Denne artikel bruger en simpel forespørgsel til at udforske nogle dybe interne forhold vedrørende opdateringsforespørgsler.
Eksempel på data og konfiguration
Eksempeldataoprettelsesscriptet nedenfor kræver en tabel med tal. Hvis du ikke allerede har en af disse, kan scriptet nedenfor bruges til at oprette et effektivt. Den resulterende taltabel vil indeholde en enkelt heltalskolonne med tal fra én til én million:
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); Scriptet nedenfor opretter en klynget eksempeldatatabel med 10.000 id'er med omkring 100 forskellige startdatoer pr. id. Slutdatokolonnen er oprindeligt sat til den faste værdi '99991231'.
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); Mens punkterne i denne artikel gælder temmelig generelt for alle nuværende versioner af SQL Server, kan konfigurationsoplysningerne nedenfor bruges til at sikre, at du ser lignende eksekveringsplaner og ydeevneeffekter:
- SQL Server 2012 Service Pack 3 x64 Developer Edition
- Maksimal serverhukommelse indstillet til 2048 MB
- Fire logiske processorer tilgængelige for instansen
- Ingen sporingsflag aktiveret
- Standard læst forpligtet isolationsniveau
- RCSI- og SI-databaseindstillinger deaktiveret
Aggregerede hashspild
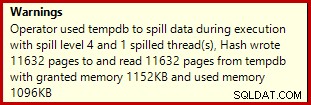
Hvis du kører dataoprettelsesscriptet ovenfor med faktiske eksekveringsplaner aktiveret, kan hash-aggregatet spildes til tempdb og generere et advarselsikon:

Når det udføres på SQL Server 2012 Service Pack 3, vises yderligere oplysninger om udslippet i værktøjstippet:
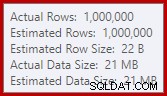
Dette spild kan være overraskende, eftersom inputrækkeestimater for Hash Match er nøjagtigt korrekte:
Vi er vant til at sammenligne estimater på input til sorteringer og hash-sammenføjninger (kun build-input), men ivrige hash-aggregater er forskellige. Et hashaggregat fungerer ved at akkumulere grupperede resultatrækker i hashtabellen, så det er antallet af output rækker, der er vigtige:
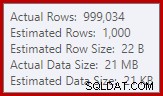
Kardinalitetsestimatoren i SQL Server 2012 giver et ret dårligt gæt på antallet af forventede distinkte værdier (1.000 mod 999.034 faktiske); hash-aggregatet spildes rekursivt til niveau 4 ved kørsel som en konsekvens. Den 'nye' kardinalitetsestimator, der er tilgængelig i SQL Server 2014 og fremefter, producerer tilfældigvis et mere nøjagtigt estimat for hash-outputtet i denne forespørgsel, så du vil ikke se et hashspild i dette tilfælde:

Antallet af faktiske rækker kan være lidt anderledes for dig, givet brugen af en pseudo-tilfældig talgenerator i scriptet. Det vigtige er, at Hash Aggregate-udslip afhænger af antallet af unikke værdier, der outputtes, ikke af inputstørrelsen.
Opdateringsspecifikationen
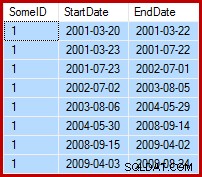
Den aktuelle opgave er at opdatere eksempeldataene, således at slutdatoerne er sat til dagen før den følgende startdato (per SomeID). For eksempel kan de første par rækker af eksempeldataene se sådan ud før opdateringen (alle slutdatoer sat til 9999-12-31):

Så sådan efter opdateringen:
1. Grundlinjeopdateringsforespørgsel
En rimelig naturlig måde at udtrykke den nødvendige opdatering i T-SQL på er som følger:
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Efterudførelsen (faktisk) udførelsesplan er:
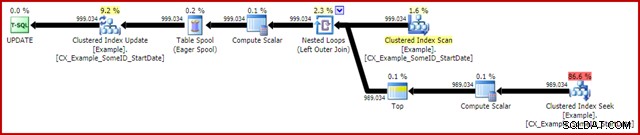
Den mest bemærkelsesværdige funktion er brugen af en ivrig bordspole til at give Halloween-beskyttelse. Dette er påkrævet for korrekt drift her på grund af selvforbindelsen af opdateringsmåltabellen. Effekten er, at alt til højre for spolen køres til færdiggørelse, og gemmer al den information, der er nødvendig for at foretage ændringer i en tempdb-arbejdstabel. Når læseoperationen er afsluttet, afspilles indholdet af arbejdstabellen igen for at anvende ændringerne ved Clustered Index Update iteratoren.
Ydeevne
For at fokusere på det maksimale ydeevnepotentiale i denne eksekveringsplan kan vi køre den samme opdateringsforespørgsel flere gange. Det er klart, at kun den første kørsel vil resultere i ændringer i dataene, men dette viser sig at være en mindre overvejelse. Hvis dette generer dig, er du velkommen til at nulstille slutdatokolonnen før hver kørsel ved hjælp af følgende kode. De generelle punkter, jeg vil komme med, afhænger ikke af antallet af dataændringer, der faktisk er foretaget.
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
Med indsamling af eksekveringsplan deaktiveret, alle påkrævede sider i bufferpuljen og ingen nulstilling af slutdatoværdierne mellem kørsler, udføres denne forespørgsel typisk på omkring 5700ms på min bærbare computer. Statistikkens IO-output er som følger:(læs fremadlæsning og LOB-tællere var nul, og er udeladt af pladshensyn)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
Scanningstallet repræsenterer antallet af gange, en scanningsoperation blev startet. For eksempeltabellen er dette 1 for Clustered Index Scan og 999.034 for hver gang den korrelerede Clustered Index Seek er rebound. Arbejdsbordet, der bruges af Eager Spool, har en scanning, der kun er startet én gang.
Logiske læsninger
Den mere interessante information i IO-outputtet er antallet af logiske læsninger:over 6 millioner for eksempeltabellen og næsten 3 mio. til arbejdsbordet.
Eksempeltabellens logiske læsninger er for det meste forbundet med søgningen og opdateringen. Søgningen medfører 3 logiske læsninger for hver iteration:1 hver for indeksets rod-, mellem- og bladniveauer. Opdateringen koster ligeledes 3 læsninger hver gang en række opdateres, efterhånden som motoren navigerer ned i b-træet for at finde målrækken. Clustered Index Scan er kun ansvarlig for et par tusinde læsninger, én pr. side læs.
Spool-arbejdsbordet er også struktureret internt som et b-træ, og tæller flere læsninger, når spolen lokaliserer indsættelsespositionen, mens den bruger input. Måske kontra-intuitivt tæller spoolen ingen logiske læsninger, mens den læses for at drive Clustered Index Update. Dette er simpelthen en konsekvens af implementeringen:en logisk læsning tælles hver gang koden udfører BPool::Get metode. At skrive til spolen kalder denne metode på hvert niveau af indekset; læsning fra spoolen følger en anden kodesti, der ikke kalder BPool::Get overhovedet.
Bemærk også, at IO-statistikkens output rapporterer en enkelt total for eksempeltabellen, på trods af at den tilgås af tre forskellige iteratorer i udførelsesplanen (Scan, Seek og Update). Dette sidstnævnte faktum gør det svært at korrelere logiske læsninger til iteratoren, der forårsagede dem. Jeg håber, at denne begrænsning bliver løst i en fremtidig version af produktet.
2. Opdater ved hjælp af rækkenumre
En anden måde at udtrykke opdateringsforespørgslen på involverer nummerering af rækkerne pr. ID og joinforbindelse:
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); Efterudførelsesplanen er som følger:
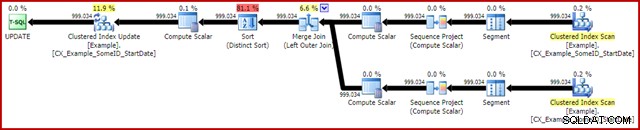
Denne forespørgsel kører typisk i 2950ms på min bærbare computer, som kan sammenlignes positivt med de 5700ms (under samme omstændigheder) set for den oprindelige opdateringserklæring. Statistikkens IO-output er:
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Dette viser to scanninger startet for eksempeltabellen (en for hver Clustered Index Scan iterator). De logiske læsninger er igen en aggregering over alle iteratorer, der får adgang til denne tabel i forespørgselsplanen. Som før gør manglen på en opdeling det umuligt at afgøre, hvilken iterator (af de to scanninger og opdateringen) der var ansvarlig for de 3 millioner læsninger.
Ikke desto mindre kan jeg fortælle dig, at Clustered Index Scans kun tæller et par tusinde logiske læsninger hver. Langt størstedelen af de logiske læsninger er forårsaget af Clustered Index Update, der navigerer ned i indeks b-træet for at finde opdateringspositionen for hver række, den behandler. Du bliver nødt til at tage mit ord for det for øjeblikket; mere forklaring vil komme snart.
Ulemperne
Det er stort set slutningen på de gode nyheder for denne form for forespørgslen. Den fungerer meget bedre end originalen, men den er meget mindre tilfredsstillende af en række andre årsager. Hovedproblemet er forårsaget af en optimeringsbegrænsning, hvilket betyder, at den ikke genkender, at rækkenummereringsoperationen producerer et unikt nummer for hver række i en SomeID-partition.
Denne simple kendsgerning fører til en række uønskede konsekvenser. For det første er flettesammenføjningen konfigureret til at køre i mange-til-mange-sammenføjningstilstand. Dette er årsagen til den (ubrugte) arbejdstabel i statistik-IO (mange-til-mange-fletning kræver en arbejdstabel for duplikat-sammenføringsnøgler tilbage). At forvente en mange-til-mange join betyder også, at kardinalitetsestimatet for join-outputtet er håbløst forkert:
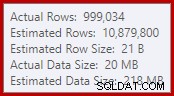
Som en konsekvens heraf anmoder Sorten om alt for meget hukommelsesbevilling. Rodknudeegenskaberne viser, at Sort ville have ønsket 812.752 KB hukommelse, selvom den kun fik 379.440 KB på grund af den begrænsede maksimale serverhukommelsesindstilling (2048 MB). Den slags brugte faktisk maksimalt 58.968 KB ved kørsel:
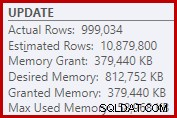
Overdreven hukommelse giver mulighed for at stjæle hukommelse væk fra andre produktive anvendelser og kan føre til forespørgsler, der venter, indtil hukommelsen bliver tilgængelig. I mange henseender kan overdreven hukommelsesbevillinger være mere et problem end at undervurdere.
Optimeringsbegrænsningen forklarer også, hvorfor et flettesammenføjningstip var nødvendigt på forespørgslen for den bedste ydeevne. Uden dette tip vurderer optimeringsværktøjet forkert, at en hash-join ville være billigere end mange-til-mange-fusionen. Hash join-planen kører i gennemsnit på 3350ms.
Som en sidste negativ konsekvens skal du bemærke, at sorteringen i planen er en særskilt sortering. Nu er der et par grunde til den sortering (ikke mindst fordi den kan give den nødvendige Halloween-beskyttelse), men det er kun en Særlig Sorter fordi optimeringsværktøjet savner unikhedsoplysningerne. Generelt er det svært at holde meget af denne eksekveringsplan ud over præstationen.
3. Opdater ved hjælp af LEAD-analysefunktionen
Da denne artikel primært er rettet mod SQL Server 2012 og senere, kan vi udtrykke opdateringsforespørgslen ganske naturligt ved hjælp af LEAD-analysefunktionen. I en ideel verden kunne vi bruge en meget kompakt syntaks som:
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); Det er desværre ikke lovligt. Det resulterer i fejlmeddelelse 4108, "Windowed-funktioner kan kun vises i SELECT- eller ORDER BY-sætningerne". Dette er lidt frustrerende, fordi vi håbede på en eksekveringsplan, der kunne undgå en selvtilmelding (og den tilhørende opdatering Halloween Protection).
Den gode nyhed er, at vi stadig kan undgå selvtilslutningen ved at bruge et fælles tabeludtryk eller en afledt tabel. Syntaksen er lidt mere udførlig, men ideen er stort set den samme:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); Efterudførelsesplanen er:

Dette kører typisk på omkring 3400ms på min bærbare computer, som er langsommere end rækkenummerløsningen (2950ms), men stadig meget hurtigere end originalen (5700ms). En ting, der skiller sig ud fra udførelsesplanen, er udslipstypen (igen, yderligere spildoplysninger takket være forbedringerne i SP3):
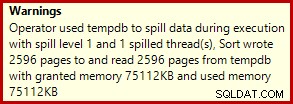
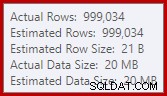
Dette er et ganske lille spild, men det kan stadig påvirke ydeevnen til en vis grad. Det mærkelige ved det er, at input-estimatet til sorteringen er nøjagtigt korrekt:
Heldigvis er der en "fix" til denne specifikke tilstand i SQL Server 2012 SP2 CU8 (og andre udgivelser – se KB-artiklen for detaljer). At køre forespørgslen med rettelsen og det påkrævede sporingsflag 7470 aktiveret betyder, at sorteringen anmoder om nok hukommelse til at sikre, at den aldrig spildes til disken, hvis den estimerede inputsorteringsstørrelse ikke overskrides.
LEAD-opdateringsforespørgsel uden sorteringsspild
For variation bruger den rettelsesaktiverede forespørgsel nedenfor afledt tabelsyntaks i stedet for en CTE:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); Den nye efterudførelsesplan er:

Eliminering af det lille spild forbedrer ydeevnen fra 3400 ms til 3250 ms . Statistikkens IO-output er:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
Hvis du sammenligner dette med de logiske læsninger for den rækkenummererede forespørgsel, vil du se, at de logiske læsninger er faldet fra 3.001.808 til 2.999.455 – en forskel på 2.353 læsninger. Dette svarer nøjagtigt til fjernelse af en enkelt Clustered Index Scan (én læst pr. side).
Du husker måske, at jeg nævnte, at langt størstedelen af de logiske læsninger for disse opdateringsforespørgsler er forbundet med Clustered Index Update, og at scanningerne var forbundet med "kun et par tusinde læsninger". Vi kan nu se dette lidt mere direkte ved at køre en simpel rækkeoptællingsforespørgsel mod eksempeltabellen:
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
IO-output viser nøjagtigt de 2.353 logiske læseforskelle mellem rækkenummeret og leadopdateringer:
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
Yderligere forbedring?
Den spil-fixed lead-forespørgsel (3250ms) er stadig en del langsommere end den dobbelte række nummererede forespørgsel (2950ms), hvilket kan være lidt overraskende. Intuitivt kan man forvente, at en enkelt scannings- og analysefunktion (Window Spool og Stream Aggregate) er hurtigere end to scanninger, to sæt rækkenummerering og en joinforbindelse.
Uanset hvad er det, der springer ud fra planen for eksekvering af leadforespørgsler, sorteringen. Den var også til stede i den rækkenummererede forespørgsel, hvor den bidrog med Halloween-beskyttelse samt en optimeret sorteringsrækkefølge for Clustered Index Update (som har DMLRequestSort-egenskabssættet).
Sagen er, at denne sortering er fuldstændig unødvendig i lead-forespørgselsplanen. Det er ikke nødvendigt til Halloween Protection, fordi selvtilslutningen er gået. Det er heller ikke nødvendigt for optimeret indsættelsessorteringsrækkefølge:rækkerne læses i Clustered Key-rækkefølge, og der er intet i planen, der forstyrrer den rækkefølge. Det virkelige problem kan ses ved at se på sorteringsegenskaberne:

Læg mærke til sektionen Bestil efter der. Sorteringen er sorteret efter SomeID og StartDate (de klyngede indeksnøgler), men også efter [Uniq1002], som er uniquifieren. Dette er en konsekvens af ikke at erklære det klyngede indeks som unikt, selvom vi tog skridt i datapopulationsforespørgslen for at sikre, at kombinationen af SomeID og StartDate faktisk ville være unik. (Dette var bevidst, så jeg kunne tale om dette.)
Alligevel er dette en begrænsning. Rækker læses fra Clustered Index i rækkefølge, og de nødvendige interne garantier eksisterer, således at optimizeren sikkert kan undgå denne sortering. Det er simpelthen en forglemmelse, at optimizeren ikke genkender, at den indkommende stream er sorteret efter uniquifier samt efter SomeID og StartDate. Den genkender, at (SomeID, StartDate) rækkefølge kunne bevares, men ikke (SomeID, StartDate, uniquifier). Igen håber jeg, at dette vil blive behandlet i en fremtidig version.
For at omgå dette kan vi gøre, hvad vi skulle have gjort i første omgang:opbygge det klyngede indeks som unikt:
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
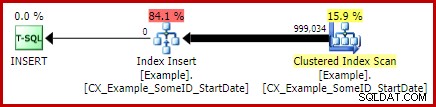
Jeg vil efterlade det som en øvelse for læseren at vise, at de to første (ikke-LEAD) forespørgsler ikke drager fordel af denne indekseringsændring (udeladt udelukkende af pladshensyn – der er meget at dække).
Den endelige form for forespørgslen om opdatering af kundeemner
Med den unikke klynget indeks på plads, producerer den nøjagtig samme LEAD-forespørgsel (CTE eller afledt tabel, som du vil) den estimerede (førudførelse) plan, vi forventer:

Dette virker ret optimalt. En enkelt læse- og skriveoperation med et minimum af operatører imellem. Det virker bestemt meget bedre end den tidligere version med den unødvendige Sort, som blev udført på 3250 ms, når det undgåelige spild blev fjernet (på bekostning af at øge hukommelsesbevillingen en smule).
Planen efter udførelse (faktisk) er næsten nøjagtig den samme som planen før udførelse:

Alle estimaterne er nøjagtigt korrekte, undtagen outputtet fra Window Spool, som er slukket med 2 rækker. Statistikkerne IO-oplysninger er nøjagtig de samme som før sorteringen blev fjernet, som du ville forvente:
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
For at opsummere kort er den eneste tilsyneladende forskel mellem denne nye plan og den umiddelbart tidligere, at sorteringen (med et anslået omkostningsbidrag på næsten 80%) er blevet fjernet.
Det kan da komme som en overraskelse at høre, at den nye forespørgsel – uden sorteringen – udføres på 5000ms . Dette er meget værre end de 3250 ms med Sort, og næsten lige så længe som den originale loop join-forespørgsel på 5700 ms. Den dobbelte rækkenummereringsløsning er stadig langt fremme ved 2950ms.
Forklaring
Forklaringen er noget esoterisk og relaterer sig til den måde, låse håndteres på for den seneste forespørgsel. Vi kan vise denne effekt på flere måder, men den enkleste er nok at se på vente- og låsestatistikken ved hjælp af DMV'er:
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; Når det klyngede indeks ikke er unikt, og der er en sortering i planen, er der ingen signifikante ventetider, kun et par PAGEIOLATCH_UP-ventinger og de forventede SOS_SCHEDULER_YIELDs.
Når det klyngede indeks er unikt, og sorteringen er fjernet, er ventetiden:
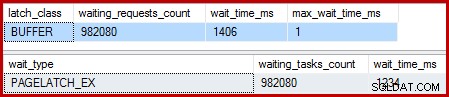
Der er 982.080 eksklusive sidelåse der, med en ventetid, der forklarer stort set al den ekstra eksekveringstid. For at understrege, det er næsten én ventetid pr. række opdateret! Vi forventer måske en ændring af låsen pr. række, men ikke en lås vent , især når testforespørgslen er den eneste aktivitet på forekomsten. Ventetiden på låsen er korte, men der er rigtig mange af dem.
Dovne låse
Efter udførelse af forespørgslen med en debugger og analysator tilknyttet, er forklaringen som følger.
Clustered Index Scan bruger dovne låse – en optimering, der betyder, at låsene kun frigives, når en anden tråd kræver adgang til siden. Normalt udløses låsene umiddelbart efter læsning eller skrivning. Dovne låse optimerer det tilfælde, hvor scanning af en hel side ellers ville opnå og frigive den samme sidelås for hver række. Når lazy latching bruges uden uenighed, tages der kun en enkelt latch for hele siden.
Problemet er, at udførelsesplanens pipelinede karakter (ingen blokerende operatører) betyder, at læsninger overlapper med skrivninger. Når Clustered Index Update forsøger at erhverve en EX-lås for at ændre en række, vil den næsten altid opdage, at siden allerede er låst SH (den dovne lås, der tages af Clustered Index Scan). Denne situation resulterer i en ventetid.
Som en del af forberedelsen til at vente og skifte til det næste kørebare element på skemalæggeren, er koden omhyggelig med at frigive eventuelle dovne låse. Slip den dovne lås signalerer den første kvalificerede tjener, som tilfældigvis er sig selv. Så vi har den mærkelige situation, hvor en tråd blokerer sig selv, udløser sin dovne lås og derefter signalerer sig selv, at den kan køres igen. Tråden tages op igen og fortsætter, men først efter alt det spildte suspend- og switch-, signal- og genoptagelsesarbejde er udført. Som jeg sagde før, er ventetiden korte, men der er mange af dem.
For alt, hvad jeg ved, er denne mærkelige sekvens af begivenheder ved design og af gode interne grunde. Alligevel er der ingen mulighed for at komme væk fra det faktum, at det har en ret dramatisk indflydelse på præstationen her. Jeg vil stille nogle forespørgsler om dette og opdatere artiklen, hvis der er en offentlig udtalelse at komme med. I mellemtiden kan overdrevne selvlåsende ventetider være noget at være opmærksom på med pipelinede opdateringsforespørgsler, selvom det ikke er klart, hvad der skal gøres ved det fra forespørgselsskriverens synspunkt.
Betyder det, at tilgangen til dobbelt rækkenummerering er det bedste, vi kan gøre for denne forespørgsel? Ikke helt.
4. Manuel Halloween-beskyttelse
Denne sidste mulighed kan lyde og se lidt skør ud. Den overordnede idé er at skrive al den information, der er nødvendig for at foretage ændringerne i en tabelvariabel, og derefter udføre opdateringen som et separat trin.
I mangel af en bedre beskrivelse kalder jeg dette den "manuelle HP"-tilgang, fordi den konceptuelt ligner at skrive alle ændringsoplysningerne til en Ivrig Table Spool (som det ses i den første forespørgsel), før du kører opdateringen fra den Spool.
Under alle omstændigheder er koden som følger:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); Denne kode bruger bevidst en tabelvariabel for at undgå omkostningerne ved automatisk oprettede statistikker, som det ville medføre ved brug af en midlertidig tabel. Dette er OK her, fordi jeg kender den planform, jeg ønsker, og det afhænger ikke af omkostningsestimater eller statistiske oplysninger.
Den eneste ulempe ved tabelvariablen (uden et sporingsflag) er, at optimeringsværktøjet typisk vil estimere en enkelt række og vælge indlejrede loops til opdateringen. For at forhindre dette har jeg brugt et sammenføjningstip. Igen er dette drevet af at kende præcis den planform, der skal opnås.
Post-udførelsesplanen for tabelvariabelindsættelsen ser nøjagtig ud som den forespørgsel, der havde problemet med latch waits:

Fordelen ved denne plan er, at den ikke ændrer den samme tabel, som den læser fra. Ingen Halloween-beskyttelse er påkrævet, og der er ingen chance for låseinterferens. Derudover er der betydelige interne optimeringer for tempdb-objekter (låsning og logning) og andre normale bulkload-optimeringer anvendes også. Husk, at masseoptimeringer kun er tilgængelige for indsættelser, ikke opdateringer eller sletninger.
Efterudførelsesplanen for opdateringserklæringen er:
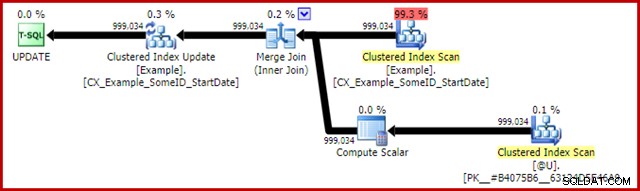
Merge Join her er den effektive en-til-mange type. Mere til det punkt, denne plan kvalificerer sig til en særlig optimering, der betyder, at Clustered Index Scan og Clustered Index Update deler det samme rækkesæt. Den vigtige konsekvens er, at opdateringen ikke længere skal lokalisere rækken, der skal opdateres - den er allerede placeret korrekt ved læsningen. Dette sparer en masse logiske læsninger (og anden aktivitet) ved opdateringen.
Der er intet i normale udførelsesplaner, der viser, hvor denne Shared Rowset-optimering anvendes, men aktivering af udokumenteret sporingsflag 8666 afslører ekstra egenskaber på opdateringen og scanningen, der viser, at rækkesætdeling er i brug, og at der tages skridt for at sikre, at opdateringen er sikker fra Halloween-problemet.
Statistik IO output for de to forespørgsler er som følger:
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Begge læsninger af eksempeltabellen involverer en enkelt scanning og en logisk læsning pr. side (se den enkle rækkeoptællingsforespørgsel tidligere). #B9C034B8-tabellen er navnet på det interne tempdb-objekt, der understøtter tabelvariablen. Den samlede logiske læsning for begge forespørgsler er 3 * 2353 =7.059. Arbejdsbordet er det interne lager i hukommelsen, der bruges af Window Spool.
Den typiske udførelsestid for denne forespørgsel er 2300ms . Endelig har vi noget, der slår den dobbelte rækkenummereringsforespørgsel (2950 ms), så usandsynligt som det kan virke.
Sidste tanker
Der kan være endnu bedre måder at skrive denne opdatering på, som yder endnu bedre end den "manuelle HP"-løsning ovenfor. Ydeevneresultaterne kan endda være forskellige på din hardware- og SQL Server-konfiguration, men ingen af disse er hovedpointen i denne artikel. Det betyder ikke, at jeg ikke er interesseret i at se bedre forespørgsler eller sammenligninger af ydeevne – det er jeg.
Pointen er, at der sker meget mere inde i SQL Server, end der er afsløret i eksekveringsplaner. Forhåbentlig vil nogle af detaljerne diskuteret i denne ret lange artikel være interessante eller endda nyttige for nogle mennesker.
Det er godt at have forventninger til ydeevne og at vide, hvilke planformer og egenskaber der generelt er gavnlige. Den slags erfaring og viden vil tjene dig godt for 99 % eller flere af de forespørgsler, du nogensinde bliver bedt om at tune. Nogle gange er det dog godt at prøve noget lidt mærkeligt eller usædvanligt bare for at se, hvad der sker, og for at bekræfte disse forventninger.