Bemærk:Dette indlæg blev oprindeligt kun udgivet i vores e-bog, High Performance Techniques for SQL Server, bind 4. Du kan finde ud af om vores e-bøger her.
Jeg bliver jævnligt stillet spørgsmålet:"Hvor skal jeg starte, når det kommer til at prøve at tune en SQL Server-instans?" Mit første svar er at spørge dem om konfigurationen af deres instans. Hvis visse ting ikke er konfigureret korrekt, kan det være spildte kræfter at begynde at se på langvarige eller dyre forespørgsler med det samme.
Jeg har blogget om almindelige ting, administratorer savner, hvor jeg deler mange af de indstillinger, som administratorer bør ændre fra en standardinstallation af SQL Server. For præstationsrelaterede emner fortæller jeg dem, at de skal kontrollere følgende:
- Hukommelsesindstillinger
- Opdatering af statistik
- Indeksvedligeholdelse
- MAXDOP og omkostningstærskel for parallelitet
- tempdb bedste praksis
- Optimer til ad hoc-arbejdsbelastninger
Når jeg kommer forbi konfigurationselementerne, spørger jeg, om de har set på fil- og ventestatistikker samt højprisforespørgsler. Det meste af tiden er svaret "nej" - med en forklaring om, at de ikke er sikre på, hvordan de finder denne information.
Typisk er den almindelige kompatible, når nogen siger, at de skal tune en SQL Server, at den kører langsomt. Hvad betyder langsom? Er det en bestemt rapport, en specifik applikation eller alt muligt? Begyndte det lige at ske, eller er det blevet værre med tiden? Jeg starter med at stille de sædvanlige triage-spørgsmål om, hvad hukommelsen, CPU'en og diskudnyttelsen er sammenlignet med, når tingene er normale, begyndte problemet lige at ske, og hvad ændrede sig for nylig. Medmindre klienten fanger en baseline, har de ikke metrics at sammenligne med for at vide, om den aktuelle statistik er unormal.
Næsten hver eneste SQL Server, som jeg arbejder på, hoster mere end én brugerdatabase. Når en klient rapporterer, at SQL Serveren kører langsomt, er de oftest bekymrede over en specifik applikation, der forårsager problemer for deres kunder. Et knæfald er straks at fokusere på den pågældende database, men ofte kan en anden proces tære på værdifulde ressourcer, og applikationens database bliver påvirket. For eksempel, hvis du har en stor rapporteringsdatabase, og nogen startede en massiv rapport, der mætter disken, spikes CPU og tømmer planens cache, kan du vædde på, at de andre brugerdatabaser ville blive langsommere, mens den rapport bliver genereret.
Jeg kan altid godt lide at starte med at se på filstatistikken. For SQL Server 2005 og nyere kan du forespørge sys.dm_io_virtual_file_stats DMV for at få I/O-statistik for hver data og logfil. Denne DMV erstattede funktionen fn_virtualfilestats. For at indfange filstatistikken kan jeg godt lide at bruge et script, som Paul Randal satte sammen:at fange IO-forsinkelser i en periode. Dette script vil fange en baseline og, 30 minutter senere (medmindre du ændrer varigheden i WAITFOR DELAY sektionen), fange statistikken og beregne deltaerne mellem dem. Pauls manuskript gør også en smule matematik for at bestemme læse- og skriveforsinkelserne, hvilket gør det meget nemmere for os at læse og forstå.
På min bærbare computer gendannede jeg en kopi af AdventureWorks2014-databasen på et USB-drev, så jeg ville have langsommere diskhastigheder; Jeg startede derefter en proces for at generere en belastning mod den. Du kan se resultaterne nedenfor, hvor min skriveforsinkelse for min datafil er 240ms og skriveforsinkelse for min logfil er 46ms. Så høje ventetider er besværlige.
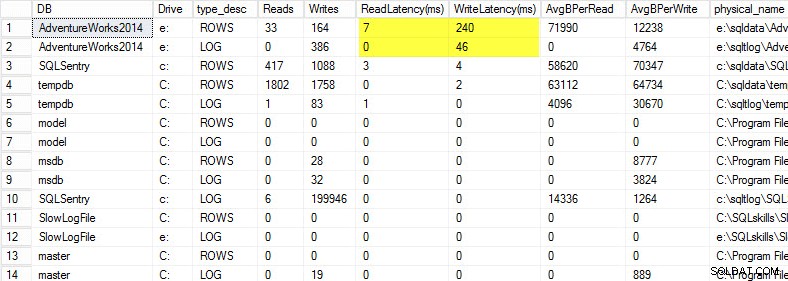
Alt over 20 ms bør betragtes som dårligt, som jeg delte i et tidligere indlæg:overvågning af læse-/skriveforsinkelse. Min læseforsinkelse er anstændig, men AdventureWorks2014-databasen lider under langsomme skrivninger. I dette tilfælde ville jeg undersøge, hvad der genererer skrivningerne, samt undersøge mit I/O-undersystems ydeevne. Hvis dette havde været for høje læseforsinkelser, ville jeg begynde at undersøge forespørgselsydeevne (hvorfor læser den så mange, for eksempel fra manglende indekser), såvel som den overordnede I/O-undersystemydelse.
Det er vigtigt at kende den overordnede ydeevne af dit I/O-undersystem, og den bedste måde at vide, hvad det er i stand til, er ved at benchmarke det. Glenn Berry taler om dette i sin artikel, der analyserer I/O-ydeevne for SQL Server. Glenn forklarer latency, IOPS og throughput og viser CrystalDiskMark frem, som er et gratis værktøj, som du kan bruge til at baseline din storage.
Efter at have fundet ud af, hvordan filstatistikken fungerer, kan jeg godt lide at se på ventestatistikker ved at bruge DMV sys.dm_os_wait_stats, som returnerer information om alle de ventetider, der opstod. Til dette vender jeg mig til et andet script, som Paul Randal giver i sin fangende ventestatistik for en periode på blogindlæg. Pauls manuskript laver lidt matematik for os igen, men endnu vigtigere, det udelukker mange af de godartede ventetider, som vi typisk er ligeglade med. Dette script har også en WAITFOR DELAY og er indstillet til 30 minutter. Det kan være lidt mere vanskeligt at læse ventestatistikker:Du kan have ventetider, der ser ud til at være høje baseret på procent, men den gennemsnitlige ventetid er så lav, at det ikke er noget at bekymre sig om.
Jeg startede den samme indlæsningsproces og fangede mine ventestatistikker, som jeg har vist nedenfor. For forklaringer på mange af disse ventetyper kan du læse endnu et af Pauls blogindlæg, ventestatistikker eller fortælle mig, hvor det gør ondt, plus nogle af hans indlæg på denne blog.
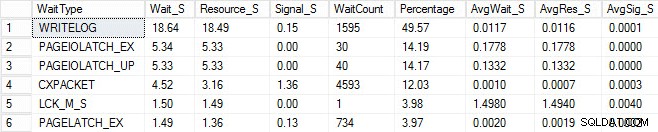
I dette konstruerede output kunne PAGEIOLATCH-venterne indikere en flaskehals med mit I/O-undersystem, men det kan også være et hukommelsesproblem, tabelscanninger i stedet for søgninger eller en lang række andre problemer. I mit tilfælde ved vi, at det er et diskproblem, da jeg gemmer databasen på en USB-stick. LCK_M_S ventetiden er meget høj, men der er kun én forekomst af ventetiden. Min WRITELOG er også højere, end jeg gerne vil se, men det er forståeligt at kende latensproblemerne med USB-stikket. Dette viser også CXPACKET-venter, og det ville være let at få et knæfald og tro, at du har et parallelisme/MAXDOP-problem, men AvgWait_S-tælleren er meget lav. Vær forsigtig, når du bruger venter på fejlfinding. Lad det være en guide til at fortælle dig ting, der ikke er problemet, samt give dig en retning for, hvor du skal gå og lede efter problemer. Korrekt fejlfinding er at korrelere adfærd fra flere områder for at indsnævre problemet.
Efter at have kigget på filen og ventestatistikken begynder jeg at grave i de høje omkostninger forespørgsler baseret på de problemer, jeg fandt. Til dette vender jeg mig til Glenn Berry's Diagnostic Information Queries. Disse sæt forespørgsler er de go-to-scripts, som mange konsulenter bruger. Glenn og fællesskabet leverer konstant opdateringer for at gøre dem så informative og robuste som muligt. En af mine yndlingsforespørgsler er de mest cachelagrede forespørgsler efter eksekveringsantal. Jeg elsker at finde forespørgsler eller lagrede procedurer, der har høj execution_count kombineret med høj total_logical_reads. Hvis disse forespørgsler har muligheder for tuning, kan du hurtigt gøre en stor forskel for serveren. Også inkluderet i scripterne er top cachelagrede SP'er efter samlede logiske læsninger og top cachelagrede SP'er efter samlede fysiske læsninger. Begge disse er gode til at lede efter høje læsninger med høje eksekveringstal, så du kan reducere antallet af I/O'er.
Ud over Glenns scripts kan jeg godt lide at bruge Adam Machanics sp_whoisactive til at se, hvad der kører i øjeblikket.
Der er meget mere til justering af ydeevne end blot at se på fil- og ventestatistikker og høje omkostninger-forespørgsler, men det er her, jeg kan lide at starte. Det er en måde at hurtigt triage et miljø for at begynde at bestemme, hvad der forårsager problemet. Der er ingen helt idiotsikker måde at tune på:hvad enhver produktions-DBA har brug for er en tjekliste over ting, der skal køres igennem for at eliminere og en rigtig god samling af scripts, der skal køres igennem for at analysere systemets sundhed. At have en baseline er nøglen til hurtigt at udelukke normal vs. unormal adfærd. Min gode ven Erin Stellato har et helt kursus om Pluralsight kaldet SQL Server:Benchmarking og Baselining, hvis du har brug for hjælp til at opsætte og fange din baseline.
Endnu bedre, få et state-of-the-art værktøj som SQL Sentry Performance Advisor, der ikke kun vil indsamle og gemme historisk information til profilering og trending, og giver nem adgang til alle de detaljer nævnt ovenfor og mere, men det giver også evnen til at sammenligne aktivitet med indbyggede eller brugerdefinerede basislinjer, effektivt vedligeholde indekser uden at løfte en finger og advare eller automatisere svar baseret på en meget robust tilpasset arkitektur. Følgende skærmbillede viser den historiske visning af Performance Advisor-dashboardet med diskventer i orange, database I/O nederst til højre og basislinjer, der sammenligner den nuværende og forrige periode på hver graf (klik for at forstørre):
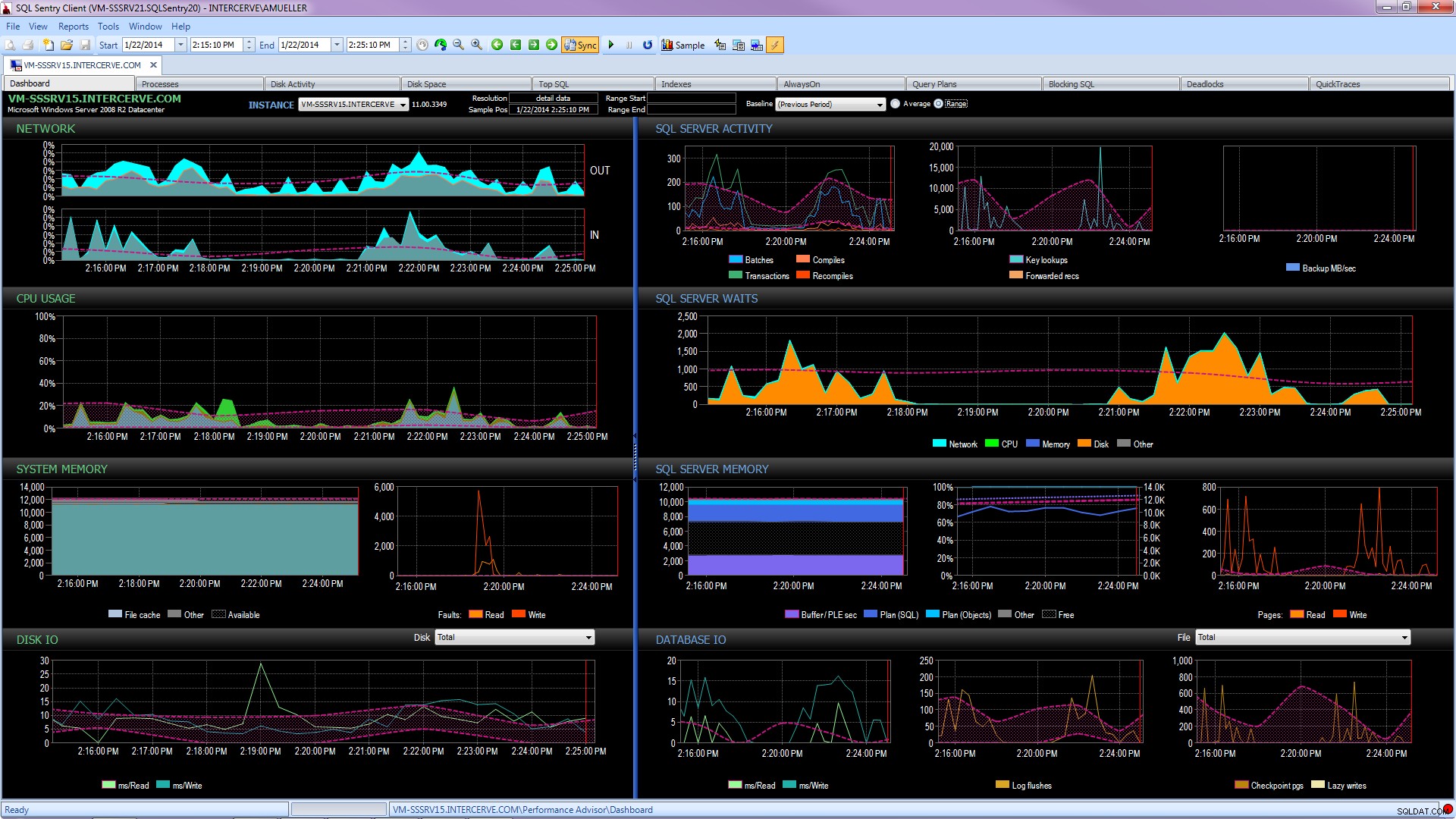
Kvalitetsovervågningsværktøjer er ikke gratis, men de giver et væld af funktionalitet og support, der giver dig mulighed for at fokusere på ydeevneproblemerne på dine servere i stedet for at fokusere på forespørgsler, jobs og advarsler, der kan giver dig mulighed for at fokusere på dine præstationsproblemer - men kun når du får dem rigtigt. Der er ofte stor værdi i ikke at genopfinde hjulet.