Når du er dybt involveret i fejlfinding af et problem i SQL Server, vil du nogle gange have lyst til at vide, i hvilken rækkefølge forespørgsler kørte. Jeg ser dette med mere komplicerede lagrede procedurer, der indeholder lag af logik, eller i scenarier, hvor der er en masse overflødig kode. Udvidede begivenheder er et naturligt valg her, da det typisk bruges til at fange information om udførelse af forespørgsler. Du kan ofte bruge session_id og tidsstemplet til at forstå rækkefølgen af begivenheder, men der er en sessionsmulighed for XE, der er endnu mere pålidelig:Spor årsagssammenhæng.
Når du aktiverer Spor årsagssammenhæng for en session, tilføjer den et GUID og et sekvensnummer til hver hændelse, som du derefter kan bruge til at gå gennem den rækkefølge, som hændelser fandt sted. Overhead er minimal, og det kan være en betydelig tidsbesparelse i mange fejlfindingsscenarier.
Konfigurer
Ved at bruge WideWorldImporters-databasen opretter vi en lagret procedure til brug:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO
Så opretter vi en begivenhedssession:
CREATE EVENT SESSION [TrackQueries] ON SERVER
ADD EVENT sqlserver.sp_statement_completed(
WHERE ([sqlserver].[is_system]=(0))),
ADD EVENT sqlserver.sql_statement_completed(
WHERE ([sqlserver].[is_system]=(0)))
ADD TARGET package0.event_file
(
SET filename=N'C:\temp\TrackQueries',max_file_size=(256)
)
WITH
(
MAX_MEMORY = 4096 KB,
EVENT_RETENTION_MODE = ALLOW_SINGLE_EVENT_LOSS,
MAX_DISPATCH_LATENCY = 30 SECONDS,
MAX_EVENT_SIZE = 0 KB,
MEMORY_PARTITION_MODE = NONE,
TRACK_CAUSALITY = ON,
STARTUP_STATE = OFF
); Vi kommer også til at køre ad-hoc-forespørgsler, så vi fanger både sp_statement_completed (udsagn afsluttet inden for en lagret procedure) og sql_statement_completed (udførte udsagn, der ikke er inden for en lagret procedure). Bemærk, at TRACK_CAUSALITY-indstillingen for sessionen er sat til TIL. Igen er denne indstilling specifik for begivenhedssessionen og skal aktiveres, før den startes. Du kan ikke aktivere indstillingen med det samme, ligesom du kan tilføje eller fjerne begivenheder og mål, mens sessionen kører.
For at starte begivenhedssessionen gennem brugergrænsefladen skal du blot højreklikke på den og vælge Start session.
Test
I Management Studio kører vi følgende kode:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan'; Her er vores XE-output:

Bemærk, at den første udførte forespørgsel, som er fremhævet, er SELECT @@SPID og har en GUID på FDCCB1CF-CA55-48AA-8FBA-7F5EBF870674. Vi udførte ikke denne forespørgsel, den fandt sted i baggrunden, og selvom XE-sessionen er sat op til at filtrere systemforespørgsler fra, bliver denne – uanset årsagen – stadig fanget.
De næste fire linjer repræsenterer den kode, vi faktisk kørte. Der er de to forespørgsler fra den lagrede procedure, selve den lagrede procedure og så vores ad-hoc forespørgsel. Alle har den samme GUID, ACBFFD99-2400-4AFF-A33F-351821667B24. Ved siden af GUID'et er sekvens-id'et (seq), og forespørgslerne er nummereret fra én til fire.
I vores eksempel brugte vi ikke GO til at adskille erklæringerne i forskellige batches. Bemærk, hvordan outputtet ændres, når vi gør det:
EXEC [Sales].[usp_CustomerTransactionInfo] 490;
GO
SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = 'Naseem Radan';
GO

Vi har stadig det samme antal samlede rækker, men nu har vi tre GUID'er. Én for SELECT @@SPID (E8D136B8-092F-439D-84D6-D4EF794AE753), én for de tre forespørgsler, der repræsenterer den lagrede procedure (F962B9A4-0665-4802-9E6C-B217634D8787), og én for ad-hoc 5. -9702-4DE5-8467-8D7CF55B5D80).
Dette er, hvad du højst sandsynligt vil se, når du ser på data fra din applikation, men det afhænger af, hvordan applikationen fungerer. Hvis den bruger forbindelsespooling, og forbindelser nulstilles regelmæssigt (hvilket forventes), så vil hver forbindelse have sin egen GUID.
Du kan genskabe dette ved at bruge eksempel PowerShell-koden nedenfor:
while(1 -eq 1)
{
$SqlConn = New-Object System.Data.SqlClient.SqlConnection;
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;Integrated Security=True;Application Name = MyCoolApp";
$SQLConn.Open()
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT TOP 1 CustomerID FROM Sales.Customers ORDER BY NEWID();"
$SqlCmd.CommandType = [System.Data.CommandType]::Text;
$SqlReader = $SqlCmd.ExecuteReader();
$Results = New-Object System.Collections.ArrayList;
while ($SqlReader.Read())
{
$Results.Add($SqlReader.GetSqlInt32(0)) | Out-Null;
}
$SqlReader.Close();
$Value = Get-Random -InputObject $Results;
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "Sales.usp_CustomerTransactionInfo"
$SqlCmd.CommandType = [System.Data.CommandType]::StoredProcedure;
$SqlParameter = $SqlCmd.Parameters.AddWithValue("@CustomerID", $Value);
$SqlParameter.SqlDbType = [System.Data.SqlDbType]::Int;
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
$Names = New-Object System.Collections.Generic.List``1[System.String]
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $SqlConn.CreateCommand();
$SqlCmd.CommandText = "SELECT FullName FROM Application.People ORDER BY NEWID();";
$dr = $SqlCmd.ExecuteReader();
while($dr.Read())
{
$Names.Add($dr.GetString(0));
}
$SqlConn.Close();
$name = Get-Random -InputObject $Names;
$query = [String]::Format("SELECT [c].[CustomerID], [c].[CustomerName], [p].[FullName], [o].[OrderID]
FROM [Application].[People] [p]
JOIN [Sales].[Customers] [c] ON [p].[PersonID] = [c].[PrimaryContactPersonID]
JOIN [Sales].[Orders] [o] ON [c].[CustomerID] = [o].[CustomerID]
WHERE [p].[FullName] = '{0}';", $name);
$SqlConn = New-Object System.Data.SqlClient.SqlConnection
$SqlConn.ConnectionString = "Data Source=Hedwig\SQL2017;Initial Catalog=WideWorldImporters;User Id=aw_webuser;Password=12345;Application Name=AdventureWorks Online Ordering;Workstation ID=AWWEB01";
$SqlConn.Open();
$SqlCmd = $sqlconnection.CreateCommand();
$SqlCmd.CommandText = $query
$SqlCmd.ExecuteNonQuery();
$SqlConn.Close();
} Her er et eksempel på output af udvidede hændelser efter at have ladet koden køre et stykke tid:

Der er fire forskellige GUID'er til vores fem udsagn, og hvis du ser på koden ovenfor, vil du se, at der er lavet fire forskellige forbindelser. Hvis du ændrer begivenhedssessionen til at inkludere begivenheden rpc_completed, kan du se poster med exec sp_reset_connection.
Dit XE-output afhænger af din kode og din applikation; Jeg nævnte indledningsvis, at dette var nyttigt ved fejlfinding af mere komplekse lagrede procedurer. Overvej følgende eksempel:
DROP PROCEDURE IF EXISTS [Sales].[usp_CustomerTransactionInfo]; GO CREATE PROCEDURE [Sales].[usp_CustomerTransactionInfo] @CustomerID INT AS SELECT [CustomerID], SUM([AmountExcludingTax]) FROM [Sales].[CustomerTransactions] WHERE [CustomerID] = @CustomerID GROUP BY [CustomerID]; SELECT COUNT([OrderID]) FROM [Sales].[Orders] WHERE [CustomerID] = @CustomerID GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetFullCustomerInfo]; GO CREATE PROCEDURE [Sales].[usp_GetFullCustomerInfo] @CustomerID INT AS SELECT [o].[CustomerID], [o].[OrderDate], [ol].[StockItemID], [ol].[Quantity], [ol].[UnitPrice] FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID ORDER BY [o].[OrderDate] DESC; SELECT [o].[CustomerID], SUM([ol].[Quantity]*[ol].[UnitPrice]) FROM [Sales].[Orders] [o] JOIN [Sales].[OrderLines] [ol] ON [o].[OrderID] = [ol].[OrderID] WHERE [o].[CustomerID] = @CustomerID GROUP BY [o].[CustomerID] ORDER BY [o].[CustomerID] ASC; GO DROP PROCEDURE IF EXISTS [Sales].[usp_GetCustomerData]; GO CREATE PROCEDURE [Sales].[usp_GetCustomerData] @CustomerID INT AS BEGIN SELECT * FROM [Sales].[Customers] EXEC [Sales].[usp_CustomerTransactionInfo] @CustomerID EXEC [Sales].[usp_GetFullCustomerInfo] @CustomerID END GO
Her har vi to lagrede procedurer, usp_TransctionInfo og usp_GetFullCustomerInfo, som kaldes af en anden lagret procedure, usp_GetCustomerData. Det er ikke ualmindeligt at se dette, eller endda se yderligere niveauer af indlejring med lagrede procedurer. Hvis vi udfører usp_GetCustomerData fra Management Studio, ser vi følgende:
EXEC [Sales].[usp_GetCustomerData] 981;

Her forekom alle eksekveringer på den samme GUID, BF54CD8F-08AF-4694-A718-D0C47DBB9593, og vi kan se rækkefølgen af forespørgselsudførelse fra et til otte ved hjælp af seq-kolonnen. I tilfælde, hvor der kaldes flere lagrede procedurer, er det ikke ualmindeligt, at sekvens-id-værdien kommer i hundredvis eller tusindvis.
Til sidst, i det tilfælde, hvor du ser på udførelse af forespørgsler, og du har inkluderet Track Causality, og du finder en forespørgsel, der er dårligt ydende – fordi du sorterede outputtet baseret på varighed eller en anden metrik, skal du bemærke, at du kan finde den anden forespørgsler ved at gruppere på GUID:
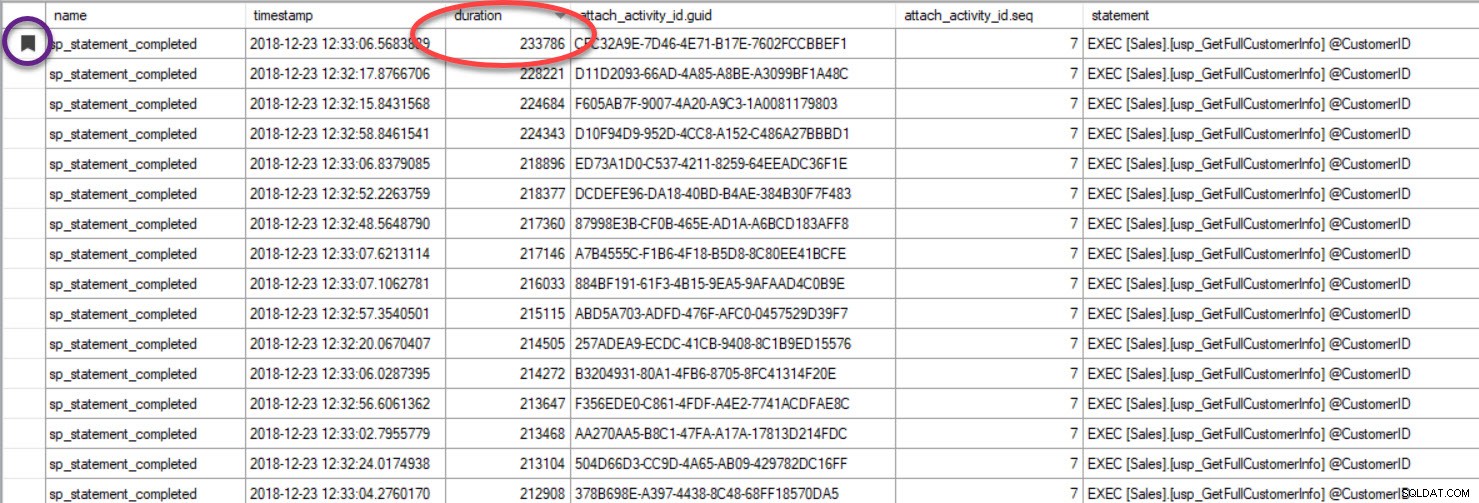
Outputtet er blevet sorteret efter varighed (højeste værdi indkredset i rødt), og jeg har markeret det (i lilla) ved at bruge knappen Skift bogmærke. Hvis vi ønsker at se de andre forespørgsler til GUID'en, grupper efter GUID (højreklik på kolonnenavnet øverst, vælg derefter Grupper efter denne kolonne), og brug derefter knappen Næste bogmærke for at vende tilbage til vores forespørgsel:
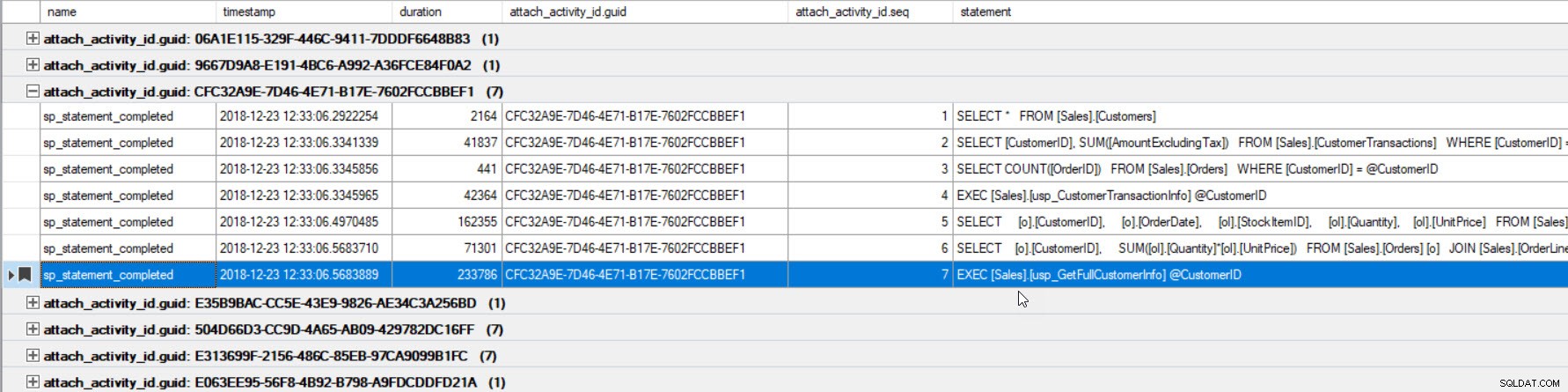
Nu kan vi se alle de forespørgsler, der blev udført inden for den samme forbindelse og i den udførte rækkefølge.
Konklusion
Indstillingen Track Causality kan være uhyre nyttig, når du skal fejlfinde forespørgselsydeevne og forsøge at forstå rækkefølgen af hændelser i SQL Server. Det er også nyttigt, når du opsætter en begivenhedssession, der bruger pair_matching-målet, for at sikre, at du matcher på det rigtige felt/handling og finder den korrekte umatchede begivenhed. Igen er dette en indstilling på sessionsniveau, så den skal anvendes, før du starter begivenhedssessionen. For en session, der kører, skal du stoppe begivenhedssessionen, aktivere indstillingen og derefter starte den igen.