Enkelte prædikater
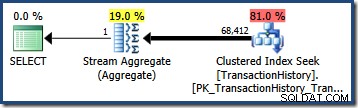
Det er ofte ligetil at estimere antallet af rækker, der er kvalificeret af et enkelt forespørgselsprædikat. Når et prædikat laver en simpel sammenligning mellem en kolonne og en skalarværdi, er chancerne gode for, at kardinalitetsberegningen vil kunne udlede et estimat af god kvalitet fra statistikhistogrammet. For eksempel producerer følgende AdventureWorks-forespørgsel et nøjagtigt korrekt estimat på 203 rækker (forudsat at der ikke er foretaget ændringer i dataene, siden statistikken blev bygget):
VÆLG COUNT_BIG(*) FROM Production.TransactionHistory AS THWHERE TH.TransactionDate ='20070903';
Ser på statistikhistogrammet for TransactionDate kolonne, er det tydeligt at se, hvor dette skøn kom fra:
DBCC SHOW_STATISTICS ( 'Production.TransactionHistory', 'TransactionDate') MED HISTOGRAM;
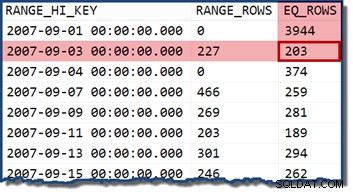
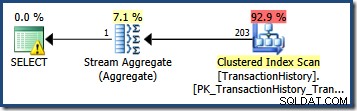
Hvis vi ændrer forespørgslen til at angive en dato, der falder inden for en histogram-bøtte, antager kardinalitetsestimatoren, at værdierne er jævnt fordelt. Bruger datoen 2007-09-02 producerer et estimat på 227 rækker (fra RANGE_ROWS indgang). Som en interessant sidebemærkning forbliver estimatet på 227 rækker, uanset hvilken tidsdel vi måtte tilføje til datoværdien (TransactionDate kolonne er en datetime datatype).
Hvis vi prøver forespørgslen igen med datoen 2007-09-05 eller 2007-09-06 (begge falder mellem 2007-09-04 og 2007-09-07 histogramtrin), antager kardinalitetsestimatoren 466 RANGE_ROWS er ligeligt fordelt mellem de to værdier og estimerer 233 rækker i begge tilfælde.
Der er mange andre detaljer til kardinalitetsestimater for simple prædikater, men det foregående vil tjene som en genopfriskning til vores nuværende formål.
Problemerne med flere prædikater
Når en forespørgsel indeholder mere end ét kolonneprædikat, bliver kardinalitetsestimatering sværere. Overvej følgende forespørgsel med to simple prædikater (som hver især er lette at estimere alene):
VÆLG COUNT_BIG(*) FROM Production.TransactionHistory SOM THWHERE TH.TransactionID MELLEM 100000 OG 168412 OG TH.TransactionDate MELLEM '20070901' OG '20080313';
De specifikke værdiområder i forespørgslen er bevidst valgt, så begge prædikater identificerer nøjagtig de samme rækker. Vi kunne nemt ændre forespørgselsværdierne for at resultere i en hvilken som helst mængde af overlap, inklusive slet ingen overlapning. Forestil dig nu, at du er kardinalitetsestimator:hvordan ville du udlede et kardinalitetsestimat for denne forespørgsel?
Problemet er sværere, end det måske umiddelbart lyder. Som standard opretter SQL Server automatisk enkeltkolonnestatistik på begge prædikatkolonner. Vi kan også oprette multi-kolonner statistik manuelt. Giver dette os nok information til at producere et godt skøn for disse specifikke værdier? Hvad med det mere generelle tilfælde, hvor der kan være enhver grad af overlapning?
Ved at bruge de to enkeltkolonne statistiske objekter kan vi nemt udlede et estimat for hvert prædikat ved hjælp af histogrammetoden beskrevet i det foregående afsnit. For de specifikke værdier i forespørgslen ovenfor viser histogrammerne, at TransactionID rækkevidde forventes at matche 68412.4 rækker og TransactionDate rækkevidde forventes at matche 68.413 rækker. (Hvis histogrammerne var perfekte, ville disse to tal være nøjagtigt ens.)
Hvad histogrammerne ikke kan fortæl os, hvor mange fra disse to sæt rækker vil være de samme rækker . Alt, hvad vi kan sige baseret på histogramoplysningerne er, at vores estimat skal være et sted mellem nul (for ingen overlap overhovedet) og 68412,4 rækker (komplet overlap).
Oprettelse af statistik med flere kolonner giver ingen hjælp til denne forespørgsel (eller for intervalforespørgsler generelt). Statistik med flere kolonner skaber stadig kun et histogram over den først navngivne kolonne, hvilket i det væsentlige duplikerer histogrammet, der er forbundet med en af de automatisk oprettede statistikker. Den ekstra densitet oplysninger, der leveres af statistikken med flere kolonner, kan være nyttige til at give gennemsnits-case-oplysninger for forespørgsler, der indeholder flere lighedsprædikater, men de er ikke til nogen hjælp for os her.
For at producere et estimat med en høj grad af tillid ville vi have brug for SQL Server til at give bedre information om datadistributionen – noget i retning af en multidimensional statistik histogram. Så vidt jeg ved, tilbyder ingen kommerciel databasemotor i øjeblikket en facilitet som denne, selvom der er udgivet adskillige tekniske artikler om emnet (inklusive en Microsoft Research, der brugte en intern udvikling af SQL Server 2000).
Uden at vide noget om datakorrelationer og overlapninger for bestemte værdiområder, er det ikke klart, hvordan vi skal gå videre for at producere et godt estimat for vores forespørgsel. Så hvad gør SQL Server her?
SQL Server 7 – 2012
Kardinalitetsestimatoren i disse versioner af SQL Server antager generelt, at værdier af forskellige attributter i en tabel er fordelt fuldstændig uafhængigt af hinanden. Denne uafhængighedsantagelse er sjældent en nøjagtig afspejling af de virkelige data, men den har den fordel, at den giver enklere beregninger.
OG Selektivitet
Ved at bruge uafhængighedsantagelsen, to prædikater forbundet med AND (kendt som en konjunktion ) med selektiviteter S1 og S2 , resulterer i en kombineret selektivitet på:
(S1 * S2)
Hvis udtrykket ikke er bekendt for dig, selektivitet er et tal mellem 0 og 1, der repræsenterer den brøkdel af rækker i tabellen, der passerer prædikatet. For eksempel, hvis et prædikat vælger 12 rækker fra en tabel med 100 rækker, er selektiviteten (12/100) =0,12.
I vores eksempel er TransactionHistory tabel indeholder 113.443 rækker i alt. Prædikatet på TransactionID estimeres (fra histogrammet) til at kvalificere 68.412,4 rækker, så selektiviteten er (68.412,4 / 113.443) eller ca. 0,603055 . Prædikatet på TransactionDate er ligeledes estimeret til at have en selektivitet på (68.413 / 113.443) =ca. 0,603061 .
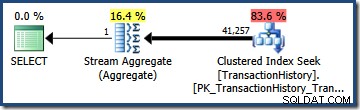
Multiplicering af de to selektiviteter (ved hjælp af formlen ovenfor) giver et kombineret selektivitetsestimat på 0,363679 . Multiplicering af denne selektivitet med bordets kardinalitet (113.443) giver det endelige estimat på 41.256,8 rækker:
ELLER Selektivitet
To prædikater forbundet med OR (en adskillelse ) med selektiviteter S1 og S2 , resulterer i en kombineret selektivitet på:
(S1 + S2) – (S1 * S2)
Intuitionen bag formlen er at tilføje de to selektiviteter og derefter trække estimatet for deres konjunktion (ved at bruge den foregående formel). Det er klart, at vi kunne have to prædikater, hver med selektivitet 0,8, men blot at lægge dem sammen ville producere en umulig kombineret selektivitet på 1,6. På trods af uafhængighedsantagelsen må vi erkende, at de to prædikater kan have et overlap, så for at undgå dobbelttælling trækkes den estimerede selektivitet af konjunktionen fra.
Vi kan nemt ændre vores kørende eksempel til at bruge OR :
VÆLG COUNT_BIG(*) FROM Production.TransactionHistory SOM THWHERE TH.TransactionID MELLEM 100000 OG 168412 ELLER TH.TransactionDate MELLEM '20070901' OG '20080313';
Substitution af prædikatselektiviteterne i OR formel giver en kombineret selektivitet på:
(0.603055 + 0.603061) - (0.603055 * 0.603061) = 0.842437
Multipliceret med antallet af rækker i tabellen giver denne selektivitet os det endelige kardinalitetsestimat på 95.568,6 :
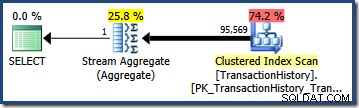
Ingen af estimaterne (41.257 for AND forespørgsel; 95.569 for OR query) er særligt godt, fordi begge er baseret på en modelleringsantagelse, der ikke matcher datafordelingen særlig godt. Begge forespørgsler returnerer faktisk 68.413 rækker (fordi prædikaterne identificerer nøjagtig de samme rækker).
Sporingsflag 4137 – Minimum selektivitet
For SQL Server 2008 (R1) til og med 2012 udgav Microsoft en rettelse, der ændrer den måde, hvorpå selektivitet beregnes for AND kun kasus (konjunktive prædikater). Knowledge Base-artiklen i det link indeholder ikke mange detaljer, men det viser sig, at rettelsen ændrer den anvendte selektivitetsformel. I stedet for at multiplicere de individuelle selektiviteter, bruger kardinalitetsestimater for konjunktive prædikater nu den laveste selektivitet alene.
For at aktivere den ændrede adfærd kræves understøttet sporingsflag 4137. En separat Knowledge Base-artikel dokumenterer, at dette sporingsflag også understøttes til brug pr. forespørgsel via QUERYTRACEON tip:
VÆLG COUNT_BIG(*)FROM Production.TransactionHistory AS THWHERE TH.TransactionID MELLEM 100000 OG 168412 OG TH.TransactionDate MELLEM '20070901' OG '20080313'OPTION (QUERYTRACEON );137);Med dette flag aktivt bruger kardinalitetsestimat minimumselektiviteten af de to prædikater, hvilket resulterer i et estimat på 68.412,4 rækker:
Dette er tilfældigvis næsten perfekt til vores forespørgsel, fordi vores testprædikater er nøjagtigt korrelerede (og estimaterne afledt af basishistogrammerne er også meget gode).
Det er rimeligt sjældent, at prædikater er perfekt korreleret som dette med rigtige data, men sporflaget kan alligevel hjælpe i nogle tilfælde. Bemærk, at minimumselektivitetsadfærden vil gælde for alle konjunktive (
AND) prædikater i forespørgslen; der er ingen måde at specificere adfærden på et mere detaljeret niveau.Der er ikke noget tilsvarende sporingsflag til at estimere disjunktiv (
OR) prædikater ved brug af minimum selektivitet.SQL Server 2014
Selektivitetsberegning i SQL Server 2014 opfører sig på samme måde som tidligere versioner (og sporingsflag 4137 fungerer som før), hvis databasekompatibilitetsniveauet er sat lavere end 120, eller hvis sporingsflag 9481 er aktiv. Indstilling af databasekompatibilitetsniveauet er den officielle måde at bruge pre-2014 kardinalitet estimator i SQL Server 2014. Trace flag 9481 er effektiv til at gøre det samme som i skrivende stund, og fungerer også med
QUERYTRACEON, selvom det ikke er dokumenteret at gøre det. Der er ingen måde at vide, hvad RTM-adfærden for dette flag vil være.Hvis den nye kardinalitetsestimator er aktiv, bruger SQL Server 2014 en anden standardformel til at kombinere konjunktive og disjunktive prædikater. Selvom den er udokumenteret, er selektivitetsformlen for konjunktioner blevet opdaget og dokumenteret flere gange nu. Den første, jeg husker at have set, er i dette portugisiske blogindlæg, og den opfølgende del to udkom et par uger senere. For at opsummere er 2014-tilgangen til konjunktive prædikater at bruge eksponentiel backoff: givet en tabel med kardinalitet C, og prædikatselektiviteter S1 , S2 , S3 … Sn , hvor S1 er den mest selektive og Sn mindst:
Estimate = C * S1 * SQRT(S2) * SQRT(SQRT(S3)) * SQRT(SQRT(SQRT(S4))) …Estimatet beregnes som det mest selektive prædikat ganget med tabellens kardinalitet, ganget med kvadratroden af det næstmest selektive prædikat, og så videre, hvor hver ny selektivitet får en ekstra kvadratrod.
Når man husker på, at selektivitet er et tal mellem 0 og 1, er det klart, at anvendelse af en kvadratrod flytter tallet tættere på 1. Effekten er at tage højde for alle prædikater i det endelige estimat, men at reducere virkningen af de mindre selektive prædikater eksponentielt. Der er uden tvivl mere logik i denne idé end under uafhængighedsantagelsen , men det er stadig en fast formel – den ændrer sig ikke baseret på den faktiske grad af datakorrelation.
Kardinalitetsestimatoren for 2014 bruger en eksponentiel backoff-formel for begge konjunktive og disjunktive prædikater, selvom formlen bruges i disjunktivet (
OR) sagen er endnu ikke dokumenteret (officielt eller på anden måde).SQL Server 2014 Selektivitetssporingsflag
Sporingsflag 4137 (for at bruge minimumselektivitet) gør ikke arbejde i SQL Server 2014, hvis den nye kardinalitetsestimator bruges ved kompilering af en forespørgsel. I stedet er der et nyt sporingsflag 9471 . Når dette flag er aktivt, bruges minimumselektivitet til at estimere flere konjunktive og disjunktive prædikater. Dette er en ændring i forhold til 4137-adfærden, som kun påvirkede konjunktive prædikater.
På samme måde kan du spore flag 9472 kan specificeres til at antage uafhængighed for flere prædikater, som tidligere versioner gjorde. Dette flag adskiller sig fra 9481 (for at bruge kardinalitetsberegningen før 2014), fordi den nye kardinalitetsestimator under 9472 stadig vil blive brugt, kun selektivitetsformlen for flere prædikater er påvirket.
Hverken 9471 eller 9472 er dokumenteret i skrivende stund (selvom de kan være på RTM).
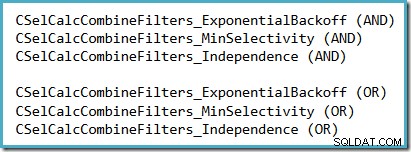
En bekvem måde at se, hvilken selektivitetsantagelse, der bruges i SQL Server 2014 (med den nye kardinalitetsestimator aktiv), er at undersøge selektivitetsberegningens fejlretningsoutput, der produceres, når sporingsflag 2363 og 3604 er aktive. Sektionen, du skal kigge efter, vedrører selektivitetsberegneren, der kombinerer filtre, hvor du vil se et af følgende, afhængigt af hvilken antagelse der bruges:
Der er ingen realistisk udsigt til, at 2363 vil blive dokumenteret eller understøttet.
Sidste tanker
Der er intet magisk ved eksponentiel backoff, minimum selektivitet eller uafhængighed. Hver tilgang repræsenterer en (uhyre) forenklingsantagelse, der måske eller måske ikke giver et acceptabelt skøn for en bestemt forespørgsel eller datadistribution.
I nogle henseender eksponentiel backoff repræsenterer et kompromis mellem de to yderpunkter uafhængighed og minimum selektivitet . Alligevel er det vigtigt ikke at have urimelige forventninger til det. Indtil der findes en mere nøjagtig måde at estimere selektivitet for flere prædikater (med rimelige ydeevnekarakteristika), er det fortsat vigtigt at være opmærksom på modelbegrænsningerne og passe på (potentielle) estimeringsfejl i overensstemmelse hermed.
De forskellige sporflag giver en vis kontrol over, hvilken antagelse der bruges, men situationen er langt fra perfekt. For det første er den fineste granularitet, hvormed et flag kan anvendes, en enkelt forespørgsel – estimeringsadfærd kan ikke specificeres på prædikatniveau. Hvis du har en forespørgsel, hvor nogle prædikater er korrelerede og andre uafhængige, hjælper sporingsflagene dig måske ikke meget uden at omstrukturere forespørgslen på den ene eller anden måde. Ligeledes kan en problematisk forespørgsel have prædikatkorrelationer, der ikke er modelleret godt af nogen af de tilgængelige muligheder.
Ad hoc brug af sporingsflag kræver de samme tilladelser som
DBCC TRACEON– nemlig sysadmin . Det er sikkert fint til personlig test, men til produktion skal du bruge en planvejledning ved hjælp afQUERYTRACEONtip er en bedre mulighed. Med en planguide kræves der ingen yderligere tilladelser for at udføre forespørgslen (selvom der selvfølgelig kræves forhøjede tilladelser for at oprette planguiden).