Når en forespørgsel udføres, forsøger SQL Server-optimeringsværktøjet at finde den bedste forespørgselsplan baseret på eksisterende indekser og tilgængelige seneste statistikker i rimelig tid, selvfølgelig, hvis denne plan ikke allerede er gemt i servercachen. Hvis nej, udføres forespørgslen i henhold til denne plan, og planen gemmes i servercachen. Hvis planen allerede er bygget til denne forespørgsel, udføres forespørgslen i overensstemmelse med den eksisterende plan.
Vi er interesserede i følgende emne:
Under kompilering af en forespørgselsplan, ved sortering af mulige indekser, hvis serveren ikke finder det bedste indeks, markeres det manglende indeks i forespørgselsplanen, og serveren fører statistik over sådanne indekser:hvor mange gange serveren ville bruge dette indeks og hvor meget denne forespørgsel ville koste.
I denne artikel skal vi analysere disse manglende indekser – hvordan man håndterer dem.
Lad os overveje dette på et bestemt eksempel. Opret et par tabeller i vores database på en lokal og testserver:
[expand title =”Kode”]
if object_id ('orders_detail') is not null drop table orders_detail;
if object_id('orders') is not null drop table orders;
go
create table orders
(
id int identity primary key,
dt datetime,
seller nvarchar(50)
)
create table orders_detail
(
id int identity primary key,
order_id int foreign key references orders(id),
product nvarchar(30),
qty int,
price money,
cost as qty * price
)
go
with cte as
(
select 1 id union all
select id+1 from cte where id < 20000
)
insert orders
select
dt,
seller
from
(
select
dateadd(day,abs(convert(int,convert(binary(4),newid()))%365),'2016-01-01') dt,
abs(convert(int,convert(binary(4),newid()))%5)+1 seller_id
from cte
) c
left join
(
values
(1,'John'),
(2,'Mike'),
(3,'Ann'),
(4,'Alice'),
(5,'George')
) t (id,seller) on t.id = c.seller_id
option(maxrecursion 0)
insert orders_detail
select
order_id,
product,
qty,
price
from
(
select
o.id as order_id,
abs(convert(int,convert(binary(4),newid()))%5)+1 product_id,
abs(convert(int,convert(binary(4),newid()))%20)+1 qty
from orders o cross join
(
select top(abs(convert(int,convert(binary(4),newid()))%5)+1) *
from
(
values (1),(2),(3),(4),(5),(6),(7),(8)
) n(num)
) n
) c
left join
(
values
(1,'Sugar', 50),
(2,'Milk', 80),
(3,'Bread', 20),
(4,'Pasta', 40),
(5,'Beer', 100)
) t (id,product, price) on t.id = c.product_id
go [/udvid]
Strukturen er enkel og består af to borde. Den første tabel kaldes ordrer med felter som en identifikator, salgsdato og sælger. Den anden er ordredetaljer, hvor nogle varer er specificeret med pris og mængde.
Se på en simpel forespørgsel og dens plan:
select count(*) from orders o join orders_detail d on o.id = d.order_id where d.cost > 1800 go
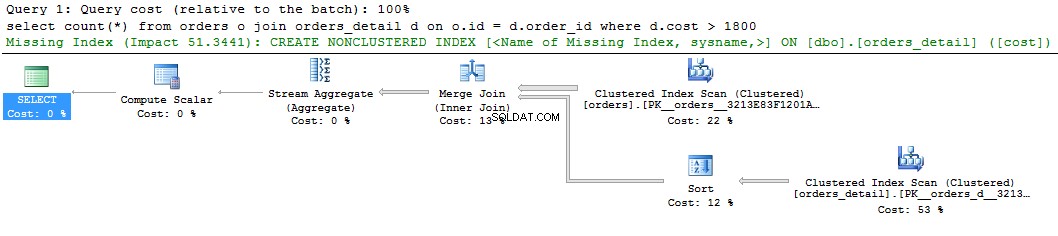
Vi kan se et grønt hint om det manglende indeks på den grafiske visning af forespørgselsplanen. Hvis du højreklikker på det og vælger "Manglende indeksdetaljer ...", vil der være teksten i det foreslåede indeks. Det eneste du skal gøre er at fjerne kommentarerne i teksten og give et navn til indekset. Scriptet er klar til at blive udført.
Vi vil ikke bygge det indeks, vi modtog, ud fra tippet fra SSMS. I stedet vil vi se, om dette indeks vil blive anbefalet af dynamiske visninger knyttet til manglende indekser. Synspunkterne er som følger:
select * from sys.dm_db_missing_index_group_stats select * from sys.dm_db_missing_index_details select * from sys.dm_db_missing_index_groups
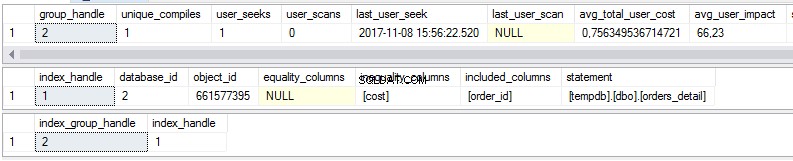
Som vi kan se, er der nogle statistikker over manglende indekser i den første visning:
- Hvor mange gange ville en søgning blive udført, hvis det foreslåede indeks eksisterede?
- Hvor mange gange ville en scanning blive udført, hvis det foreslåede indeks eksisterede?
- Seneste dato og tidspunkt, hvor vi brugte indekset
- Den aktuelle reelle pris for forespørgselsplanen uden det foreslåede indeks.
Den anden visning er indeksteksten:
- Database
- Objekt/tabel
- Sorterede kolonner
- Kolonner tilføjet for at øge indeksdækningen
Den tredje visning er kombinationen af den første og anden visning.
Derfor er det ikke svært at få et script, der ville generere et script, til at skabe manglende indekser fra disse dynamiske visninger. Scriptet er som følger:
[expand title="Kode"]
with igs as
(
select *
from sys.dm_db_missing_index_group_stats
)
, igd as
(
select *,
isnull(equality_columns,'')+','+isnull(inequality_columns,'') as ix_col
from sys.dm_db_missing_index_details
)
select --top(10)
'use ['+db_name(igd.database_id)+'];
create index ['+'ix_'+replace(convert(varchar(10),getdate(),120),'-','')+'_'+convert(varchar,igs.group_handle)+'] on '+
igd.[statement]+'('+
case
when left(ix_col,1)=',' then stuff(ix_col,1,1,'')
when right(ix_col,1)=',' then reverse(stuff(reverse(ix_col),1,1,''))
else ix_col
end
+') '+isnull('include('+igd.included_columns+')','')+' with(online=on, maxdop=0)
go
' command
,igs.user_seeks
,igs.user_scans
,igs.avg_total_user_cost
from igs
join sys.dm_db_missing_index_groups link on link.index_group_handle = igs.group_handle
join igd on link.index_handle = igd.index_handle
where igd.database_id = db_id()
order by igs.avg_total_user_cost * igs.user_seeks desc [/udvid]
For indekseffektivitet udlæses de manglende indekser. Den perfekte løsning er, når dette resultatsæt intet returnerer. I vores eksempel vil resultatsættet returnere mindst ét indeks:

Når der ikke er tid, og du ikke har lyst til at håndtere klientfejlene, udførte jeg forespørgslen, kopierede den første kolonne og udførte den på serveren. Herefter fungerede alt godt.
Jeg anbefaler at behandle oplysningerne på disse indekser bevidst. For eksempel, hvis systemet anbefaler følgende indekser:
create index ix_01 on tbl1 (a,b) include (c) create index ix_02 on tbl1 (a,b) include (d) create index ix_03 on tbl1 (a)
Og disse indekser bruges til søgningen, det er helt indlysende, at det er mere logisk at erstatte disse indekser med et, der dækker alle tre foreslåede:
create index ix_1 on tbl1 (a,b) include (c,d)
Derfor laver vi en gennemgang af de manglende indekser, inden vi implementerer dem på produktionsserveren. Selvom…. Igen, for eksempel, implementerede jeg de tabte indekser til TFS-serveren, hvilket øgede den samlede ydeevne. Det tog minimal tid at udføre denne optimering. Men da jeg skiftede fra TFS 2015 til TFS 2017, stod jeg over for det problem, at der ikke var nogen opdatering på grund af disse nye indekser. Ikke desto mindre kan de nemt findes ved masken
select * from sys.indexes where name like 'ix[_]2017%'
Nyttigt værktøj:
dbForge Index Manager – praktisk SSMS-tilføjelse til at analysere status for SQL-indekser og løse problemer med indeksfragmentering.