Denne artikel er den femte del i en serie om tabeludtryk. I del 1 gav jeg baggrunden for tabeludtryk. I del 2, del 3 og del 4 dækkede jeg både de logiske og optimeringsaspekterne af afledte tabeller. I denne måned starter jeg dækningen af almindelige tabeludtryk (CTE'er). Ligesom med afledte tabeller vil jeg først behandle den logiske behandling af CTE'er, og i fremtiden vil jeg komme til optimeringsovervejelser.
I mine eksempler vil jeg bruge en prøvedatabase kaldet TSQLV5. Du kan finde scriptet, der opretter og udfylder det her, og dets ER-diagram her.
CTE'er
Lad os starte med udtrykket fælles tabeludtryk . Hverken dette udtryk eller dets akronym CTE forekommer i ISO/IEC SQL-standardspecifikationerne. Så det kan være, at begrebet stammer fra et af databaseprodukterne og senere overtaget af nogle af de andre databaseleverandører. Du kan finde det i dokumentationen til Microsoft SQL Server og Azure SQL Database. T-SQL understøtter det fra og med SQL Server 2005. Standarden bruger termen forespørgselsudtryk at repræsentere et udtryk, der definerer en eller flere CTE'er, inklusive den ydre forespørgsel. Den bruger udtrykket med listeelement at repræsentere det, T-SQL kalder en CTE. Jeg giver snart syntaksen for et forespørgselsudtryk.
Bortset fra kilden til udtrykket, almindelig tabeludtryk eller CTE , er det almindeligt anvendte udtryk af T-SQL-udøvere for den struktur, der er fokus i denne artikel. Så lad os først tage fat på, om det er et passende udtryk. Vi har allerede konkluderet, at udtrykket tabeludtryk er passende for et udtryk, der konceptuelt returnerer en tabel. Afledte tabeller, CTE'er, visninger og indlejrede tabelværdier er alle typer navngivne tabeludtryk som T-SQL understøtter. Altså tabeludtrykket del af fælles tabeludtryk virker bestemt passende. Hvad angår det almindelige del af udtrykket, har det sandsynligvis at gøre med en af designfordelene ved CTE'er i forhold til afledte tabeller. Husk, at du ikke kan genbruge det afledte tabelnavn (eller mere præcist områdevariabelnavnet) mere end én gang i den ydre forespørgsel. Omvendt kan CTE-navnet bruges flere gange i den ydre forespørgsel. Med andre ord er CTE-navnet almindeligt til den ydre forespørgsel. Selvfølgelig vil jeg demonstrere dette designaspekt i denne artikel.
CTE'er giver dig lignende fordele som afledte tabeller, herunder muliggør udvikling af modulære løsninger, genbrug af kolonnealiaser, indirekte interaktion med vinduesfunktioner i klausuler, der normalt ikke tillader dem, understøtter modifikationer, der indirekte er afhængige af TOP eller OFFSET FETCH med ordrespecifikation, og andre. Men der er visse designfordele sammenlignet med afledte tabeller, som jeg vil dække i detaljer, når jeg har angivet syntaksen for strukturen.
Syntaks
Her er standardens syntaks for et forespørgselsudtryk:
7.17
Funktion
Angiv en tabel.
Format
[
[
AS
|
[
|
[
|
[
|
[
TILSVARENDE [ AF
FETCH { FIRST | NÆSTE } [
|
7.18
Funktion
Angiv genereringen af bestillings- og cyklusdetektionsinformation i resultatet af rekursive forespørgselsudtryk.
Format
SØG
DYBDE FØRST AF
CYKLUS
STANDARD
7.3
Funktion
Angiv et sæt af
Standardudtrykket forespørgselsudtryk repræsenterer et udtryk, der involverer en WITH-sætning, en med liste , som er lavet af en eller flere med listeelementer , og en ydre forespørgsel. T-SQL henviser til standarden med listeelement som CTE.
T-SQL understøtter ikke alle standard syntakselementer. For eksempel understøtter den ikke nogle af de mere avancerede rekursive forespørgselselementer, der giver dig mulighed for at kontrollere søgeretningen og håndtere cyklusser i en grafstruktur. Rekursive forespørgsler er i fokus i næste måneds artikel.
Her er T-SQL-syntaksen til en forenklet forespørgsel mod en CTE:
Her er et eksempel på en simpel forespørgsel mod en CTE, der repræsenterer kunder i USA:
Du vil finde de samme tre dele i en sætning mod en CTE, som du ville finde i en erklæring mod en afledt tabel:
Hvad der er anderledes ved designet af CTE'er sammenlignet med afledte tabeller er, hvor i koden disse tre elementer er placeret. Med afledte tabeller indlejres den indre forespørgsel i den ydre forespørgsels FROM-klausul, og tabeludtrykkets navn tildeles efter selve tabeludtrykket. Elementerne hænger på en måde sammen. Omvendt adskiller koden med CTE'er de tre elementer:først tildeler du tabeludtrykkets navn; for det andet specificerer du tabeludtrykket - fra start til slut uden afbrydelser; for det tredje angiver du den ydre forespørgsel - fra start til slut uden afbrydelser. Senere, under "Designovervejelser", vil jeg forklare implikationerne af disse designforskelle.
Et ord om CTE'er og brugen af et semikolon som en erklæringsterminator. Desværre, i modsætning til standard SQL, tvinger T-SQL dig ikke til at afslutte alle udsagn med et semikolon. Der er dog meget få tilfælde i T-SQL, hvor koden uden en terminator er tvetydig. I de tilfælde er opsigelsen obligatorisk. En sådan sag vedrører det faktum, at WITH-klausulen bruges til flere formål. En er at definere en CTE, en anden er at definere et tabeltip til en forespørgsel, og der er et par ekstra use cases. Som et eksempel bruges WITH-sætningen i følgende sætning til at tvinge det serialiserbare isolationsniveau med et tabeltip:
Potentialet for tvetydighed er, når du har en uafsluttet sætning forud for en CTE-definition, i hvilket tilfælde parseren muligvis ikke er i stand til at fortælle, om WITH-sætningen hører til den første eller anden sætning. Her er et eksempel, der viser dette:
Her kan parseren ikke fortælle, om WITH-sætningen skal bruges til at definere et tabeltip for Customers-tabellen i den første sætning, eller starte en CTE-definition. Du får følgende fejlmeddelelse:
Rettelsen er selvfølgelig at afslutte erklæringen forud for CTE-definitionen, men som en bedste praksis bør du virkelig afslutte alle dine erklæringer:
Du har måske bemærket, at nogle mennesker starter deres CTE-definitioner med et semikolon som en praksis, som sådan:
Pointen i denne praksis er at reducere potentialet for fremtidige fejl. Hvad hvis nogen på et senere tidspunkt tilføjer en uafsluttet sætning lige før din CTE-definition i scriptet og ikke gider at tjekke hele scriptet, snarere kun deres erklæring? Dit semikolon lige før WITH-klausulen bliver effektivt deres erklæringsafslutning. Du kan helt sikkert se det praktiske i denne praksis, men det er lidt unaturligt. Hvad der anbefales, selvom det er sværere at opnå, er at indgyde god programmeringspraksis i organisationen, herunder opsigelse af alle erklæringer.
Med hensyn til de syntaksregler, der gælder for det tabeludtryk, der bruges som den indre forespørgsel i CTE-definitionen, er de de samme som dem, der gælder for det tabeludtryk, der bruges som den indre forespørgsel i en afledt tabeldefinition. Det er:
For detaljer, se afsnittet "Et tabeludtryk er en tabel" i del 2 af serien.
Hvis du spørger erfarne T-SQL-udviklere om, hvorvidt de foretrækker at bruge afledte tabeller eller CTE'er, er ikke alle enige om, hvad der er bedst. Naturligvis har forskellige mennesker forskellige stylingpræferencer. Jeg bruger nogle gange afledte tabeller og nogle gange CTE'er. Det er godt at være i stand til bevidst at identificere de specifikke sprogdesignforskelle mellem de to værktøjer og vælge ud fra dine prioriteter i en given løsning. Med tid og erfaring træffer du dine valg mere intuitivt.
Desuden er det vigtigt ikke at forveksle brugen af tabeludtryk og midlertidige tabeller, men det er en præstationsrelateret diskussion, som jeg vil behandle i en fremtidig artikel.
CTE'er har rekursive forespørgselsfunktioner, og afledte tabeller har ikke. Så hvis du har brug for at stole på dem, ville du naturligvis gå med CTE'er. Rekursive forespørgsler er i fokus i næste måneds artikel.
I del 2 forklarede jeg, at jeg ser indlejring af afledte tabeller som at tilføje kompleksitet til koden, da det gør det svært at følge logikken. Jeg gav følgende eksempel, der identificerede ordreår, hvor mere end 70 kunder afgav ordrer:
CTE'er understøtter ikke indlejring. Så når du gennemgår eller fejlfinder en løsning baseret på CTE'er, går du ikke tabt i den indlejrede logik. I stedet for nesting bygger du flere modulære løsninger ved at definere flere CTE'er under den samme WITH-sætning, adskilt af kommaer. Hver af CTE'erne er baseret på en forespørgsel, der er skrevet fra start til slut uden afbrydelser. Jeg ser det som en god ting fra et kodeklarheds- og vedligeholdelsesperspektiv.
Her er en løsning på den førnævnte opgave ved hjælp af CTE'er:
Jeg kan bedre lide den CTE-baserede løsning. Men igen, spørg erfarne udviklere, hvilken af de to ovenstående løsninger de foretrækker, og de vil ikke alle være enige. Nogle foretrækker faktisk den indlejrede logik og at kunne se alt på ét sted.
En meget klar fordel ved CTE'er i forhold til afledte tabeller er, når du skal interagere med flere forekomster af det samme tabeludtryk i din løsning. Husk følgende eksempel baseret på afledte tabeller fra del 2 i serien:
Denne løsning returnerer ordreår, ordretal pr. år og forskellen mellem indeværende års og det foregående års optællinger. Ja, du kunne gøre det nemmere med LAG-funktionen, men mit fokus her er ikke at finde den bedste måde at nå denne meget specifikke opgave. Jeg bruger dette eksempel til at illustrere visse sprogdesignaspekter af navngivne tabeludtryk.
Problemet med denne løsning er, at du ikke kan tildele et navn til et tabeludtryk og genbruge det i det samme logiske forespørgselsbehandlingstrin. Du navngiver en afledt tabel efter selve tabeludtrykket i FROM-sætningen. Hvis du definerer og navngiver en afledt tabel som det første input i en join, kan du ikke også genbruge det afledte tabelnavn som det andet input af den samme join. Hvis du selv skal forbinde to forekomster af det samme tabeludtryk, har du med afledte tabeller intet andet valg end at duplikere koden. Det er, hvad du gjorde i ovenstående eksempel. Omvendt er CTE-navnet tildelt som det første element i koden blandt de førnævnte tre (CTE-navn, indre forespørgsel, ydre forespørgsel). I logisk forespørgselsbehandling, når du kommer til den ydre forespørgsel, er CTE-navnet allerede defineret og tilgængeligt. Dette betyder, at du kan interagere med flere forekomster af CTE-navnet i den ydre forespørgsel, som sådan:
Denne løsning har en klar programmerbar fordel i forhold til den, der er baseret på afledte tabeller, idet du ikke behøver at vedligeholde to kopier af det samme tabeludtryk. Der er mere at sige om det fra et fysisk behandlingsperspektiv og sammenligne det med brugen af midlertidige tabeller, men det vil jeg gøre i en fremtidig artikel, der fokuserer på ydeevne.
En fordel, som kode baseret på afledte tabeller har sammenlignet med kode baseret på CTE'er, har at gøre med den lukkeegenskab, som et tabeludtryk formodes at have. Husk, at et relationsudtryks lukkeegenskab siger, at både input og output er relationer, og at et relationelt udtryk derfor kan bruges, hvor der forventes en relation, som input til endnu et relationelt udtryk. På samme måde returnerer et tabeludtryk en tabel og formodes at være tilgængelig som en inputtabel for et andet tabeludtryk. Dette gælder for en forespørgsel, der er baseret på afledte tabeller - du kan bruge den, hvor en tabel forventes. For eksempel kan du bruge en forespørgsel, der er baseret på afledte tabeller, som den indre forespørgsel i en CTE-definition, som i følgende eksempel:
Det samme gælder dog ikke for en forespørgsel, der er baseret på CTE'er. Selvom det konceptuelt formodes at blive betragtet som et tabeludtryk, kan du ikke bruge det som den indre forespørgsel i afledte tabeldefinitioner, underforespørgsler og selve CTE'er. For eksempel er følgende kode ikke gyldig i T-SQL:
Den gode nyhed er, at du kan bruge en forespørgsel, der er baseret på CTE'er, som den indre forespørgsel i visninger og inline-tabel-vurderede funktioner, som jeg dækker i fremtidige artikler.
Husk også, at du altid kan definere en anden CTE baseret på den sidste forespørgsel, og derefter få den yderste forespørgsel til at interagere med den CTE:
Fra et fejlfindingssynspunkt har jeg som nævnt som regel nemmere ved at følge logikken i kode, der er baseret på CTE'er, sammenlignet med kode baseret på afledte tabeller. Løsninger baseret på afledte tabeller har dog den fordel, at du kan fremhæve ethvert indlejringsniveau og køre det uafhængigt, som vist i figur 1.
Med CTE'er er tingene sværere. For at kode, der involverer CTE'er, skal kunne køres, skal den starte med et WITH-udtryk efterfulgt af et eller flere navngivne tabeludtryk i parentes adskilt af kommaer, efterfulgt af en forespørgsel uden forudgående komma. Du er i stand til at fremhæve og køre enhver af de indre forespørgsler, der virkelig er selvstændige, såvel som den komplette løsnings kode; du kan dog ikke fremhæve og køre nogen anden mellemliggende del af løsningen. For eksempel viser figur 2 et mislykket forsøg på at køre koden, der repræsenterer C2.
Så med CTE'er er du nødt til at ty til noget akavede midler for at kunne fejlfinde et mellemtrin i løsningen. For eksempel er en almindelig løsning midlertidigt at injicere en SELECT * FROM your_cte-forespørgsel lige under den relevante CTE. Du fremhæver og kører derefter koden inklusive den injicerede forespørgsel, og når du er færdig, sletter du den injicerede forespørgsel. Figur 3 viser denne teknik.
Problemet er, at når du foretager ændringer i koden – selv midlertidige mindre som ovenstående – er der en chance for, at når du forsøger at vende tilbage til den originale kode, vil du ende med at introducere en ny fejl.
En anden mulighed er at style din kode lidt anderledes, sådan at hver ikke-første CTE-definition starter med en separat kodelinje, der ser sådan ud:
Derefter, når du vil køre en mellemliggende del af koden ned til en given CTE, kan du gøre det med minimale ændringer i din kode. Ved at bruge en linjekommentar kommenterer du kun den ene kodelinje, der svarer til den CTE. Du fremhæver og kører derefter koden ned til og med CTE's indre forespørgsel, som nu betragtes som den yderste forespørgsel, som illustreret i figur 4.
Hvis du ikke er tilfreds med denne stil, har du endnu en mulighed. Du kan bruge en blokkommentar, der starter lige før kommaet, der går forud for den aktuelle CTE og slutter efter den åbne parentes, som illustreret i figur 5.
Det bunder i personlige præferencer. Jeg bruger typisk den midlertidigt injicerede SELECT *-forespørgselsteknik.
Der er en vis begrænsning i T-SQL's understøttelse af tabelværdikonstruktører sammenlignet med standarden. Hvis du ikke er bekendt med konstruktionen, så sørg for at tjekke del 2 i serien først, hvor jeg beskriver det i detaljer. Mens T-SQL giver dig mulighed for at definere en afledt tabel baseret på en tabelværdikonstruktør, tillader den dig ikke at definere en CTE baseret på en tabelværdikonstruktør.
Her er et understøttet eksempel, der bruger en afledt tabel:
Desværre er lignende kode, der bruger en CTE, ikke understøttet:
Denne kode genererer følgende fejl:
Der er dog et par løsninger. Den ene er at bruge en forespørgsel mod en afledt tabel, der igen er baseret på en tabelværdikonstruktør, som CTE'ens indre forespørgsel, som sådan:
En anden er at ty til den teknik, som folk brugte, før tabelvurderede konstruktører blev introduceret i T-SQL - ved at bruge en række FROMless-forespørgsler adskilt af UNION ALL-operatorer, som sådan:
Bemærk, at kolonnealiasserne er tildelt lige efter CTE-navnet.
De to metoder bliver algebriseret og optimeret på samme måde, så brug den, du er mere komfortabel med.
Et værktøj, som jeg bruger ret ofte i mine løsninger, er en hjælpetabel med tal. En mulighed er at oprette en faktisk taltabel i din database og udfylde den med en sekvens af rimelig størrelse. En anden er at udvikle en løsning, der producerer en række tal i farten. For sidstnævnte mulighed vil du have, at inputs skal være afgrænsningerne for det ønskede område (vi kalder dem
Denne kode genererer følgende output:
Den første CTE kaldet L0 er baseret på en tabelværdikonstruktør med to rækker. De faktiske værdier der er ubetydelige; det vigtige er, at den har to rækker. Derefter er der en sekvens af fem yderligere CTE'er ved navn L1 til L5, der hver anvender en krydsforbindelse mellem to forekomster af den foregående CTE. Følgende kode beregner antallet af rækker, der potentielt genereres af hver af CTE'erne, hvor @L er CTE-niveaunummeret:
Her er de tal, du får for hver CTE:
At gå op til niveau 5 giver dig over fire milliarder rækker. Dette burde være tilstrækkeligt til enhver praktisk anvendelse, som jeg kan komme i tanke om. Det næste trin finder sted i CTE kaldet Nums. Du bruger en ROW_NUMBER-funktion til at generere en sekvens af heltal, der starter med 1 baseret på ingen defineret rækkefølge (ORDER BY (SELECT NULL)), og navngiver resultatkolonnen rownum. Endelig bruger den ydre forespørgsel et TOP-filter baseret på rækkefølge for at filtrere så mange tal som den ønskede sekvenskardinalitet (@high – @low + 1), og beregner resultattallet n som @low + rownum – 1.
Her kan du virkelig værdsætte skønheden i CTE-designet og de besparelser, det giver, når du bygger løsninger på en modulær måde. I sidste ende udpakker unnesting-processen 32 tabeller, der hver består af to rækker baseret på konstanter. Dette kan tydeligt ses i udførelsesplanen for denne kode, som vist i figur 6 ved brug af SentryOne Plan Explorer.
Hver konstant scanningsoperator repræsenterer en tabel med konstanter med to rækker. Sagen er, at den øverste operatør er den, der anmoder om disse rækker, og den kortslutter, efter den har fået det ønskede nummer. Læg mærke til de 10 rækker, der er angivet over pilen, der flyder ind i Top-operatoren.
Jeg ved, at denne artikels fokus er den konceptuelle behandling af CTE'er og ikke fysiske/præstationsmæssige overvejelser, men ved at se på planen kan du virkelig sætte pris på kodens korthed sammenlignet med den langvarige, hvad den oversætter til bag kulisserne.
Ved at bruge afledte tabeller kan du faktisk skrive en løsning, der erstatter hver CTE-reference med den underliggende forespørgsel, som den repræsenterer. Det du får er ret skræmmende:
Obviously, you don’t want to write a solution like this, but it’s a good way to illustrate what SQL Server does behind the scenes with your CTE code.
If you were really planning to write a solution based on derived tables, instead of using the above nested approach, you’d be better off simplifying the logic to a single query with 31 cross joins between 32 table value constructors, each based on two rows, like so:
Still, the solution based on CTEs is obviously significantly simpler. The plans are identical.
CTEs can be used as the source and target tables in INSERT, UPDATE, DELETE and MERGE statements. They cannot be used in the TRUNCATE statement.
The syntax is pretty straightforward. You start the statement as usual with a WITH clause, followed by one or more CTEs separated by commas. Then you specify the outer modification statement, which interacts with the CTEs that were defined under the WITH clause as the source tables, target table, or both. Just like I explained in Part 2 about derived tables, also with CTEs what really gets modified is the underlying base table that the table expression uses. I’ll show a couple of examples using DELETE and UPDATE statements, but remember that you can use CTEs in MERGE and INSERT statements as well.
Here’s the general syntax of a DELETE statement against a CTE:
As an example (don’t actually run it), the following code deletes the 10 oldest orders:
Here’s the general syntax of an UPDATE statement against a CTE:
As an example, the following code updates the 10 oldest unshipped orders that have an overdue required date, increasing the required date to 10 days from today:
The code applies the update in a transaction that it then rolls back so that the change won’t stick.
This code generates the following output, showing both the old and the new required dates:
Of course you will get a different new required date based on when you run this code.
I like CTEs. They have a few advantages compared to derived tables. Instead of nesting the code, you define multiple CTEs separated by commas, typically leading to a more modular solution that is easier to review and maintain. Also, you can have multiple references to the same CTE name in the outer statement, so you don’t need to repeat the inner table expression’s code. However, unlike derived tables, CTEs cannot be defined directly based on a table value constructor, and you cannot highlight and execute some of the intermediate parts of the code. The following table summarizes the differences between derived tables and CTEs:
As the last item says, derived tables do not support recursive capabilities, whereas CTEs do. Recursive queries are the focus of next month’s article.
Format
VALUES
[ { WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
SELECT < select list >
FROM < table name >;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
SELECT custid, country FROM Sales.Customers WITH (SERIALIZABLE);
SELECT custid, country FROM Sales.Customers
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC
Forkert syntaks nær 'UC'. Hvis dette er beregnet til at være et almindeligt tabeludtryk, skal du eksplicit afslutte den forrige sætning med et semikolon. SELECT custid, country FROM Sales.Customers;
WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
;WITH UC AS
(
SELECT custid, companyname
FROM Sales.Customers
WHERE country = N'USA'
)
SELECT custid, companyname
FROM UC;
Designovervejelser
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70;> WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70;
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM ( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS CUR
LEFT OUTER JOIN
( SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate) ) AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH OrdCount AS
(
SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders
FROM Sales.Orders
GROUP BY YEAR(orderdate)
)
SELECT CUR.orderyear, CUR.numorders,
CUR.numorders - PRV.numorders AS diff
FROM OrdCount AS CUR
LEFT OUTER JOIN OrdCount AS PRV
ON CUR.orderyear = PRV.orderyear + 1; WITH C AS
(
SELECT orderyear, numcusts
FROM ( SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM ( SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders ) AS D1
GROUP BY orderyear ) AS D2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C; SELECT orderyear, custid
FROM (WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
)
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70) AS D; WITH C1 AS
(
SELECT YEAR(orderdate) AS orderyear, custid
FROM Sales.Orders
),
C2 AS
(
SELECT orderyear, COUNT(DISTINCT custid) AS numcusts
FROM C1
GROUP BY orderyear
),
C3 AS
(
SELECT orderyear, numcusts
FROM C2
WHERE numcusts > 70
)
SELECT orderyear, numcusts
FROM C3;
 Figur 1:Kan fremhæve og køre en del af koden med afledte tabeller
Figur 1:Kan fremhæve og køre en del af koden med afledte tabeller  Figur 2:Kan ikke fremhæve og køre en del af koden med CTE'er
Figur 2:Kan ikke fremhæve og køre en del af koden med CTE'er  Figur 3:Injicer SELECT * under relevant CTE
Figur 3:Injicer SELECT * under relevant CTE , cte_name AS (
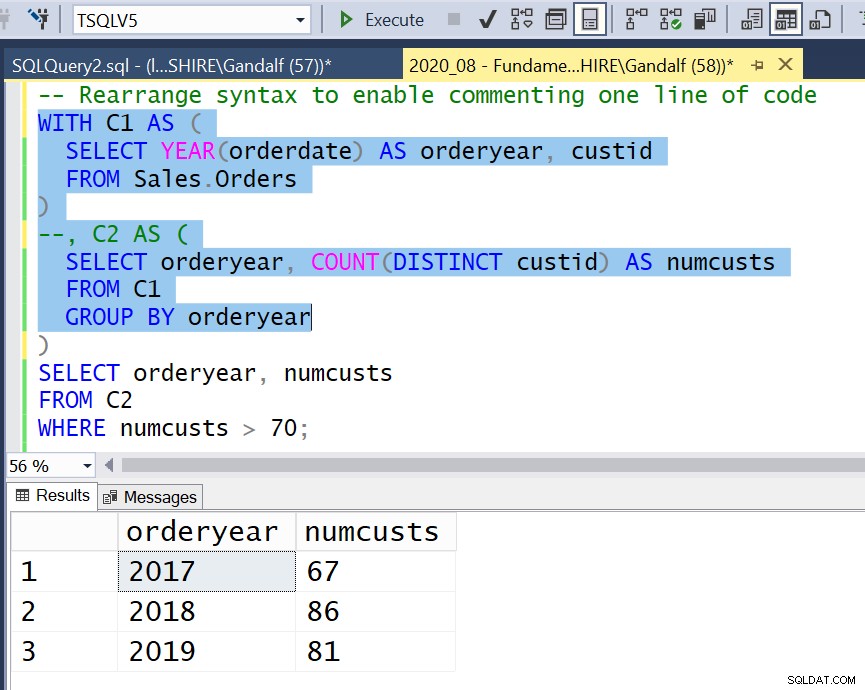 Figur 4:Omarranger syntaks for at muliggøre kommentering af én kodelinje
Figur 4:Omarranger syntaks for at muliggøre kommentering af én kodelinje  Figur 5:Brug blokkommentar
Figur 5:Brug blokkommentar Tabelværdikonstruktør
SELECT custid, companyname, contractdate
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate); WITH MyCusts(custid, companyname, contractdate) AS
(
VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' )
)
SELECT custid, companyname, contractdate
FROM MyCusts;
Forkert syntaks nær søgeordet 'VALUES'. WITH MyCusts AS
(
SELECT *
FROM ( VALUES( 2, 'Cust 2', '20200212' ),
( 3, 'Cust 3', '20200118' ),
( 5, 'Cust 5', '20200401' ) )
AS MyCusts(custid, companyname, contractdate)
)
SELECT custid, companyname, contractdate
FROM MyCusts; WITH MyCusts(custid, companyname, contractdate) AS
(
SELECT 2, 'Cust 2', '20200212'
UNION ALL SELECT 3, 'Cust 3', '20200118'
UNION ALL SELECT 5, 'Cust 5', '20200401'
)
SELECT custid, companyname, contractdate
FROM MyCusts; Fremstilling af en talfølge
@low og @high ). Du ønsker, at din løsning understøtter potentielt store rækkevidder. Her er min løsning til dette formål, ved hjælp af CTE'er, med en anmodning om området 1001 til 1010 i dette specifikke eksempel:DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
WITH
L0 AS ( SELECT 1 AS c FROM (VALUES(1),(1)) AS D(c) ),
L1 AS ( SELECT 1 AS c FROM L0 AS A CROSS JOIN L0 AS B ),
L2 AS ( SELECT 1 AS c FROM L1 AS A CROSS JOIN L1 AS B ),
L3 AS ( SELECT 1 AS c FROM L2 AS A CROSS JOIN L2 AS B ),
L4 AS ( SELECT 1 AS c FROM L3 AS A CROSS JOIN L3 AS B ),
L5 AS ( SELECT 1 AS c FROM L4 AS A CROSS JOIN L4 AS B ),
Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM L5 )
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM Nums
ORDER BY rownum; n
-----
1001
1002
1003
1004
1005
1006
1007
1008
1009
1010
DECLARE @L AS INT = 5;
SELECT POWER(2., POWER(2., @L));
CTE Kardinalitet L0 2 L1 4 L2 16 L3 256 L4 65.536 L5 4.294.967.296  Figur 6:Plan for forespørgselsgenererende talsekvens
Figur 6:Plan for forespørgselsgenererende talsekvens DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D9
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D7
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D5
CROSS JOIN
( SELECT 1 AS C
FROM ( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D3
CROSS JOIN
( SELECT 1 AS C
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN
(VALUES(1),(1)) AS D02(c) ) AS D4 ) AS D6 ) AS D8 ) AS D10 ) AS Nums
ORDER BY rownum; DECLARE @low AS BIGINT = 1001, @high AS BIGINT = 1010;
SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n
FROM ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum
FROM (VALUES(1),(1)) AS D01(c)
CROSS JOIN (VALUES(1),(1)) AS D02(c)
CROSS JOIN (VALUES(1),(1)) AS D03(c)
CROSS JOIN (VALUES(1),(1)) AS D04(c)
CROSS JOIN (VALUES(1),(1)) AS D05(c)
CROSS JOIN (VALUES(1),(1)) AS D06(c)
CROSS JOIN (VALUES(1),(1)) AS D07(c)
CROSS JOIN (VALUES(1),(1)) AS D08(c)
CROSS JOIN (VALUES(1),(1)) AS D09(c)
CROSS JOIN (VALUES(1),(1)) AS D10(c)
CROSS JOIN (VALUES(1),(1)) AS D11(c)
CROSS JOIN (VALUES(1),(1)) AS D12(c)
CROSS JOIN (VALUES(1),(1)) AS D13(c)
CROSS JOIN (VALUES(1),(1)) AS D14(c)
CROSS JOIN (VALUES(1),(1)) AS D15(c)
CROSS JOIN (VALUES(1),(1)) AS D16(c)
CROSS JOIN (VALUES(1),(1)) AS D17(c)
CROSS JOIN (VALUES(1),(1)) AS D18(c)
CROSS JOIN (VALUES(1),(1)) AS D19(c)
CROSS JOIN (VALUES(1),(1)) AS D20(c)
CROSS JOIN (VALUES(1),(1)) AS D21(c)
CROSS JOIN (VALUES(1),(1)) AS D22(c)
CROSS JOIN (VALUES(1),(1)) AS D23(c)
CROSS JOIN (VALUES(1),(1)) AS D24(c)
CROSS JOIN (VALUES(1),(1)) AS D25(c)
CROSS JOIN (VALUES(1),(1)) AS D26(c)
CROSS JOIN (VALUES(1),(1)) AS D27(c)
CROSS JOIN (VALUES(1),(1)) AS D28(c)
CROSS JOIN (VALUES(1),(1)) AS D29(c)
CROSS JOIN (VALUES(1),(1)) AS D30(c)
CROSS JOIN (VALUES(1),(1)) AS D31(c)
CROSS JOIN (VALUES(1),(1)) AS D32(c) ) AS Nums
ORDER BY rownum; Used in modification statements
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
DELETE [ FROM ] <table name>
[ WHERE <filter predicate> ];
WITH OldestOrders AS
(
SELECT TOP (10) *
FROM Sales.Orders
ORDER BY orderdate, orderid
)
DELETE FROM OldestOrders;
WITH < table name > [ (< target columns >) ] AS
(
< table expression >
)
UPDATE <table name>
SET <assignments>
[ WHERE <filter predicate> ];
BEGIN TRAN;
WITH OldestUnshippedOrders AS
(
SELECT TOP (10) orderid, requireddate,
DATEADD(day, 10, CAST(SYSDATETIME() AS DATE)) AS newrequireddate
FROM Sales.Orders
WHERE shippeddate IS NULL
AND requireddate < CAST(SYSDATETIME() AS DATE)
ORDER BY orderdate, orderid
)
UPDATE OldestUnshippedOrders
SET requireddate = newrequireddate
OUTPUT
inserted.orderid,
deleted.requireddate AS oldrequireddate,
inserted.requireddate AS newrequireddate;
ROLLBACK TRAN; orderid oldrequireddate newrequireddate
----------- --------------- ---------------
11008 2019-05-06 2020-07-16
11019 2019-05-11 2020-07-16
11039 2019-05-19 2020-07-16
11040 2019-05-20 2020-07-16
11045 2019-05-21 2020-07-16
11051 2019-05-25 2020-07-16
11054 2019-05-26 2020-07-16
11058 2019-05-27 2020-07-16
11059 2019-06-10 2020-07-16
11061 2019-06-11 2020-07-16
(10 rows affected)
Oversigt
Item Derived table CTE Supports nesting Yes No Supports multiple references No Yes Supports table value constructor Yes No Can highlight and run part of code Yes No Supports recursion No Yes