I ClusterControl 1.5 tilføjede vi en understøttelse af MySQL NDB Cluster 7.5. I dette blogindlæg vil vi se på nogle af de funktioner, der gør ClusterControl til et godt værktøj til at administrere MySQL NDB Cluster. Først og fremmest, da der er adskillige produkter med "Cluster" i deres navn, vil vi gerne sige et par ord om selve MySQL NDB Cluster, og hvordan det adskiller sig fra andre løsninger.
MySQL NDB-klynge
MySQL NDB Cluster er en delt-intet synkron klynge til MySQL, baseret på NDB-motoren. Det er et produkt med sin egen liste over funktioner og meget anderledes end Galera Cluster eller MySQL InnoDB Cluster. En væsentlig forskel er brugen af NDB-motor, ikke InnoDB, som er standardmotoren til MySQL. I NDB-klynge er data opdelt på tværs af flere dataknuder, mens Galera Cluster eller MySQL InnoDB Cluster indeholder det fulde datasæt på hver af noderne. Dette har alvorlige konsekvenser for den måde, MySQL NDB Cluster håndterer forespørgsler, der bruger JOINs og store bidder af datasættet.
Når det kommer til arkitektur, består MySQL NDB Cluster af tre forskellige nodetyper. Data noder gemmer data ved hjælp af NDB-motor. Data spejles for redundans med op til 4 replikaer af data. Bemærk, at ClusterControl vil implementere 2 replikaer pr. nodegruppe, da dette er den mest testede og stabile konfiguration. Management noder er beregnet til at kontrollere klyngen - af høje tilgængelighedsårsager har du typisk to sådanne noder. SQL-noder bruges som indgangspunkter til klyngen. De parser SQL, beder om data fra dataknuderne og samler resultatsæt, når det er nødvendigt.
ClusterControl-funktioner til MySQL NDB Cluster
Implementering
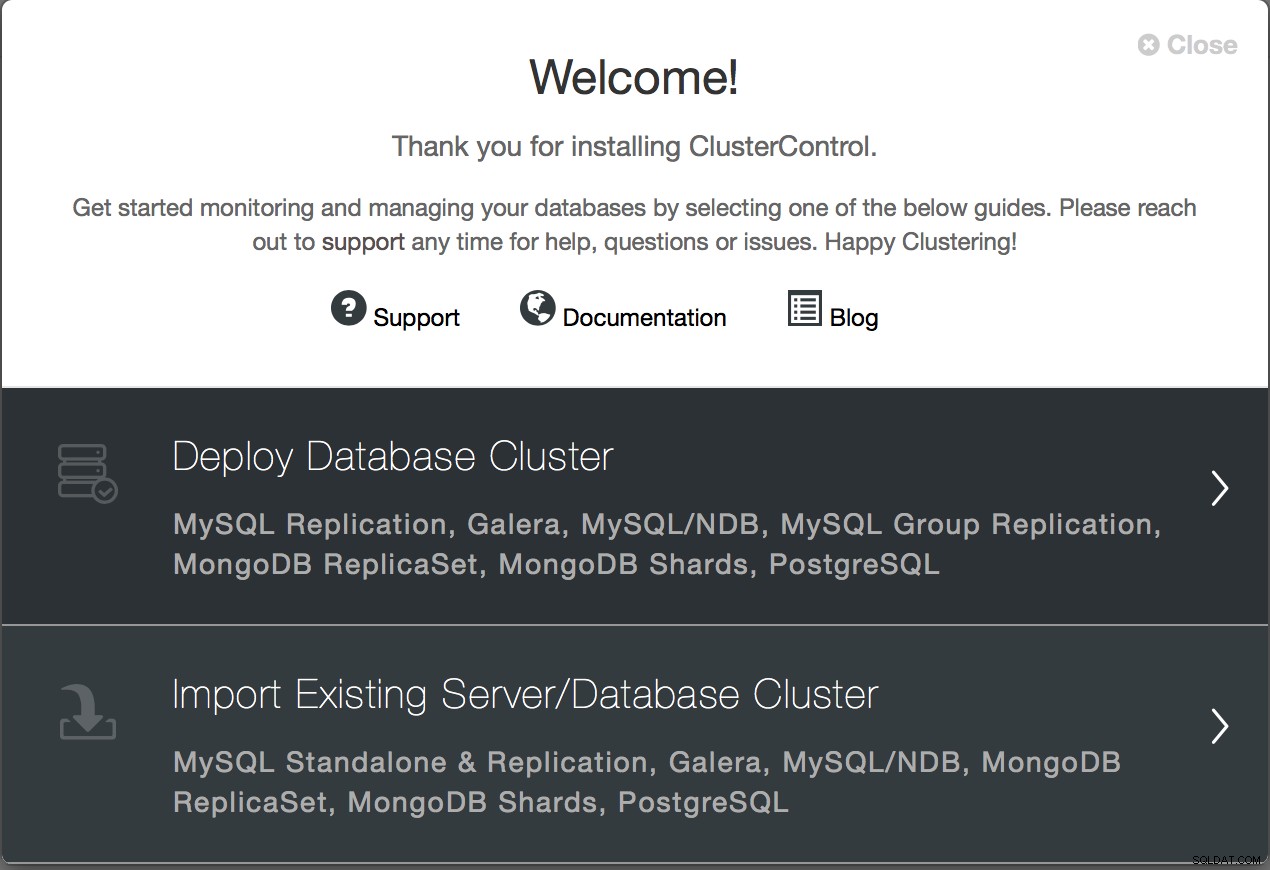
ClusterControl 1.5 understøtter implementering af MySQL NDB Cluster 7.5. Det gøres gennem den samme installationsguide som med de resterende klyngetyper.
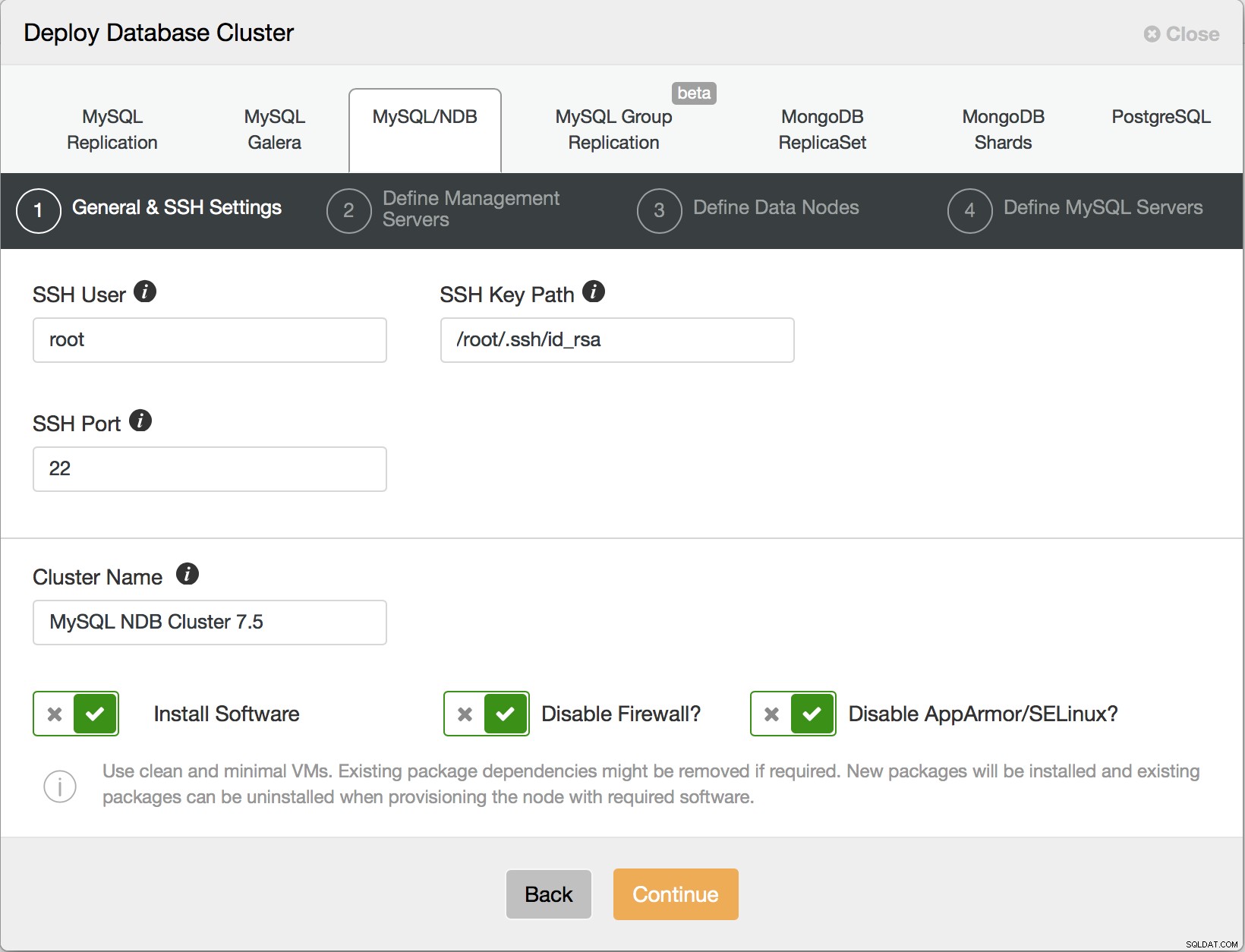
I det første trin skal du konfigurere, hvordan ClusterControl kan logge ind via SSH til værterne - dette er et standardkrav for ClusterControl - det er agentløst, så det kræver root SSH-adgang enten direkte, til root-kontoen eller via (adgangskode eller adgangskodefri) sudo.
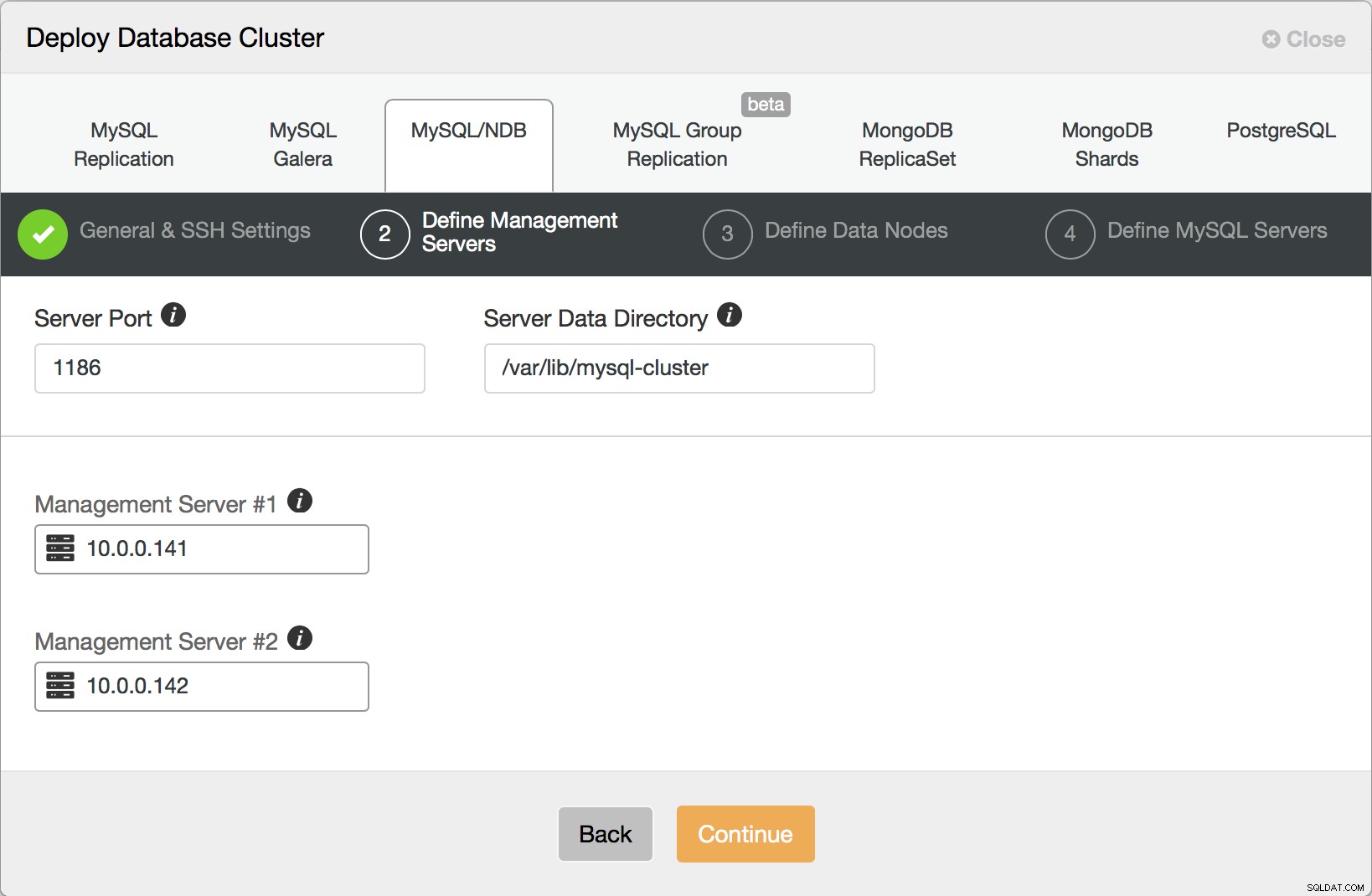
I det næste trin definerer du administrationsknuder for din klynge.
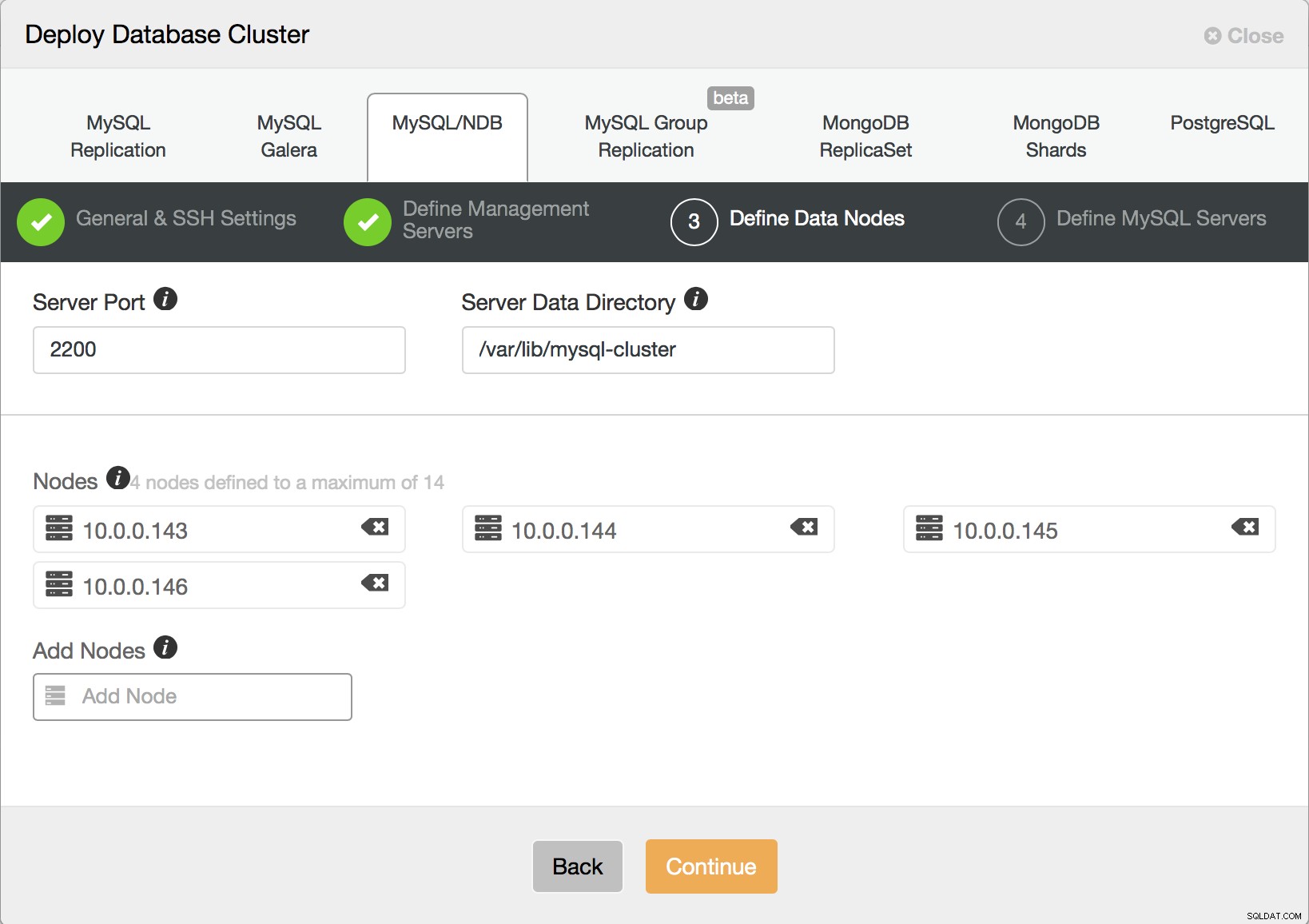
Her skal du bestemme, hvor mange dataknuder du vil have. Som vi tidligere har nævnt, vil hver 2 noder være en del af en nodegruppe, så dette bør være et lige tal.
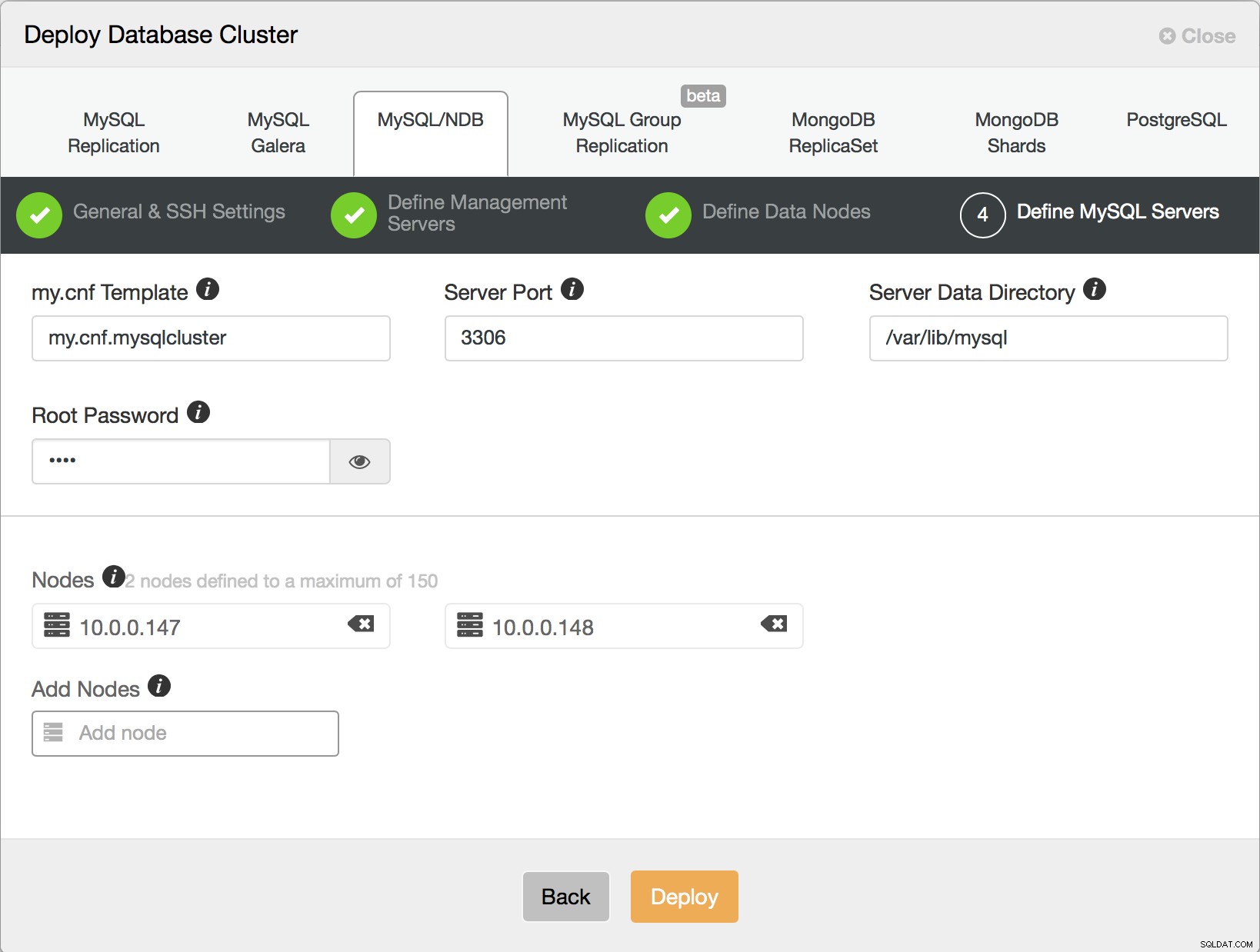
Til sidst skal du beslutte, hvor mange SQL-noder du vil implementere i din klynge. Når du klikker på implementering, vil ClusterControl oprette forbindelse til værterne, installere softwaren og konfigurere alle tjenester. Efter et stykke tid bør du se din klynge installeret.
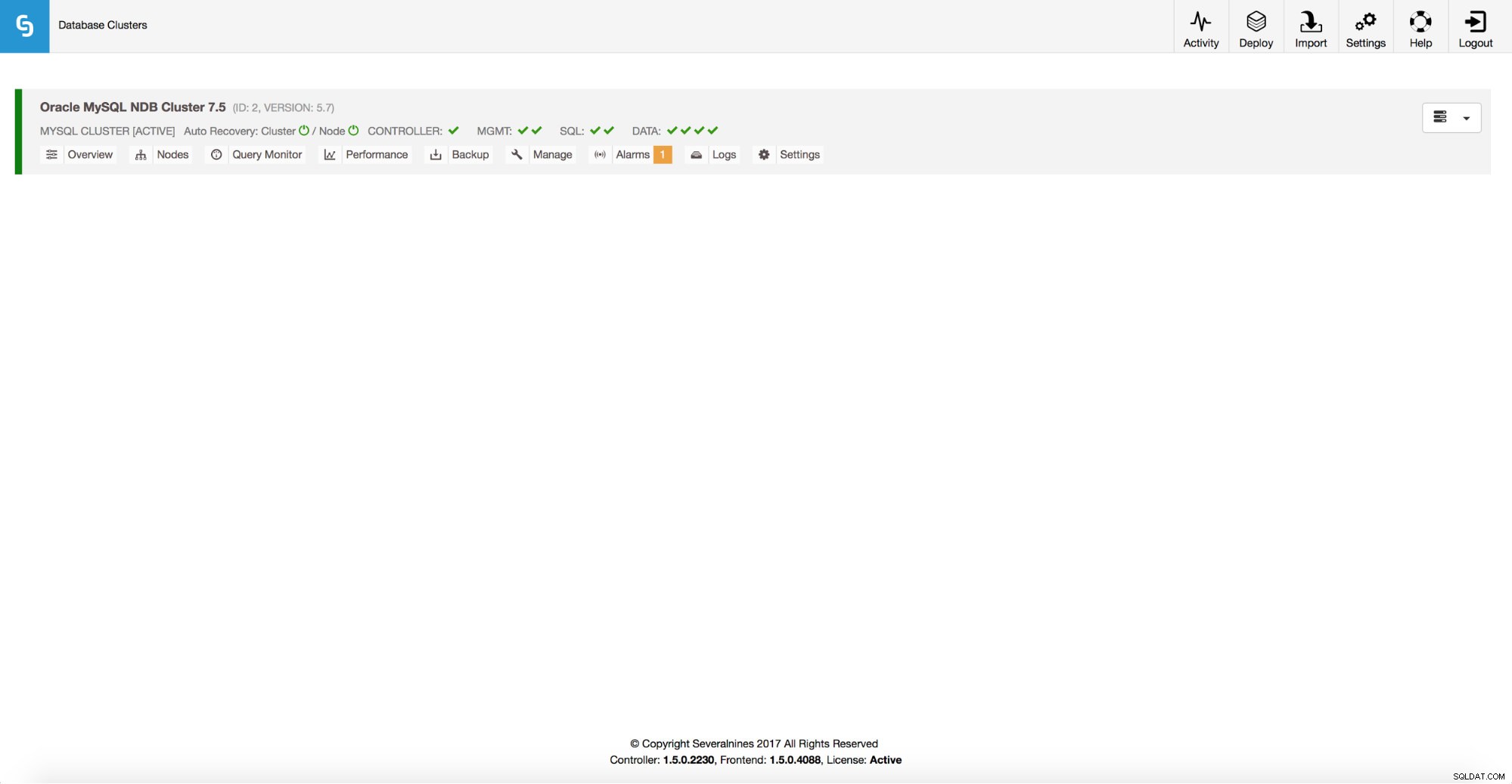
Skalering af MySQL NDB-klynge
For MySQL NDB Cluster understøtter ClusterControl 1.5.0 skalering af SQL-noder. Du kan få adgang til jobbet fra rullemenuen Klyngejob.
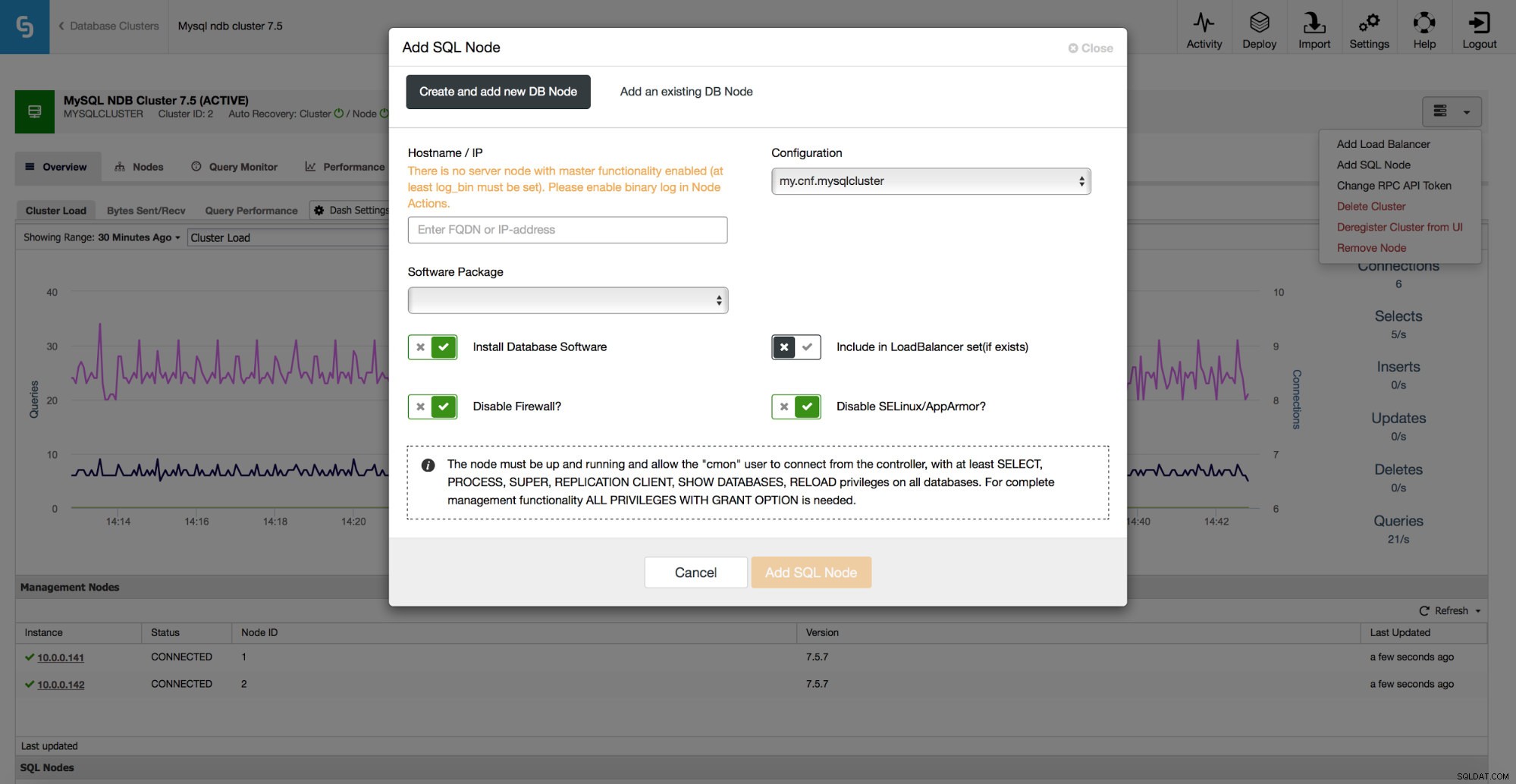
Der kan du udfylde værtsnavnet på den node, du gerne vil tilføje, og det er alt, hvad du behøver - ClusterControl tager sig af resten.
Administration af MySQL NDB Cluster
ClusterControl hjælper dig med at administrere MySQL NDB Cluster. I dette afsnit vil vi gerne gennemgå nogle af de administrationsfunktioner, vi har.
Sikkerhedskopier
Sikkerhedskopier er afgørende for ethvert produktionsmiljø. I tilfælde af katastrofe kan kun en god sikkerhedskopiering minimere datatabet og hjælpe dig med hurtigt at gendanne problemet. Replikering er måske ikke altid en løsning, der virker - DROP TABLE vil droppe tabellen på alle værterne i topologien. Selv en forsinket slave kan kun forsinke det uundgåelige med så meget.
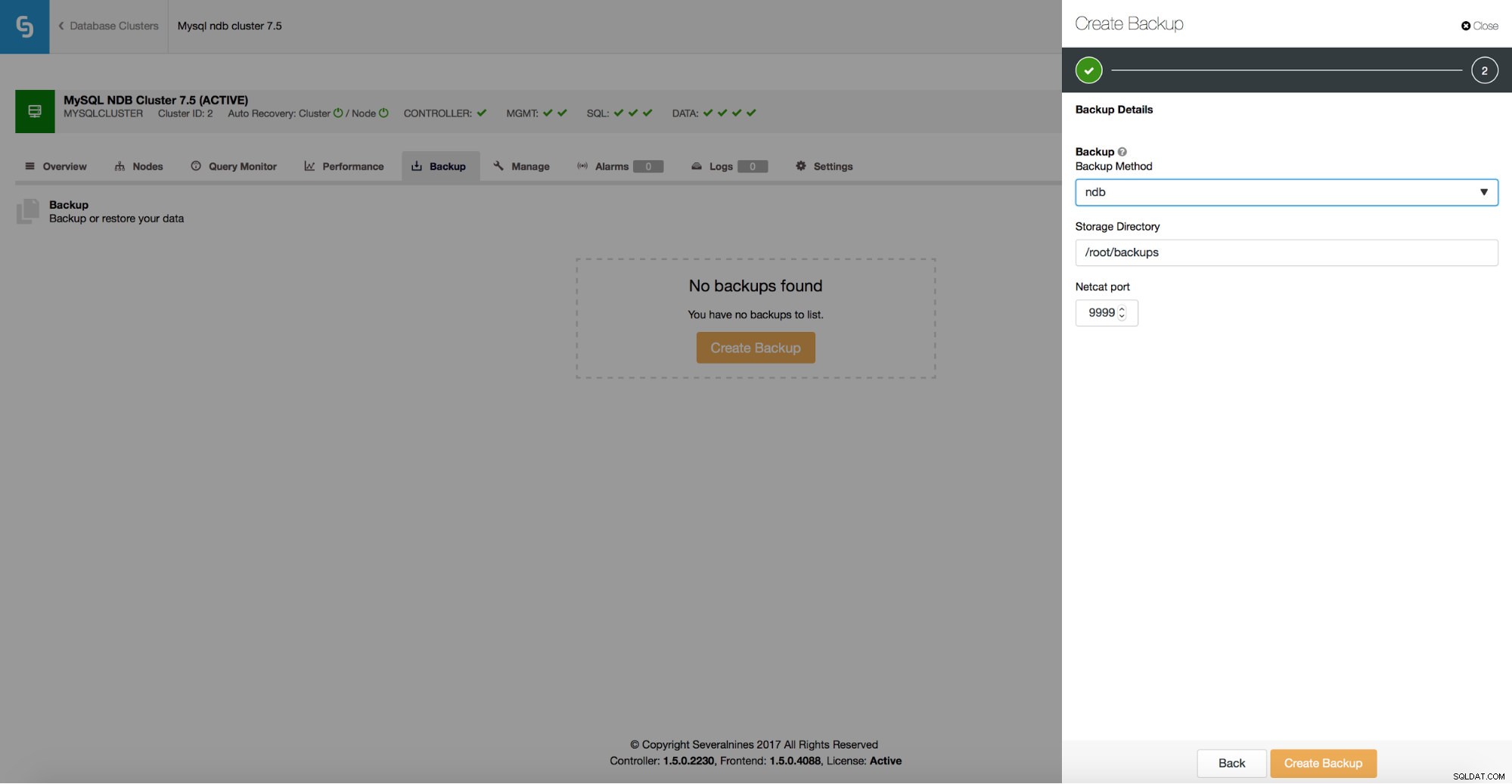
ClusterControl understøtter ndb backup til MySQL NDB Cluster.
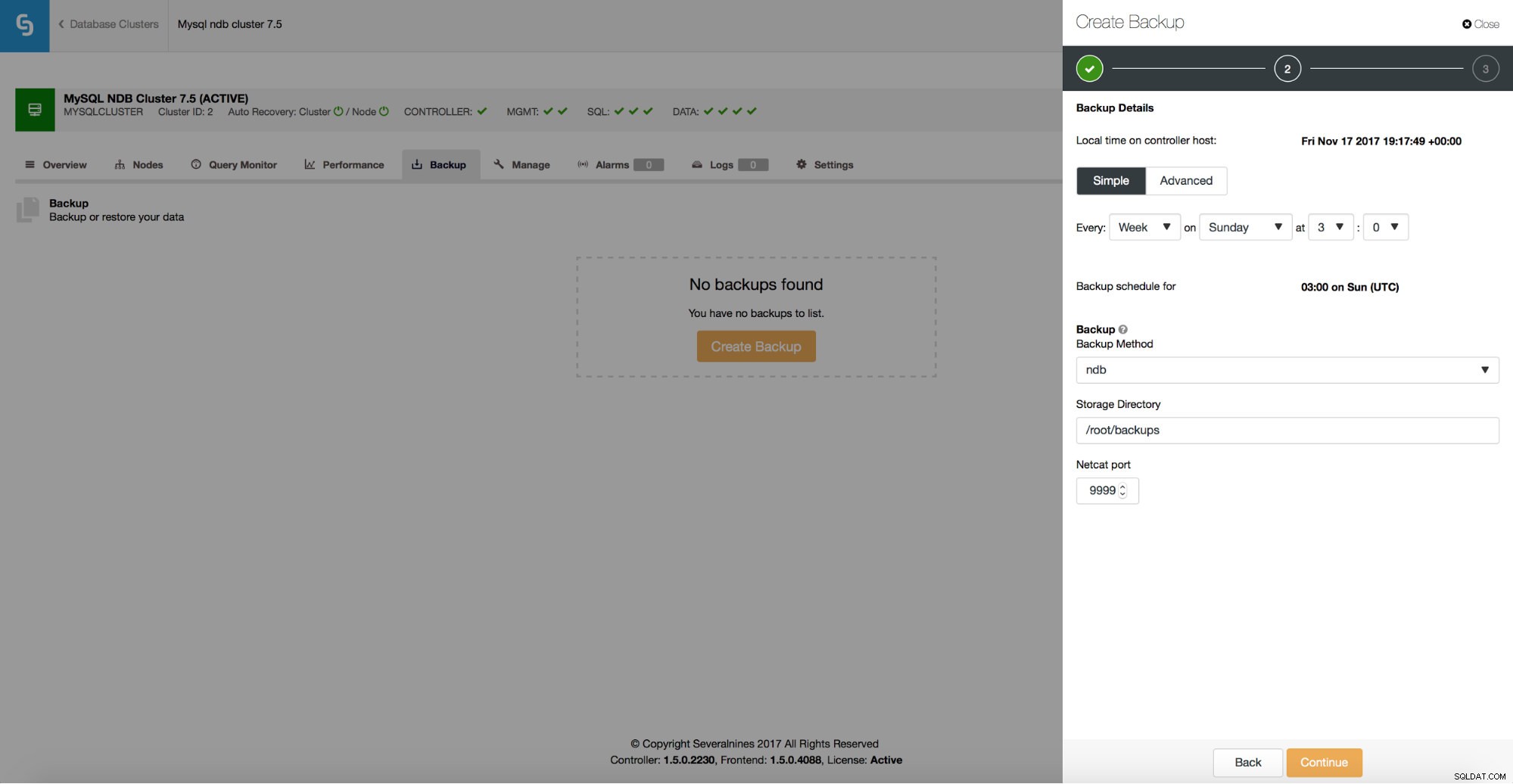
Du kan nemt oprette en backup tidsplan, der skal udføres af ClusterControl.
Proxylag
ClusterControl giver dig mulighed for at implementere en fuld høj tilgængelig stack oven på MySQL NDB Cluster. For proxy-laget understøtter vi implementering af HAProxy og MaxScale.
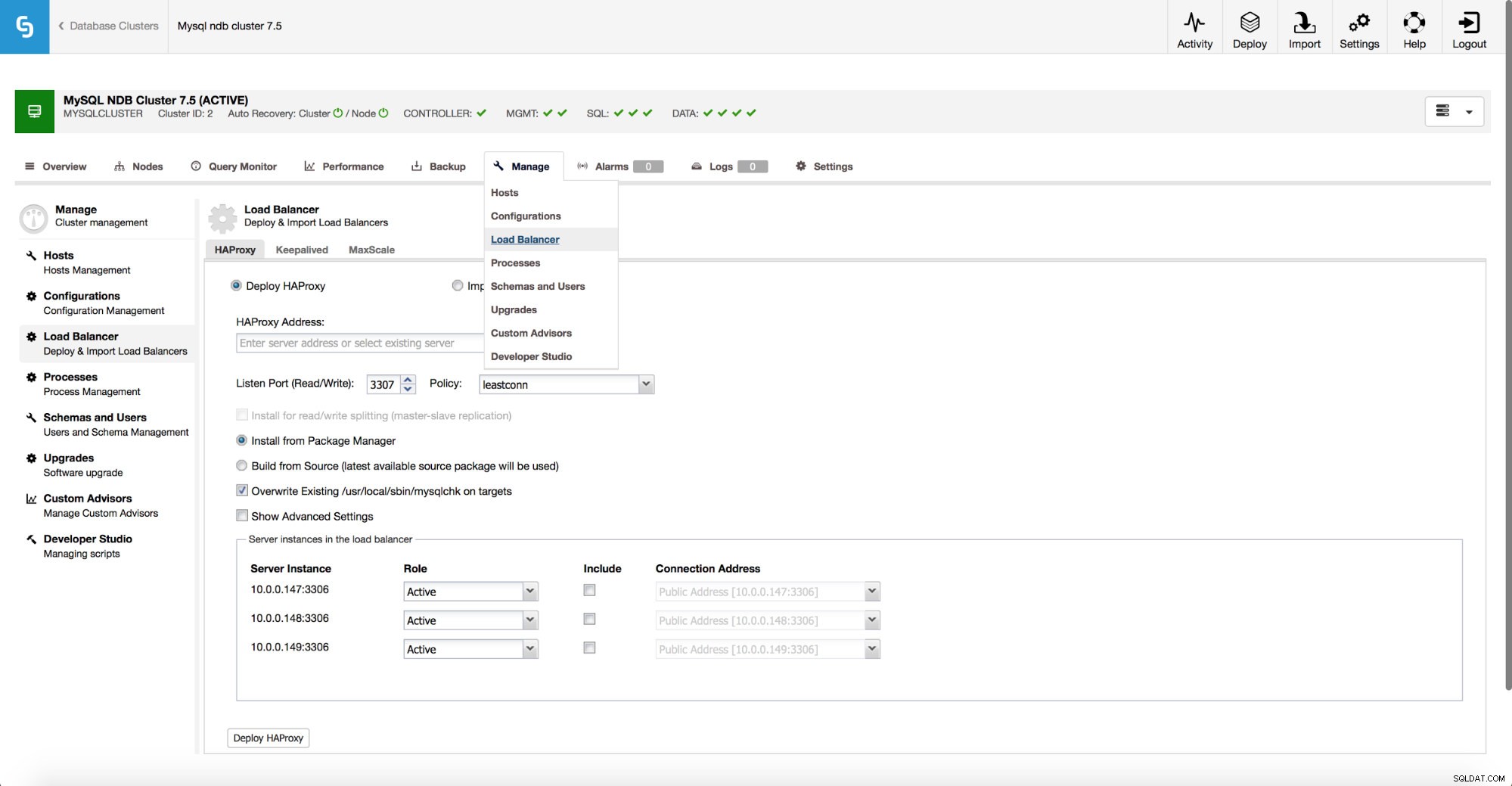
Som vist på skærmbilledet ovenfor ligner implementeringen meget de andre klyngetyper. Du skal beslutte, om du vil bruge en eksisterende HAProxy eller implementere en ny. Så skal du vælge, hvordan du installerer det - ved at bruge pakker fra lagre, der er tilgængelige på noden, eller kompilere det fra kildekoden til den seneste udgivelse.
Hvis du beslutter dig for at bruge HAProxy, vil du have mulighed for at konfigurere høj tilgængelighed ved hjælp af Keepalved og Virtual IP.
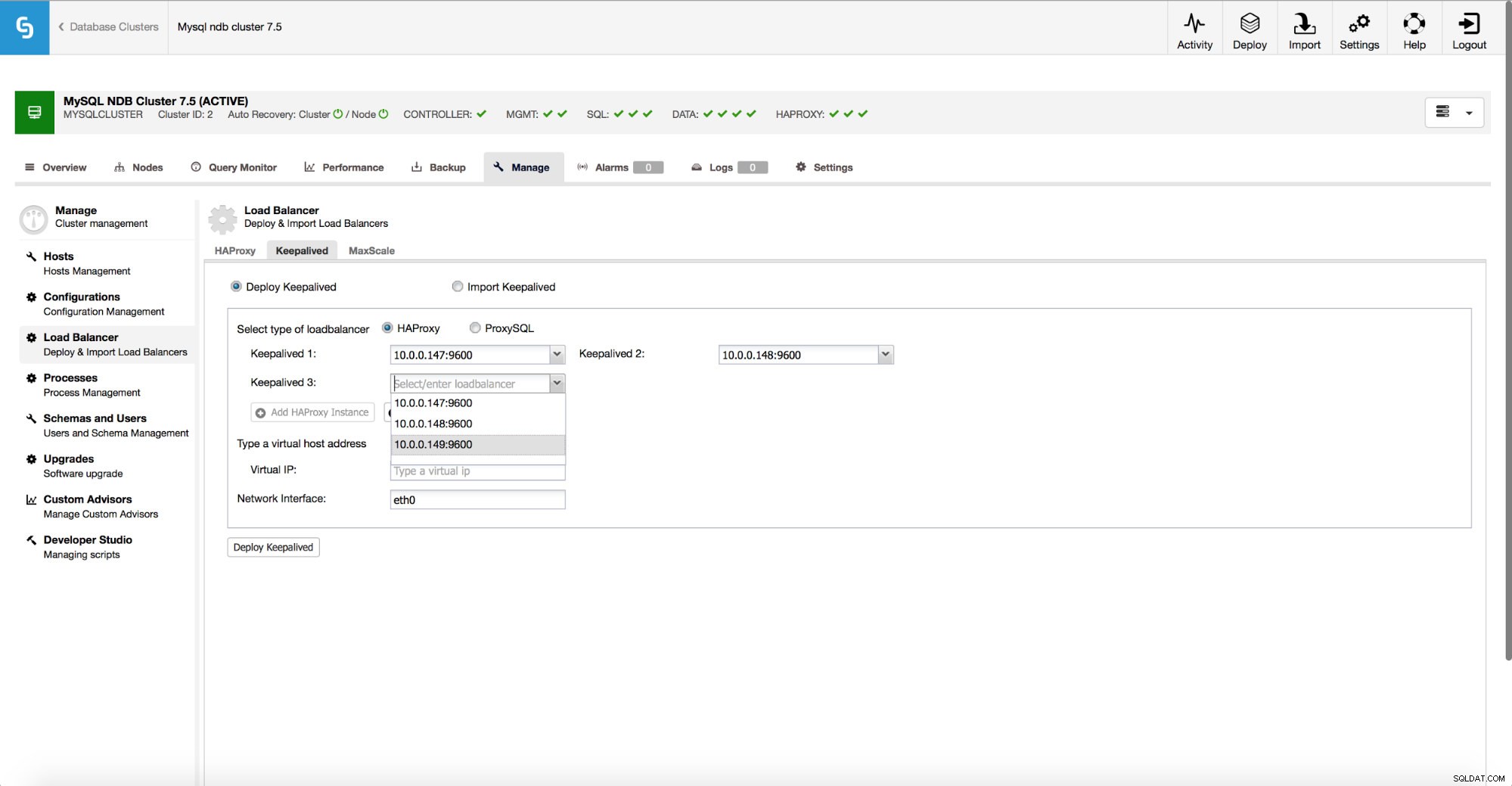
Processen er følgende - du definerer en virtuel IP og den grænseflade, som den skal bringes op på. Derefter kan du implementere det for hver HAProxy, du har installeret. En af Keepalved-processerne vil blive bestemt som en "master", og den vil aktivere VIP på sin node. Din applikation opretter derefter forbindelse til denne særlige IP. Når en aktuel aktiv HAProxy ikke er tilgængelig, vil VIP'en blive flyttet til en anden tilgængelig HAProxy, hvilket genopretter forbindelsen.
Gendannelsesstyring
Mens MySQL NDB Cluster kan tolerere fejl i individuelle noder, er det vigtigt at reagere hurtigt på disse. ClusterControl giver automatisk gendannelse for alle komponenter i klyngen. Uanset hvad der fejler (styringsknude, datanode eller SQL-knude), vil ClusterControl automatisk genstarte dem.
Overvågning af MySQL NDB-klyngen
Ethvert produktionsklar miljø skal overvåges. ClusterControl giver dig en række målinger, du kan overvåge. På siden "Oversigt" viser vi grafer baseret på de vigtigste målinger for din klynge. Du kan også oprette dine egne dashboards, der viser yderligere data, der ville være nyttige i dit miljø.
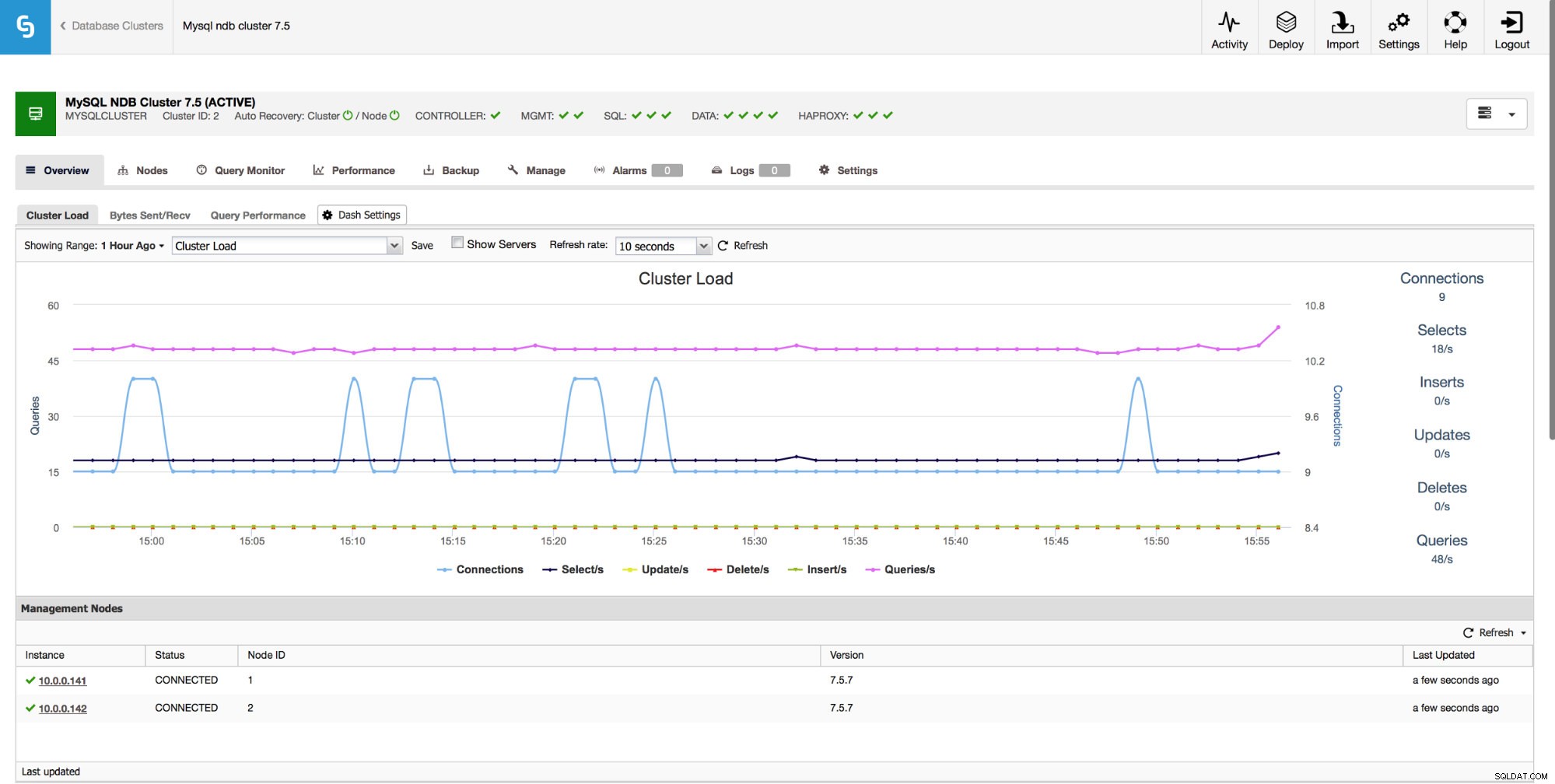
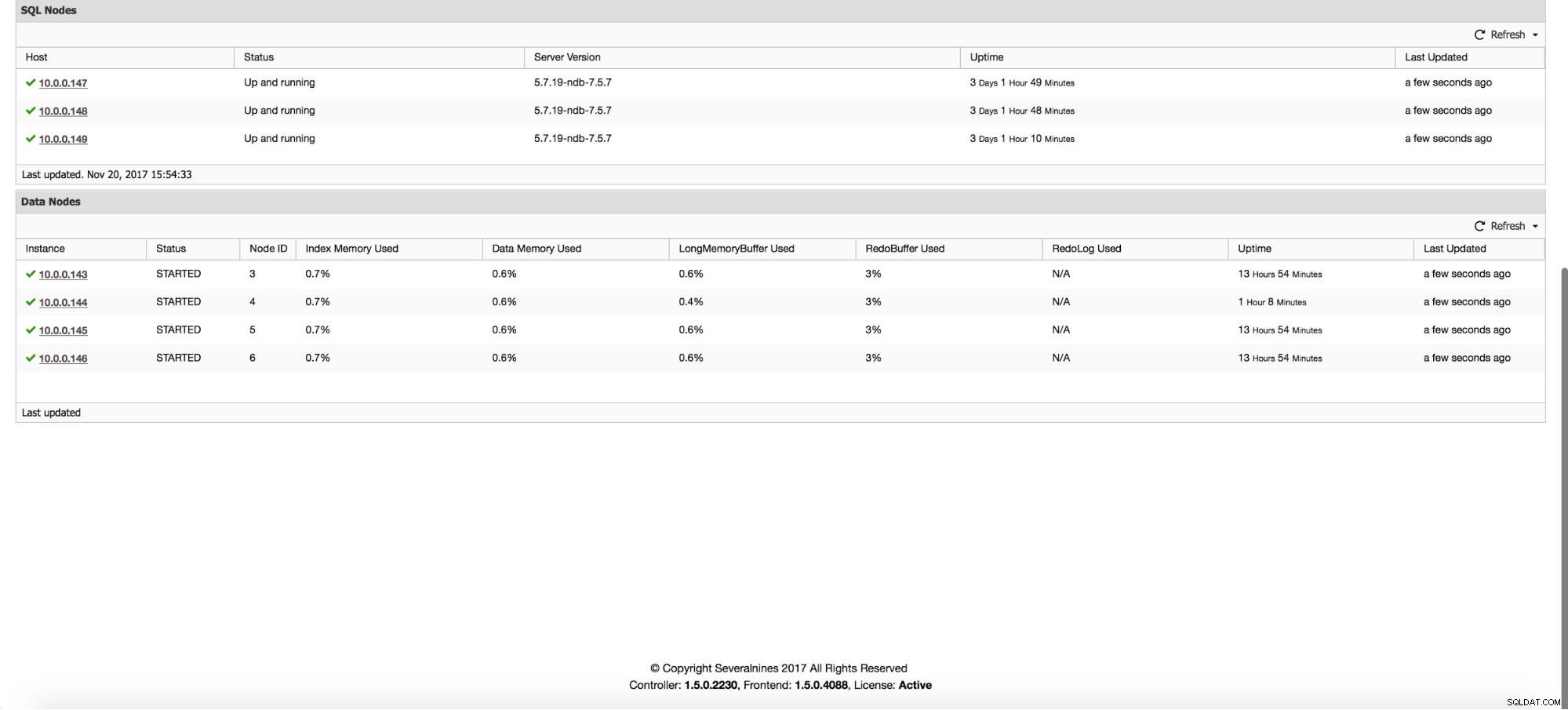
Ud over graferne giver "Oversigt"-siden dig indsigt i klyngens tilstand baseret på nogle MySQL NDB-klynge-metrics som brugt Index Memory, Data Memory og tilstanden af nogle buffere.
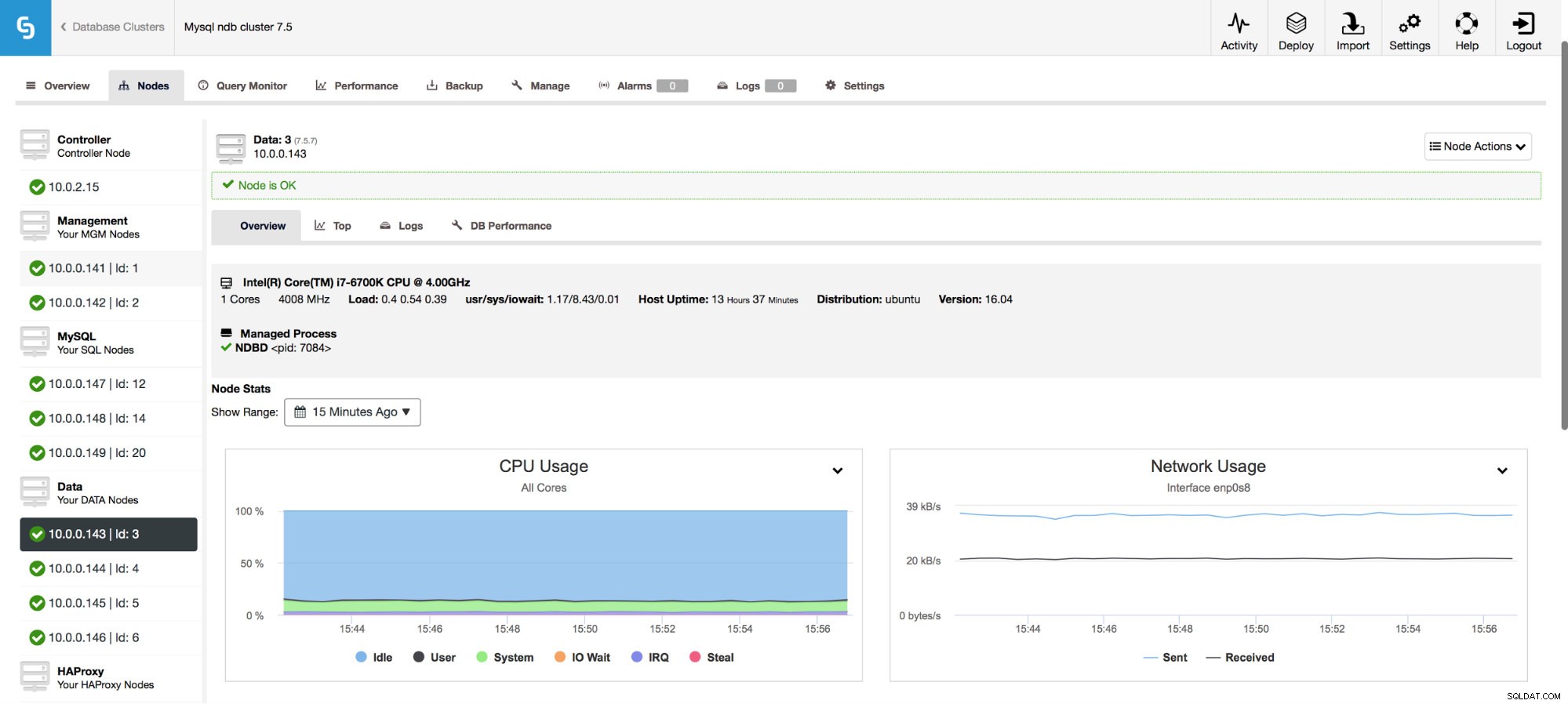
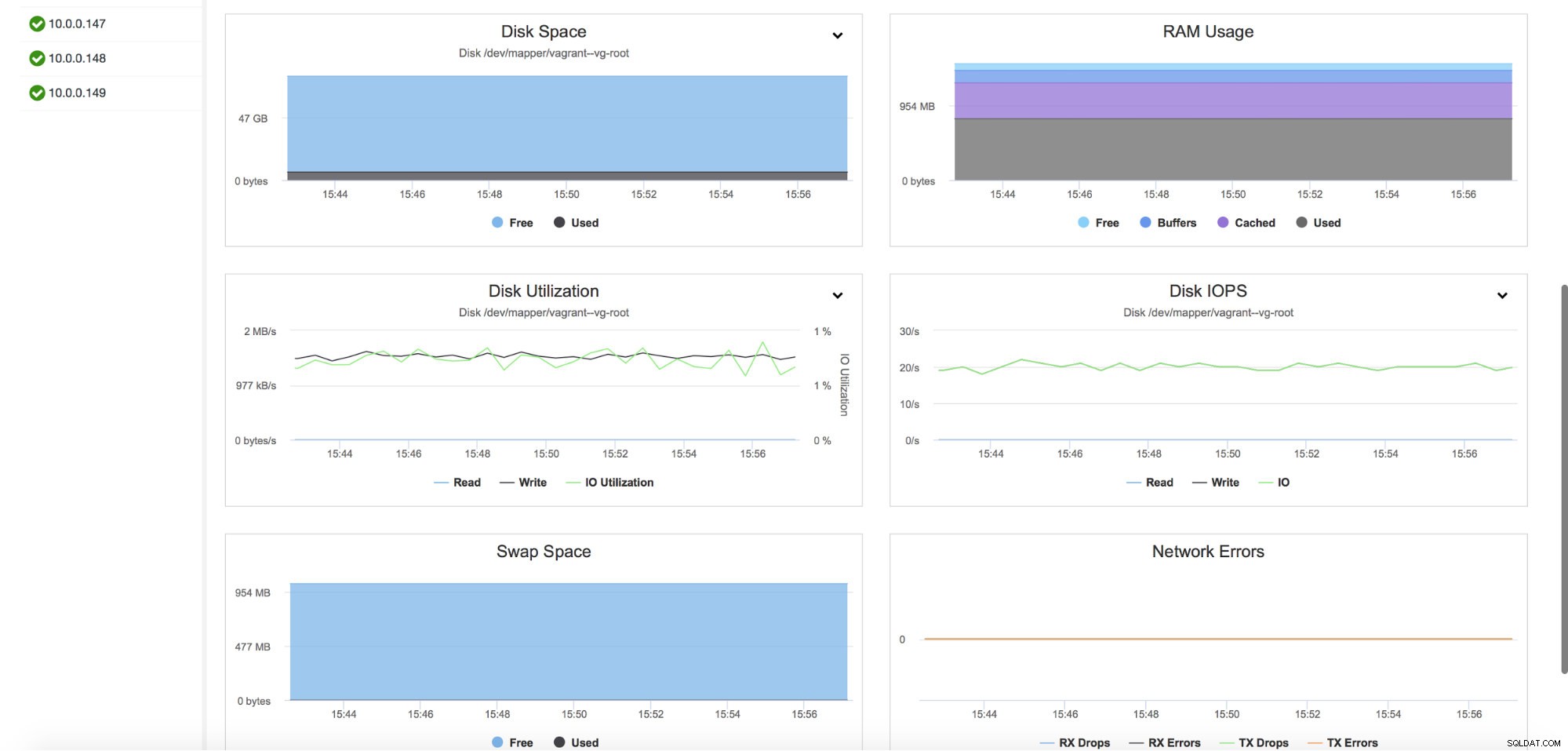
Det giver også overvågning af værtsmålingerne, herunder CPU-udnyttelse, RAM, disk eller netværksstatistik. Disse grafer er også afgørende for at opbygge et overblik over klyngens sundhed.
ClusterControl kan også hjælpe dig med at forbedre ydeevnen af dine databaser ved at give dig adgang til Query Monitor, som indeholder statistik om din trafik.
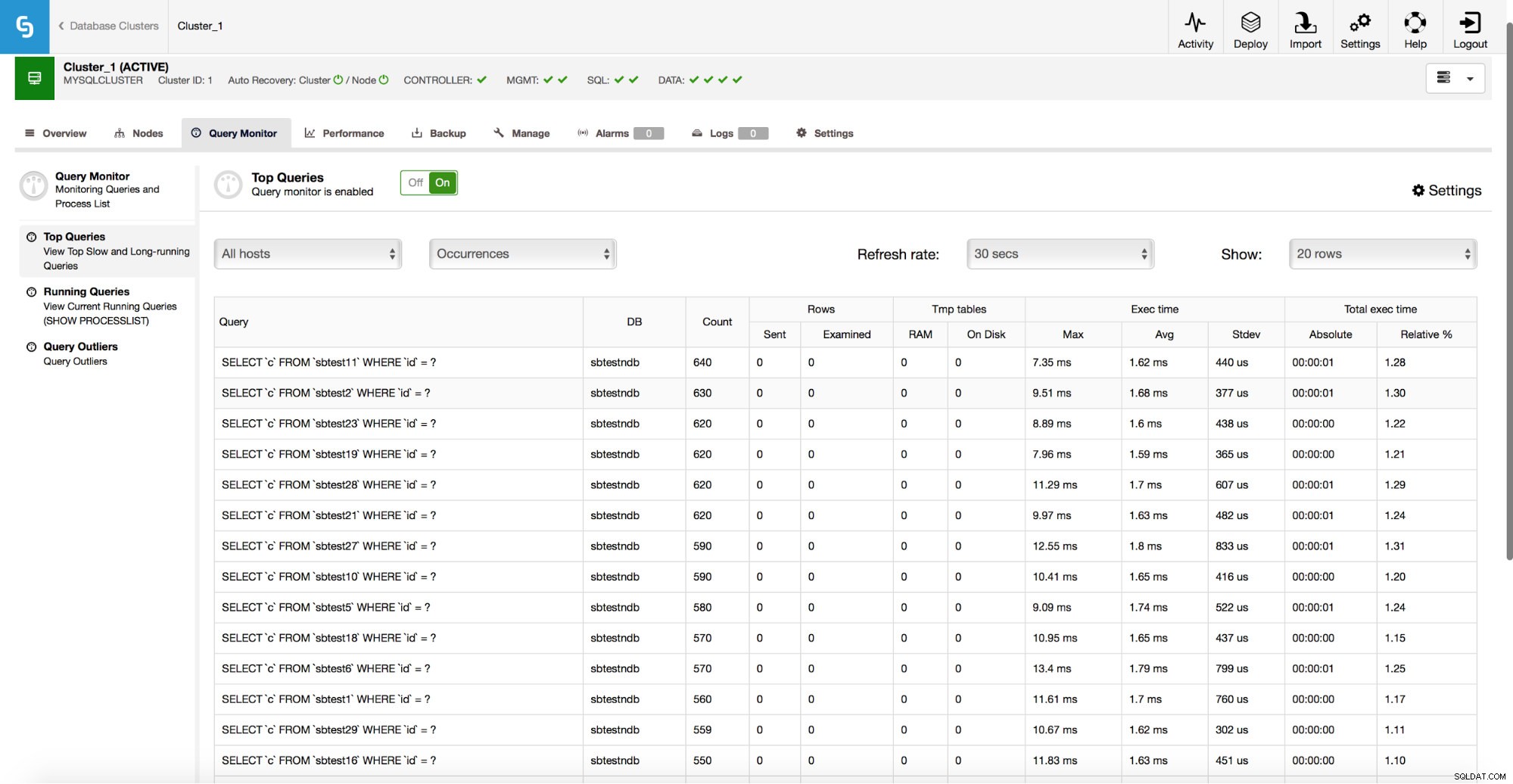
Som det ses på skærmbilledet ovenfor, kan du se, hvilken slags forespørgsler der kører mod din klynge, hvor mange forespørgsler af en given type, hvad er deres eksekveringstider og de samlede eksekveringstider. Dette hjælper med at identificere, hvilke forespørgsler der er langsomme, og hvilke af dem der er ansvarlige for størstedelen af trafikken. Du kan derefter fokusere på de forespørgsler, som kan give dig den største præstationsforbedring.