I del 5 af min serie om tabeludtryk gav jeg følgende løsning til generering af en række tal ved hjælp af CTE'er, en tabelværdikonstruktør og krydsforbindelser:
DECLARE @low AS BIGINT =1001, @high AS BIGINT =1010; MED L0 AS ( VÆLG 1 AS c FRA (VÆRDIER(1),(1)) SOM D(c) ), L1 AS ( VÆLG 1 AS c FRA L0 SOM A CROSS JOIN L0 AS B ), L2 AS ( VÆLG 1 AS c FRA L1 SOM KRYDSJOIN L1 AS B ), L3 AS ( VÆLG 1 AS c FRA L2 SOM A CROSS JOIN L2 AS B ), L4 AS ( VÆLG 1 AS c FRA L3 SOM A CROSS JOIN L3 AS B ), L5 AS ( VÆLG 1 SOM c FRA L4 SOM ET KRYDSJOIN L4 SOM B ), Nums AS ( VÆLG ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) SOM rækkenummer FRA L5 )SELECT TOP(@high - @low + 1) @low + rækkenummer - 1 SOM nFRA numreORDER BY rownum;
Der er mange praktiske use cases for et sådant værktøj, herunder generering af en række dato- og tidsværdier, oprettelse af eksempeldata og mere. I erkendelse af det fælles behov, har nogle platforme et indbygget værktøj, såsom PostgreSQL's gener_series funktion. I skrivende stund tilbyder T-SQL ikke et sådant indbygget værktøj, men man kan altid håbe og stemme på, at et sådant værktøj bliver tilføjet i fremtiden.
I en kommentar til min artikel nævnte Marcos Kirchner, at han testede min løsning med varierende tabelværdikonstruktørkardinaliteter og fik forskellige udførelsestider for de forskellige kardinaliteter.
 Jeg brugte altid min løsning med en basistabelværdikonstruktørkardinalitet på 2, men Marcos' kommentar fik mig til at tænke. Dette værktøj er så nyttigt, at vi som et fællesskab bør gå sammen for at prøve at skabe den hurtigste version, vi overhovedet kan. Afprøvning af forskellige basisbordskardinaliteter er kun én dimension at prøve. Der kunne være mange andre. Jeg vil præsentere de præstationstest, som jeg har lavet med min løsning. Jeg eksperimenterede hovedsageligt med forskellige tabelværdi-konstruktørkardinaliteter, med seriel versus parallel behandling og med rækketilstand versus batchtilstandsbehandling. Det kan dog være, at en helt anden løsning er endnu hurtigere end min bedste version. Så udfordringen er i gang! Jeg kalder både jedi, padawan, troldmand og lærling. Hvad er den bedste løsning, du kan fremtrylle? Har du det indeni dig at slå den hurtigste løsning, der er sendt indtil videre? Hvis det er tilfældet, så del din som en kommentar til denne artikel, og du er velkommen til at forbedre enhver løsning, som andre har indsendt.
Jeg brugte altid min løsning med en basistabelværdikonstruktørkardinalitet på 2, men Marcos' kommentar fik mig til at tænke. Dette værktøj er så nyttigt, at vi som et fællesskab bør gå sammen for at prøve at skabe den hurtigste version, vi overhovedet kan. Afprøvning af forskellige basisbordskardinaliteter er kun én dimension at prøve. Der kunne være mange andre. Jeg vil præsentere de præstationstest, som jeg har lavet med min løsning. Jeg eksperimenterede hovedsageligt med forskellige tabelværdi-konstruktørkardinaliteter, med seriel versus parallel behandling og med rækketilstand versus batchtilstandsbehandling. Det kan dog være, at en helt anden løsning er endnu hurtigere end min bedste version. Så udfordringen er i gang! Jeg kalder både jedi, padawan, troldmand og lærling. Hvad er den bedste løsning, du kan fremtrylle? Har du det indeni dig at slå den hurtigste løsning, der er sendt indtil videre? Hvis det er tilfældet, så del din som en kommentar til denne artikel, og du er velkommen til at forbedre enhver løsning, som andre har indsendt.
Krav:
- Implementer din løsning som en indlejret tabelværdi-funktion (iTVF) ved navn dbo.GetNumsYourName med parametrene @low AS BIGINT og @high AS BIGINT. Som et eksempel, se dem, jeg indsender i slutningen af denne artikel.
- Du kan oprette understøttende tabeller i brugerdatabasen, hvis det er nødvendigt.
- Du kan tilføje tip efter behov.
- Som nævnt bør løsningen understøtte skilletegn af typen BIGINT, men du kan antage en maksimal seriekardinalitet på 4.294.967.296.
- For at evaluere ydeevnen af din løsning og sammenligne den med andre, tester jeg den med intervallet 1 til 100.000.000, med Kassér resultater efter udførelse aktiveret i SSMS.
Held og lykke til os alle! Må det bedste samfund vinde.;)
Forskellige kardinaliteter for basistabelværdikonstruktør
Jeg eksperimenterede med forskellige kardinaliteter af basis-CTE, startende med 2 og fremad i en logaritmisk skala, hvor jeg kvadrerede den foregående kardinalitet i hvert trin:2, 4, 16 og 256.
Før du begynder at eksperimentere med forskellige basiskardinaliteter, kunne det være nyttigt at have en formel, der givet basiskardinaliteten og det maksimale intervalkardinalitet vil fortælle dig, hvor mange niveauer af CTE'er du har brug for. Som et indledende trin er det nemmere først at komme med en formel, der givet basiskardinaliteten og antallet af niveauer af CTE'er beregner, hvad der er den maksimale resulterende rækkeviddekardinalitet. Her er sådan en formel udtrykt i T-SQL:
ERKLÆR @basecardinality AS INT =2, @levels AS INT =5; VÆLG POWER(1.*@basecardinality, POWER(2., @levels));
Med ovenstående eksempelinputværdier giver dette udtryk en maksimal intervalkardinalitet på 4.294.967.296.
Derefter involverer den omvendte formel til beregning af antallet af nødvendige CTE-niveauer indlejring af to logfunktioner, som sådan:
DECLARE @basecardinality AS INT =2, @seriescardinality AS BIGINT =4294967296; SELECT CEILING(LOG(LOG(@seriekardinalitet, @basekardinalitet), 2));
Med ovenstående eksempelinputværdier giver dette udtryk 5. Bemærk, at dette tal er et supplement til basis-CTE, der har tabelværdikonstruktøren, som jeg navngav L0 (for niveau 0) i min løsning.
Spørg mig ikke, hvordan jeg kom til disse formler. Den historie, jeg holder mig til, er, at Gandalf udtalte dem til mig på alvisk i mine drømme.
Lad os gå videre til præstationstest. Sørg for, at du aktiverer Kassér resultater efter udførelse i dialogboksen Indstillinger for SSMS-forespørgsel under Gitter, Resultater. Brug følgende kode til at køre en test med basis-CTE-kardinalitet på 2 (kræver 5 yderligere niveauer af CTE'er):
DECLARE @low AS BIGINT =1, @high AS BIGINT =100000000; MED L0 AS ( VÆLG 1 AS c FRA (VÆRDIER(1),(1)) SOM D(c) ), L1 AS ( VÆLG 1 AS c FRA L0 SOM A CROSS JOIN L0 AS B ), L2 AS ( VÆLG 1 AS c FRA L1 SOM KRYDSJOIN L1 AS B ), L3 AS ( VÆLG 1 AS c FRA L2 SOM A CROSS JOIN L2 AS B ), L4 AS ( VÆLG 1 AS c FRA L3 SOM A CROSS JOIN L3 AS B ), L5 AS ( VÆLG 1 SOM c FRA L4 SOM ET KRYDSJOIN L4 SOM B ), Nums AS ( VÆLG ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) SOM rækkenummer FRA L5 )SELECT TOP(@high - @low + 1) @low + rækkenummer - 1 SOM nFRA numreORDER BY rownum;
Jeg fik planen vist i figur 1 for denne udførelse.
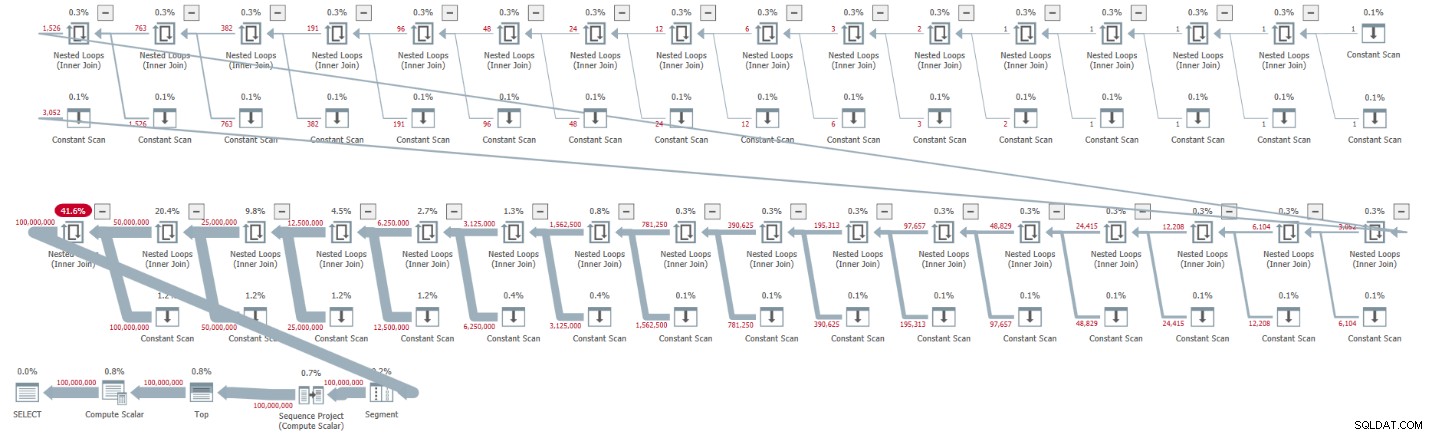 Figur 1:Plan for basis-CTE-kardinalitet på 2
Figur 1:Plan for basis-CTE-kardinalitet på 2
Planen er seriel, og alle operatører i planen bruger rækketilstandsbehandling som standard. Hvis du får en parallel plan som standard, f.eks. når du indkapsler løsningen i en iTVF og bruger en stor rækkevidde, skal du nu fremtvinge en seriel plan med et MAXDOP 1-tip.
Se, hvordan udpakningen af CTE'erne resulterede i 32 forekomster af Constant Scan-operatoren, der hver repræsenterer en tabel med to rækker.
Jeg fik følgende præstationsstatistik for denne udførelse:
CPU-tid =30188 ms, forløbet tid =32844 ms.
Brug følgende kode til at teste løsningen med en basis-CTE-kardinalitet på 4, som ifølge vores formel kræver fire niveauer af CTE'er:
DECLARE @low AS BIGINT =1, @high AS BIGINT =100000000; MED L0 AS ( VÆLG 1 AS c FRA (VÆRDIER(1),(1),(1),(1)) SOM D(c) ), L1 AS (VÆLG 1 AS c FRA L0 SOM KRYDSJOIN L0 AS B ), L2 AS ( VÆLG 1 AS c FRA L1 SOM A CROSS JOIN L1 AS B ), L3 AS ( VÆLG 1 AS c FRA L2 SOM A CROSS JOIN L2 AS B ), L4 AS ( VÆLG 1 AS c FRA L3 SOM ET KRYDS JOIN L3 AS B ), Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum FROM L4 )SELECT TOP(@high - @low + 1) @low + rownum - 1 AS nFROM NumsORDER BY rownum;
Jeg fik planen vist i figur 2 for denne udførelse.
 Figur 2:Plan for basis-CTE-kardinalitet på 4
Figur 2:Plan for basis-CTE-kardinalitet på 4
Udpakningen af CTE'erne resulterede i 16 Constant Scan-operatorer, der hver repræsenterer en tabel med 4 rækker.
Jeg fik følgende præstationsstatistik for denne udførelse:
CPU-tid =23781 ms, forløbet tid =25435 ms.
Dette er en anstændig forbedring på 22,5 procent i forhold til den tidligere løsning.
Ved at undersøge ventestatistikker, der er rapporteret for forespørgslen, er den dominerende ventetype SOS_SCHEDULER_YIELD. Faktisk faldt ventetallet mærkeligt med 22,8 procent sammenlignet med den første løsning (ventetal 15.280 mod 19.800).
Brug følgende kode til at teste løsningen med en basis-CTE-kardinalitet på 16, som ifølge vores formel kræver tre niveauer af CTE'er:
DECLARE @low AS BIGINT =1, @high AS BIGINT =100000000; MED L0 SOM ( VÆLG 1 SOM c FRA (VÆRDIER(1),(1),(1),(1),(1),(1),(1),(1), (1),(1) ,(1),(1),(1),(1),(1),(1)) AS D(c) ), L1 AS (VÆLG 1 AS c FRA L0 SOM EN KRYDSJOIN L0 AS B ), L2 AS ( VÆLG 1 AS c FRA L1 SOM A CROSS JOIN L1 AS B ), L3 AS ( VÆLG 1 AS c FRA L2 SOM A CROSS JOIN L2 AS B ), Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL) )) SOM rækkenummer FRA L3 )VÆLG TOP(@høj - @lav + 1) @lav + rækkenummer - 1 SOM nFRA numreORDER BY rownum;
Jeg fik planen vist i figur 3 for denne udførelse.
 Figur 3:Plan for basis-CTE-kardinalitet på 16
Figur 3:Plan for basis-CTE-kardinalitet på 16
Denne gang resulterede udpakningen af CTE'erne i 8 Constant Scan-operatorer, der hver repræsenterer en tabel med 16 rækker.
Jeg fik følgende præstationsstatistik for denne udførelse:
CPU-tid =22968 ms, forløbet tid =24409 ms.
Denne løsning reducerer den forløbne tid yderligere, dog med blot et par ekstra procent, hvilket svarer til en reduktion på 25,7 procent i forhold til den første løsning. Igen, ventetællingen for SOS_SCHEDULER_YIELD ventetypen bliver ved med at falde (12.938).
Når vi går videre i vores logaritmiske skala, involverer den næste test en basis-CTE-kardinalitet på 256. Den er lang og grim, men prøv det:
DECLARE @low AS BIGINT =1, @high AS BIGINT =100000000; MED L0 SOM ( VÆLG 1 SOM c FRA (VÆRDIER(1),(1),(1),(1),(1),(1),(1),(1), (1),(1) ,(1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),( 1),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1),(1) ,(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),( 1), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1),(1),(1) ,(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), ( 1),(1),(1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ,(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),( 1),(1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1) ,(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1),( 1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1) ,(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1) ),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1), (1),(1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1) ),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1), (1),(1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1) ),(1), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1),(1), (1),(1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1) ), (1),(1),(1),(1),(1),(1),(1),(1), (1),(1),(1),(1), (1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1)) AS D (c) ), L1 AS ( VÆLG 1 AS c FRA L0 SOM A CROSS JOIN L0 AS B ), L2 AS ( VÆLG 1 AS c FRA L1 SOM A CROSS JOIN L1 AS B ), Nums AS ( SELECT ROW_NUMBER() OVER( BESTIL EFTER (VÆLG NULL)) SOM rækkenummer FRA L2 )VÆLG TOP(@high - @low + 1) @low + rownum - 1 SOM nFRA NumsORDER BY rownum;
Jeg fik planen vist i figur 4 for denne udførelse.
 Figur 4:Plan for basis-CTE-kardinalitet på 256
Figur 4:Plan for basis-CTE-kardinalitet på 256
Denne gang resulterede udpakningen af CTE'erne i kun fire Constant Scan-operatorer, hver med 256 rækker.
Jeg fik følgende præstationstal for denne udførelse:
CPU-tid =23516 ms, forløbet tid =25529 ms.
Denne gang ser det ud til, at ydeevnen blev forringet en smule sammenlignet med den tidligere løsning med en basis CTE-kardinalitet på 16. Faktisk steg ventetallet for ventetypen SOS_SCHEDULER_YIELD en smule til 13.176. Så det ser ud til, at vi fandt vores gyldne tal – 16!
Parallelle kontra serielle planer
Jeg eksperimenterede med at fremtvinge en parallel plan ved at bruge hintet ENABLE_PARALLEL_PLAN_PREFERENCE, men det endte med at skade ydeevnen. Faktisk, da jeg implementerede løsningen som en iTVF, fik jeg som standard en parallel plan på min maskine for store intervaller, og jeg måtte gennemtvinge en seriel plan med et MAXDOP 1-tip for at få optimal ydeevne.
Batchbehandling
Den vigtigste ressource, der bruges i planerne for mine løsninger, er CPU. I betragtning af at batchbehandling handler om at forbedre CPU-effektiviteten, især når der er tale om et stort antal rækker, er det umagen værd at prøve denne mulighed. Den vigtigste aktivitet her, der kan drage fordel af batchbehandling, er rækkenummerberegningen. Jeg testede mine løsninger i SQL Server 2019 Enterprise-udgaven. SQL Server valgte rækketilstandsbehandling for alle tidligere viste løsninger som standard. Tilsyneladende bestod denne løsning ikke den heuristik, der kræves for at aktivere batch-tilstand på rowstore. Der er et par måder at få SQL Server til at bruge batchbehandling her.
Mulighed 1 er at inddrage en tabel med et kolonnelagerindeks i løsningen. Du kan opnå dette ved at oprette en dummy-tabel med et columnstore-indeks og indføre en dummy-venstre joinforbindelse i den yderste forespørgsel mellem vores Nums CTE og den tabel. Her er dummy-tabellens definition:
OPRET TABEL dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Revider derefter den ydre forespørgsel mod Nums for at bruge FROM Nums VENSTRE YDRE JOIN dbo.BatchMe ON 1 =0. Her er et eksempel med en basis CTE-kardinalitet på 16:
DECLARE @low AS BIGINT =1, @high AS BIGINT =100000000; MED L0 SOM ( VÆLG 1 SOM c FRA (VÆRDIER(1),(1),(1),(1),(1),(1),(1),(1), (1),(1) ,(1),(1),(1),(1),(1),(1)) AS D(c) ), L1 AS (VÆLG 1 AS c FRA L0 SOM EN KRYDSJOIN L0 AS B ), L2 AS ( VÆLG 1 AS c FRA L1 SOM A CROSS JOIN L1 AS B ), L3 AS ( VÆLG 1 AS c FRA L2 SOM A CROSS JOIN L2 AS B ), Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL) )) SOM rownum FRA L3 )SELECT TOP(@high - @low + 1) @low + rownum - 1 AS nFROM Nums VENSTRE YDRE JOIN dbo.BatchMe ON 1 =0ORDER BY rownum;
Jeg fik planen vist i figur 5 for denne udførelse.
 Figur 5:Plan med batchbehandling
Figur 5:Plan med batchbehandling
Observer brugen af batch-tilstanden Window Aggregate-operator til at beregne rækkenumrene. Bemærk også, at planen ikke involverer dummy-bordet. Optimeringsværktøjet optimerede det.
Fordelen ved mulighed 1 er, at den fungerer i alle SQL Server-udgaver og er relevant i SQL Server 2016 eller senere, da batch-tilstanden Window Aggregate-operatoren blev introduceret i SQL Server 2016. Ulempen er behovet for at oprette dummy-tabellen og bl.a. det i løsningen.
Mulighed 2 for at få batchbehandling til vores løsning, forudsat at du bruger SQL Server 2019 Enterprise-udgaven, er at bruge det udokumenterede selvforklarende tip OVERRIDE_BATCH_MODE_HEURISTICS (detaljer i Dmitry Pilugins artikel), som sådan:
DECLARE @low AS BIGINT =1, @high AS BIGINT =100000000; MED L0 SOM ( VÆLG 1 SOM c FRA (VÆRDIER(1),(1),(1),(1),(1),(1),(1),(1), (1),(1) ,(1),(1),(1),(1),(1),(1)) AS D(c) ), L1 AS (VÆLG 1 AS c FRA L0 SOM EN KRYDSJOIN L0 AS B ), L2 AS ( VÆLG 1 AS c FRA L1 SOM A CROSS JOIN L1 AS B ), L3 AS ( VÆLG 1 AS c FRA L2 SOM A CROSS JOIN L2 AS B ), Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL) )) SOM rækkenummer FRA L3 )VÆLG TOP(@høj - @lav + 1) @lav + rækkenummer - 1 SOM nFRA numreORDER BY rownumOPTION(BRUG TIP('OVERRIDE_BATCH_MODE_HEURISTICS')); Fordelen ved mulighed 2 er, at du ikke behøver at oprette et dummy-bord og inddrage det i din løsning. Ulemperne er, at du skal bruge Enterprise-udgaven, bruge som minimum SQL Server 2019, hvor batch-tilstand på rowstore blev introduceret, og løsningen involverer at bruge et udokumenteret hint. Af disse grunde foretrækker jeg mulighed 1.
Her er præstationstallene, som jeg fik for de forskellige grundlæggende CTE-kardinaliteter:
Figur 6 har en ydelsessammenligning mellem de forskellige løsninger:
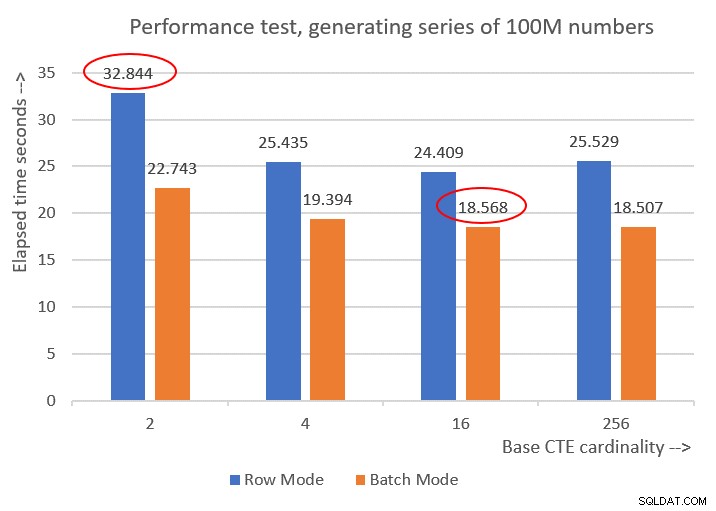 Figur 6:Præstationssammenligning
Figur 6:Præstationssammenligning
Du kan observere en anstændig forbedring af ydeevnen på 20-30 procent i forhold til modparter i rækketilstand.
Mærkeligt nok klarede løsningen med base-CTE-kardinalitet på 256 sig bedst med batch-mode-behandling. Det er dog bare en lille smule hurtigere end løsningen med basis-CTE-kardinalitet på 16. Forskellen er så lille, og sidstnævnte har en klar fordel med hensyn til kodekorthed, at jeg ville holde mig til 16.
Så min tuning-indsats endte med at give en forbedring på 43,5 procent i forhold til den oprindelige løsning med basiskardinaliteten på 2 ved brug af rækketilstandsbehandling.
Udfordringen er startet!
Jeg indsender to løsninger som mit samfundsbidrag til denne udfordring. Hvis du kører på SQL Server 2016 eller nyere og er i stand til at oprette en tabel i brugerdatabasen, skal du oprette følgende dummy-tabel:
OPRET TABEL dbo.BatchMe(col1 INT NOT NULL, INDEX idx_cs CLUSTERED COLUMNSTORE);
Og brug følgende iTVF-definition:
CREATE OR ALTER FUNCTION dbo.GetNumsItzikBatch(@low AS BIGINT, @high AS BIGINT) RETURERER TABLEASRETURN MED L0 AS (VÆLG 1 AS c FRA (VÆRDIER(1),(1),(1),(1), (1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1)) AS D (c) ), L1 AS ( VÆLG 1 AS c FRA L0 SOM A CROSS JOIN L0 AS B ), L2 AS ( VÆLG 1 AS c FRA L1 SOM A CROSS JOIN L1 AS B ), L3 AS ( VÆLG 1 AS c FRA L2 SOM A CROSS JOIN L2 AS B ), Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum FROM L3 ) SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n FROM Nums VENSTRE YDRE JOIN dbo.BatchMe ON 1 =0 BESTIL EFTER rownum;GO
Brug følgende kode til at teste det (sørg for at have Kassér resultater efter udførelse kontrolleret):
VÆLG n FRA dbo.GetNumsItzikBatch(1, 100000000) OPTION(MAXDOP 1);
Denne kode slutter om 18 sekunder på min maskine.
Hvis du af en eller anden grund ikke kan opfylde batchbehandlingsløsningens krav, indsender jeg følgende funktionsdefinition som min anden løsning:
CREATE OR ALTER FUNCTION dbo.GetNumsItzik(@low AS BIGINT, @high AS BIGINT) RETURERER TABLEASRETURN MED L0 AS (VÆLG 1 AS c FRA (VÆRDIER(1),(1),(1),(1), (1),(1),(1),(1), (1),(1),(1),(1),(1),(1),(1),(1)) AS D (c) ), L1 AS ( VÆLG 1 AS c FRA L0 SOM A CROSS JOIN L0 AS B ), L2 AS ( VÆLG 1 AS c FRA L1 SOM A CROSS JOIN L1 AS B ), L3 AS ( VÆLG 1 AS c FRA L2 SOM A CROSS JOIN L2 AS B ), Nums AS ( SELECT ROW_NUMBER() OVER(ORDER BY (SELECT NULL)) AS rownum FROM L3 ) SELECT TOP(@high - @low + 1) @low + rownum - 1 AS n FROM Nums BESTIL EFTER rownum;GO
Brug følgende kode til at teste det:
VÆLG n FRA dbo.GetNumsItzik(1, 100000000) OPTION(MAXDOP 1);
Denne kode slutter om 24 sekunder på min maskine.
Din tur!