MySQL er let at installere og bruge, det har altid været populært blandt udviklere og systemadministratorer. På den anden side er det en anden historie at implementere et produktionsklart MySQL-miljø til en virksomhedskritisk arbejdsbyrde. Det kan være lidt af en udfordring, og kræver et indgående kendskab til databasen. I dette blogindlæg vil vi diskutere nogle af de trin, der skal tages, før vi kan overveje, at vores MySQL-implementering er produktionsklar.
Høj tilgængelighed

Hvis du hører til de heldige, der kan acceptere timevis af nedetid, kan du stoppe med at læse her og springe til næste afsnit. For 99,999 % af forretningskritiske systemer ville det ikke være acceptabelt. Derfor skal en produktionsklar implementering omfatte foranstaltninger med høj tilgængelighed. Automatisk failover af databaseforekomsterne samt et proxy-lag, som registrerer ændringer i topologi og tilstand af MySQL og dirigerer trafik i overensstemmelse hermed, ville være et hovedkrav. Der er adskillige værktøjer, som kan bruges til at bygge sådanne miljøer, for eksempel MHA, MRM eller ClusterControl.
Proxylag
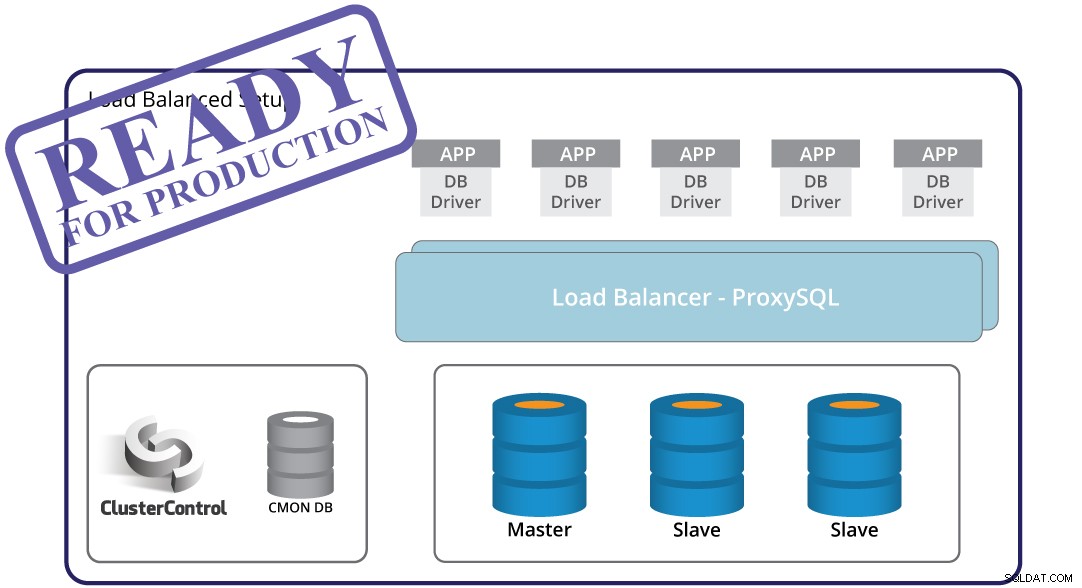
Masterfejlsdetektering, automatiseret failover og gendannelse - disse er afgørende, når man bygger en produktionsklar infrastruktur. Men i sig selv er det ikke nok. Der er stadig en applikation, som skal tilpasse sig topologiændringen udløst af failover. Det er selvfølgelig muligt at kode applikationen, så den er opmærksom på instansfejl. Dette er dog en besværlig og ufleksibel måde at håndtere topologiændringer på. Her kommer databaseproxyen - et mellemlag mellem applikation og database. En proxy kan skjule kompleksiteten af dit databaselag fra applikationen - alt, hvad applikationen gør, er at oprette forbindelse til proxy'en, og proxy'en vil tage sig af resten. Proxyen dirigerer forespørgsler til en databaseinstans, den håndterer topologiændringer og omdirigerer efter behov. En proxy kan også bruges til at implementere læse-skriveopdeling, hvilket fritager applikationen fra en mere kompleks sag til at dække. Dette skaber endnu en udfordring - hvilken proxy skal man bruge? Hvordan konfigureres det? Hvordan overvåger man det? Hvordan gør man det meget tilgængeligt, så det ikke bliver en SPOF?
ClusterControl kan hjælpe her. Det kan bruges til at implementere forskellige proxyer for at danne et proxy-lag:ProxySQL, HAProxy og MaxScale. Den forudkonfigurerer proxyer for at sikre, at de håndterer trafik korrekt. Det gør det også nemt at implementere eventuelle konfigurationsændringer, hvis du har brug for at tilpasse proxy-opsætningen til din applikation. Læse-skrive-split kan konfigureres ved hjælp af enhver af de proxyer, ClusterControl understøtter. ClusterControl overvåger også proxyerne og vil gendanne dem i tilfælde af fejl. Proxylaget kan blive et enkelt fejlpunkt, da automatisk gendannelse måske ikke er nok - for at løse det kan ClusterControl implementere Keepalved og konfigurere Virtual IP til at automatisere failover.
Sikkerhedskopier
Selvom du ikke behøver at implementere høj tilgængelighed, skal du sandsynligvis stadig bekymre dig om dine data. Sikkerhedskopiering er et must for næsten enhver produktionsdatabase. Intet andet end en sikkerhedskopi kan redde dig fra en utilsigtet DROP TABLE eller DROP SCHEMA (godt, måske en forsinket replikeringsslave, men kun i en vis periode). MySQL tilbyder flere metoder til at tage sikkerhedskopier - mysqldump, xtrabackup, forskellige typer snapshot (nogle kun tilgængelige med en bestemt hardware- eller cloud-udbyder). Det er ikke nemt at designe den korrekte backup-strategi, beslutte hvilke værktøjer der skal bruges og derefter scripte hele processen, så den udføres korrekt. Det er heller ikke raketvidenskab, og det kræver omhyggelig planlægning og test. Når først en sikkerhedskopi er taget, er du ikke færdig. Er du sikker på, at sikkerhedskopien kan gendannes, og at dataene ikke er skrald? At verificere dine sikkerhedskopier er tidskrævende, og måske ikke det mest spændende, du vil have på din todo-liste. Men det er stadig vigtigt, og det skal gøres regelmæssigt.
ClusterControl har omfattende backup- og gendannelsesfunktionalitet. Det understøtter mysqldump til logisk backup og Percona Xtrabackup til fysisk backup - disse værktøjer kan bruges i næsten alle miljøer, enten cloud eller on-premises. Det er muligt at bygge en backup-strategi med en blanding af logiske og fysiske backups, trinvise eller fulde, på en online måde.
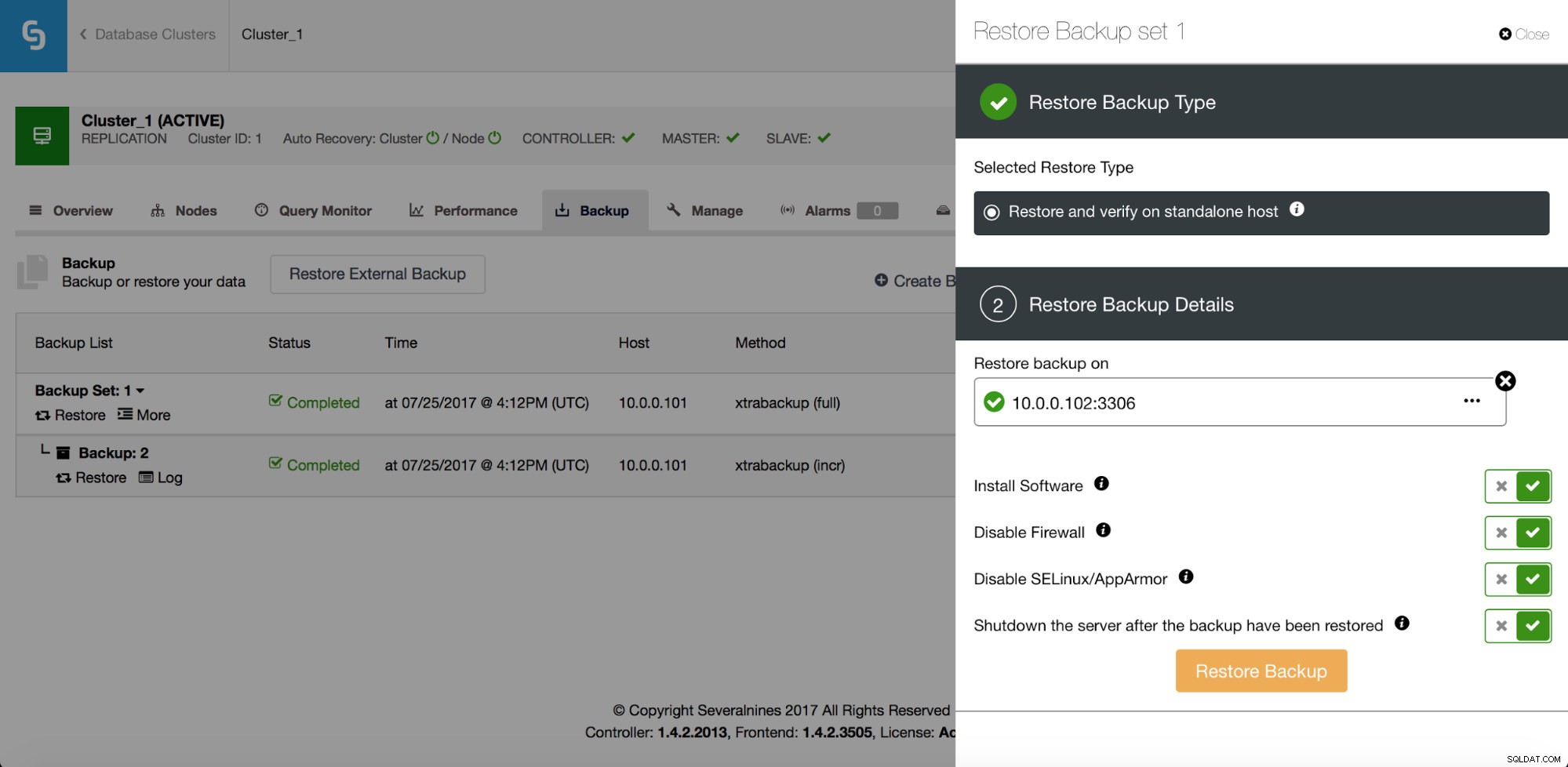
Udover gendannelse har den også muligheder for at verificere en sikkerhedskopi - f.eks. gendan den på en separat vært for at verificere, om sikkerhedskopieringsprocessen fungerer ok eller ej.
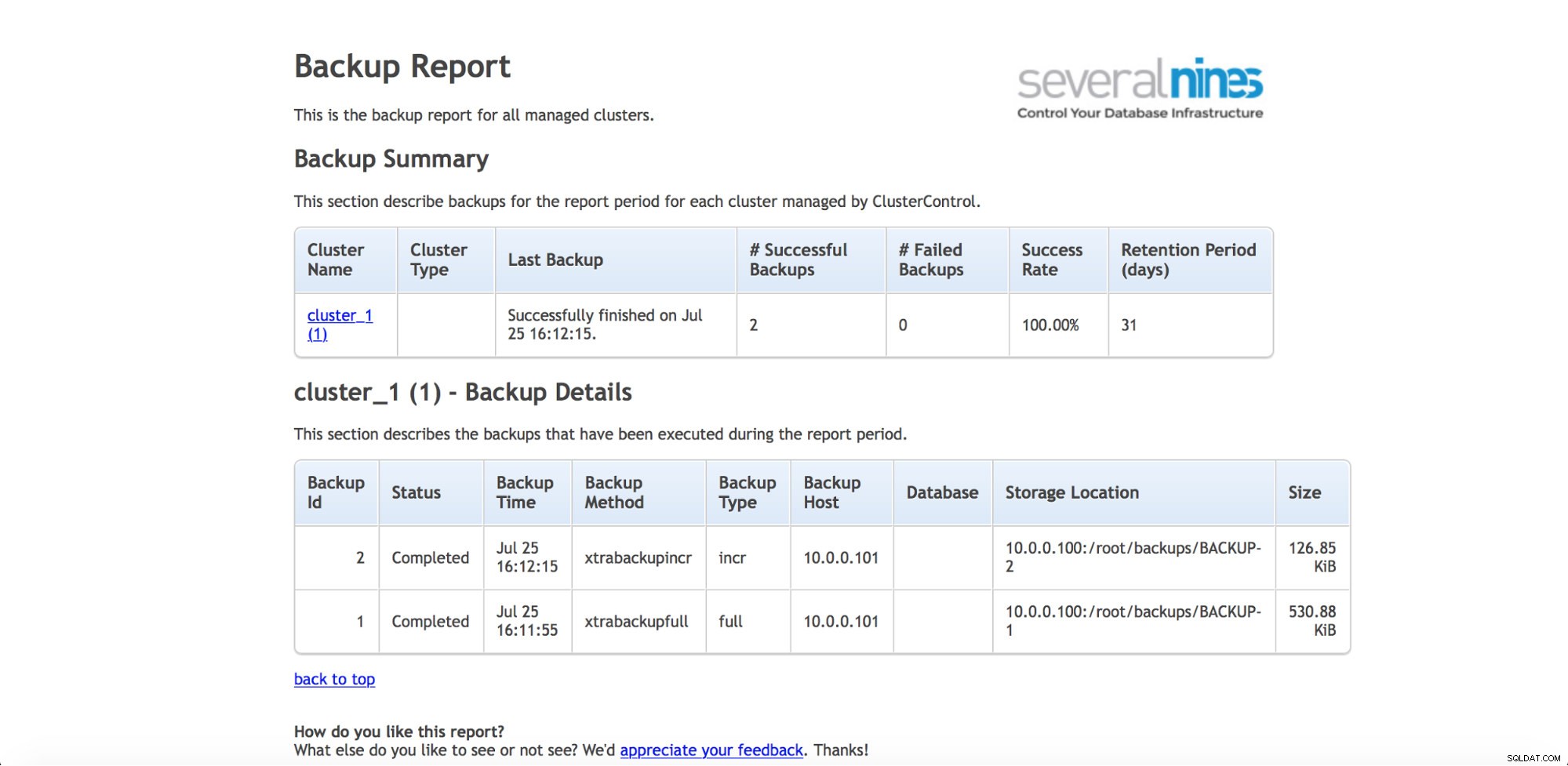
Hvis du gerne vil holde øje med sikkerhedskopierne regelmæssigt (og du vil sikkert gerne gøre dette), har ClusterControl mulighed for at generere driftsrapporter. Sikkerhedskopieringsrapporten hjælper dig med at spore udførte sikkerhedskopier og informerer, hvis der var problemer, mens du tog dem.
Severalnines DevOps Guide til Database Management Lær om, hvad du skal vide for at automatisere og administrere dine open source-databaser. Download gratisOvervågning og trending

Ingen implementering er produktionsklar uden ordentlig overvågning af tjenesterne. Du vil være sikker på, at du vil blive advaret, hvis nogle tjenester bliver utilgængelige, så du kan foretage en handling, undersøge eller starte gendannelsesprocedurer. Selvfølgelig vil du også gerne have en trendløsning. Det kan ikke understreges nok, hvor vigtigt det er at have overvågningsdata til at vurdere infrastrukturens tilstand eller til enhver undersøgelse, enten post mortem eller realtidsovervågning af tjenesternes tilstand. Metrics er ikke lige vigtige - hvis du ikke er meget fortrolig med et bestemt databaseprodukt, vil du højst sandsynligt ikke vide, hvilke målinger der er de vigtigste at indsamle og se. Selvfølgelig kan du muligvis indsamle alt, men når det kommer til at gennemgå data, er det næppe muligt at gennemgå hundredvis af metrics pr. vært - du skal vide, hvilken af dem du skal fokusere på.
Open source-verdenen er fuld af værktøjer designet til at overvåge og indsamle metrics fra forskellige databaser - de fleste af dem ville kræve, at du integrerer dem med din overordnede overvågningsinfrastruktur, chatops-platform eller oncall-supportværktøjer (som PagerDuty). Det kan også være nødvendigt at installere og integrere flere komponenter - storage (en slags tidsseriedatabase), præsentationslag og dataindsamlingsværktøjer.
ClusterControl er en lidt anderledes tilgang, da det er ét enkelt produkt med overvågning i realtid, trending og dashboards, der viser de vigtigste detaljer. Databaserådgivere, som kan være alt fra simpel konfigurationsrådgivning, advarsel om tærskler eller mere komplekse regler for forudsigelser, ville generelt give omfattende anbefalinger.
Mulighed for opskalering

Databaser har en tendens til at vokse i størrelse, og det er ikke usandsynligt, at det vil vokse i form af transaktionsmængder eller antal brugere. Evnen til at skalere ud eller op kan være afgørende for produktionen. Selvom du gør et godt stykke arbejde med at estimere dine hardwarekrav i starten af produktets livscyklus, vil du sandsynligvis skulle håndtere en vækstfase - så længe dit produkt er vellykket, det vil sige (men det er det, vi alle planlægger, ikke ?). Du skal have midlerne til nemt at opskalere din infrastruktur for at klare indkommende belastning. For statsløse tjenester som webservere er dette ret nemt - du skal blot klargøre flere forekomster ved hjælp af det seneste produktionsbillede eller kode fra dit versionskontrolværktøj. For statelige tjenester som databaser er det mere vanskeligt. Du skal klargøre nye forekomster ved hjælp af dine nuværende produktionsdata, opsætte replikering eller en form for klyngedannelse mellem den nuværende og de nye forekomster. Dette kan være en kompleks proces, og for at få det rigtigt, skal du have mere indgående kendskab til den valgte klynge- eller replikeringsmodel.
ClusterControl, som navnet antyder, giver omfattende support til opbygning af klyngede eller replikerede databaseopsætninger. De anvendte metoder er kamptestet gennem tusindvis af implementeringer. Den leveres med en Command Line Interface (CLI), så den nemt kan integreres med konfigurationsstyringssystemer. Vær dog opmærksom på, at du måske ikke ønsker at foretage ændringer i din pool af databaser for ofte - klargøring af en ny instans tager tid og tilføjer nogle overhead i eksisterende databaser. Derfor vil du måske gerne forblive på en "over-provisioneret" side lidt, så du vil have lidt tid til at oprette en ny instans, før din klynge bliver overbelastet.
Alt i alt er der flere trin, du stadig skal tage efter den første implementering, for at sikre, at dit miljø er klar til produktion. Med de rigtige værktøjer er det meget nemmere at komme dertil.