At være ansvarlig for udførelsen af SQL Server kan være en skræmmende opgave. Der er mange områder, som vi skal overvåge og forstå. Vi forventes også at være i stand til at være på toppen af alle disse målinger og vide, hvad der sker på vores servere til enhver tid. Jeg kan godt lide at spørge DBA'er, hvad det første de tænker på, når de hører udtrykket "tuning SQL Server;" det overvældende svar, jeg får, er "forespørgselsjustering." Jeg er enig i, at tuning af forespørgsler er meget vigtigt og er en uendelig opgave, som vi står over for, fordi arbejdsbelastningen ændrer sig konstant.
Der er dog mange andre aspekter at overveje, når du tænker på SQL Server-ydeevne. Der er mange indstillinger på instans-, OS- og databaseniveau, der skal justeres fra standardindstillingerne. At være konsulent giver mig mulighed for at arbejde i mange forskellige brancher og få eksponering for alle mulige præstationsproblemer. Når jeg arbejder med en ny klient, forsøger jeg altid at udføre en sundhedsaudit af serveren for at vide, hvad jeg har med at gøre. Mens jeg udførte disse revisioner, har en af de ting, som jeg gentagne gange har fundet ud af, været overdreven læse- og skriveforsinkelse på de diske, hvor SQL Server-data og logfiler findes.
Læse-/skriveforsinkelse
For at se dine diskforsinkelser i SQL Server kan du hurtigt og nemt forespørge DMV sys.dm_io_virtual_file_stats . Denne DMV accepterer to parametre:database_id og fil_id . Det fantastiske er, at du kan sende NULL som både værdier og returnere latenserne for alle filer for alle databaser. Outputkolonnerne inkluderer:
- database_id
- fil_id
- sample_ms
- antal_af_læsninger
- antal_af_bytes_læste
- io_stall_read_ms
- antal_of_writes
- antal_of_bytes_skrevne
- io_stall_write_ms
- io_stall
- størrelse_på_disk_bytes
- fil_håndtag
Som du kan se fra kolonnelisten, er der virkelig nyttig information, som denne DMV henter, men kører bare SELECT * FROM sys.dm_io_virtual_file_stats(NULL, NULL); hjælper ikke meget, medmindre du har lært dine database_id'er udenad og kan lave noget matematik i dit hoved.
Når jeg forespørger på filstatistikken, bruger jeg en forespørgsel fra Paul Randals blogindlæg, "Sådan undersøger man IO-undersystemforsinkelser fra SQL Server." Dette script gør kolonnenavnene nemmere at læse, inkluderer det drev, filen er på, databasenavnet og stien til filen.
Ved at forespørge på denne DMV kan du nemt se, hvor I/O-hotspots er for dine filer. Du kan se, hvor de højeste skrive- og læseforsinkelser er, og hvilke databaser der er synderne. At vide dette vil give dig mulighed for at begynde at se på indstillingsmulighederne for de specifikke databaser. Dette kunne omfatte indeksjustering, kontrol for at se, om bufferpuljen er under hukommelsestryk, muligvis flytning af databasen til en hurtigere del af I/O-undersystemet eller muligvis partitionering af databasen og spredning af filgrupperne på tværs af andre LUN'er.
Så du kører forespørgslen, og den returnerer masser af værdier i ms for latency – hvilke værdier er okay, og hvilke er dårlige?
Hvilke værdier er gode eller dårlige?
Hvis du spørger SQLskills, vil vi fortælle dig noget i retning af:
- Fremragende:<1ms
- Meget god:<5ms
- Godt:5 – 10 ms
- Dårlig:10 – 20 ms
- Dårlig:20 – 100 ms
- Rigtig dårligt:100 – 500 ms
- OMG!:> 500ms
Hvis du laver en Bing-søgning, vil du finde artikler fra Microsoft, der giver anbefalinger, der ligner:
- Godt:<10 ms
- Okay:10 – 20 ms
- Dårlig:20 – 50 ms
- Alvorligt dårligt:> 50ms
Som du kan se, er der nogle små variationer i tallene, men konsensus er, at alt over 20 ms kan betragtes som besværligt. Når det er sagt, kan din gennemsnitlige skriveforsinkelse være 20 ms, og det er 100 % acceptabelt for din organisation, og det er okay. Du skal kende generelle I/O-forsinkelser for dit system, så du, når tingene bliver dårlige, ved, hvad normalt er.
Mine læse-/skriveforsinkelser er dårlige, hvad skal jeg gøre?
Hvis du opdager, at læse- og skriveforsinkelser er dårlige på din server, er der flere steder, du kan begynde at lede efter problemer. Dette er ikke en udtømmende liste, men en vejledning om, hvor du skal starte.
- Analyser din arbejdsbyrde. Er din indekseringsstrategi korrekt? Ikke at have de rigtige indekser vil føre til, at meget flere data bliver læst fra disken. Scanner i stedet for søger.
- Er dine statistikker opdaterede? Dårlige statistikker kan give dårlige valg for udførelsesplaner.
- Har du problemer med parametersniffing, der forårsager dårlige eksekveringsplaner?
- Er bufferpuljen under hukommelsestryk, for eksempel fra en oppustet plancache?
- Er der nogen netværksproblemer? Fungerer dit SAN-stof korrekt? Få din lageringeniør til at validere pathing og netværk.
- Flyt hotspots til forskellige lagerarrays. I nogle tilfælde kan det være en enkelt database eller blot nogle få databaser, der forårsager alle problemerne. At isolere dem til et andet sæt diske eller hurtigere high-end diske såsom SSD'er kan være den bedste logiske løsning.
- Kan du partitionere databasen for at flytte besværlige tabeller til en anden disk for at sprede belastningen?
Ventstatistik
Ligesom overvågning af din filstatistik kan overvågning af dine ventestatistikker fortælle dig meget om flaskehalse i dit miljø. Vi er heldige at have endnu en fantastisk DMV (sys.dm_os_wait_stats ) at vi kan forespørge, der vil trække alle tilgængelige venteoplysninger indsamlet siden sidste genstart eller siden sidste gang, ventetiden blev nulstillet; der er også ventetider relateret til diskens ydeevne. Denne DMV returnerer vigtig information, herunder:
- wait_type
- waiting_task_count
- ventetid_ms
- max_wait_time_ms
- signal_wait_time_ms
Forespørgsel på denne DMV på min SQL Server 2014-maskine returnerede 771 ventetyper. SQL Server venter altid på noget, men der er mange ventetider, som vi ikke skal bekymre os om. Af denne grund bruger jeg en anden forespørgsel fra Paul Randal; hans blogindlæg, "Vent statistik, eller fortæl mig venligst, hvor det gør ondt," har et fremragende manuskript, der udelukker en masse af de ventetider, vi egentlig er ligeglade med. Paul opremser også mange af de almindelige problematiske ventetider samt tilbyder vejledning til de almindelige ventetider.
Hvorfor er ventestatistikker vigtige?
Overvågning af høje ventetider for visse begivenheder vil fortælle dig, når der er problemer i gang. Du har brug for en baseline for at vide, hvad der er normalt, og hvornår tingene overstiger en tærskel eller smerteniveau. Hvis du har en rigtig høj PAGEIOLATCH_XX så ved du, at SQL Server skal vente på, at en dataside bliver læst fra disken. Dette kan være disk, hukommelse, ændring af arbejdsbelastning eller en række andre problemer.
En nylig klient, jeg arbejdede med, så noget meget usædvanlig adfærd. Da jeg oprettede forbindelse til databaseserveren og var i stand til at observere serveren under en arbejdsbelastning, begyndte jeg straks at tjekke filstatistik, ventestatistik, hukommelsesudnyttelse, tempdb-brug osv. En ting, der straks skilte sig ud var WRITELOG er den mest udbredte ventetid. Jeg ved, at denne ventetid har at gøre med en log flush til disk og mindede mig om Pauls serie om Trimning af transaktionslogfedtet. Høj WRITELOG ventetider kan normalt identificeres ved høje skriveforsinkelser for transaktionslogfilen. Så jeg brugte derefter mit filstatistikscript til at gennemgå læse- og skriveforsinkelserne på disken. Jeg var derefter i stand til at se høj skriveforsinkelse på datafilen, men ikke min logfil. Når du ser på WRITELOG det var en høj ventetid, men ventetiden i ms var ekstremt lav. Men noget i det andet indlæg i Pauls serie var stadig i mit hoved. Jeg burde se på indstillingerne for automatisk vækst for databasen bare for at udelukke "Død med tusinde snit". Da jeg kiggede på databasens egenskaber, så jeg, at datafilen var indstillet til automatisk vækst med 1 MB og transaktionsloggen indstillet til automatisk vækst med 10%. Begge filer havde næsten 0 ubrugt plads. Jeg delte med klienten, hvad jeg fandt, og hvordan dette dræbte deres præstation. Vi lavede hurtigt den passende ændring, og testen gik fremad, i øvrigt meget bedre. Det er desværre ikke den eneste gang, jeg er stødt på netop dette problem. En anden gang en database var 66 GB i størrelse, kom den dertil med 1 MB vækst.
Optagelse af dine data
Mange dataprofessionelle har oprettet processer til at fange fil- og ventestatistikker på en regelmæssig basis til analyse. Da ventestatistikken er kumulativ, vil du gerne fange dem og sammenligne deltaerne mellem forskellige tidspunkter på dagen eller før og efter, at bestemte processer er kørt. Dette er ikke for kompliceret, og der er adskillige blogindlæg tilgængelige, hvor folk deler, hvordan de opnåede dette. Den vigtige del er at måle disse data, så du kan overvåge dem. Hvordan ved du i dag, at tingene er bedre eller værre på din databaseserver, medmindre du kender dataene fra i går?
Hvordan kan SQL Sentry hjælpe?
Jeg er glad for, at du spurgte! SQL Sentry Performance Advisor bringer latency og venter foran og i midten på dashboardet. Eventuelle anomalier er lette at få øje på; du kan skifte til historisk tilstand og se den tidligere tendens og sammenligne den med tidligere perioder. Dette kan vise sig at være uvurderligt, når man analyserer disse "hvad skete der?" øjeblikke. Alle har fået det opkald:"I går omkring kl. 15.00 så systemet ud til at fryse, kan du fortælle os, hvad der skete?" Um, selvfølgelig, lad mig trække Profiler op og gå tilbage i tiden. Hvis du har et overvågningsværktøj som Performance Advisor, vil du have den historiske information lige ved hånden.
Ud over diagrammerne og graferne på dashboardet har du mulighed for at bruge indbyggede advarsler for forhold som høje diskventer, høje VLF-tal, høj CPU, lav forventet levetid for sider og mange flere. Du har også mulighed for at skabe dine egne brugerdefinerede betingelser, og du kan lære af eksemplerne på SQL Sentry-webstedet eller gennem Condition Exchange (Aaron Bertrand har blogget om dette). Jeg kom ind på alarmsiden af dette i min sidste artikel om SQL Server Agent Alerts.
På fanen Diskplads i Performance Advisor er det meget nemt at se ting som autovækstindstillinger og høje VLF-tal. Du burde vide det, men hvis du ikke gør det, er autovækst med 1 MB eller 10 % ikke den bedste indstilling. Hvis du ser disse værdier (Performance Advisor fremhæver dem for dig), kan du hurtigt notere og planlægge tidspunktet for at foretage de korrekte justeringer. Jeg elsker også, hvordan den viser Total VLF'er; for mange VLF'er kan være meget problematiske. Du bør læse Kimberlys indlæg "Transaction Log VLFs - too many or too few?" hvis du ikke allerede har gjort det.
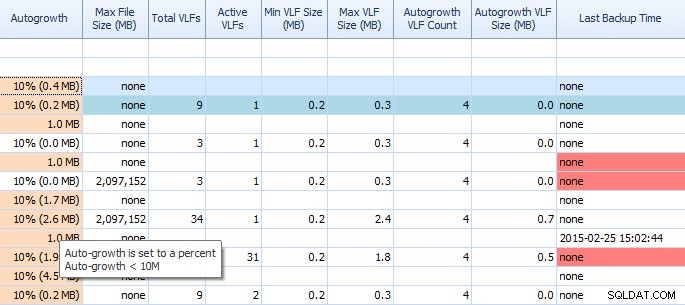 Delvist gitter på Performance Advisors fane Diskplads
Delvist gitter på Performance Advisors fane Diskplads
En anden måde, som Performance Advisor kan hjælpe, er gennem dets patenterede Disk Activity-modul. Her kan du se, at tempdb på F:oplever betydelig skriveforsinkelse; du kan se dette på de tykke røde linjer under diskens grafik. Du vil måske også bemærke, at F:er det eneste drevbogstav, hvis disk er repræsenteret med rødt; dette er en visuel tegn på, at drevet har en forkert justeret partition, hvilket kan bidrage til I/O-problemer.
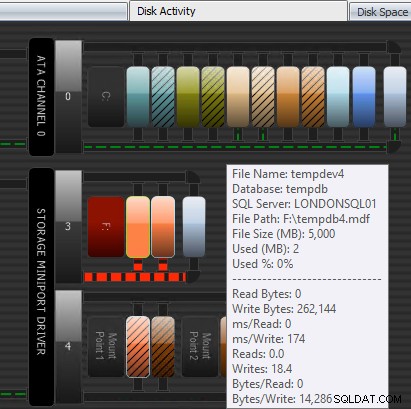 Performance Advisor Diskaktivitetsmodul
Performance Advisor Diskaktivitetsmodul
Og du kan korrelere disse oplysninger i tavlerne nedenfor – problemer er også fremhævet i tavlerne der, og tag et kig på ms/Write kolonne:
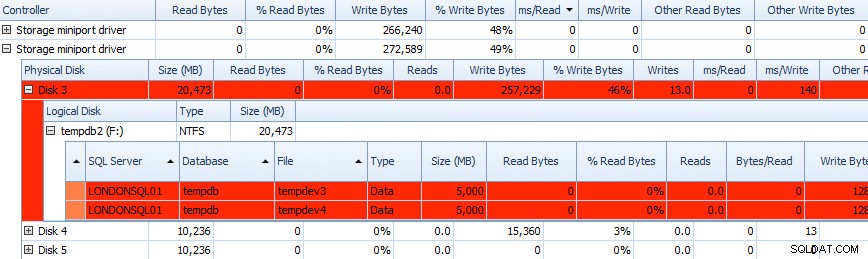 Delvis gitter af Performance Advisor Disk Activity-data
Delvis gitter af Performance Advisor Disk Activity-data
Du kan også se på disse oplysninger med tilbagevirkende kraft; hvis nogen klager over en opfattet diskflaskehals i går eftermiddags eller sidste tirsdag, kan du blot gå tilbage ved hjælp af datovælgerne i værktøjslinjen og se den gennemsnitlige gennemstrømning og latenstid for ethvert interval. Se brugervejledningen for mere information om diskaktivitetsmodulet.
Performance Advisor har også en masse indbyggede rapporter under kategorierne Performance, Blocking, Top SQL, Disk/File Space og Deadlocks. Billedet nedenfor viser dig, hvordan du kommer til Disk/File Space-rapporterne. Det er meget værdifuldt at have rapporterne blot et par museklik væk for straks at kunne grave ind og se, hvad der sker (eller foregik) på din server.
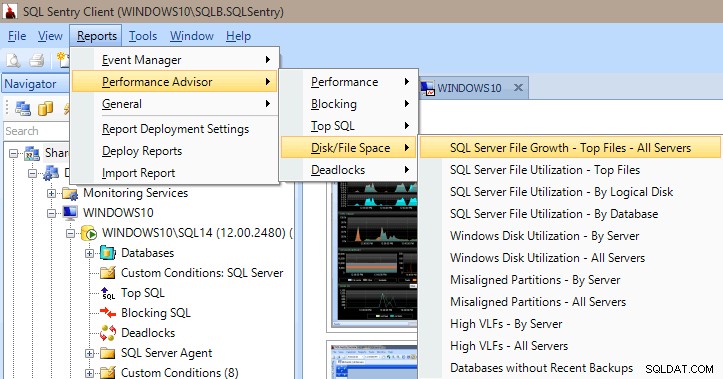 Performance Advisor-rapporter
Performance Advisor-rapporter
Oversigt
Det vigtige ved dette indlæg er at kende dine præstationsmålinger. Et almindeligt udsagn blandt dataprofessionelle er, at disken er vores #1 flaskehals. At kende filstatistikken på din server vil hjælpe dig langt med at forstå smertepunkterne på din server. I forbindelse med filstatistik er dine ventestatistikker også et godt sted at se. Mange mennesker, inklusive mig selv, starter der. At have et værktøj som SQL Sentry Performance Advisor kan drastisk hjælpe dig med at fejlfinde og finde ydeevneproblemer, før de bliver for problematiske; men hvis du ikke har et sådant værktøj, skal du blive fortrolig med sys.dm_os_wait_stats og sys.dm_io_virtual_file_stats vil tjene dig godt til at begynde at tune din server.