Tidligere på ugen postede jeg en opfølgning på mit seneste indlæg om STRING_SPLIT() i SQL Server 2016, der adresserer adskillige kommentarer, der er tilbage på indlægget og/eller sendt direkte til mig:
STRING_SPLIT()i SQL Server 2016 :Opfølgning #1
Efter at indlægget for det meste var skrevet, var der et sent spørgsmål fra Doug Ellner:
Hvordan sammenligner disse funktioner sig med tabelværdisatte parametre?
Nu var test af TVP'er allerede på min liste over fremtidige projekter, efter en nylig twitter-udveksling med @Nick_Craver på Stack Overflow. Han sagde, at de var begejstrede for STRING_SPLIT() klarede sig godt, fordi de var utilfredse med ydeevnen ved at sende ~7.000 værdier ind gennem en tabelværdiparameter.
Mine tests
Til disse test brugte jeg SQL Server 2016 RC3 (13.0.1400.361) på en 8-core Windows 10 VM med PCIe-lager og 32 GB RAM.
Jeg oprettede en simpel tabel, der efterlignede, hvad de lavede (ved at vælge omkring 10.000 værdier fra en tabel med 3+ millioner rækkeposter), men til mine tests har den langt færre kolonner og færre indekser:
CREATE TABLE dbo.Posts_Regular( PostID int PRIMARY KEY, HitCount int NOT NULL DEFAULT 0); INSERT dbo.Posts_Regular(PostID) SELECT TOP (3000000) ROW_NUMBER() OVER (ORDER BY s1.[object_id]) FROM sys.all_objects AS s1 CROSS JOIN sys.all_objects AS s2;
Jeg oprettede også en In-Memory-version, fordi jeg var nysgerrig efter, om en fremgangsmåde ville fungere anderledes der:
OPRET TABEL dbo.Posts_InMemory( PostID int PRIMÆR NØGLE IKKE-KLUNGERET HASH MED (BUCKET_COUNT =4000000), HitCount int IKKE NULL DEFAULT 0) MED (MEMORY_OPTIMIZED =ON);
Nu ønskede jeg at skabe en C#-app, der ville sende 10.000 unikke værdier ind, enten som en kommasepareret streng (bygget ved hjælp af en StringBuilder) eller som en TVP (overført fra en datatabel). Pointen ville være at hente eller opdatere et udvalg af rækker baseret på et match, enten til et element produceret ved at opdele listen eller en eksplicit værdi i en TVP. Så koden blev skrevet for at tilføje hver 300. værdi til strengen eller DataTable (C#-koden er i et appendiks nedenfor). Jeg tog de funktioner, jeg oprettede i det originale indlæg, ændrede dem til at håndtere varchar(max) , og tilføjede derefter to funktioner, der accepterede en TVP - en af dem hukommelsesoptimeret. Her er tabeltyperne (funktionerne findes i appendiks nedenfor):
CREATE TYPE dbo.PostIDs_Regular AS TABLE(PostID int PRIMARY KEY);GO CREATE TYPE dbo.PostIDs_InMemory AS TABLE( PostID int NOT NULL PRIMÆR NØGLE IKKE-KLUNGERET HASH MED (BUCKET_COUNT =0ME)0MIOPRYD =10ME)0MIOPRY; /pre>Jeg var også nødt til at gøre Numbers-tabellen større for at kunne håndtere strenge> 8K og med> 8K elementer (jeg lavede den til 1MM rækker). Derefter oprettede jeg syv lagrede procedurer:fem af dem tager en
varchar(max)og slutte sig til funktionsudgangen for at opdatere basistabellen, og derefter to for at acceptere TVP'en og slutte sig direkte til den. C#-koden kalder hver af disse syv procedurer med listen over 10.000 indlæg, der skal vælges eller opdateres 1.000 gange. Disse procedurer er også i appendiks nedenfor. Så bare for at opsummere er metoderne, der testes:
- Native (
STRING_SPLIT()) - XML
- CLR
- Tabel med tal
- JSON (med eksplicit
intoutput) - Tabelværdiparameter
- Hukommelsesoptimeret parameter med en tabelværdi
Vi vil teste at hente de 10.000 værdier, 1.000 gange, ved hjælp af en DataReader – men ikke iterere over DataReader, da det blot ville få testen til at tage længere tid og ville være den samme mængde arbejde for C#-applikationen uanset hvordan databasen producerede sættet. Vi tester også at opdatere de 10.000 rækker, 1.000 gange hver, ved hjælp af ExecuteNonQuery() . Og vi tester mod både de almindelige og hukommelsesoptimerede versioner af Posts-tabellen, som vi kan skifte meget nemt uden at skulle ændre nogen af funktionerne eller procedurerne ved hjælp af et synonym:
OPRET SYNONYM dbo.Posts FOR dbo.Posts_Regular; -- for at teste hukommelsesoptimeret version:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_InMemory; -- for at teste den diskbaserede version igen:DROP SYNONYM dbo.Posts;CREATE SYNONYM dbo.Posts FOR dbo.Posts_Regular;
Jeg startede applikationen, kørte den flere gange for hver kombination for at sikre, at kompilering, caching og andre faktorer ikke var uretfærdige over for den batch, der blev udført først, og analyserede derefter resultaterne fra logningstabellen (jeg tjekkede også sys. dm_exec_procedure_stats for at sikre, at ingen af tilgangene havde signifikant applikationsbaseret overhead, og det havde de ikke).
Resultater – Diskbaserede tabeller
Jeg kæmper nogle gange med datavisualisering – jeg prøvede virkelig at finde på en måde at repræsentere disse målinger på et enkelt diagram, men jeg synes, der var alt for mange datapunkter til at få de fremtrædende til at skille sig ud.
Du kan klikke for at forstørre en hvilken som helst af disse i en ny fane/vindue, men selvom du har et lille vindue, forsøgte jeg at gøre vinderen tydelig ved brug af farver (og vinderen var den samme i alle tilfælde). Og for at være klar, mener jeg med "Gennemsnitlig varighed" den gennemsnitlige tid, det tog for applikationen at gennemføre en loop på 1.000 operationer.
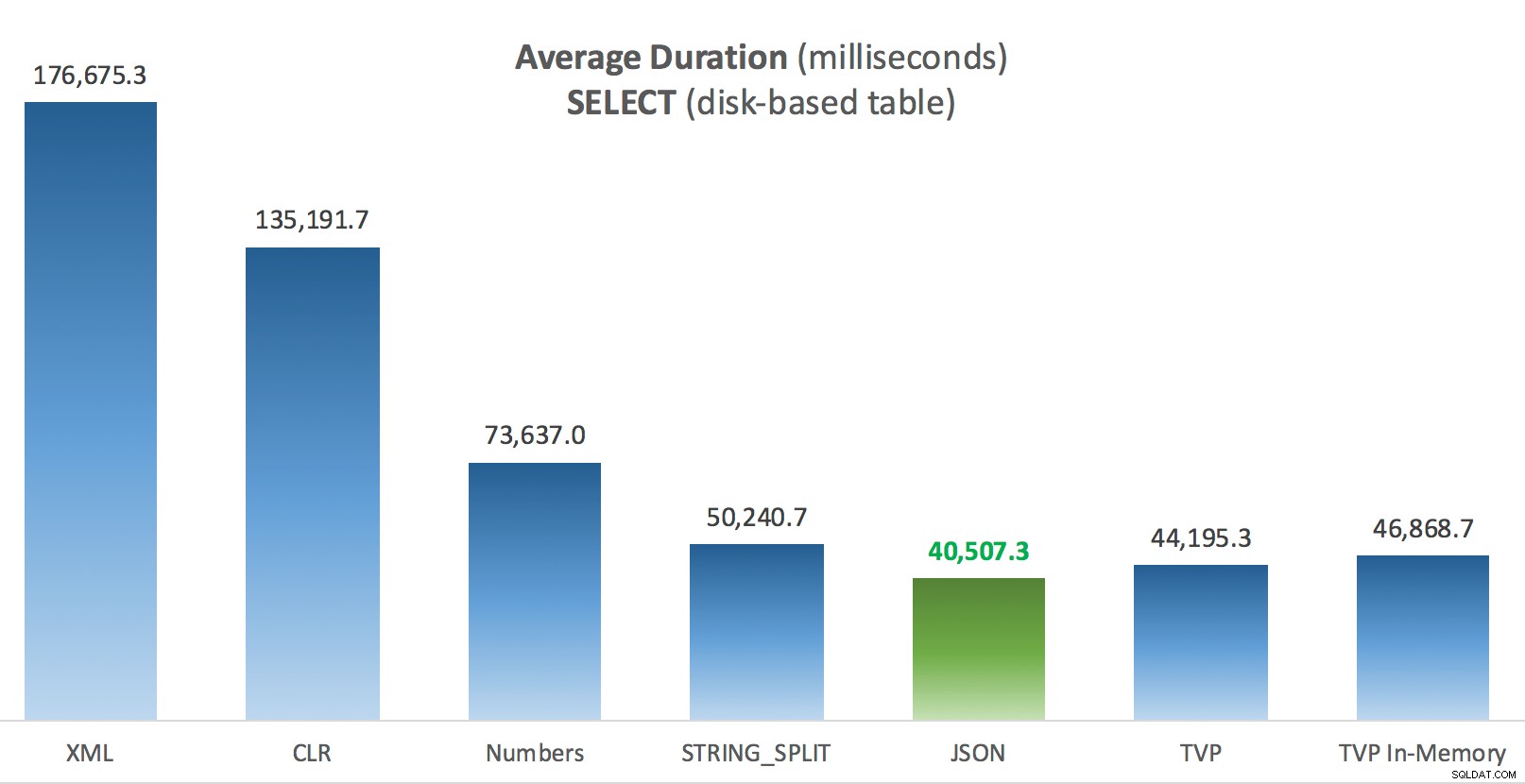 Gennemsnitlig varighed (millisekunder) for SELECTs mod disk-baseret posttabel
Gennemsnitlig varighed (millisekunder) for SELECTs mod disk-baseret posttabel
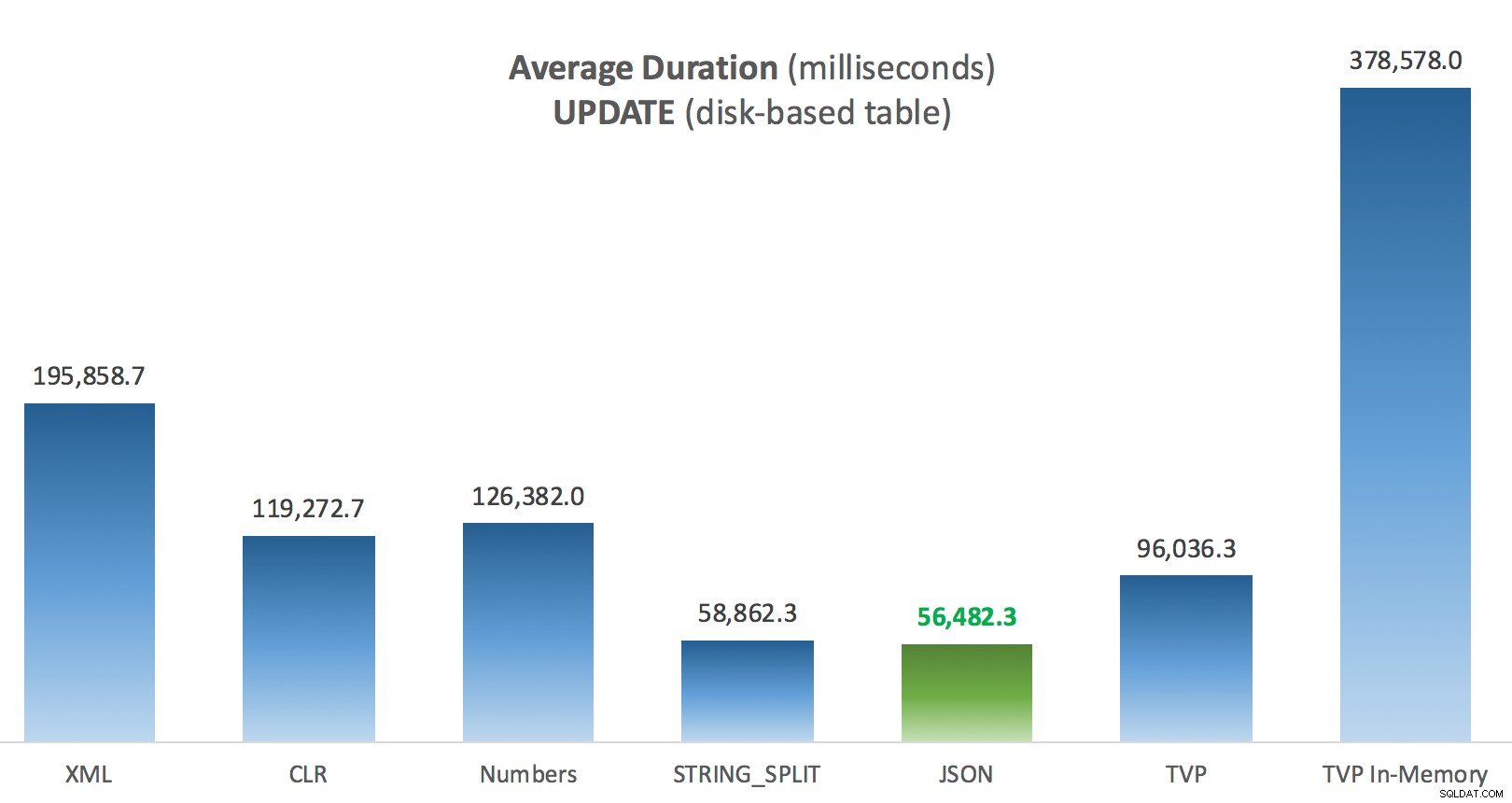 Gennemsnitlig varighed (millisekunder) for OPDATERINGER mod disk-baseret indlægstabel
Gennemsnitlig varighed (millisekunder) for OPDATERINGER mod disk-baseret indlægstabel
Det mest interessante her for mig er, hvor dårligt den hukommelsesoptimerede TVP klarede sig, da den hjalp med en UPDATE . Det viser sig, at parallelle scanninger i øjeblikket blokeres for aggressivt, når DML er involveret; Microsoft har anerkendt dette som et funktionsgab, og de håber at løse det snart. Bemærk, at parallel scanning i øjeblikket er mulig med SELECT men det er blokeret for DML lige nu. (Det vil ikke blive løst i SQL Server 2014, da disse specifikke parallelle scanningsoperationer ikke er tilgængelige der for nogen operation.) Når det er rettet, eller når dine TVP'er er mindre og/eller parallelitet alligevel ikke er fordelagtigt, bør du se at hukommelsesoptimerede TVP'er vil præstere bedre (mønsteret fungerer bare ikke godt til netop dette anvendelsestilfælde af relativt store TVP'er).
For dette specifikke tilfælde er her planerne for SELECT (som jeg kunne tvinge til at gå parallelt) og UPDATE (hvilket jeg ikke kunne):
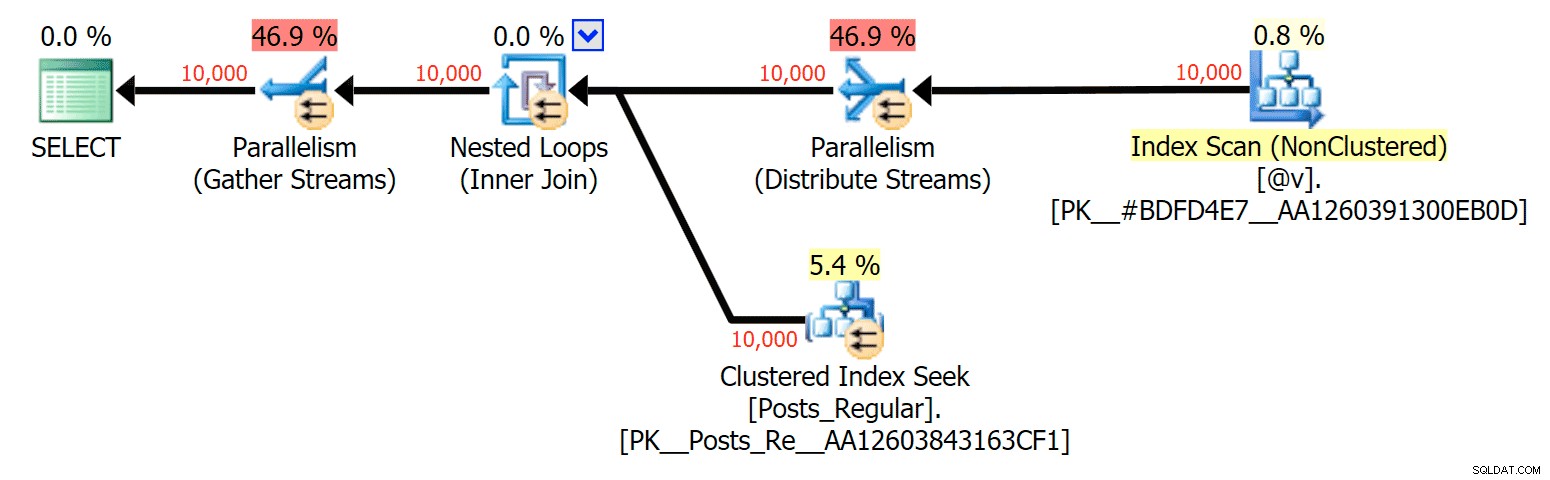 Parallelisme i en SELECT-plan, der forbinder en disk-baseret tabel med en in-memory TVP
Parallelisme i en SELECT-plan, der forbinder en disk-baseret tabel med en in-memory TVP
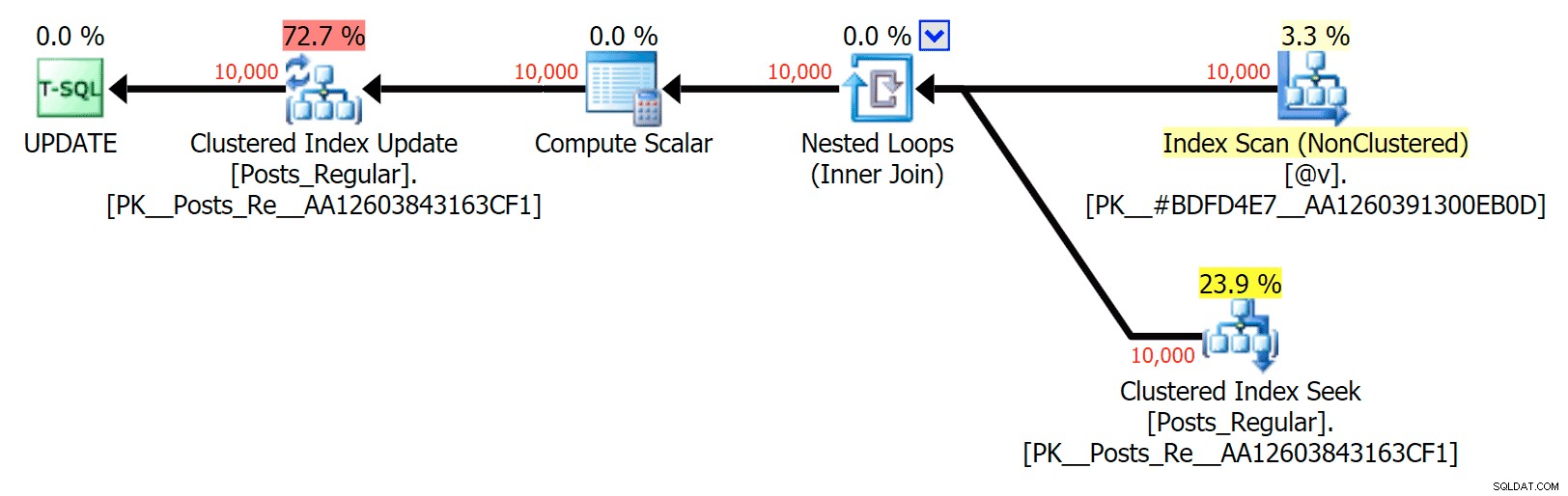 Ingen parallelitet i en UPDATE-plan, der forbinder en disk-baseret tabel til en in-memory TVP
Ingen parallelitet i en UPDATE-plan, der forbinder en disk-baseret tabel til en in-memory TVP
Resultater – Hukommelsesoptimerede tabeller
Lidt mere konsistens her – de fire metoder til højre er relativt jævne, mens de tre til venstre derimod virker meget uønskede. Vær også særlig opmærksom på absolut skala sammenlignet med de diskbaserede tabeller - for det meste, ved at bruge de samme metoder, og selv uden parallelitet, ender du med meget hurtigere operationer mod hukommelsesoptimerede tabeller, hvilket fører til lavere samlet CPU-brug.
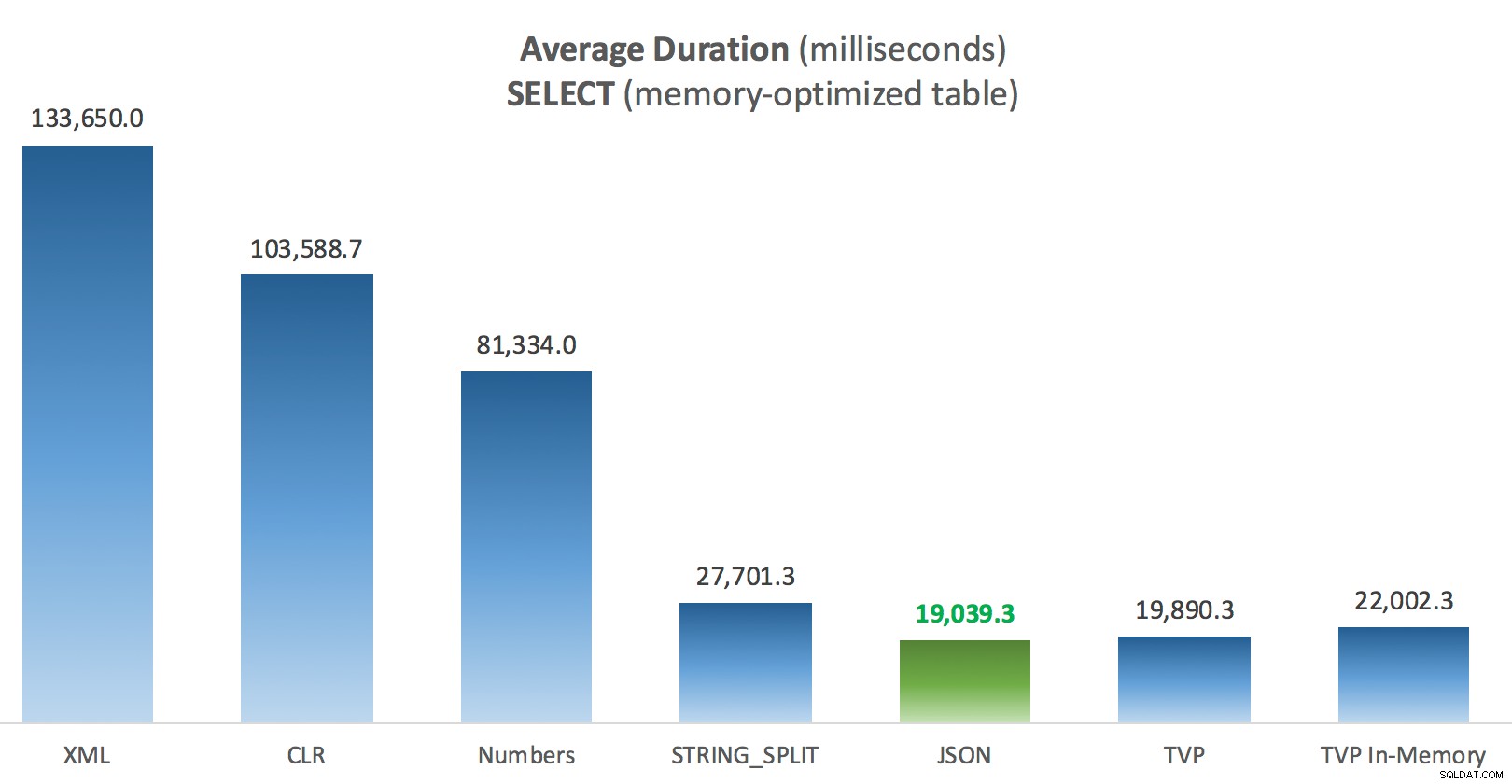 Gennemsnitlig varighed (millisekunder) for SELECT'er mod hukommelsesoptimeret indlægstabel
Gennemsnitlig varighed (millisekunder) for SELECT'er mod hukommelsesoptimeret indlægstabel
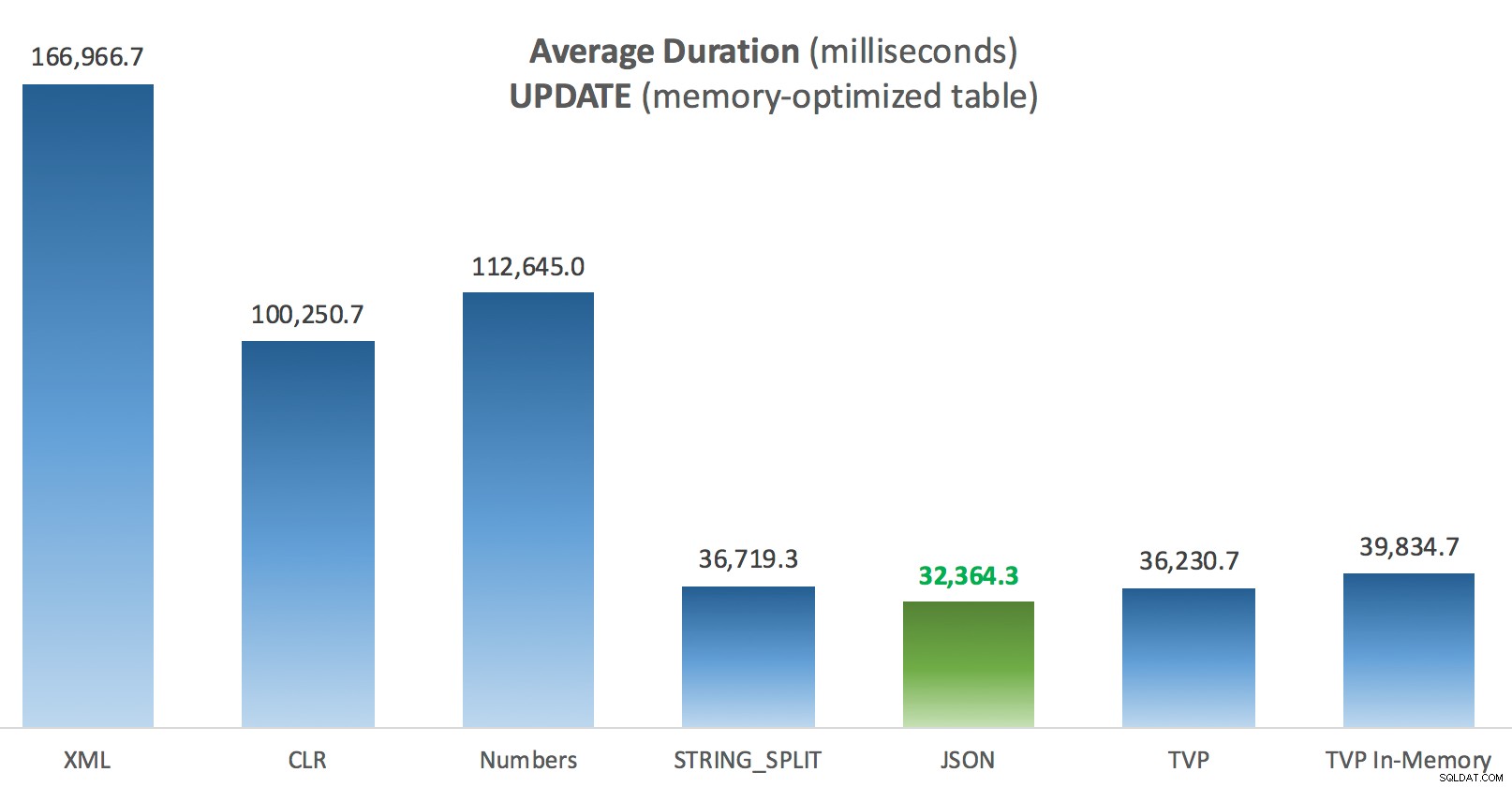 Gennemsnitlig varighed (millisekunder) for OPDATERINGER mod hukommelsesoptimeret indlægstabel
Gennemsnitlig varighed (millisekunder) for OPDATERINGER mod hukommelsesoptimeret indlægstabel
Konklusion
Til denne specifikke test, med en specifik datastørrelse, fordeling og antal parametre, og på min særlige hardware, var JSON en konsekvent vinder (dog marginalt). For nogle af de andre tests i tidligere indlæg klarede andre tilgange sig dog bedre. Bare et eksempel på, hvordan det, du laver, og hvor du gør det, kan have en dramatisk indvirkning på den relative effektivitet af forskellige teknikker, her er de ting, jeg har testet i denne korte serie, med min opsummering af, hvilken teknik der skal bruge i det tilfælde, og som du skal bruge som et 2. eller 3. valg (f.eks. hvis du ikke kan implementere CLR på grund af virksomhedens politik, eller fordi du bruger Azure SQL Database, eller du ikke kan bruge JSON eller STRING_SPLIT() fordi du ikke er på SQL Server 2016 endnu). Bemærk, at jeg ikke gik tilbage og testede variabeltildelingen igen og SELECT INTO scripts ved hjælp af TVP'er - disse tests blev sat op under forudsætning af, at du allerede havde eksisterende data i CSV-format, som alligevel skulle brydes op først. Generelt, hvis du kan undgå det, skal du ikke smuldre dine sæt ind i kommaseparerede strenge i første omgang, IMHO.
| Mål | Første valg | 2. valg (og 3., hvor det er relevant) |
|---|---|---|
| Simpel variabeltildeling | STRING_SPLIT() | CLR if <2016 XML hvis ingen CLR og <2016 |
| VÆLG TIL | CLR | XML hvis ingen CLR |
| VÆLG TIL (ingen spole) | CLR | Talstabel hvis ingen CLR |
| VÆLG TIL (ingen spole + MAXDOP 1) | STRING_SPLIT() | CLR if <2016 Talstabel hvis ingen CLR og <2016 |
| VÆLG deltager i stor liste (diskbaseret) | JSON (int) | TVP if <2016 |
| VÆLG deltager i stor liste (hukommelsesoptimeret) | JSON (int) | TVP if <2016 |
| OPDATERING slutter sig til stor liste (diskbaseret) | JSON (int) | TVP if <2016 |
| OPDATERING slutter sig til stor liste (hukommelsesoptimeret) | JSON (int) | TVP if <2016 |
Til Dougs specifikke spørgsmål:JSON, STRING_SPLIT() , og TVP'er udførte temmelig ens på tværs af disse tests i gennemsnit - tæt nok på, at TVP'er er det oplagte valg, hvis du ikke er på SQL Server 2016. Hvis du har forskellige use cases, kan disse resultater variere. Meget .
Hvilket bringer os til moralen i dette historie:Jeg og andre kan udføre meget specifikke præstationstests, der kredser om enhver funktion eller tilgang, og kommer til en konklusion om, hvilken tilgang der er hurtigst. Men der er så mange variabler, at jeg aldrig vil have tillid til at sige "denne tilgang er altid den hurtigste." I dette scenarie prøvede jeg meget hårdt på at kontrollere de fleste af de medvirkende faktorer, og mens JSON vandt i alle fire tilfælde, kan du se, hvordan disse forskellige faktorer påvirkede eksekveringstiden (og drastisk for nogle tilgange). Så det er altid det værd at konstruere dine egne tests, og jeg håber, jeg har været med til at illustrere, hvordan jeg går til den slags.
Bilag A:Konsolapplikationskode
Please, ingen nit-picking om denne kode; det blev bogstaveligt talt smidt sammen som en meget enkel måde at køre disse lagrede procedurer 1.000 gange med sande lister og datatabeller samlet i C#, og til at logge den tid, hver sløjfe tog til en tabel (for at være sikker på at inkludere enhver applikationsrelateret overhead med håndtering enten en stor snor eller en samling). Jeg kunne tilføje fejlhåndtering, sløjfe anderledes (f.eks. konstruere listerne inde i løkken i stedet for at genbruge en enkelt arbejdsenhed) og så videre.
using System;using System.Text;using System.Configuration;using System.Data;using System.Data.SqlClient; navneområde SplitTesting{ class Program { static void Main(string[] args) { string operation ="Opdater"; if (args[0].ToString() =="-Select") { operation ="Vælg"; } var csv =new StringBuilder(); DataTable-elementer =new DataTable(); elements.Columns.Add("værdi", typeof(int)); for (int i =1; i <=10000; i++) { csv.Append((i*300).ToString()); if (i <10000) { csv.Append(","); } elements.Rows.Add(i*300); } string[] methods ={ "Native", "CLR", "XML", "Numbers", "JSON", "TVP", "TVP_InMemory" }; ved hjælp af (SqlConnection con =new SqlConnection()) { con.ConnectionString =ConfigurationManager.ConnectionStrings["primær"].ToString(); con.Open(); SqlParameter p; foreach (strengmetode i metoder) { SqlCommand cmd =new SqlCommand("dbo." + operation + "Posts_" + metode, con); cmd.CommandType =CommandType.StoredProcedure; if (metode =="TVP" || metode =="TVP_InMemory") { cmd.Parameters.Add("@PostList", SqlDbType.Structured).Value =elementer; } else { cmd.Parameters.Add("@PostList", SqlDbType.VarChar, -1).Value =csv.ToString(); } var timer =System.Diagnostics.Stopwatch.StartNew(); for (int x =1; x <=1000; x++) { if (operation =="Opdater") { cmd.ExecuteNonQuery(); } else { SqlDataReader rdr =cmd.ExecuteReader(); rdr.Luk(); } } timer.Stop(); long this_time =timer.ElapsedMilliseconds; // logtid - logningsproceduren tilføjer klokkeslæt og // registrerer hukommelse/diskbaseret (bestemt via synonym) SqlCommand log =new SqlCommand("dbo.LogBatchTime", con); log.CommandType =CommandType.StoredProcedure; log.Parameters.Add("@Operation", SqlDbType.VarChar, 32).Value =operation; log.Parameters.Add("@Method", SqlDbType.VarChar, 32).Value =metode; log.Parameters.Add("@Timing", SqlDbType.Int).Value =this_time; log.ExecuteNonQuery(); Console.WriteLine(metode + " :" + this_time.ToString()); } } } }} Eksempel på brug:
SplitTesting.exe -VælgSplitTesting.exe -Opdater
Bilag B:Funktioner, procedurer og logningstabel
Her var funktionerne redigeret til at understøtte varchar(max) (CLR-funktionen er allerede accepteret nvarchar(max) og jeg var stadig tilbageholdende med at prøve at ændre det):
CREATE FUNCTION dbo.SplitStrings_Native( @List varchar(max), @Delimiter char(1))RETURNER TABEL MED SCHEMABINDINGAS RETURN (VÆLG [værdi] FRA STRING_SPLIT(@List, @Delimiter));GO OPRET FUNCTION dbo.SplitStrings ( @List varchar(max), @Delimiter char(1))RETURNERER TABEL MED SCHEMABINDINGAS RETURN (SELECT [value] =y.i.value('(./text())[1]', 'varchar(max)') FRA (SELECT x =CONVERT(XML, '' + REPLACE(@List, @Delimiter, '') + '').query('.')) SOM en CROSS APPLY x.nodes('i') AS y(i));GO CREATE FUNCTION dbo.SplitStrings_Numbers( @List varchar(max), @Delimiter char(1))RETURNERER TABEL MED SCHEMABINDINGAS RETURN (VÆLG [værdi] =SUBSTRING (@List, Tal, CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number) FRA dbo.Numbers WHERE Number <=CONVERT(INT, LEN(@List)) AND SUBSTRING(@Delimiter + @List, Number , LEN(@Delimiter)) =@Delimiter );GO CREATE FUNCTION dbo.SplitStrings_JSON( @List varchar(max), @Delimiter char(1))RETURNERER TABEL MED SCH EMABINDINGAS RETURN (VÆLG [værdi] FRA OPENJSON(CHAR(91) + @List + CHAR(93)) MED (værdi int '$'));GO Og de lagrede procedurer så således ud:
CREATE PROCEDURE dbo.UpdatePosts_Native @PostList varchar(max)ASBEGIN UPDATE p SET HitCount +=1 FRA dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s. [værdi];ENDGOCREATE PROCEDURE dbo.SelectPosts_Native @PostList varchar(max)ASBEGIN SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN dbo.SplitStrings_Native(@PostList, ',') AS s ON p.PostID =s.[værdi];ENDGO-- gentag for de 4 andre varchar(max)-baserede metoder CREATE PROCEDURE dbo.UpdatePosts_TVP @PostList dbo.PostIDs_Regular READONLY -- skift _Regular til _InMemoryASBEGIN SET NOCOUNT ON; OPDATERING p SET HitCount +=1 FRA dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGOCREATE PROCEDURE dbo.SelectPosts_TVP @PostList dbo.PostIDs_Regular READONLY -- BEGIN InSETNOCOUNT ASON; SELECT p.PostID, p.HitCount FROM dbo.Posts AS p INNER JOIN @PostList AS s ON p.PostID =s.PostID;ENDGO-- gentag for in-memory
Og endelig, logningstabellen og proceduren:
CREATE TABLE dbo.SplitLog( LogID int IDENTITY(1,1) PRIMARY KEY, ClockTime datetime NOT NULL DEFAULT GETDATE(), OperatingTable nvarchar(513) NOT NULL, -- Posts_InMemory eller Posts_Regular Operation varchar(32) NOT NULL 'Opdater', -- eller vælg Metode varchar(32) NOT NULL DEFAULT 'Native', -- eller TVP, JSON, etc. Timing int NOT NULL DEFAULT 0);GO CREATE PROCEDURE dbo.LogBatchTime @Operation varchar(32), @Method varchar(32), @Timing intASBEGIN SET NOCOUNT ON; INSERT dbo.SplitLog(OperatingTable, Operation, Method, Timing) SELECT base_object_name, @Operation, @Method, @Timing FROM sys.synonyms WHERE name =N'Posts';ENDGO -- og forespørgslen til at generere graferne:;WITH x AS( SELECT OperatingTable, Operation, Methode, Timing, Recent =ROW_NUMBER() OVER (PARTITION BY OperatingTable, Operation, Method ORDER BY ClockTime DESC) FROM dbo.SplitLog)SELECT OperatingTable, Operation, Method, AverageDuration =GMT(1,0*Timing) FROM x WHERE seneste <=3GROUP BY OperatingTable,Operation,Method;