaniske harddiske – jeg ved, at der er masser derude, men i nogle butikker er de ret sparsomme.