
Dette er heller ikke god fragmentering
Sidste måned skrev jeg om uventet klynget indeksfragmentering, så denne gang vil jeg gerne diskutere nogle af de ting, du kan gøre for at undgå, at der sker indeksfragmentering. Jeg går ud fra, at du har læst det forrige indlæg og er bekendt med de termer, jeg definerede der, og i resten af denne artikel, når jeg siger 'fragmentering', henviser jeg til både den logiske fragmentering og problemer med lav sidetæthed.
Vælg en god klyngenøgle
Den dyreste datastruktur at operere på for at fjerne fragmentering er det klyngede indeks for en tabel, fordi det er den største struktur, da det indeholder alle tabeldataene. Fra et fragmenteringsperspektiv giver det mening at vælge en klyngenøgle, der matcher tabelindsættelsesmønsteret, så der er ingen mulighed for, at en indsættelse sker på en side, hvor der ikke er plads, og derfor forårsager en sideopdeling og introducerer fragmentering.
Hvad der udgør den bedste klyngenøgle til en given tabel er et spørgsmål om meget debat, men generelt vil du ikke gå galt, hvis din klyngenøgle har følgende simple egenskaber:
- Smal (dvs. så få kolonner som muligt)
- Statisk (dvs. du opdaterer det aldrig)
- Unik
- Stadig stigende
Det er den stadigt stigende egenskab, som er den vigtigste for at forhindre fragmentering, da den undgår tilfældige indsættelser, der kan forårsage sideopdelinger på allerede fulde sider. Eksempler på et sådant nøglevalg er int-identitet og bigint-identitetskolonner eller endda en sekventiel GUID fra NEWSEQUENTIALID()-funktionen.
Med disse typer nøgler vil nye rækker have en nøgleværdi, der er garanteret højere end alle andre i tabellen, og derfor vil den nye rækkes indsættelsespunkt være i slutningen af siden længst til højre i den klyngede indeksstruktur. Til sidst vil de nye rækker fylde denne side op, og endnu en side vil blive tilføjet til højre i indekset, men uden at der forekommer skadelig sideopdeling.
Hvis du nu har en klynget indeksnøgle, der ikke er konstant stigende, kan det være en meget kompleks og ubehagelig procedure at ændre den til en stadigt stigende, så bare rolig – i stedet kan du bruge en udfyldningsfaktor, som jeg diskuterer. nedenfor.
For en meget dybere indsigt i valget af en klyngenøgle og alle konsekvenserne af den, tjek i øvrigt Kimberlys Clustering Key-blogkategori (læs nedefra og op).
Opdater ikke indeksnøglekolonner
Når en nøglekolonne opdateres, er det ikke bare en simpel opdatering på stedet, selvom mange steder online og i bøger siger, at det er det (de tager fejl). En nøglekolonne kan ikke opdateres på plads, da den nye nøgleværdi så vil betyde, at rækken er i den forkerte nøglerækkefølge for indekset. I stedet oversættes en nøglekolonneopdatering til en sletning af hele rækken plus en hel rækkeindsættelse med den nye nøgleværdi. Hvis siden, hvor den nye række vil blive indsat, ikke har nok plads på den, vil en sideopdeling ske, hvilket forårsager fragmentering.
Det burde være let at undgå opdateringer af nøglekolonnen for det klyngede indeks, da det er et dårligt design, der kræver opdatering af klyngenøglen i en tabelrække. For ikke-klyngede indekser er det dog uundgåeligt, hvis opdateringer til tabellen tilfældigvis involverer kolonner, hvor der er et ikke-klynget indeks. I disse tilfælde skal du bruge en fyldfaktor.
Opdater ikke kolonner med variabel længde
Det her er lettere sagt end gjort. Hvis du skal bruge kolonner med variabel længde, og det er muligt, at de bliver opdateret, er det muligt, at de vokser og derfor kræver mere plads til den opdaterede række, hvilket fører til en sideopdeling, hvis siden allerede er fuld.
Der er et par ting, du kan gøre for at undgå fragmentering i dette tilfælde:
- Brug en fyldfaktor
- Brug en kolonne med fast længde i stedet, hvis overhead for alle de ekstra udfyldningsbytes er et mindre problem end fragmentering eller brug af en udfyldningsfaktor
- Brug en pladsholderværdi til at 'reservere' plads til kolonnen – dette er et trick, du kan bruge, hvis applikationen indtaster en ny række og derefter kommer tilbage for at udfylde nogle af detaljerne, hvilket forårsager kolonneudvidelse med variabel længde li>
- Udfør en sletning plus indsættelse i stedet for en opdatering
Brug en udfyldningsfaktor
Som du kan se, er mange af måderne til at undgå fragmentering ubehagelige, da de involverer applikations- eller skemaændringer, og derfor er brug af en udfyldningsfaktor en nem måde at afbøde fragmentering på.
En indeksfyldningsfaktor er en indstilling for indekset, der angiver, hvor meget tom plads der skal efterlades på hver side på bladniveau, når indekset oprettes, genopbygges eller omorganiseres. Ideen er, at der er nok ledig plads på siden til at tillade tilfældige indsættelser eller rækkevækst (fra et versioneringstag, der tilføjes eller opdaterede kolonner med variabel længde), uden at siden fyldes op og kræver en sideopdeling. Men til sidst vil siden blive fyldt op, og derfor skal den ledige plads med jævne mellemrum genopfriskes ved at genopbygge eller omorganisere indekset (generelt kaldet at udføre indeksvedligeholdelse). Tricket er at finde den rigtige fyldfaktor at bruge sammen med den rigtige periodicitet af indeksvedligeholdelse.
Du kan læse mere om indstilling af fyldfaktor i MSDN her. Gå ikke i fælden med at indstille udfyldningsfaktoren for hele forekomsten (ved at bruge sp_configure), da det betyder, at alle indekser vil blive genopbygget eller reorganiseret ved hjælp af denne udfyldningsfaktorværdi, selv de indekser, der ikke har nogen fragmenteringsproblemer. Du ønsker ikke, at dine store klyngede indekser, med pæne, stadigt stigende taster, alle skal have 30 % af deres plads på bladniveau spildt ved at forberede tilfældige indsættelser, som aldrig vil ske. Det er meget bedre at finde ud af, hvilke indekser der faktisk er påvirket af fragmentering og kun indstille en udfyldningsfaktor for dem.
Der er ikke noget rigtigt svar eller magisk formel, jeg kan give dig til dette. Den generelt accepterede praksis er at sætte en fyldningsfaktor på 70 (hvilket betyder, at der skal være 30 % ledig plads) på plads for de indekser, hvor fragmentering er et problem, overvåge, hvor hurtigt fragmentering sker, og derefter ændre enten fyldfaktoren eller indeksvedligeholdelsesfrekvensen (eller begge dele).
Ja, det betyder, at du bevidst spilder plads i indekserne for at undgå fragmentering, men det er en god afvejning at tage i betragtning, hvor dyre sideopdelinger er, og hvor skadelig fragmentering kan være for ydeevnen. Og ja, på trods af hvad nogle måske siger, er dette stadig vigtigt, selvom du bruger SSD'er.
Oversigt
Der er nogle enkle ting, du kan gøre for at undgå, at der sker fragmentering, men så snart du kommer ind i ikke-klyngede indekser, eller bruger snapshot-isolering eller læsbare sekundære, rejser fragmentering sit grimme hoved, og du skal forsøge at forhindre det.
Lad være med at gå i knæ og tro, at du skal sætte en fyldfaktor på 70 på alle dine forekomster – du skal vælge og indstille dem med omhu, som jeg beskrev ovenfor.
Og glem ikke SQL Sentry Fragmentation Manager, som du kan bruge (som en tilføjelse til Performance Advisor) til at hjælpe med at finde ud af, hvor fragmenteringsproblemer er, og derefter løse dem. For eksempel, på fanen Indekser, kan du nemt sortere dine indekser efter højeste fragmentering først (og, hvis du vil, anvende et filter på rækkeoptællingskolonnen for at ignorere dine mindre tabeller):
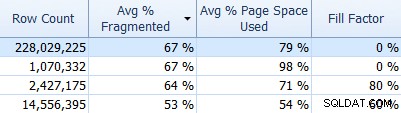
Og se så, om disse indekser bruger standardfyldningsfaktoren (0%), eller måske en ikke-standardfyldningsfaktor, som måske ikke passer godt til dine data og DML-mønstre. Jeg vil lade dig gætte, hvilke i ovenstående skærmbillede, jeg ville være mest interesseret i at undersøge. Implementering af mere passende indeksfyldningsfaktorer er den enkleste måde at løse eventuelle problemer, du opdager.