I mine indlæg i år har jeg diskuteret knæfaldsreaktionerne på forskellige ventetyper, og i dette indlæg vil jeg fortsætte med ventestatistik-temaet og diskutere PAGEIOLATCH_XX vente. Jeg siger "vent", men der er virkelig flere slags PAGEIOLATCH venter, hvilket jeg har tilkendegivet med XX til sidst. De mest almindelige eksempler er:
PAGEIOLATCH_SH– (SH er) venter på, at en datafilside bringes fra disken til bufferpuljen, så dens indhold kan læsesPAGEIOLATCH_EXellerPAGEIOLATCH_UP– (EX clusive eller OP dato) venter på, at en datafilside bringes fra disken til bufferpuljen, så dens indhold kan ændres
Af disse er langt den mest almindelige type PAGEIOLATCH_SH .
Når denne ventetype er den mest udbredte på en server, er det knæfaldende reaktion, at I/O-undersystemet skal have et problem, og det er derfor, undersøgelserne bør fokuseres.
Den første ting at gøre er at sammenligne PAGEIOLATCH_SH ventetal og varighed i forhold til din baseline. Hvis mængden af ventetider er nogenlunde den samme, men varigheden af hver læsevent er blevet meget længere, ville jeg være bekymret over et I/O-undersystemproblem, såsom:
- En fejlkonfiguration/fejl på I/O-undersystemniveau
- Netværksforsinkelse
- En anden I/O-arbejdsbelastning, der forårsager strid med vores arbejdsbyrde
- Konfiguration af replikering/spejling af synkront I/O-undersystem
Efter min erfaring er mønsteret ofte, at antallet af PAGEIOLATCH_SH ventetider er steget væsentligt fra det normale (normale) antal, og ventetiden er også steget (dvs. tiden for et læst I/O er steget), fordi det store antal aflæsninger overbelaster I/O-undersystemet. Dette er ikke et I/O-undersystemproblem – dette er SQL Server, der driver flere I/O'er, end det burde være. Fokus skal nu skifte til SQL Server for at identificere årsagen til de ekstra I/O'er.
Årsager til et stort antal læste I/O'er
SQL Server har to typer læsninger:logiske I/O'er og fysiske I/O'er. Når Access Methods-delen af Storage Engine skal have adgang til en side, beder den Buffer Pool om en pegepind til siden i hukommelsen (kaldet en logisk I/O), og Buffer Pool tjekker dens metadata for at se, om denne side er allerede i hukommelsen.
Hvis siden er i hukommelsen, giver bufferpuljen adgangsmetoderne markøren, og I/O'et forbliver en logisk I/O. Hvis siden ikke er i hukommelsen, udsender bufferpuljen en "rigtig" I/O (kaldet en fysisk I/O), og tråden skal vente på, at den er fuldført – hvilket medfører en PAGEIOLATCH_XX vente. Når I/O er færdig, og markøren er tilgængelig, får tråden besked og kan fortsætte med at køre.
I en ideel verden ville hele din arbejdsbyrde passe i hukommelsen, og så når bufferpuljen er "varmet op" og holder hele arbejdsbyrden, kræves der ikke flere læsninger, kun skrivning af opdaterede data. Det er dog ikke en ideel verden, og de fleste af jer har ikke den luksus, så nogle læsninger er uundgåelige. Så længe antallet af læsninger forbliver omkring dit basisbeløb, er der ikke noget problem.
Når der pludselig og uventet kræves et stort antal læsninger, er det et tegn på, at der er en væsentlig ændring i enten arbejdsbyrden, mængden af bufferpuljehukommelse, der er tilgængelig til lagring af kopier af sider i hukommelsen, eller begge dele.
Her er nogle mulige grundlæggende årsager (ikke en udtømmende liste):
- Eksternt Windows-hukommelsestryk på SQL Server, der får hukommelsesadministratoren til at reducere bufferpuljens størrelse
- Planlæg cache-bloat, der får ekstra hukommelse til at blive lånt fra bufferpuljen
- En forespørgselsplan, der udfører en tabel-/klyngeindeksscanning (i stedet for en indekssøgning) på grund af:
- en stigning i arbejdsbyrden
- et parametersniffningsproblem
- et påkrævet ikke-klynget indeks, der blev slettet eller ændret
- en implicit konvertering
Et mønster at kigge efter, der tyder på, at en tabel/clustered index-scanning er årsagen, er også at se et stort antal CXPACKET venter sammen med PAGEIOLATCH_SH venter. Dette er et almindeligt mønster, der indikerer, at der forekommer store parallelle tabel-/klyngeindeksscanninger.
I alle tilfælde kan du se på, hvilken forespørgselsplan der forårsager PAGEIOLATCH_SH venter ved at bruge sys.dm_os_waiting_tasks og andre DMV'er, og du kan få kode til at gøre det i mit blogindlæg her. Hvis du har et tredjepartsovervågningsværktøj tilgængeligt, kan det muligvis hjælpe dig med at identificere den skyldige uden at blive beskidte.
Eksempel på arbejdsgang med SQL Sentry og Plan Explorer
I et simpelt (åbenbart konstrueret) eksempel, lad os antage, at jeg er på et klientsystem, der bruger SQL Sentrys suite af værktøjer, og ser en stigning i I/O-venter i dashboardvisningen af SQL Sentry, som vist nedenfor:
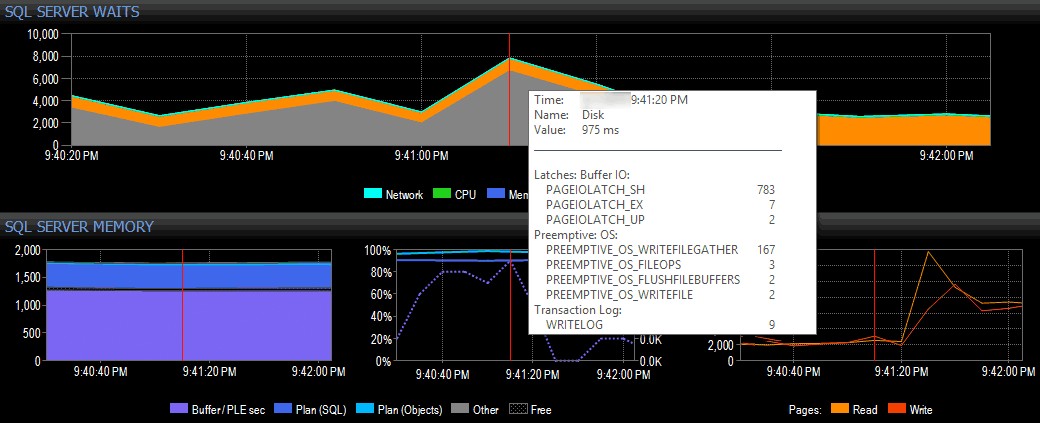
At opdage en stigning i I/O venter i SQL Sentry
Jeg beslutter mig for at undersøge det ved at højreklikke på et valgt tidsinterval omkring tidspunktet for stigningen og derefter hoppe over til den øverste SQL-visning, som vil vise mig de dyreste forespørgsler, der er udført:
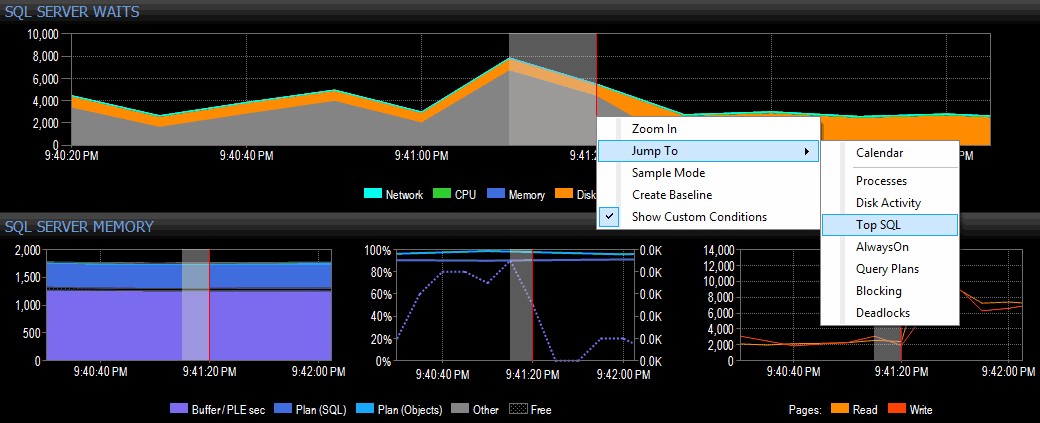
Fremhæv et tidsinterval og navigering til Top SQL
I denne visning kan jeg se, hvilke langvarige eller høje I/O-forespørgsler, der kørte på det tidspunkt, hvor spidsen opstod, og derefter vælge at bore ind i deres forespørgselsplaner (i dette tilfælde er der kun én langvarig forespørgsel, som kørte i næsten et minut):
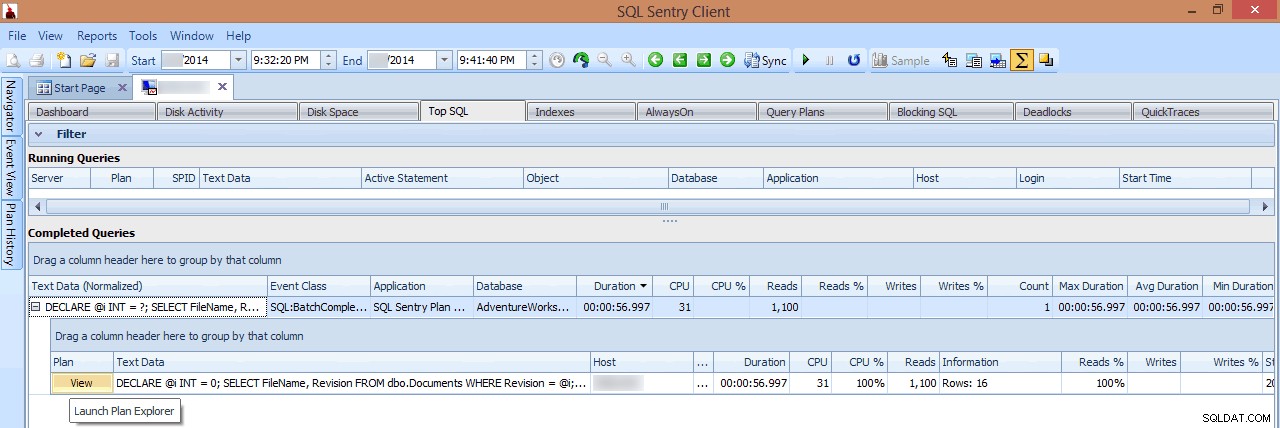
Gennemgang af en langvarig forespørgsel i Top SQL
Hvis jeg ser på planen i SQL Sentry-klienten eller åbner den i SQL Sentry Plan Explorer, ser jeg med det samme flere problemer. Antallet af læsninger, der kræves for at returnere 7 rækker, virker alt for højt, deltaet mellem estimerede og faktiske rækker er stort, og planen viser en indeksscanning, der finder sted, hvor jeg ville have forventet en søgning:
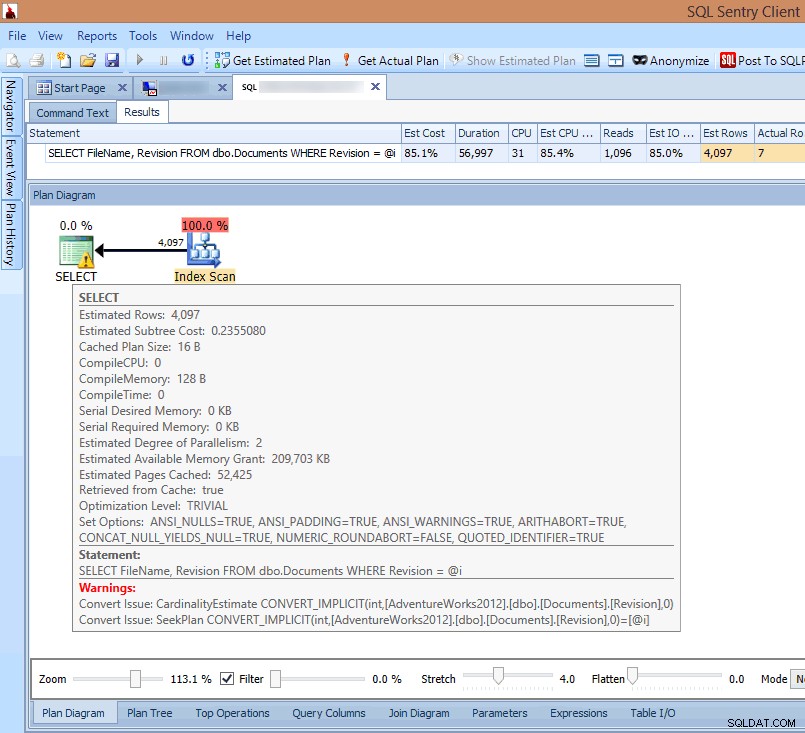
Se implicitte konverteringsadvarsler i forespørgselsplanen
Årsagen til alt dette er fremhævet i advarslen på SELECT operator:Det er en implicit konvertering!
Implicitte konverteringer er et snigende problem forårsaget af et misforhold mellem søgeprædikatets datatype og datatypen for den søjle, der søges i, eller en beregning, der udføres på tabelkolonnen i stedet for søgeprædikatet. I begge tilfælde kan SQL Server ikke bruge en indekssøgning i tabelkolonnen og skal bruge en scanning i stedet.
Dette kan dukke op i tilsyneladende uskyldig kode, og et almindeligt eksempel er at bruge en datoberegning. Hvis du har en tabel, der gemmer kundernes alder, og du vil udføre en beregning for at se, hvor mange der er 21 år eller ældre i dag, kan du skrive kode som denne:
WHERE DATEADD (YEAR, 21, [MyTable].[BirthDate]) <= @today;
Med denne kode er beregningen på tabelkolonnen, og en indekssøgning kan derfor ikke bruges, hvilket resulterer i et usøgeligt udtryk (teknisk kendt som et ikke-SARG-bart udtryk) og en tabel/clustered indeksscanning. Dette kan løses ved at flytte beregningen til den anden side af operatoren:
WHERE [MyTable].[BirthDate] <= DATEADD (YEAR, -21, @today);
Med hensyn til hvornår en grundlæggende kolonnesammenligning kræver en datatypekonvertering, der kan forårsage en implicit konvertering, skrev min kollega Jonathan Kehayias et fremragende blogindlæg, der sammenligner enhver kombination af datatyper og noterer, hvornår en implicit konvertering vil være påkrævet.
Oversigt
Gå ikke i fælden med at tro, at overdreven PAGEIOLATCH_XX ventetider er forårsaget af I/O-undersystemet. Min erfaring er, at de normalt er forårsaget af noget, der har med SQL Server at gøre, og det var her, jeg ville begynde at fejlfinde.
Hvad angår generel ventestatistik, kan du finde mere information om brugen af dem til fejlfinding af ydeevne i:
- Min SQLskills blogindlægsserie, der starter med Vent-statistikker, eller fortæl mig venligst, hvor det gør ondt
- Mine ventetyper og låseklasser bibliotek her
- Mit Pluralsight onlinekursus SQL Server:Fejlfinding af ydeevne ved hjælp af ventestatistik
- SQL Sentry
I den næste artikel i serien vil jeg diskutere en anden ventetype, der er en almindelig årsag til knæfaldsreaktioner. Indtil da, god fejlfinding!