Dyrepleje er en kæmpe industri. Findes der en datamodel, der kan hjælpe kæledyrsejere og fagfolk med at styre deres aktiviteter? Der er nu!
Mange mennesker deler deres liv med katte, hunde, fugle og andre dyr. (Jeg havde engang en due i et stykke tid, indtil dens vinge blev repareret.) Hvad mange kæledyrsejere ikke er klar over er, hvor stor en kæledyrspleje er. I USA brugte kæledyrsejere $66,75 milliarder – og det var lige i 2016!
Mens de fleste af os kan holde vores hamstere i live uden at bruge sofistikeret teknologi, er der masser af virksomheder, der centrerer sig om kæledyrspleje:kæledyrskenneler (alias kæledyrshoteller eller kæledyrsresorts), kæledyrsfrisører, dyrepassere (som bliver i dit hjem, med din kæledyr, mens du tager på ferie), hundeluftere, kæledyrsadfærdseksperter, endda kæledyrsmassører og terapeuter. Disse leverer ofte ret komplekse tjenester til kæledyr og deres ejere, og de ville have brug for en datamodel for at holde dem organiseret. Så lad os tage et kig på en.
Hvad indgår i en datamodel for kæledyrspleje?
Før vi begynder at beskrive modellens detaljer, lad os diskutere nogle krav:
-
Hvem skal bruge denne datamodel?
Selvom denne datamodel måske lyder eksotisk, er den egentlig ikke så usædvanlig. Forestil dig, at du driver en af de ovennævnte virksomheder. Uanset hvor forskellige disse forretningsmodeller er, skal du stadig:
- Kommunikere med potentielle kunder
- Forklar dine tjenester og angiv deres priser
- Organiser din tidsplan
- Spor igangværende opgaver og aktiviteter
- Debiter klienter for ydede tjenester
Så ja, der er en chance for, at du får brug for denne model til dig selv eller til dine kunder.
Nu kan vi gå videre og besvare nogle tekniske spørgsmål.
-
Hvad skal dækkes af denne model?
Det vil være generelt nok til at dække mange forskellige situationer. Jeg vil gå ud fra den antagelse, at vi har et fysisk sted, hvor vi leverer tjenester (som et kæledyrshotel), eller som tjener som udgangspunkt for at levere tjenester (dvs. for en hundelufter).
Vi bliver også nødt til at gemme optegnelser for individuelle kæledyr og deres ejere, samt optegnelser over de tjenester, vi leverer. At relatere alt dette burde dække de fleste kæledyrsplejesager.
-
Hvorfor er denne model vigtig?
For at forklare, lad mig fortælle dig om en "profeti", som jeg tror vil gå i opfyldelse.
Vi er alle klar over, hvordan teknologien ændrer forretning. Vi ser artikler om jobs, som automatiseringen vil overtage i de næste 10 eller 20 år. De fleste af disse job vil sandsynligvis være dem, der ikke er afhængige af kontakt med mennesker. For eksempel har mange butikker nu selvudtjekningsbaner, hvor en menneskelig medarbejder kan overvåge 5 eller 10 kasser. Før ville hver af disse kasser have haft en kasserer. Men at stå i kø for at betale for dine dagligvarer er nok ikke det bedste øjeblik på din dag. Og det job er også meget trættende og underbetalt, så kasserere er ikke rigtig begejstrede for at se dig. Den slags jobs kan og bliver automatiseret.
Det andet sæt job, der vil blive automatiseret, er intellektuelt mere udfordrende, men noget gentagne – f.eks. næsten alle finansielle tjenester, de fleste computerprogrammering og endda skrivning.
Så min "profeti" er, at job, der kræver en masse menneskelig (eller, i dette tilfælde, kæledyr) kontakt, ikke kun vil overleve, men blive "fremtidens job"; vi taler om psykologer, frisører, hundefrisører og dyrepassere osv. Men de skal bruge noget teknologi til at drive deres forretninger. Og det er her, denne model kommer ind.
Datamodellen
Denne datamodel består af fire emneområder:
KæledyrFaciliteter og tjenesterSagerPlanlagt og leveret
Vi starter med
Afsnit 1:Kæledyr
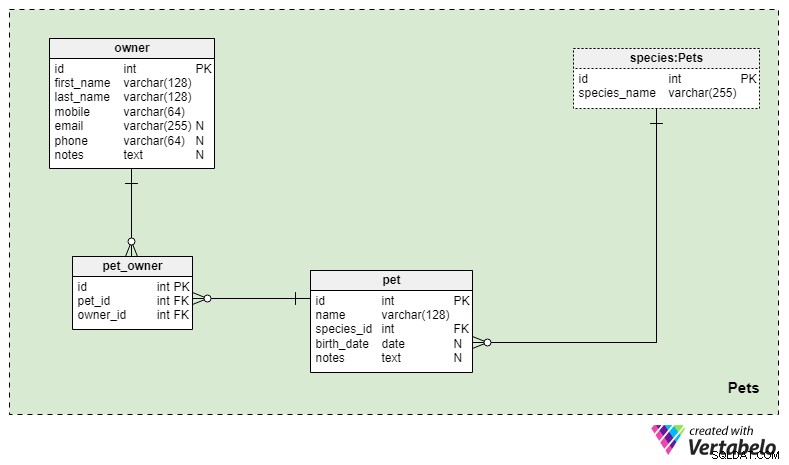
Jeg starter med Kæledyr emneområde; trods alt er denne model her på grund af vores små venner klædt i deres pels og fjer. Jeg vil holde det enkelt, selvom dette emneområde kunne udvides. For eksempel kunne vi gemme mange flere detaljer, der beskriver kæledyr, deres egenskaber og kæledyrsejerne (og deres egenskaber 😊 ).
Den vigtigste tabel i hele modellen er kæledyret bord. For hvert kæledyr gemmer vi:
navn– Det navn, ejeren gav deres kæledyr.arts_id– Henviser tilartenordbog og betegner kæledyrsarten.fødselsdato– Kæledyrets fødselsdato, hvis tilgængelig.noter– Alle yderligere bemærkninger relateret til dette kæledyr, i fritekstformat.
I ejer tabel, gemmer vi en liste over alle vores tidligere, nuværende og potentielle kunder. Personligt kan jeg ikke lide ordet "ejer", for efter at du bor med dine kæledyr, er de mere som familiemedlemmer. Men jeg er okay at bruge det i datamodellen. Så for hver ejer gemmer vi deres first_name og efternavn , kontaktoplysninger (som vi kender dem, kender vi muligvis ikke dem alle) og eventuelle yderligere detaljer i noterne attribut.
Vi relaterer ejere og kæledyr ved hjælp af pet_owner bord. En ejer kan have mange kæledyr, og et kæledyr kan have et par ejere, så vi bliver nødt til at indsætte en mange-til-mange relation her. For hver post gemmer vi et UNIKT kæledyrs-id – ejer_id par.
Den tredje og sidste tabel i dette emneområde er arten ordbog. Udover den primære nøgleattribut id , den indeholder kun det UNIKKE artsnavn værdi. Vi bruger denne ordbog til at gemme artsoplysningerne på det niveau, virksomheden kræver. Vi kunne gå med et sæt simple værdier som "kat", "hund", "hest" og "fugl". Eller vi kunne bruge mere beskrivende værdier som "kat - Maine Coon", "kat - Munchkin" osv. Vi kunne bruge en mere kompleks struktur - dvs. have en tabel for arter og en anden for racer - men jeg tror ikke, denne tilgang vil bringe noget nyt til modellen.
Afsnit 2:Faciliteter og tjenester
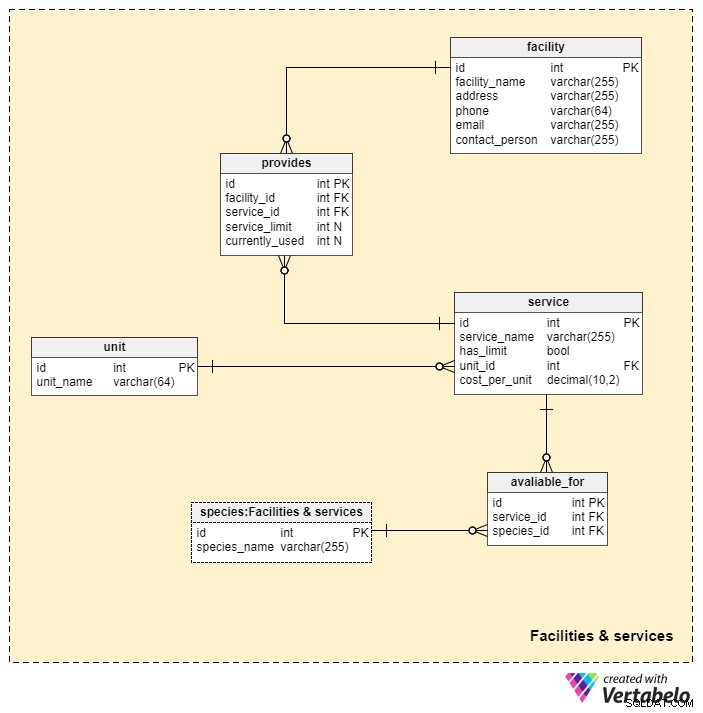
Den næstvigtigste ting i denne model er de tjenester, vi leverer. Vi får også brug for faciliteter, uanset hvad vi tilbyder kæledyrsejere. Dette kan være ét sted, såsom et kæledyrshotel, eller det kan være et sted, hvor vi henter eller afleverer kæledyr (såsom en hundelufter ville bruge). Vi gemmer disse oplysninger i Faciliteter og tjenester emneområde.
Jeg starter med tjenesten bord. Dette er en ordbog, vi vil bruge til at gemme en liste over alle tjenester, vi tilbyder til vores kunder. For hver tjeneste skal vi bruge en:
tjenestenavn– Et navn, der UNIKT definerer en tjeneste.har_grænse– En værdi, der angiver, om denne service har en grænse (f.eks. antallet af "senge" på dyrehotellet).enheds-id– Den enhed, vi bruger til at måle den service. Det afhænger af den type service, vi leverer, og om det kræver tid eller materiale (eller begge dele). I de fleste tilfælde vil vi være bekymrede over tid. For eksempel, hvis en hund bor på et kæledyrshotel, skal den anvendte enhed være en "dag". På den anden side, hvis vi går tur med hund, så skal enheden være en "time" eller et "minut". Udover tidsenheder kunne vi også bruge andre mål, f.eks. hvis vi ønsker at definere antallet af godbidder, som hunden skal "gives".cost_per_unit– Den aktuelle pris pr. enhed for den pågældende tjeneste.
enheden ordbog bruges til at gemme listen over UNIQUE unit_name værdier. Værdier fra denne ordbog refereres kun i tjenesten tabel, men de er meget vigtige i planlægningsfasen, og når vi opkræver kunder for ydelser.
For hver tjeneste skal vi også definere alle accepterede arter. For eksempel vil vi måske kun tilbyde kæledyrshotelservice til katte og ikke til hunde. Dette kan være tilfældet uanset, at vi tilbyder hundeluftning og pleje. Vi gemmer alle de UNIKKE service_id – species_id par i available_for tabel.
Efter at vi har beskrevet alle vores tjenester og deres detaljer, vil vi nu beskrive de faciliteter (steder), hvor vi leverer disse tjenester.
Der er en god chance for, at vi vil drive mere end én facilitet og levere mere end én service. På grund af det bliver vi nødt til at opbevare alle vores faciliteter og deres relaterede detaljer. Vi bruger faciliteten tabel for at spore:
facilitetsnavn– Et navn, vi vil bruge internt til at betegne den facilitet UNIKT.adresse,telefon,e-mailogcontact_person– Placering og kontaktoplysninger, som stort set er selvforklarende.
For hver facilitet gemmer vi, hvilke tjenester den leverer. Vi kunne have en facilitet kun til katte og en anden kun til hunde. Eller vi kunne have en veterinærtekniker i det ene anlæg og ikke i det andet. Under alle omstændigheder bliver vi nødt til at gemme alle tjenester, vi er i stand til at levere, i hver facilitet. I leverer tabel, gemmer vi et UNIKT facility_id - service_id par. I tilfælde af at tjeneste .har_grænse for den refererede tjeneste er sand, skal vi også definere service_limit for den facilitet også den currently_used antal. Denne værdi bør genberegnes, hver gang vi begynder at levere den service til et kæledyr mere i det pågældende anlæg (f.eks. en plads mere på kæledyrshotellet er taget), eller vi holder op med at give den til et kæledyr (f.eks. antallet af tilgængelige kæledyrssenge på hotellet er steget med én).
Afsnit 3:Sager
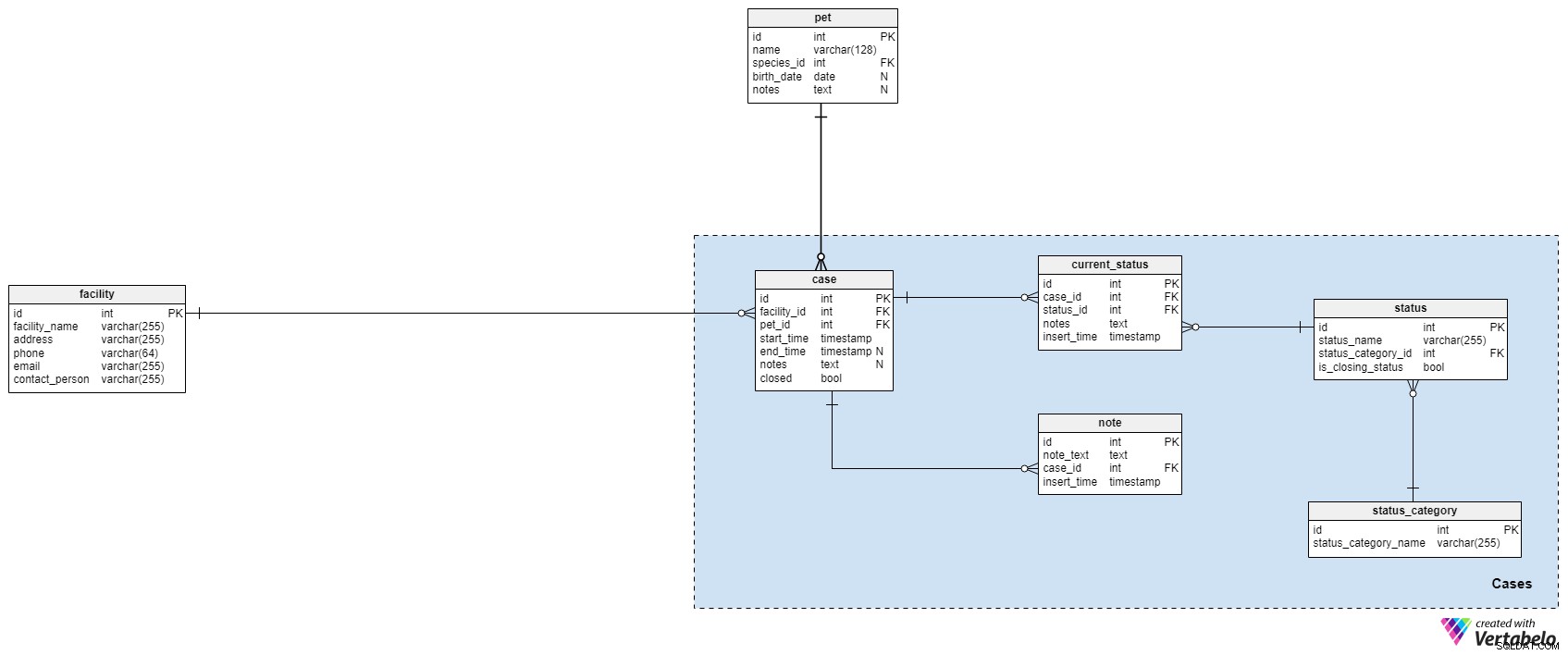
Sager emneområdet er, hvor vi vil beskrive og gemme alle data relateret til besøg eller sessioner (dvs. et besøg er et ophold på vores hundehotel, en pleje, en gåtur osv.)
sagen bord opbevarer kæledyr og faciliteter relateret til sessioner, opkald eller besøg. Jeg har besluttet at bruge "case" som navnet på bordet, fordi vi måske ikke kun gemmer besøg her. Måske vil vi gemme opkald eller andre kontakter. For hver sag gemmer vi:
facility_id– ID'et for den relaterede facilitet. Det kunne være der, hvor kæledyret opholdt sig (på et hotel) eller den facilitet, der modtog et opkald i forbindelse med denne sag.kæledyrs-id– ID'et på det involverede kæledyr.starttid– Det faktiske tidsstempel, da sagen startede.sluttid– Det faktiske tidsstempel, da sagen sluttede. Den vil være NULL, indtil sagen er afsluttet.noter– Eventuelle yderligere bemærkninger, i tekstformat, relateret til den pågældende sag.lukket– Om denne sag er afsluttet eller ej. Det vil blive indstillet til "True", nårsluttidspunkteter indstillet.
Vi bruger kombinationen af facility_id – kæledyrs-id – starttid som den UNIK nøgle i denne tabel.
Hver sag vil have en eller flere statusser tildelt. Vi kan forvente, at den først tildelte status vil indikere, hvornår sagen startede. Derefter tildeler vi nye statusser efter behov, indtil sagen er løst (lukket).
Den første ordbog her er status_category ordbog. Den indeholder en liste over UNIQUE status_kategori_navn værdier. Disse er gruppestatus efter type, f.eks. "fysisk status", "appetit" eller "generel status".
Alle mulige statusser gemmes i status ordbog. For hver status gemmer vi dens status_name , ID'et for den statuskategori, den tilhører, og is_closing_status værdi. Hvis is_closing_status værdien er "True", det betyder, at når vi tildeler denne status, vil sagen blive markeret som afsluttet. status_name – status_kategori_id par danner den UNIKKE nøgle i denne tabel.
I case_status tabel, gemmer vi alle statusser, der faktisk blev tildelt sager. For hver post i denne tabel gemmer vi referencer til sagen og status tabeller, eventuelle yderligere noter , og insert_time af den status. Vi kunne for eksempel opbevare et kæledyrs aktuelle fysiske tilstand og appetit som statusser, når kæledyret kommer ind i vores facilitet. Disse statusser ville blive ændret, hvis vi bemærkede en ændring i deres tilstand. På den anden side gemmer vi også statusser vedrørende hvert enkelt tilfælde (f.eks. "hunden blev gået tur"); vi angiver yderligere detaljer vedrørende denne status i noterne attribut. Disse statusser vil ikke være "lukkende" statusser, fordi de er relateret til a) kæledyrets nuværende status på det pågældende tidspunkt, eller b) til handlinger, der er foretaget under sessionen eller besøget. Et eksempel på en "lukkende" status kunne være "hund checket ud" af vores kæledyrshotel.
Den sidste tabel i dette afsnit er noten bord. Vi bruger denne tabel til at gemme alle noter relateret til tilfælde, hvor der ikke er behov for at indsætte ny status. For hver post gemmer vi note_text , et ID for den relaterede sag og insert_time da den note blev oprettet.
Afsnit 4:Planlagt og leveret
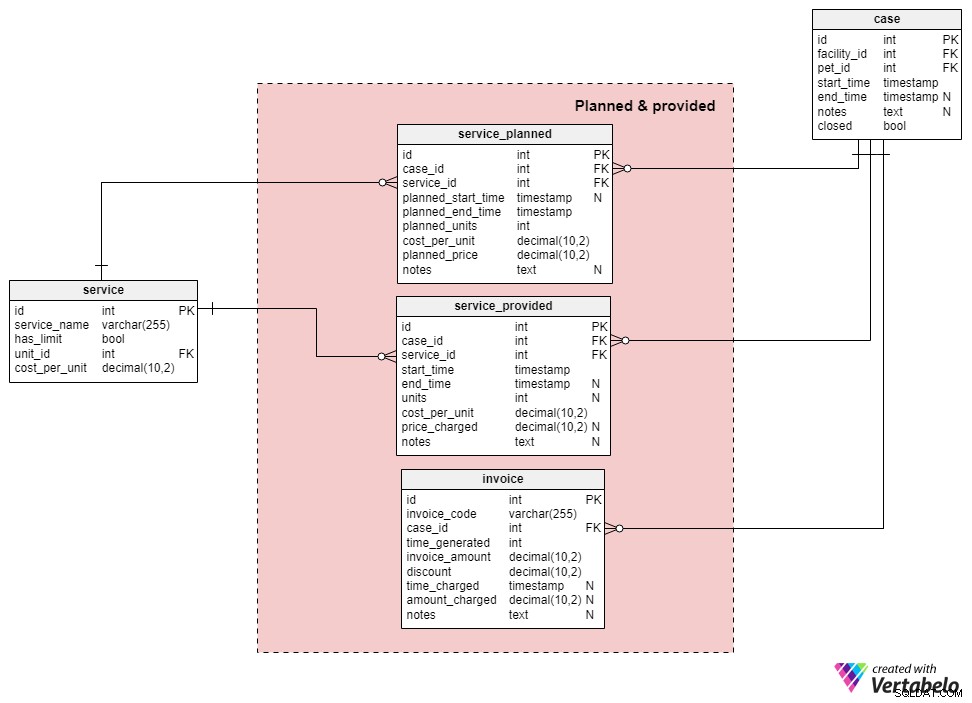
Det sidste emneområde er
service_planned tabellen indeholder en liste over alle tjenester, vi har foreslået vores kunder, eller som de har reserveret. Hver post vil indeholde:
case_id– ID'et for den relaterede sag.service_id– ID'et for den relaterede tjeneste.planlagt_starttidspunkt&planlagt_sluttid– Hvornår planlægger vi at starte og afslutte denne service. Starttidspunktet bør defineres, men sluttidspunktet kan være NULL.planlagte_enheder– Antallet af planlagte serviceenheder, f.eks. 3 dage på dyrehotel.cost_per_unit– Omkostningerne pr. enhed på det tidspunkt. Det er vigtigt at gemme denne værdi, fordi værdien er gemt iservice.cost_per_unitkunne ændre sig mellem det tidspunkt, reservationen foretages, og det tidspunkt, hvor den udføres.planlagt_pris– Prisen for den service. Dette skal være lig medplanlagte_enheder*cost_per_unit.noter– Eventuelle yderligere bemærkninger vedrørende den planlagte service.
service_provided tabellen har næsten samme struktur som service_planned bord. Den eneste forskel er, at enhederne og price_charged attributter kunne indeholde NULL-værdier. Dette skyldes, at vi kan indsætte en post i denne tabel, når vi begynder at levere tjenesten (f.eks. når kæledyret kommer ind på dyrehotellet), og vi opdaterer dem, når vi stopper med at levere tjenesten (f.eks. når ejeren tager kæledyrshjem).
Den sidste tabel i vores model er fakturaen bord. Den fører en liste over alle fakturaer, vi har genereret for alle vores sager. For hver faktura gemmer vi:
fakturakode– Et internt UNIKT nummer genereret for hver faktura.case_id– ID'et for den relaterede sag.tid_genereret– Hvornår fakturaen blev genereret.fakturabeløb– Det oprindelige beløb, vi opkræver hos kunden. Dette beløb skal være lig med summen af alle værdier iprice_chargedforservice_provided.rabat– En rabat givet til kunden (f.eks. på grund af en kupon, et loyalitetskort osv. Årsagen er ligegyldig.)tid_opkrævet– Hvornår kunden faktisk blev opkrævet for den pågældende faktura. Denne attribut vil indeholde en NULL-værdi, indtil betaling er foretaget.beløb_opkrævet– Det faktiske beløb, der blev debiteret kunden for den pågældende faktura.noter– Eventuelle yderligere bemærkninger vedrørende den pågældende faktura.
Hvad vil du tilføje?
I dag talte vi om en mulig datamodel for en kæledyrsplejevirksomhed. Denne model dækker de grundlæggende funktioner, men der er plads til forbedringer. Del venligst dine forslag med os i kommentarfeltet. Tak!