Gæsteforfatter:Monica Rathbun (@SQLEspresso)
Nogle gange kan problemer med hardwareydeevne, såsom Disk I/O-latens, koges ned til ikke-optimeret arbejdsbyrde snarere end underpræsterende hardware. Mange databaseadministratorer, inklusive mig, vil straks give lagringen skylden for langsommeligheden. Før du går og bruger et væld af penge på ny hardware, bør du altid undersøge din arbejdsbyrde for unødvendig I/O.
Ting at undersøge
| Vare | I/O-påvirkning | Mulige løsninger |
|---|---|---|
| Ubrugte indekser | Ekstra skrivninger | Fjern/deaktiver indeks |
| Manglende indekser | Ekstra læsninger | Tilføj indeks / dækkende indekser |
| Implicitte konverteringer | Ekstra læsninger og skrivninger | Covert eller Cast Field ved kilden før evaluering af værdi |
| Funktioner | Ekstra læsninger og skrivninger | Fjernede dem, konverter dataene før evaluering |
| ETL | Ekstra læsninger og skrivninger | Brug SSIS, Replikering, Change Data Capture, Tilgængelighedsgrupper |
| Ordre- og gruppebys | Ekstra læsninger og skrivninger | Fjern dem, hvor det er muligt |
Ubrugte indekser
Vi kender alle styrken af et indeks. At have de rigtige indekser kan gøre lysår af en forskel i forespørgselshastighed. Men hvor mange af os vedligeholder løbende vores indekser ud over indeksombygning og omorganiseringer? Det er vigtigt regelmæssigt at køre et indeksscript for at evaluere, hvilke indekser der rent faktisk bliver brugt. Jeg bruger personligt Glenn Berrys diagnostiske forespørgsler til at gøre dette.
Du vil blive overrasket over at opdage, at nogle af dine indekser slet ikke er blevet læst. Disse indekser er en belastning for ressourcer, især på en meget transaktionel tabel. Når du ser på resultaterne, skal du være opmærksom på de indekser, der har et højt antal skrivninger kombineret med et lavt antal læsninger. I dette eksempel kan du se, at jeg spilder skriverier. Det ikke-klyngede indeks er blevet skrevet til 11 millioner gange, men kun læst to gange.

Jeg starter med at deaktivere de indekser, der falder ind under denne kategori, og dropper dem derefter, når jeg har bekræftet, at der ikke er opstået problemer. At udføre denne øvelse rutinemæssigt kan i høj grad reducere unødvendige I/O-skrivninger til dit system, men husk, at brugsstatistikker på dine indekser kun er så gode som den sidste genstart, så sørg for, at du har indsamlet data i en fuld forretningscyklus, før du afskriver et indeks som "ubrugelig".
Manglende indekser
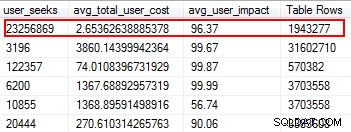
Manglende indekser er en af de nemmeste ting at rette; når alt kommer til alt, når du kører en eksekveringsplan, vil den fortælle dig, om nogen indekser ikke blev fundet, men det ville have været nyttigt. Men vent, jeg håber, at du ikke bare vilkårligt tilføjer indekser baseret på dette forslag. Hvis du gør dette, kan du oprette duplikerede indekser og indekser, der kan have minimal brug og derfor spilde I/O. Igen, tilbage til Glenns scripts, giver han os et fantastisk værktøj til at evaluere anvendeligheden af et indeks ved at give brugersøgninger, brugerpåvirkning og antal rækker. Vær opmærksom på dem med høj læsning sammen med lave omkostninger og effekt. Dette er et godt sted at starte, og det vil hjælpe dig med at reducere læse-I/O.
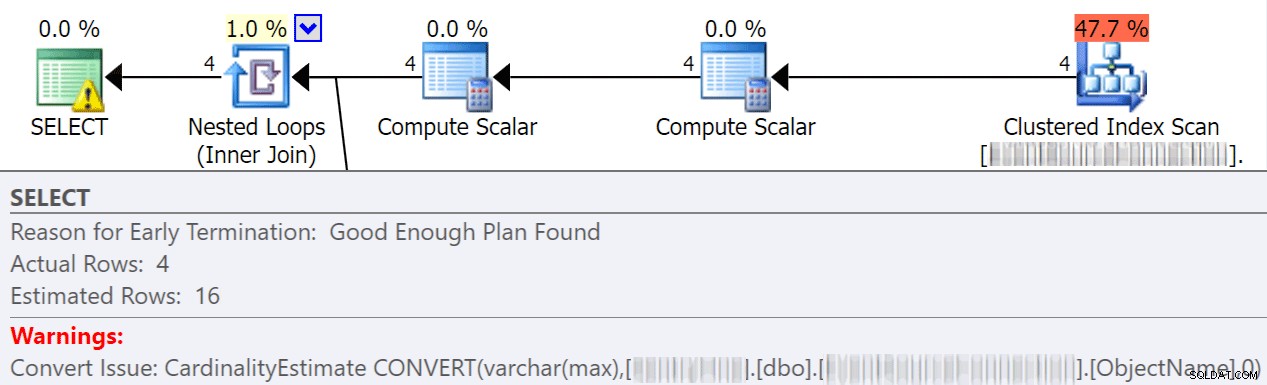
Implicitte konverteringer
Implicitte konverteringer sker ofte, når en forespørgsel sammenligner to eller flere kolonner med forskellige datatyper. I eksemplet nedenfor skal systemet udføre ekstra I/O for at sammenligne en varchar(max)-kolonne med en nvarchar(4000)-kolonne, hvilket fører til en implicit konvertering og i sidste ende en scanning i stedet for en søgning. Ved at fikse tabellerne til at have matchende datatyper, eller blot konvertere denne værdi før evaluering, kan du i høj grad reducere I/O og forbedre kardinalitet (de estimerede rækker, som optimeringsværktøjet bør forvente).
dbo.table1 t1 JOIN dbo.table2 t2 ON t1.ObjectName = t2.TableName
Jonathan Kehayias går meget mere i detaljer i dette fantastiske indlæg:"Hvor dyre er implicitte konverteringer på kolonnesiden?"
Funktioner
En af de mest undgåelige, nemme at rette ting, jeg er stødt på, der sparer på I/O-udgifter, er at fjerne funktioner fra hvor-klausuler. Et perfekt eksempel er en datosammenligning, som vist nedenfor.
CONVERT(Date,FromDate) >= CONVERT(Date, dbo.f_realdate(MyField)) AND (CONVERT(Date,ToDate) <= CONVERT(Date, dbo.f_realdate(MyField))
Uanset om det er på en JOIN-sætning eller i en WHERE-sætning, bevirker dette, at hver kolonne konverteres, før den evalueres. Ved blot at konvertere disse kolonner før evaluering til en midlertidig tabel kan du eliminere et væld af unødvendige I/O.
Eller endnu bedre, lad være med at udføre nogen konverteringer overhovedet (i dette specifikke tilfælde taler Aaron Bertrand her om at undgå funktioner i where-klausulen, og bemærk, at dette stadig kan være dårligt, selvom konvertering til dato er sargerbar).
ETL
Tag dig tid til at undersøge, hvordan dine data indlæses. Afkorter og genindlæser du borde? Kan du implementere replikering, en skrivebeskyttet AG-replika eller logforsendelse i stedet for? Bliver alle tabellerne skrevet til rent faktisk læst? Hvordan indlæser du dataene? Er det gennem lagrede procedurer eller SSIS? At undersøge ting som dette kan reducere I/O dramatisk.
I mit miljø fandt jeg ud af, at vi afkortede 48 borde dagligt med over 120 millioner rækker hver morgen. Oven i det læste vi 9,6 millioner rækker hver time. Du kan forestille dig, hvor meget unødvendig I/O det skabte. I mit tilfælde var implementering af transaktionsreplikering min foretrukne løsning. Da vi først var implementeret, havde vi langt færre brugerklager over sænkninger i vores indlæsningstider, hvilket oprindeligt var blevet tilskrevet den langsomme lagring.
Bestil efter og grupper efter
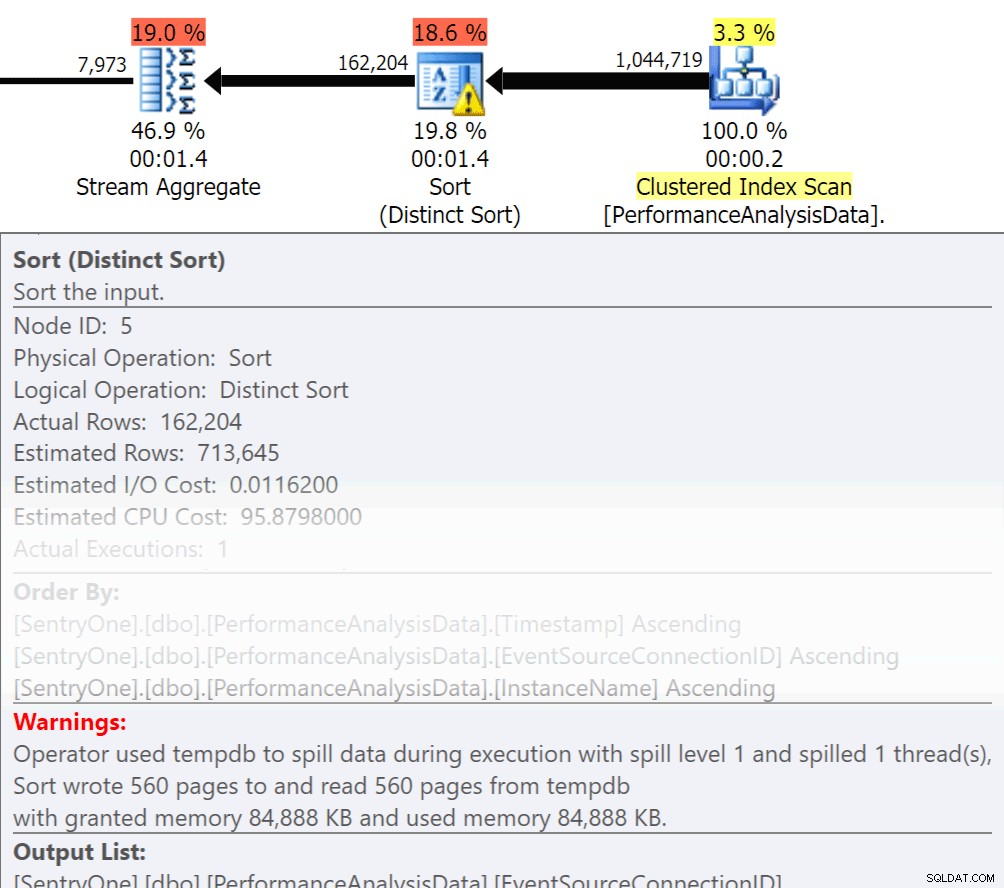 Spørg dig selv, skal disse data returneres i rækkefølge? Skal vi virkelig gruppere i proceduren, eller kan vi håndtere det i en rapport eller ansøgning? Order By og Group By operationer kan forårsage, at læsninger spredes over til disken, hvilket forårsager yderligere disk I/O. Hvis disse handlinger er berettigede, skal du sikre dig, at du har understøttende indekser og frisk statistik over de kolonner, der sorteres eller grupperes. Dette vil hjælpe optimizeren under planoprettelse. Da vi nogle gange bruger Order By og Group By i vikartabeller. sørg for, at du har Auto Create Statistics slået til for TEMPDB såvel som dine brugerdatabaser. Jo mere opdateret statistikkerne er, jo bedre kardinalitet kan optimeringsværktøjet få, hvilket resulterer i bedre planer, mindre afsmitning og mindre I/O.
Spørg dig selv, skal disse data returneres i rækkefølge? Skal vi virkelig gruppere i proceduren, eller kan vi håndtere det i en rapport eller ansøgning? Order By og Group By operationer kan forårsage, at læsninger spredes over til disken, hvilket forårsager yderligere disk I/O. Hvis disse handlinger er berettigede, skal du sikre dig, at du har understøttende indekser og frisk statistik over de kolonner, der sorteres eller grupperes. Dette vil hjælpe optimizeren under planoprettelse. Da vi nogle gange bruger Order By og Group By i vikartabeller. sørg for, at du har Auto Create Statistics slået til for TEMPDB såvel som dine brugerdatabaser. Jo mere opdateret statistikkerne er, jo bedre kardinalitet kan optimeringsværktøjet få, hvilket resulterer i bedre planer, mindre afsmitning og mindre I/O.
Nu har Group By bestemt sin plads, når det kommer til at aggregere data i stedet for at returnere et væld af rækker. Men nøglen her er at reducere I/O, tilføjelsen af aggregeringen tilføjer I/O'en.
Oversigt
Dette er bare toppen af isbjerget af ting at gøre, men et godt sted at begynde for at reducere I/O. Før du giver hardware skylden for dine latensproblemer, skal du tage et kig på, hvad du kan gøre for at minimere disktrykket.
Om forfatteren
 Monica Rathbun er i øjeblikket konsulent hos Denny Cherry &Associates Consulting og en Microsoft Data Platform MVP. Hun har været Lone DBA i 15 år, hvor hun har arbejdet med alle aspekter af SQL Server og Oracle. Hun rejser og taler på SQLSaturdays og hjælper andre Lone DBA'er med teknikker til, hvordan man kan udføre manges job. Monica er leder af Hampton Roads SQL Server User Group og er en Mid-Atlantic Pass Regional Mentor. Du kan altid finde Monica på Twitter (@SQLEspresso), der deler nyttige tips og tricks ud til sine følgere. Når hun ikke har travlt med arbejde, vil du finde hende spille taxachauffør for sine to døtre frem og tilbage til dansetimer.
Monica Rathbun er i øjeblikket konsulent hos Denny Cherry &Associates Consulting og en Microsoft Data Platform MVP. Hun har været Lone DBA i 15 år, hvor hun har arbejdet med alle aspekter af SQL Server og Oracle. Hun rejser og taler på SQLSaturdays og hjælper andre Lone DBA'er med teknikker til, hvordan man kan udføre manges job. Monica er leder af Hampton Roads SQL Server User Group og er en Mid-Atlantic Pass Regional Mentor. Du kan altid finde Monica på Twitter (@SQLEspresso), der deler nyttige tips og tricks ud til sine følgere. Når hun ikke har travlt med arbejde, vil du finde hende spille taxachauffør for sine to døtre frem og tilbage til dansetimer.