Jeg har tidligere blogget om, hvorfor jeg ikke elsker sp_updatestats. Jeg har for nylig fundet en anden grund til, at det ikke er min ven. TL;DR:Den opdaterer ikke statistik over indekserede visninger. Nu påstår dokumentationen ikke, at den gør det, så der er ingen fejl her. MSDN-dokumentationen siger tydeligt:
Kører UPDATE STATISTICS mod alle brugerdefinerede og interne tabeller i den aktuelle database.Men ... hvor mange af jer tænkte på jeres indekserede synspunkter og spekulerede på, om de blev opdateret? Det indrømmer jeg, at jeg ikke gjorde. Jeg glemmer alt om indekserede visninger, hvilket er uheldigt, fordi de kan være virkelig kraftfulde, når de bruges korrekt. De kan også være et mareridt at optrevle, når du fejlfinder, men jeg vil ikke argumentere for deres brug i dag. Jeg vil bare have dig til at være opmærksom på, at de ikke bliver opdateret af sp_updatestats, og se hvilke muligheder du har.
Opsætning
Siden World Series lige sluttede, vil vi bruge baseballdatabasen til vores test. Du kan downloade det fra siden SQLskills Resources. Når den er gendannet, opretter vi en kopi af tabellen dbo.Players, kaldet dbo.PlayerInfo, indlæser et par tusinde rækker i den og opretter derefter en indekseret visning, der forbinder vores nye tabel med PitchingPost-tabellen:
BRUG [BaseballData];GO OPRET TABEL [dbo].[PlayerInfo]( [lahmanID] [int] NOT NULL, [playerID] [varchar](10) NULL DEFAULT (NULL), [managerID] [varchar]( 10) NULL DEFAULT (NULL), [hofID] [varchar](10) NULL DEFAULT (NULL), [fødselsår] [int] NULL DEFAULT (NULL), [birthMonth] [int] NULL DEFAULT (NULL), [fødselsdag] [int] NULL DEFAULT (NULL), [birthCountry] [varchar](50) NULL DEFAULT (NULL), [birthState] [varchar](2) NULL DEFAULT (NULL), [birthCity] [varchar](50) NULL DEFAULT (NULL), [deathYear] [int] NULL DEFAULT (NULL), [deathMonth] [int] NULL DEFAULT (NULL), [deathDay] [int] NULL DEFAULT (NULL), [deathCountry] [varchar](50) NULL DEFAULT (NULL), [deathState] [varchar](2) NULL DEFAULT (NULL), [deathCity] [varchar](50) NULL DEFAULT (NULL), [nameFirst] [varchar](50) NULL DEFAULT (NULL), [nameLast] [varchar](50) NULL DEFAULT (NULL), [nameNote] [varchar](255) NULL DEFAULT (NULL), [nameGiven] [varchar](255) NULL DEFAULT (NULL), [nameNick] [varchar ](255) NULL DEFAULT (NULL), [vægt] [int] NULL DEFAULT (NULL), [højde] [int] NULL, [bats] [varchar](1) NULL DEFAULT (NULL), [throws] [varchar](1) NULL DEFAULT (NULL), [debut] [varchar]( 10) NULL DEFAULT (NULL), [finalGame] [varchar](10) NULL DEFAULT (NULL), [college] [varchar](50) NULL DEFAULT (NULL), [lahman40ID] [varchar](9) NULL DEFAULT ( NULL), [lahman45ID] [varchar](9) NULL DEFAULT (NULL), [retroID] [varchar](9) NULL DEFAULT (NULL), [holtzID] [varchar](9) NULL DEFAULT (NULL), [bbrefID ] [varchar](9) NULL STANDARD (NULL),PRIMÆR NØGLE KLUSTERET ([lahmanID] ASC) PÅ [PRIMÆR]) PÅ [PRIMÆR];GO INSERT I [dbo].[PlayerInfo] ([lahmanID] ,[playerID] ,[managerID],[hofID] ,[fødselsår],[fødselsmåned],[fødselsdag] ,[fødselsland],[fødselsstat],[fødselsby],[dødsår],[dødsmåned],[dødsdag] ,[,[dødsland] deathState], [deathCity] ,[nameFirst] ,[nameLast] ,[nameNote] ,[nameGiven] ,[nameNick] ,[weight] ,[height] ,[bats] ,[throws] ,[debut] ,[finalGame] ,[college] ,[lahman40ID] ,[lahman45ID] ,[ retroID] ,[holtzID] ,[bbrefID]) SELECT [lahmanID] ,[playerID],[managerID] ,[hofID],[fødselsår],[fødselsmåned],[fødselsdag],[fødselsland],[fødselsstat] ,[fødselsby ] ,[dødsår],[dødsmåned],[dødsdag],[dødsland],[dødsstat],[dødsby],[navnFørst],[navnLast] ,[navnBemærk] ,[navnGiv],[navnNick] ,[vægt] , [højde] ,[bats] ,[kast] ,[debut] ,[slutspil],[college] ,[lahman40ID] ,[lahman45ID] ,[retroI D],[holtzID] ,[bbrefID]FRA [dbo].[Spillere]HVOR [lahmanID] <=10000; OPRET VISNING [PlayerPostSeason]Med SCHEMABINDINGAS SELECT [p].[lahmanID], [p].[nameFirst], [p].[nameLast], [p].[debut], [p].[finalGame], [pp ].[yearID], [pp].[runde], [pp].[holdID], [pp].[W], [pp].[L], [pp].[G] FRA [dbo]. [PlayerInfo] [p] JOIN [dbo].[PitchingPost] [pp] ON [p].[playerID] =[pp].[playerID]; OPRET UNIKT KLUSTERET INDEKS [CI_PlayerPostSeason] PÅ [PlayerPostSeason] ([lahmanID], [yearID], [round]); OPRET IKKE-KLUNGERET INDEKS [NCI_PlayerPostSeason_Name] PÅ [PlayerPostSeason] ([nameFirst], [nameLast]);
Hvis vi tjekker statistik for de klyngede og ikke-klyngede indekser, ser vi, at de eksisterer:
DBCC SHOW_STATISTICS ('PlayerPostSeason', CI_PlayerPostSeason) MED STAT_HEADER;GODBCC SHOW_STATISTICS ('PlayerPostSeason', NCI_PlayerPostSeason_Name) MED STAT_HEADER;GO
 Indeksvisningsstatistikker efter første oprettelse
Indeksvisningsstatistikker efter første oprettelse
Nu vil vi indsætte flere rækker i PlayerInfo:
INSERT INTO [dbo].[PlayerInfo] ([lahmanID] ,[playerID] ,[managerID] ,[hofID],[fødselsår],[fødselsmåned],[fødselsdag],[fødselsland],[fødselsstat] ,[ fødselsby],[dødsår],[dødsmåned],[dødsdag],[dødsland],[dødsstat],[dødsby],[navnFørst],[navnLast],[navnBemærkning] ,[navnGiven] ,[navnNick] ,[vægt] ,[højde] ,[flagermus] ,[kast] ,[debut] ,[finalGame] ,[college] ,[lahman40ID] ,[lahman45ID] ,[retroID] ,[holtzID] ,[bbrefID])VÆLG [lahmanID] , [playerID] ,[managerID] ,[hofID],[fødselsår],[fødselsmåned],[fødselsdag],[fødselsland],[fødselsstat],[fødselsby] ,[deathYear],[deathMonth],[deathDay] ,[deathCountry],[deathState],[deathCity],[nameFirst],[nameLast] ,[nameNote],[nameGiven],[nameNick] ,[weight] ,[ højde] ,[bats],[kast] ,[debut] ,[slutspil] ,[college] ,[lahman40ID],[lahman45ID],[retroID] ,[holtzID],[bbrefID]FRA [dbo].[Spillere] WHERE [lahmanID]> 10000;
Og hvis vi tjekker sys.dm_db_stats_properties, kan vi se rækkeændringerne:
VÆLG [sch].[navn] AS [Skema], [så].[navn] AS [ObjectName], [så].[type] AS [ObjectType], [ss].[navn] AS [Statistics] ], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , [sp].[modification_counter] AS [RowModifications]FROM [sys].[objects] [so]JOIN [sys].[stats] [ss] ON [so].[object_id] =[ss].[object_id]JOIN [sys].[skemas] [sch] ON [ så].[schema_id] =[sch].[schema_id]YDRE ANVENDELSE [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) spWHERE [så].[navn] =' PlayerPostSeason';
 Rækker ændret i den indekserede visning via sys.dm_db_stats_properties
Rækker ændret i den indekserede visning via sys.dm_db_stats_properties
Og bare for sjov, hvis vi tjekker sys.sysindexes, kan vi også se ændringerne der:
VÆLG [så].[navn], [si].[navn], [si].[rowcnt], [si].[rowmodctr]FRA [sys].[sysindexes] [si]JOIN [sys] .[objects] [so] ON [si].[id] =[so].[object_id]WHERE [so].[name] ='PlayerPostSeason';
 Rækker ændret i den indekserede visning via sys.sysindexes
Rækker ændret i den indekserede visning via sys.sysindexes
Nu er sys.sysindexes forældet, men hvis du husker fra mit tidligere indlæg, er det det, sp_updatestats bruger til at se, hvad der er blevet ændret. Men... objektlisten for sys.indexes er drevet af forespørgslen mod sys.objects, som, hvis du husker det, filtrerer på brugertabeller ('U') og interne tabeller ('IT'). Det inkluderer ikke visninger ('V') i det filter. Som sådan, når vi kører sp_updatestats og tjekker outputtet (ikke inkluderet for kortheds skyld), er der ingen omtale af vores PlayerPostSeason-visning.
Derfor, hvis du har indekserede visninger, og du er afhængig af sp_updatestats til at opdatere dine statistikker, bliver dine visningsstatistikker ikke opdateret. Jeg vil dog gætte på, at de fleste af jer har muligheden for automatisk opdatering af statistik aktiveret for dine databaser. Det er godt, for med denne mulighed opdateres visningsstatistikker, hvis de er blevet ugyldige. Vi ved, at vi har lavet over 2000 ændringer af indekserne på PlayerPostSeason. Hvis vi forespørger med et fornavn, der er selektivt, skal vores forespørgselsplan bruge NCI_PlayerPostSeason_Name-indekset, og fordi statistikker er forældede, bør de blive opdateret. Lad os tjekke:
VÆLG *FRA [PlayerPostSeason]WHERE [nameFirst] ='Madison';GO
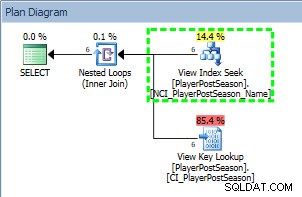 Forespørgselsplan fra SELECT mod ikke-klyngede indeks
Forespørgselsplan fra SELECT mod ikke-klyngede indeks
Vi kan se i planen, at NCI_PlayerPostSeason_Name ikke-klyngede indeks blev brugt, og hvis vi tjekker statistik:
 Statistik efter automatisk opdatering
Statistik efter automatisk opdatering
Ganske vist er statistikken for det ikke-klyngede indeks blevet opdateret. Men vi ønsker selvfølgelig ikke at stole på automatisk opdatering til at administrere statistik, vi vil være proaktive. Vi har to muligheder:
- Vedligeholdelsesopgave
- Tilpasset script
Opdateringsstatistikvedligeholdelsesopgaven gør opdatere visningsstatistikker. Dette kaldes ikke specifikt nogen steder i brugergrænsefladen, men hvis vi laver en vedligeholdelsesplan med opdateringsstatistikopgaven og kører den, opdateres statistikken for den indekserede visning. Ulempen ved vedligeholdelsesopgaven med opdatering af statistik er, at det er en slædehammer-tilgang. Den opdaterer alle statistik, uanset om det er nødvendigt (det er næsten lige så slemt som sp_updatestats). Jeg foretrækker et brugerdefineret script, hvor SQL Server kun opdaterer det, der er blevet ændret. Hvis du ikke er til at rulle dit eget manuskript, kan man bruge Ola Hallengrens manuskript. Det er almindeligt at opdatere statistik som en del af dine indeksombygninger og omorganiseringer. For eksempel, med Olas script i SQL Agent-jobbet ville du have:
sqlcmd -E -S $(ESCAPE_SQUOTE(SRVR)) -d master -Q "UDFØR [dbo].[IndexOptimize] @Databases ='BaseballData', @FragmentationLow =NULL, @FragmentationMedium ='INDEX_REORGANIZE'_igREBULDINDEXH, @FRAgmentation ='BaseballData' ', @FragmentationLevel1 =5, @FragmentationLevel2 =30, @UpdateStatistics ='ALLE', @OnlyModifiedStatistics ='Y', @LogToTable ='Y'" –bMed denne mulighed, hvis statistikker er blevet ændret, vil de blive opdateret, og hvis vi tjekker den [dbo].[IndexOptimize] lagrede procedure kan vi se, hvor Ola tjekker for ændringer:
-- Er dataene i statistikken blevet ændret, siden statistikken sidst blev opdateret? HVIS @CurrentStatisticsID IKKE ER NULL OG @UpdateStatistics IKKE ER NULL OG @OnlyModifiedStatistics ='Y' BEGIN SET @CurrentCommand10 ='' HVIS @LockTimeout IKKE ER NULL SET @CurrentCommand10 ='SET LOCK_TIMEOUT ' + CAST(@nvar0) char. + '; ' IF (@Version>=10.504000 OG @Version <11) ELLER @Version>=11.03000 BEGIN SET @CurrentCommand10 =@CurrentCommand10 + 'USE ' + QUOTENAME(@CurrentDatabaseName) + '; HVIS EKSISTERER(VÆLG * FRA sys.dm_db_stats_properties (@ParamObjectID, @ParamStatisticsID) WHERE modification_counter> 0) BEGIN SET @ParamStatisticsModified =1 END' END ELSE BEGIN SET @CurrentCommand10 ='TEIST0(+'SELECTICommand * Q @CurrentDatabaseName) + '.sys.sysindexes sysindexes WHERE sysindexes.[id] =@ParamObjectID AND sysindexes.[indid] =@ParamStatisticsID AND sysindexes.[rowmodctr] <> 0) BEGIN SET @ParamStatisticsModified' END' =END' =1>For versioner, der understøtter sys.dm_db_stats_properties DMF, tjekker Ola den for enhver statistik, der er blevet ændret, og for versioner, der ikke understøtter den nye sys.dm_db_stats_properties DMF, kontrolleres sys.sysindexes systemtabellen. Min eneste klage her er, at scriptet opfører sig på samme måde som sp_updatestats:hvis mindst én række er blevet ændret, vil statistikken blive opdateret.
Hvis du ikke er til at skrive din egen kode til styring af statistik, så vil jeg anbefale at holde fast i Olas script. Men hvis du vil målrette dine opdateringer lidt mere, så vil jeg anbefale at bruge sys.dm_db_stats_properties. Denne DMF er kun tilgængelig for SQL Server 2008R2 SP2 og højere, og SQL Server 2012 SP1 og højere, så hvis du er på en lavere version, skal du bruge sys.indexes. Men for dem af jer med adgang til sys.dm_db_stats_properties, her er en forespørgsel for at komme i gang:
VÆLG [sch].[navn] AS [Skema], [så].[navn] AS [ObjectName], [så].[type] AS [ObjectType], [ss].[navn] AS [Statistics] ], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , CAST(100 * [sp].[rows_sampled] / [sp].[rows] AS DECIMAL (18, 2)) AS [PercentSampled], [sp].[modification_counter] AS [RowModifications] , CAST(100 * [sp].[modification_counter] / [sp].[rows] ] SOM DECIMAL(18, 2)) SOM [PercentChange]FRA [sys].[objekter] SOM [så]INDRE JOIN [sys].[stats] AS [ss] PÅ [so].[object_id] =[ss] .[object_id]INNER JOIN [sys].[schemas] AS [sch] ON [so].[schema_id] =[sch].[schema_id]YDRE ANVENDELSE [sys].[dm_db_stats_properties]([so].[object_id] , [ss].[stats_id]) AS [sp]HVOR [så].[indtast] IN ('U','V')AND ((CAST(100 * [sp].[modifikationstæller] / [sp]. [rows] AS DECIMAL(18,2))>=10,0))ORDER BY CAST(100 * [sp].[modification_counter] / [sp].[rows] AS DECIMAL(18, 2)) DESC;Bemærk, at med sys.objects filtrerer vi på tabeller og visninger; du kan ændre dette til at inkludere systemtabeller. Du kan derefter ændre prædikatet til kun at hente rækker baseret på procentdelen af ændrede rækker, eller måske en kombination af modifikationsprocent og antal rækker (for tabeller med millioner eller milliarder af rækker kan denne procentdel være lavere end for små tabeller).
Oversigt
Hjemmemeddelelsen her er ret klar:Jeg anbefaler ikke at bruge sp_updatestats til at administrere statistik. Statistikker opdateres, når en eller flere rækker er ændret (hvilket er en ekstrem lav tærskel for opdatering af statistik), og statistik for indekserede visninger er ikke opdateret. Dette er ikke en omfattende og effektiv metode til styring af statistik ... og opdateringsstatistikopgaven i en vedligeholdelsesplan er ikke meget bedre. Den opdaterer de indekserede visningsstatistikker, men den opdaterer hver statistik, uanset ændringer. Et brugerdefineret script er virkelig vejen at gå, men forstå, at Ola Hallengrens script, hvis du opdaterer baseret på modifikation, også opdaterer, når kun rækken er blevet ændret (men det får i det mindste de indekserede visninger). I sidste ende, for den bedste kontrol, skal du prøve at rulle dit eget script til styring af statistik. Jeg har givet dig grundforespørgslen til at starte. Hvis du kan spærre et par timer af for at øve din T-SQL-skrivning og derefter teste den, har du et fungerende brugerdefineret script klar til dine databaser, inden ferien ruller rundt.