Fra tid til anden ser jeg nogen udtrykke et krav om at oprette et tilfældigt tal for en nøgle. Normalt er dette for at oprette en type surrogat-kunde-id eller bruger-id, der er et unikt nummer inden for et eller andet område, men som ikke udstedes sekventielt og derfor er langt mindre gætteligt end en IDENTITY værdi.
NEWID() løser gætteproblemet, men præstationsstraffen er normalt en deal-breaker, især når de er grupperet:meget bredere nøgler end heltal og sideopdelinger på grund af ikke-sekventielle værdier. NEWSEQUENTIALID() løser sideopdelingsproblemet, men er stadig en meget bred nøgle, og genindfører problemet, at du kan gætte den næste værdi (eller nyligt udstedte værdier) med et vist niveau af nøjagtighed.
Som et resultat vil de have en teknik til at generere et tilfældigt og unikt heltal. Det er ikke svært at generere et tilfældigt tal alene ved at bruge metoder som RAND() eller CHECKSUM(NEWID()) . Problemet kommer, når du skal opdage kollisioner. Lad os tage et hurtigt kig på en typisk tilgang, forudsat at vi ønsker CustomerID-værdier mellem 1 og 1.000.000:
DECLARE @rc INT =0, @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1; -- eller ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1; -- eller CONVERT(INT, RAND() * 1000000) + 1;MENS @rc =0BEGIN IF NOT EXISTS (SELECT 1 FROM dbo.Customers WHERE CustomerID =@CustomerID) BEGIN INSERT dbo.Customers(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @rc =0; SLUT
Efterhånden som bordet bliver større, bliver det ikke kun dyrere at tjekke for dubletter, men dine odds for at generere en dublet stiger også. Så denne tilgang virker måske okay, når bordet er lille, men jeg formoder, at det må gøre mere og mere ondt over tid.
En anden tilgang
Jeg er stor fan af hjælpeborde; Jeg har skrevet offentligt om kalendertabeller og taltabeller i et årti og brugt dem i meget længere tid. Og dette er et tilfælde, hvor jeg tror, at en forududfyldt tabel kunne være rigtig praktisk. Hvorfor stole på at generere tilfældige tal under kørsel og håndtere potentielle dubletter, når du kan udfylde alle disse værdier på forhånd og vide – med 100 % sikkerhed, hvis du beskytter dine tabeller mod uautoriseret DML – at den næste værdi, du vælger, aldrig har været brugt før?
CREATE TABLE dbo.RandomNumbers1( RowID INT, Value INT, --UNIQUE, PRIMARY KEY (RowID, Value));;WITH x AS ( SELECT TOP (1000000) s1.[object_id] FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2 ORDER BY s1.[object_id])INSERT dbo.RandomNumbers(RandomNumbers(Row)_SELECTr, Value ) OVER (ORDER BY [object_id]), n =ROW_NUMBER() OVER (ORDER BY NEWID())FRA xORDER BY r;
Denne population tog 9 sekunder at oprette (i en VM på en bærbar computer) og optog omkring 17 MB på disken. Dataene i tabellen ser således ud:
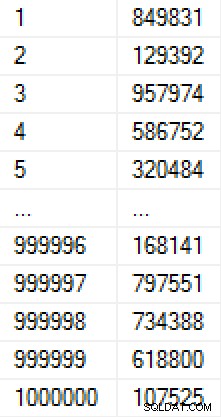
(Hvis vi var bekymrede for, hvordan tallene blev udfyldt, kunne vi tilføje en unik begrænsning på kolonnen Værdi, som ville gøre tabellen til 30 MB. Havde vi anvendt sidekomprimering, ville det have været henholdsvis 11 MB eller 25 MB. )
Jeg oprettede en anden kopi af tabellen og udfyldte den med de samme værdier, så jeg kunne teste to forskellige metoder til at udlede den næste værdi:
CREATE TABLE dbo.RandomNumbers2( RowID INT, Value INT, -- UNIK PRIMARY KEY (RowID, Value)); INDSÆT dbo.RandomNumbers2(RowID, Value) SELECT RowID, Value FROM dbo.RandomNumbers1;
Nu, når som helst vi ønsker et nyt tilfældigt tal, kan vi bare springe et ud af stakken af eksisterende numre og slette det. Dette forhindrer os i at skulle bekymre os om dubletter og giver os mulighed for at trække tal - ved hjælp af et klynget indeks - der faktisk allerede er i tilfældig rækkefølge. (Strengt taget behøver vi ikke slette tallene, som vi bruger dem; vi kunne tilføje en kolonne for at angive, om en værdi er blevet brugt – dette ville gøre det nemmere at genindsætte og genbruge denne værdi i tilfælde af, at en kunde senere bliver slettet, eller noget går galt uden for denne transaktion, men før de er fuldt oprettet.)
DECLARE @holding TABLE(KundeID INT); SLET TOP (1) dbo.RandomNumbers1OUTPUT slettet.Værdi INTO @holding; INSERT dbo.Customers(CustomerID, ...andre columns...) SELECT CustomerID, ...andre params... FROM @holding;
Jeg brugte en tabelvariabel til at holde det mellemliggende output, fordi der er forskellige begrænsninger med komponerbar DML, der kan gøre det umuligt at indsætte i Kunder-tabellen direkte fra DELETE (for eksempel tilstedeværelsen af fremmednøgler). Men i erkendelse af, at det ikke altid vil være muligt, ønskede jeg også at teste denne metode:
SLET TOP (1) dbo.RandomNumbers2 OUTPUT slettet.Value, ...andre params... INTO dbo.Customers(CustomerID, ...other columns...);
Bemærk, at ingen af disse løsninger virkelig garanterer tilfældig rækkefølge, især hvis tabellen med tilfældige tal har andre indekser (såsom et unikt indeks i kolonnen Værdi). Der er ingen måde at definere en ordre for en DELETE ved hjælp af TOP; fra dokumentationen:
Så hvis du vil garantere tilfældig bestilling, kan du gøre sådan noget i stedet:
DECLARE @holding TABLE(KundeID INT);;WITH x AS (VÆLG TOP (1) Værdi FRA dbo.RandomNumbers2 BESTIL EFTER RækkeID)DELETE x OUTPUT slettet.Værdi INTO @holding; INSERT dbo.Customers(CustomerID, ...andre columns...) SELECT CustomerID, ...andre params... FROM @holding;
En anden overvejelse her er, at kundetabellerne til disse test har en klynget primær nøgle i kolonnen Kunde-ID; dette vil helt sikkert føre til sideopdelinger, når du indsætter tilfældige værdier. I den virkelige verden, hvis du havde dette krav, ville du sandsynligvis ende med at gruppere dig i en anden kolonne.
Bemærk, at jeg også har udeladt transaktioner og fejlhåndtering her, men disse bør også tages i betragtning for produktionskoden.
Performancetest
For at tegne nogle realistiske præstationssammenligninger oprettede jeg fem lagrede procedurer, der repræsenterer følgende scenarier (testning af hastighed, fordeling og kollisionsfrekvens for de forskellige tilfældige metoder samt hastigheden af at bruge en foruddefineret tabel med tilfældige tal):
- Kørselsgenerering ved hjælp af
CHECKSUM(NEWID()) - Kørselsgenerering ved hjælp af
CRYPT_GEN_RANDOM() - Kørselsgenerering ved hjælp af
RAND() - Foruddefineret taltabel med tabelvariabel
- Foruddefineret taltabel med direkte indsættelse
De bruger en logningstabel til at spore varigheden og antallet af kollisioner:
CREATE TABLE dbo.CustomerLog( LogID INT IDENTITY(1,1) PRIMARY KEY, pid INT, kollisioner INT, varighed INT -- mikrosekunder);
Koden til procedurerne følger (klik for at vise/skjule):
/* Runtime using CHECKSUM(NEWID()) */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Checksum]AS BEGIN SET NOCOUNT ON; DECLARE @startDATETIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BEGIN IF NOT EXISTS (VÆLG 1 FRA dbo.Customers_Runtime_Checksum WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_Checksum(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CHECKSUM(NEWID())) % 1000000 + 1, @collisions +=1, @rc =0; END END SELECT @varighed =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 1, @collisions, @duration;ENDGO /* runtime using CRYPT_GEN_RANDOM() */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_CryptGen]AS BEGIN SET NOCOUNT ON; DECLARE @startDATOTIME2(7) =SYSDATETIME(), @duration INT, @CustomerID INT =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @collisions INT =0, @rc INT =0; WHILE @rc =0 BEGIN IF NOT EXISTS (VÆLG 1 FRA dbo.Customers_Runtime_CryptGen WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_CryptGen(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =ABS(CONVERT(INT,CRYPT_GEN_RANDOM(3))) % 1000000 + 1, @collisions +=1, @rc =0; END END SELECT @varighed =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 2, @collisions, @duration;ENDGO /* runtime using RAND() */ CREATE PROCEDURE [dbo].[AddCustomer_Runtime_Rand]ASBEGIN SET NOCOUNT ON; DEKLARE @startDATOTIME2(7) =SYSDATETIME(), @varighed INT, @KundeID INT =KONVERTER(INT, RAND() * 1000000) + 1, @kollisions INT =0, @rc INT =0; WHILE @rc =0 BEGIN IF NOT EXISTS (VÆLG 1 FRA dbo.Customers_Runtime_Rand WHERE CustomerID =@CustomerID ) BEGIN INSERT dbo.Customers_Runtime_Rand(CustomerID) SELECT @CustomerID; SET @rc =1; END ELSE BEGIN SELECT @CustomerID =CONVERT(INT, RAND() * 1000000) + 1, @collisions +=1, @rc =0; END END SELECT @varighed =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, collisions, duration) SELECT 3, @collisions, @duration;ENDGO /* foruddefineret ved hjælp af en tabelvariabel */ CREATE PROCEDURE [dbo].[AddCustomer_Predefined_TableVariable]ASBEGIN SET NOCOUNT ON; DECLARE @start DATOTIME2(7) =SYSDATETIME(), @varighed INT; DECLARE @holding TABLE(CustomerID INT); SLET TOP (1) dbo.RandomNumbers1 OUTPUT slettet.Værdi INTO @holding; INSERT dbo.Customers_Predefined_TableVariable(CustomerID) SELECT CustomerID FROM @holding; VÆLG @varighed =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, duration) SELECT 4, @duration;ENDGO /* foruddefineret ved hjælp af en direkte indsættelse */ CREATE PROCEDURE [dbo].[AddCustomer_Predefined_Direct]ASBEGIN SET NOCOUNT ON; DECLARE @start DATOTIME2(7) =SYSDATETIME(), @varighed INT; SLET TOP (1) dbo.RandomNumbers2 OUTPUT slettet.Value INTO dbo.Customers_Predefined_Direct; VÆLG @varighed =DATEDIFF(MICROSECOND, @start, CONVERT(DATETIME2(7),SYSDATETIME())); INSERT dbo.CustomerLog(pid, duration) SELECT 5, @duration;ENDGO
Og for at teste dette ville jeg køre hver lagret procedure 1.000.000 gange:
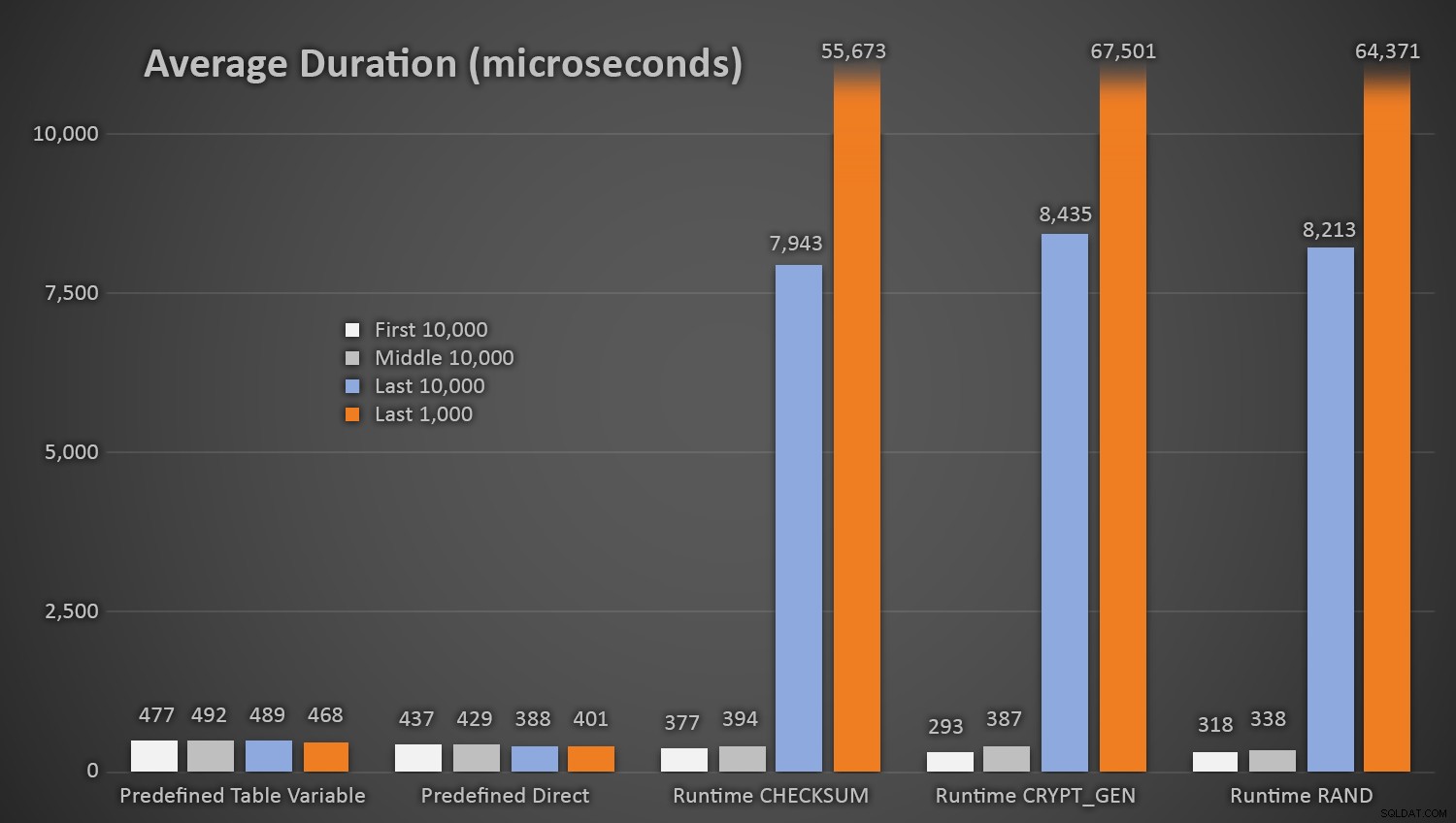
EXEC dbo.AddCustomer_Runtime_Checksum;EXEC dbo.AddCustomer_Runtime_CryptGen;EXEC dbo.AddCustomer_Runtime_Rand;EXEC dbo.AddCustomer_Predefined_TableVariable;EXEC dbo.AddCustomer_0>0>0Ikke overraskende tog metoderne ved hjælp af den foruddefinerede tabel med tilfældige tal lidt længere *i starten af testen*, da de skulle udføre både læse- og skrive-I/O hver gang. Husk på, at disse tal er i mikrosekunder , her er de gennemsnitlige varigheder for hver procedure med forskellige intervaller undervejs (i gennemsnit over de første 10.000 henrettelser, de mellemste 10.000 henrettelser, de sidste 10.000 henrettelser og de sidste 1.000 henrettelser):
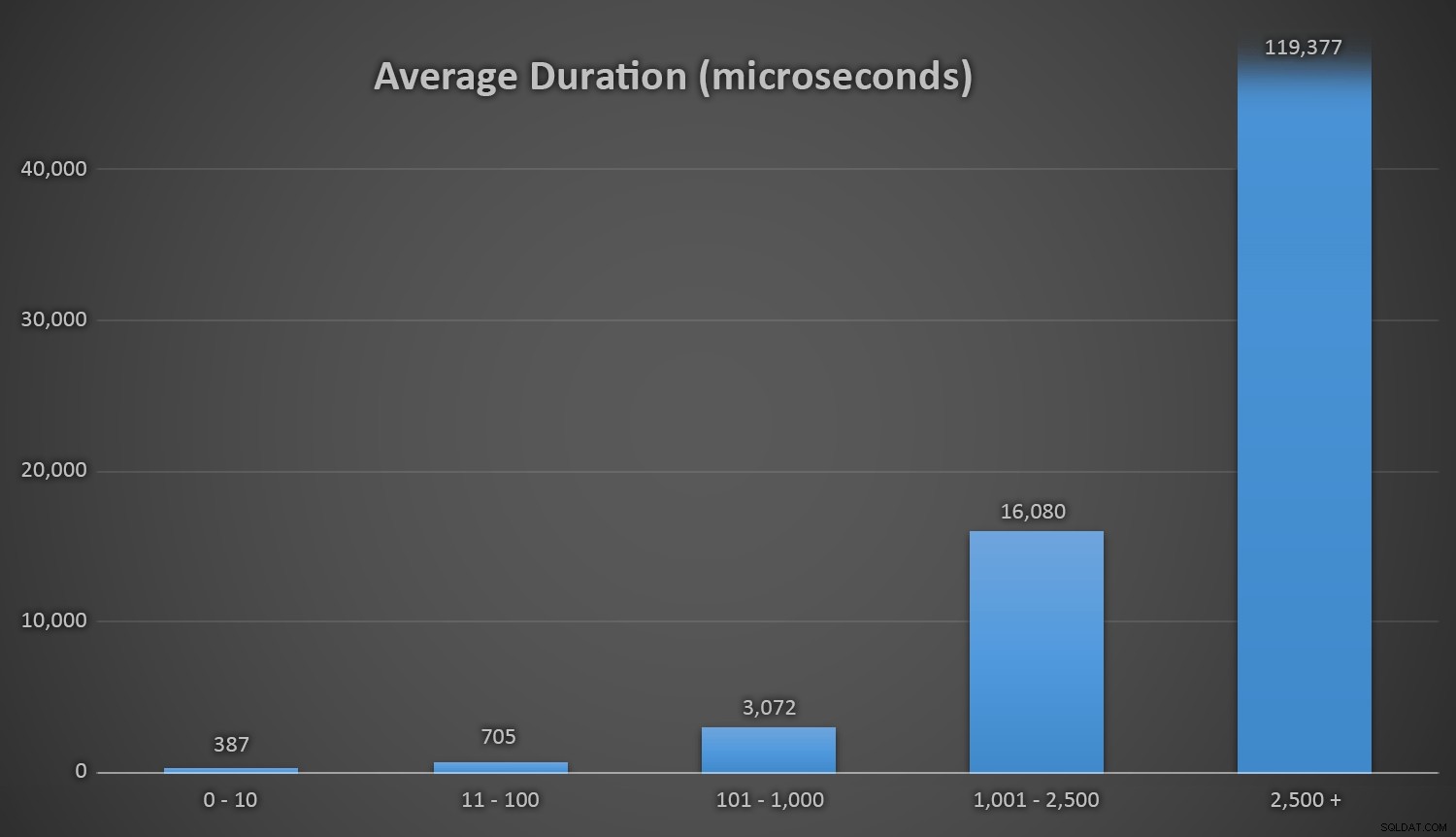
Gennemsnitlig varighed (i mikrosekunder) af tilfældig generering ved brug af forskellige tilgangeDette fungerer godt for alle metoder, når der er få rækker i Kunder-tabellen, men efterhånden som tabellen bliver større og større, stiger omkostningerne ved at tjekke det nye tilfældige tal mod de eksisterende data ved hjælp af runtime-metoderne betydeligt, både på grund af øget I /O og også fordi antallet af kollisioner stiger (tvinger dig til at prøve og prøve igen). Sammenlign den gennemsnitlige varighed, når du er i følgende intervaller af kollisionstællinger (og husk, at dette mønster kun påvirker runtime-metoderne):
Gennemsnitlig varighed (i mikrosekunder) under forskellige kollisionsintervallerJeg ville ønske, at der var en enkel måde at tegne varighed på i forhold til kollisionsantal. Jeg vil efterlade dig med denne godbid:på de sidste tre indsættelser skulle de følgende runtime-metoder udføre så mange forsøg, før de endelig faldt over det sidste unikke ID, de ledte efter, og så lang tid tog det:
| Antal kollisioner | Varighed (mikrosekunder) | ||
|---|---|---|---|
| CHECKSUM(NEWID()) | 3. til sidste række | 63.545 | 639.358 |
| 2. til sidste række | 164.807 | 1.605.695 | |
| Sidste række | 30.630 | 296.207 | |
| CRYPT_GEN_RANDOM() | 3. til sidste række | 219.766 | 2.229.166 |
| 2. til sidste række | 255.463 | 2.681.468 | |
| Sidste række | 136.342 | 1.434.725 | |
| RAND() | 3. til sidste række | 129.764 | 1.215.994 |
| 2. til sidste række | 220.195 | 2.088.992 | |
| Sidste række | 440.765 | 4.161.925 | |
For lang varighed og kollisioner nær slutningen af linjen
Det er interessant at bemærke, at den sidste række ikke altid er den, der giver det højeste antal kollisioner, så dette kan begynde at være et reelt problem længe før du har brugt mere end 999.000 værdier.
En anden overvejelse
Du vil måske overveje at konfigurere en form for advarsel eller meddelelse, når RandomNumbers-tabellen begynder at komme under et vist antal rækker (på hvilket tidspunkt du kan genudfylde tabellen med et nyt sæt fra 1.000.001 – 2.000.000, for eksempel). Du ville være nødt til at gøre noget lignende, hvis du genererede tilfældige tal i farten - hvis du holder det inden for et interval på 1 - 1.000.000, så skal du ændre koden for at generere tal fra et andet område, når du først har har brugt alle disse værdier.
Hvis du bruger metoden tilfældigt tal ved runtime, så kan du undgå denne situation ved konstant at ændre den puljestørrelse, hvorfra du trækker et tilfældigt tal (som også burde stabilisere og drastisk reducere antallet af kollisioner). For eksempel i stedet for:
DECLARE @CustomerID INT =ABS(CHECKSUM(NEWID())) % 1000000 + 1;
Du kan basere puljen på antallet af rækker, der allerede er i tabellen:
DECLARE @total INT =1000000 + ISNULL( (SELECT SUM(row_count) FROM sys.dm_db_partition_stats WHERE [object_id] =OBJECT_ID('dbo.Customers') AND index_id =1),0);
Nu er din eneste reelle bekymring, når du nærmer dig den øvre grænse for INT …
Bemærk:Jeg skrev også for nylig et tip om dette på MSSQLTips.com.