Har dine valg af SQL-serverdatatyper og deres størrelser betydning?
Svaret ligger i det resultat, du fik. Har din database ballon på kort tid? Er dine forespørgsler langsomme? Fik du de forkerte resultater? Hvad med runtime fejl under indsættelser og opdateringer?
Det er ikke så meget en skræmmende opgave, hvis du ved, hvad du laver. I dag vil du lære de 5 værste valg, man kan træffe med disse datatyper. Hvis de er blevet en vane for dig, er det dette, vi bør rette for din egen skyld og dine brugere.
Masser af datatyper i SQL, masser af forvirring
Da jeg først lærte om SQL Server-datatyper, var valgene overvældende. Alle typerne er blandet sammen i mit sind som denne ordsky i figur 1:

Vi kan dog organisere det i kategorier:
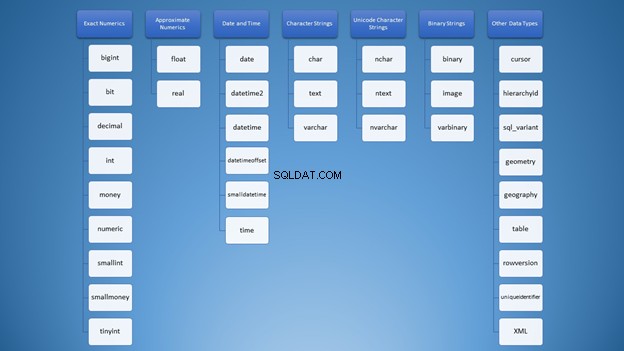
Alligevel, for at bruge strenge, har du masser af muligheder, der kan føre til forkert brug. Først tænkte jeg, at varchar og nvarchar var bare de samme. Desuden er de begge tegnstrengtyper. At bruge tal er ikke anderledes. Som udviklere skal vi vide, hvilken type vi skal bruge i forskellige situationer.
Men du kan undre dig over, hvad der er det værste, der kan ske, hvis jeg træffer det forkerte valg? Lad mig fortælle dig!
1. Valg af forkerte SQL-datatyper
Dette element vil bruge strenge og hele tal til at bevise pointen.
Brug af den forkerte tegnstreng SQL-datatype
Lad os først gå tilbage til strenge. Der er denne ting, der hedder Unicode og ikke-Unicode-strenge. Begge har forskellige opbevaringsstørrelser. Du definerer ofte dette på kolonner og variabeldeklarationer.
Syntaksen er enten varchar (n)/char (n) eller nvarchar (n)/nchar (n) hvor n er størrelsen.
Bemærk, at n er ikke antallet af tegn, men antallet af bytes. Det er en almindelig misforståelse, der sker, fordi i varchar , antallet af tegn er det samme som størrelsen i bytes. Men ikke i nvarchar .
For at bevise dette faktum, lad os oprette 2 tabeller og lægge nogle data ind i dem.
CREATE TABLE dbo.VarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString VARCHAR(4000)
)
GO
CREATE TABLE dbo.NVarcharTable
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY CLUSTERED,
someString NVARCHAR(4000)
)
GO
INSERT INTO VarcharTable (someString)
VALUES (REPLICATE('x',4000))
GO 1000
INSERT INTO NVarcharTable (someString)
VALUES (REPLICATE(N'y',4000))
GO 1000
Lad os nu tjekke deres rækkestørrelser ved hjælp af DATALENGTH.
SET STATISTICS IO ON
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM VarcharTable
SELECT TOP 800 *, DATALENGTH(id) + DATALENGTH(someString) AS RowSize FROM NVarcharTable
SET STATISTICS IO OFF
Figur 3 viser, at forskellen er dobbelt. Tjek det ud nedenfor.
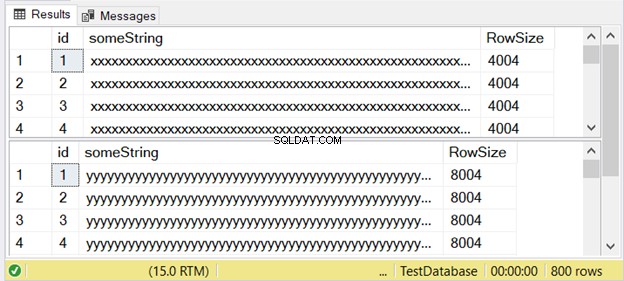
Bemærk det andet resultatsæt med en rækkestørrelse på 8004. Dette bruger nvarchar datatype. Det er også næsten dobbelt så stort som rækkestørrelsen i det første resultatsæt. Og dette bruger varchar datatype.
Du kan se konsekvenserne for lagring og I/O. Figur 4 viser de logiske læsninger af de 2 forespørgsler.
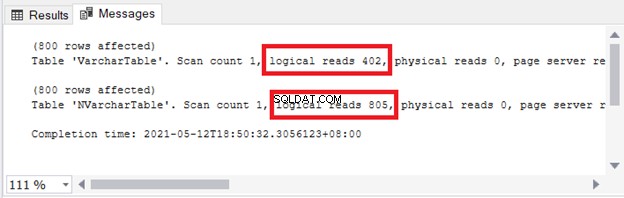
Se? Logiske læsninger er også dobbelte, når du bruger nvarchar sammenlignet med varchar .
Så du kan ikke bare bruge hver enkelt. Hvis du har brug for at gemme flersproget tegn, brug nvarchar . Ellers skal du bruge varchar .
Dette betyder, at hvis du bruger nvarchar kun for enkeltbyte-tegn (som engelsk), lagerstørrelsen er højere . Forespørgselsydeevne er også langsommere med højere logiske læsninger.
I SQL Server 2019 (og nyere) kan du gemme hele rækken af Unicode-tegndata ved hjælp af varchar eller char med nogen af UTF-8-sorteringsmulighederne.
Brug af den forkerte numeriske datatype SQL
Det samme koncept gælder med bigint vs. int – deres størrelser kan betyde nat og dag. Ligesom nvarchar og varchar , stort er dobbelt så stor som int (8 bytes for bigint og 4 bytes for int ).
Alligevel er et andet problem muligt. Hvis du ikke har noget imod deres størrelser, kan der ske fejl. Hvis du bruger en int kolonne og gemmer et tal større end 2.147.483.647, vil der opstå et aritmetisk overløb:
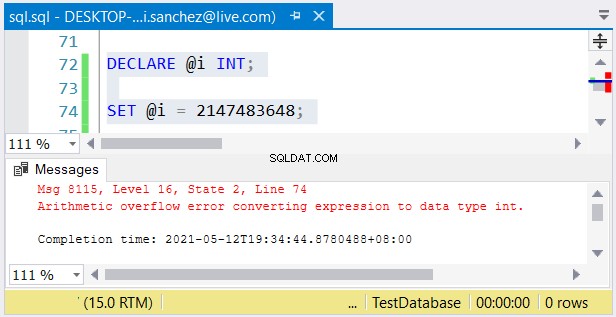
Når du vælger heltaltyper, skal du sørge for, at dataene med den maksimale værdi passer . For eksempel kan du designe en tabel med historiske data. Du planlægger at bruge hele tal som den primære nøgleværdi. Tror du, at den ikke når 2.147.483.647 rækker? Brug derefter int i stedet for bigt som den primære nøglekolonnetype.
Det værste, der kan ske
Hvis du vælger de forkerte datatyper, kan det påvirke forespørgselsydeevnen eller forårsage runtime-fejl. Vælg derfor den datatype, der passer til dataene.
2. Oprettelse af store tabelrækker ved hjælp af store datatyper til SQL
Vores næste punkt er relateret til det første, men det vil udvide pointen endnu mere med eksempler. Det har også noget at gøre med sider og store varchar eller nvarchar kolonner.
Hvad er der med sider og rækkestørrelser?
Konceptet med sider i SQL Server kan sammenlignes med siderne i en spiral notesbog. Hver side i en notesbog har den samme fysiske størrelse. Du skriver ord og tegner billeder på dem. Hvis en side ikke rækker til et sæt afsnit og billeder, fortsætter du på næste side. Nogle gange river du også en side og starter forfra.
Ligeledes er tabeldata, indeksposter og billeder i SQL Server gemt på sider.
En side har samme størrelse på 8 KB. Hvis en række data er meget stor, passer den ikke til siden på 8 KB. En eller flere kolonner vil blive skrevet på en anden side under ROW_OVERFLOW_DATA allokeringsenheden. Den indeholder en pointer til den oprindelige række på siden under IN_ROW_DATA allokeringsenheden.
Baseret på dette kan du ikke bare passe mange kolonner i en tabel under databasedesignet. Der vil være konsekvenser for I/O. Desuden hvis du forespørger meget på disse række-overløbsdata, er eksekveringstiden langsommere . Dette kan være et mareridt.
Der opstår et problem, når du maksimerer alle kolonner af varierende størrelse. Derefter overføres dataene til næste side under ROW_OVERFLOW_DATA. opdatere kolonnerne med mindre data, og det skal fjernes på den side. Den nye mindre datarække vil blive skrevet på siden under IN_ROW_DATA sammen med de andre kolonner. Forestil dig den involverede I/O her.
Eksempel på stor række
Lad os forberede vores data først. Vi vil bruge tegnstrengdatatyper med store størrelser.
CREATE TABLE [dbo].[LargeTable](
[id] [int] IDENTITY(1,1) NOT NULL,
[SomeString] [varchar](15) NOT NULL,
[LargeString] [nvarchar](3980) NOT NULL,
[AnotherString] [varchar](8000) NULL,
CONSTRAINT [PK_LargeTable] PRIMARY KEY CLUSTERED
(
[id] ASC
))
GO
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',500),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),NULL)
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',50))
GO 100
INSERT INTO LargeTable
(SomeString, LargeString, AnotherString)
VALUES(REPLICATE('x',15),REPLICATE('y',3980),REPLICATE('z',8000))
GO 100
Få rækkestørrelsen
Ud fra de genererede data, lad os inspicere deres rækkestørrelser baseret på DATALENGTH.
SELECT *, DATALENGTH(id)
+ DATALENGTH(SomeString)
+ DATALENGTH(LargeString)
+ DATALENGTH(ISNULL(AnotherString,0)) AS RowSize
FROM LargeTable
De første 300 poster passer til IN_ROW_DATA-siderne, fordi hver række har mindre end 8060 bytes eller 8 KB. Men de sidste 100 rækker er for store. Tjek resultatsættet i figur 6.
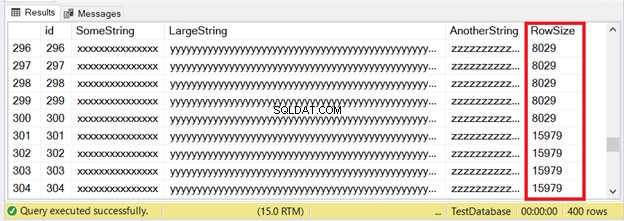
Du ser en del af de første 300 rækker. De næste 100 overskrider sidestørrelsesgrænsen. Hvordan ved vi, at de sidste 100 rækker er i ROW_OVERFLOW_DATA-allokeringsenheden?
Inspicerer ROW_OVERFLOW_DATA
Vi bruger sys.dm_db_index_physical_stats . Det returnerer sideoplysninger om tabel- og indeksposter.
SELECT
ps.index_id
,[Index] = i.[name]
,ps.index_type_desc
,ps.alloc_unit_type_desc
,ps.index_depth
,ps.index_level
,ps.page_count
,ps.record_count
FROM sys.dm_db_index_physical_stats(DB_ID(),
OBJECT_ID('dbo.LargeTable'), NULL, NULL, 'DETAILED') AS ps
INNER JOIN sys.indexes AS i ON ps.index_id = i.index_id
AND ps.object_id = i.object_id;
Resultatsættet er i figur 7.

Der er det. Figur 7 viser 100 rækker under ROW_OVERFLOW_DATA. Dette stemmer overens med figur 6, når der findes store rækker, der starter med række 301 til 400.
Det næste spørgsmål er, hvor mange logiske læsninger vi får, når vi forespørger på disse 100 rækker. Lad os prøve.
SELECT * FROM LargeTable
WHERE id BETWEEN 301 AND 400
ORDER BY AnotherString DESC

Vi ser 102 logiske læsninger og 100 lob-logiske læsninger af LargeTable . Lad disse tal ligge indtil videre – vi sammenligner dem senere.
Lad os nu se, hvad der sker, hvis vi opdaterer de 100 rækker med mindre data.
UPDATE LargeTable
SET AnotherString = 'updated',LargeString='updated'
WHERE id BETWEEN 301 AND 400
Denne opdateringssætning brugte de samme logiske læsninger og lob logiske læsninger som i figur 8. Fra dette ved vi, at der skete noget større på grund af de logiske lob-læsninger på 100 sider.
Men for at være sikker, lad os tjekke det med sys.dm_db_index_physical_stats som vi gjorde tidligere. Figur 9 viser resultatet:

Væk! Sider og rækker fra ROW_OVERFLOW_DATA blev nul efter opdatering af 100 rækker med mindre data. Nu ved vi, at databevægelsen fra ROW_OVERFLOW_DATA til IN_ROW_DATA sker, når store rækker krympes. Forestil dig, hvis dette sker meget for tusinder eller endda millioner af poster. Skørt, ikke?
I figur 8 så vi 100 lob logiske aflæsninger. Se nu figur 10 efter at have kørt forespørgslen igen:

Det blev nul!
Det værste, der kan ske
Langsom forespørgselsydeevne er biproduktet af række-overløbsdataene. Overvej at flytte den eller de store kolonner til en anden tabel for at undgå det. Eller, hvis det er relevant, reducere størrelsen af varchar eller nvarchar kolonne.
3. Blindt brug af implicit konvertering
SQL tillader os ikke at bruge data uden at angive typen. Men det er tilgivende, hvis vi træffer et forkert valg. Den forsøger at konvertere værdien til den type, den forventer, men med en straf. Dette kan ske i en WHERE-klausul eller JOIN.
USE AdventureWorks2017
GO
SET STATISTICS IO ON
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = 77775294979396 -- this will trigger an implicit conversion
SELECT
CardNumber
,CardType
,ExpMonth
,ExpYear
FROM Sales.CreditCard
WHERE CardNumber = '77775294979396'
SET STATISTICS IO OFF
Kortnummeret kolonne er ikke en numerisk type. Det er nvarchar . Så det første SELECT vil forårsage en implicit konvertering. Begge vil dog køre fint og producere det samme resultatsæt.
Lad os tjekke udførelsesplanen i figur 11.
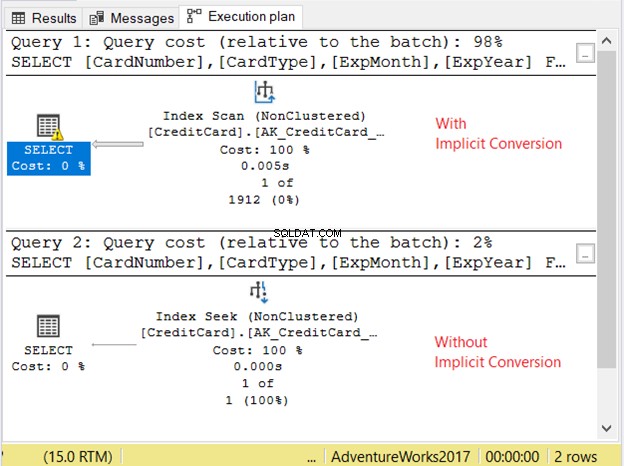
De 2 forespørgsler kørte meget hurtigt. I figur 11 er det nul sekunder. Men se på de 2 planer. Den med implicit konvertering havde en indeksscanning. Der er også et advarselsikon og en fed pil, der peger på SELECT-operatøren. Det fortæller os, at det er dårligt.
Men det slutter ikke der. Hvis du holder musen over SELECT-operatoren, vil du se noget andet:

Advarselsikonet i SELECT-operatoren handler om den implicitte konvertering. Men hvor stor er påvirkningen? Lad os tjekke de logiske aflæsninger.
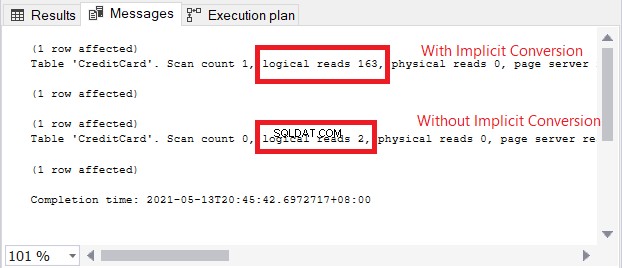
Sammenligningen af logiske læsninger i figur 13 er ligesom himmel og jord. I forespørgslen efter kreditkortoplysninger forårsagede implicit konvertering mere end hundrede gange logiske læsninger. Meget dårligt!
Det værste, der kan ske
Hvis en implicit konvertering forårsagede høje logiske læsninger og en dårlig plan, kan du forvente langsom forespørgselsydeevne på store resultatsæt. For at undgå dette skal du bruge den nøjagtige datatype i WHERE-sætningen og JOINs til at matche de kolonner, du sammenligner.
4. Brug af omtrentlige tal og afrunding
Se figur 2 igen. SQL-serverdatatyper, der tilhører omtrentlige tal, er flydende og rigtig . Kolonner og variabler lavet af dem gemmer en tæt tilnærmelse af en numerisk værdi. Hvis du planlægger at runde disse tal op eller ned, kan du få en stor overraskelse. Jeg har en artikel, der diskuterede dette i detaljer her. Se, hvordan 1 + 1 resulterer i 3, og hvordan du kan håndtere afrunding af tal.
Det værste, der kan ske
Afrunding af en float eller rigtig kan have skøre resultater. Hvis du vil have nøjagtige værdier efter afrunding, skal du bruge decimal eller numerisk i stedet.
5. Indstilling af strengdatatyper med fast størrelse til NULL
Lad os rette opmærksomheden mod datatyper med fast størrelse som char og nchar . Bortset fra de polstrede rum, vil indstilling af dem til NULL stadig have en lagerstørrelse svarende til størrelsen af char kolonne. Så indstil et tegn (500) kolonne til NULL vil have en størrelse på 500, ikke nul eller 1.
CREATE TABLE dbo.CharNullSample
(
id INT NOT NULL IDENTITY(1,1) PRIMARY KEY,
col1 CHAR(500) NULL,
col2 CHAR(200) NULL,
col3 CHAR(350) NULL,
col4 VARCHAR(500) NULL,
col5 VARCHAR(200) NULL,
col6 VARCHAR(350) NULL
)
GO
INSERT INTO CharNullSample (col1, col2, col3, col4, col5, col6)
VALUES (REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350), REPLICATE('x',500), REPLICATE('y',200), REPLICATE('z',350));
GO 200
I ovenstående kode er data maksimeret baseret på størrelsen på char og varchar kolonner. Hvis du tjekker deres rækkestørrelse ved hjælp af DATALENGTH, vises summen af størrelserne af hver kolonne. Lad os nu sætte kolonnerne til NULL.
UPDATE CharNullSample
SET col1 = NULL, col2=NULL, col3=NULL, col4=NULL, col5=NULL, col6=NULL
Dernæst forespørger vi rækkerne ved hjælp af DATALENGTH:
SELECT
DATALENGTH(ISNULL(col1,0)) AS Col1Size
,DATALENGTH(ISNULL(col2,0)) AS Col2Size
,DATALENGTH(ISNULL(col3,0)) AS Col3Size
,DATALENGTH(ISNULL(col4,0)) AS Col4Size
,DATALENGTH(ISNULL(col5,0)) AS Col5Size
,DATALENGTH(ISNULL(col6,0)) AS Col6Size
FROM CharNullSample
Hvad tror du vil være datastørrelserne for hver kolonne? Se figur 14.
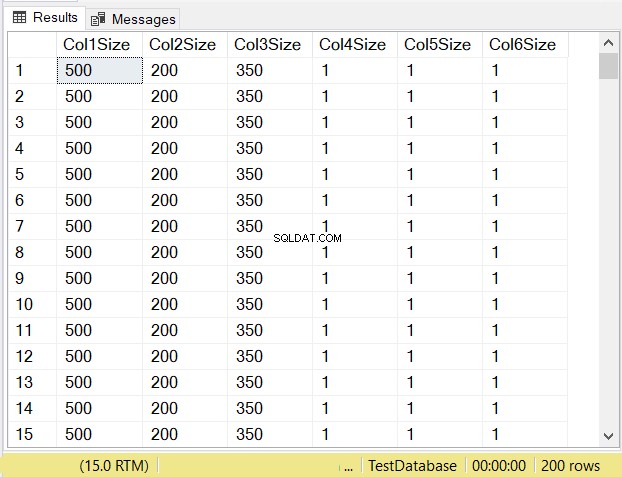
Se på kolonnestørrelserne for de første 3 kolonner. Sammenlign dem derefter med koden ovenfor, da tabellen blev oprettet. Datastørrelsen af NULL-kolonnerne er lig med størrelsen af kolonnen. I mellemtiden er varchar kolonner, når NULL har en datastørrelse på 1.
Det værste, der kan ske
Under design af tabeller, nullable char kolonner, når de er sat til NULL, vil de stadig have den samme lagerstørrelse. De vil også forbruge de samme sider og RAM. Hvis du ikke udfylder hele kolonnen med tegn, kan du overveje at bruge varchar i stedet.
Hvad er det næste?
Så betyder dine valg i SQL-serverdatatyper og deres størrelser noget? De punkter, der præsenteres her, burde være nok til at gøre en pointe. Så hvad kan du gøre nu?
- Afsæt tid til at gennemgå den database, du understøtter. Start med den nemmeste, hvis du har flere på tallerkenen. Og ja, få tid, ikke finde tiden. I vores branche er det næsten umuligt at finde tiden.
- Gennemgå tabellerne, lagrede procedurer og alt, der omhandler datatyper. Bemærk den positive virkning, når du identificerer problemer. Du får brug for det, når din chef spørger, hvorfor du skal arbejde på dette.
- Planlæg at angribe hvert af problemområderne. Følg de metoder eller politikker, som din virksomhed har til at håndtere problemerne.
- Når problemerne er væk, skal du fejre.
Det lyder nemt, men vi ved alle, at det ikke er det. Vi ved også, at der er en lys side i slutningen af rejsen. Det er derfor, de kaldes problemer – fordi der er en løsning. Så glæd dig.
Har du andet at tilføje om dette emne? Fortæl os det i kommentarfeltet. Og hvis dette indlæg gav dig en lys idé, så del det på dine foretrukne sociale medieplatforme.