Jeg har tidligere skrevet om fordelene ved at bruge NOEXPAND tip, selv i Enterprise Edition. Detaljerne er alle i den linkede artikel, men for at opsummere kort:
- SQL Server vil kun oprettes automatisk statistik på en indekseret visning, når en
NOEXPANDtabeltip bruges. Udeladelse af dette tip kan føre til advarsler om udførelsesplan om manglende statistik, som ikke kan løses ved at oprette statistik manuelt. - SQL Server vil kun bruge automatisk eller manuelt oprettet visningsstatistik i kardinalitetsestimatberegninger, når forespørgslen refererer visningen direkte og en
NOEXPANDhint er brugt. For alle undtagen de mest trivielle visningsdefinitioner betyder dette, at kvaliteten af kardinalitetsestimater sandsynligvis vil være lavere, når dette tip ikke bruges, hvilket ofte resulterer i mindre optimale udførelsesplaner. - Manglen på eller manglende evne til at bruge visningsstatistikker kan få optimeringsværktøjet til at gætte på kardinalitetsestimater, selv hvor basistabelstatistik er tilgængelig. Dette kan ske, hvor en del af forespørgselsplanen er erstattet med en indekseret visningsreference af den automatiske visningsmatchningsfunktion, men visningsstatistikker er ikke tilgængelige, som beskrevet ovenfor.
Der er en anden konsekvens af ikke at bruge NOEXPAND tip, som jeg nævnte i forbifarten for et par år siden i min artikel, Optimizer Limitations with Filtered Indexes:
NOEXPAND tip er nødvendige selv i Enterprise Edition for at sikre, at den unikke garanti, som visningsindekserne giver, bruges af optimeringsværktøjet.
Denne artikel undersøger denne erklæring og dens implikationer mere detaljeret.
Demoopsætning
Følgende script opretter en simpel tabel og en indekseret visning:
CREATE TABLE dbo.T
(
col1 integer NOT NULL
);
GO
INSERT dbo.T WITH (TABLOCKX)
(col1)
SELECT
SV.number
FROM master.dbo.spt_values AS SV
WHERE
SV.type = N'P';
GO
CREATE VIEW dbo.VT
WITH SCHEMABINDING
AS
SELECT T.col1
FROM dbo.T AS T;
GO
CREATE UNIQUE CLUSTERED INDEX cuq
ON dbo.VT (col1); Det skaber en enkelt kolonne-heap-tabel og en ubegrænset visning af den samme tabel med et unikt klynget indeks. Dette er ikke beregnet til at være en realistisk use case for en indekseret visning; men det vil hjælpe med at illustrere nøglepunkterne med et minimum af distraktioner. Det vigtige er, at basistabellen her slet ikke har nogen indekser (ikke engang et klynget indeks), men visningen har, og det indeks er unikt.
Eksempelforespørgslen
Overvej følgende simple forespørgsel mod basistabellen:
SELECT DISTINCT
T.col1
FROM dbo.T AS T; Den udførelsesplan, du vil se for denne forespørgsel, afhænger af den udgave af SQL Server, der er i brug. Hvis ikke Enterprise Edition (eller tilsvarende), vil du se en plan som denne:

SQL Server-forespørgselsoptimeringsværktøjet har valgt at scanne basistabellen og anvende den angivne distinkthed ved hjælp af en Distinct Sort-operator. Denne planform forventes fuldt ud, da automatisk matchning af indekserede visninger ikke er tilgængelig uden for Enterprise Edition. Jeg vil stoppe med at sige "Enterprise Edition eller tilsvarende" fra nu af, men fortsæt venligst med at udlede, at jeg mener enhver udgave, der understøtter automatisk visningsmatchning, når jeg siger "Enterprise Edition" fra nu af.
Tipet UDVID VISNINGER
Dette er lidt af en tilsidesættelse, men for at få den samme plan på Enterprise Edition, skal vi bruge en EXPAND VIEWS forespørgselstip:
SELECT DISTINCT
T.col1
FROM dbo.T AS T
OPTION (EXPAND VIEWS);
Det kan virke lidt mærkeligt at bruge dette tip, når der ingen visningsreferencer er i forespørgslen, men det er sådan det virker. EXPAND VIEWS tip angiver effektivt, at matchning af indekseret visning skal deaktiveres under kompilering og optimering af forespørgslen. For at være klar:Uden dette tip kan Enterprise Edition ellers matche (dele af) forespørgslen til en eller flere indekserede visninger.
Med automatisk visningsmatchning aktiveret
Uden en EXPAND VIEWS tip, kompilering af den samme forespørgsel på Developer Edition (for eksempel) producerer en anden plan:
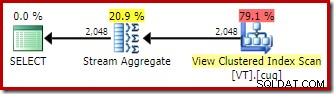
Anvendelsen af indekseret visningsmatching betyder, at udførelsesplanen indeholder en scanning af visningsklyngeindekset i stedet for en basistabelscanning.
Den samme plan produceres i dette tilfælde, hvis forespørgslen refererer til visningen direkte (i stedet for basistabellen):
SELECT DISTINCT
V.col1
FROM dbo.VT AS V; I alle udgaver udvides visningsreferencen, før forespørgselsoptimering begynder. I Enterprise-ækvivalente udgaver kan den udvidede form blive matchet tilbage til visningen senere. Dette er et nøglebegreb at forstå, når man tænker på, hvordan forespørgselskompileren og -optimeringsværktøjet bruger indekserede visninger i SQL Server.
Strømaggregatet
Den mest interessante forskel mellem de to planer, vi har set indtil videre, er Stream Aggregate i den visningsmatchede plan. Hvis du ser på de estimerede omkostninger for Table Scan- og View Scan-operatørerne, vil du se, at de er nøjagtig de samme. Optimeringsværktøjet besluttede ikke at bruge den indekserede visning, fordi det gjorde det billigere at få adgang til dataene. Tværtimod tillader scanning af visningsindekset DISTINCT krav om at blive implementeret som et Stream Aggregate, snarere end et Hash Aggregate eller Distinct Sort (som i den første plan).
Et Stream Aggregate kræver input sorteret efter grupperingskolonne(r). I dette tilfælde svarer distinkten til gruppering efter den enkelte kolonne, og visningens unikke klyngeindeks giver den nødvendige bestillingsgaranti. Optimizerens omkostningsmodel identificerer Stream Aggregate som en billigere mulighed end en Distinct Sort eller Hash Aggregate for denne forespørgsel. Dette er grundlaget for, at optimeringsværktøjet vælger at få adgang til den indekserede visning, når automatisk visningsmatchning er tilgængelig.
Med alt det sagt og forstået er Stream Aggregate stadig uventet:I betragtning af den unikke garanti, som visningsindekset giver, er der slet ikke behov for at udføre denne grupperingsoperation. Den unikke clustered index sikrer allerede, at kolonnen ikke indeholder dubletter.
Dette er i en nøddeskal problemet. Når der bruges automatisk visningsmatchning, genkender optimeringsværktøjet bestillingsgarantien fra visningsindekset, men ikke unikhedsgarantien.
Brug af et NOEXPAND-tip
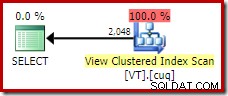
For at få den ideelle udførelsesplan til denne forespørgsel, skal vi referere til visningen direkte og bruge en NOEXPAND tabeltip:
SELECT DISTINCT
V.col1
FROM dbo.VT AS V WITH (NOEXPAND); Dette giver os den plan, som en erfaren databaseperson ville forvente; en, der korrekt genkender, at den distinkte handling er overflødig og kan fjernes:
Et andet eksempel
Undladelse af at drage fordel af entydighedsgarantien fra et visningsindeks kan have andre effekter på den endelige udførelsesplan. Overvej nu en selvsammenføjning af den indekserede visning (igen, bare for at illustrere et koncept – dette er ikke beregnet til at være en realistisk forespørgsel):
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1; Ved at bruge Developer Edition får den valgte eksekveringsplan slet ikke adgang til den indekserede visning og har en hash join (nogle gange en indikation af, at der mangler et nyttigt indeks):
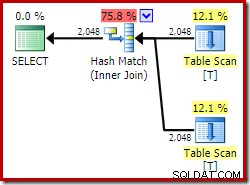
Lad os nu prøve nøjagtig den samme forespørgsel, men med en NOEXPAND tip om hver visningsreference:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1 WITH (NOEXPAND)
JOIN dbo.VT AS V2 WITH (NOEXPAND)
ON V2.col1 = V1.col1; Eksekveringsplanen har nu to indekserede visningsadgange og en flettesammenføjning:
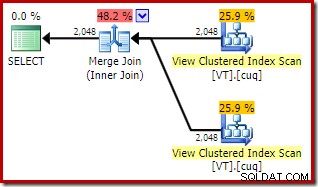
Denne nye plan har en meget lavere estimeret pris end hash join-planen, så hvorfor valgte optimeringsværktøjet ikke denne mulighed før? Vi kan se hvorfor ved at tilføje et sammenføjningstip til den originale forespørgsel:
SELECT
V1.col1,
V2.col1
FROM dbo.VT AS V1
JOIN dbo.VT AS V2
ON V2.col1 = V1.col1
OPTION (MERGE JOIN);
Dette giver et lignende udseende plan, der vælger at få adgang til visningen, selvom NOEXPAND var ikke specificeret:
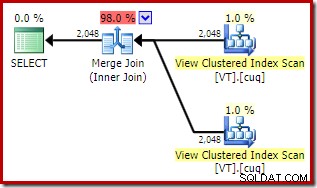
De samlede estimerede omkostninger ved denne plan er højere end begge tidligere eksempler. Merge Join i denne plan tegner sig også for en højere andel af de samlede estimerede omkostninger end før (98 % mod 48,2 %).
Årsagen til dette kan ses ved at se på egenskaberne for flettesammenføjningen. I NOEXPAND plan, var det en en-til-mange-fusion. I planen direkte ovenfor er der tale om en mange-til-mange fusion. Optimizerens omkostningsmodel tildeler en højere omkostning til mange-til-mange-sammenføjninger, fordi en tempdb-arbejdstabel er nødvendig for at håndtere eventuelle dubletter.
Konklusioner
Garantierne fra et unikt indeks kan være et kraftfuldt optimeringsværktøj, så det er en skam, at automatisk indeksmatching i øjeblikket ikke er i stand til at udnytte det. De potentielle fordele rækker ud over at eliminere unødvendige sammenlægninger eller at aktivere en en-til-mange-sammenføjning som set i de foregående enkle eksempler. Generelt kan det være svært at se, at en eksekveringsplan er suboptimal, fordi optimizeren savnede at udnytte en unikhedsgaranti.
Denne optimeringsbegrænsning gælder ikke kun for det unikke klyngeindeks, som en visning skal have for at blive materialiseret. I mere komplekse scenarier kan yderligere ikke-klyngede indekser også være til stede på visningen; måske for at afspejle krydsbordsforhold, som er svære at håndhæve eller repræsentere på anden måde. Hvis disse ikke-klyngede indekser er defineret til at være unikke, vil optimeringsværktøjet også overse disse garantier, hvis der bruges automatisk indeksmatching.
Hvis man føjer dette til begrænsningerne omkring oprettelse og brug af statistisk information, ser det ud til, at afhængighed af automatisk visningsmatchning kan resultere i dårligere udførelsesplaner. Den sikreste mulighed er sandsynligvis at referere eksplicit til indekserede visninger og bruge en NOEXPAND tip hver gang – i hvert fald indtil disse problemer er løst i produktet.
Afbødende faktorer
Jeg skal understrege, at det problem, der er beskrevet i denne artikel, kun gælder for den unikke garanti, der leveres af et unikt visningsindeks. Hvis optimeringsværktøjet kan få den nødvendige unikke information en anden måde , er chancerne gode for, at optimeringsproblemer undgås.
For eksempel kan der være et passende unikt indeks på en basistabel, der refereres til af visningen. Eller i tilfælde af en visning, der indeholder aggregering, kan optimeringsværktøjet allerede udlede en nyttig unikhedsgaranti fra visningens GROUP BY klausul. Den almindelige praksis med at tilføje et visningsklyngeindeks til grupperingsnøglerne tilføjer ingen ekstra unikkeoplysninger i så fald.
Ikke desto mindre er der tidspunkter, hvor denne "entydige tilsyn" kan betyde, at du vil få udførelsesplaner af bedre kvalitet ved at bruge en eksplicit visningsreference og NOEXPAND tip, selv i Enterprise Edition.