Da jeg var i Chicago for et par uger siden til en af vores Immersion Events, havde en deltager et statistikspørgsmål. Jeg vil ikke gå ind i alle detaljerne omkring problemet, men deltageren nævnte, at statistik blev opdateret ved hjælp af sp_updatestats . Dette er en metode til at opdatere statistik, som jeg aldrig har anbefalet; Jeg har altid anbefalet en kombination af indeksgenopbygninger og UPDATE STATISTICS at holde statistik opdateret. Hvis du ikke er bekendt med sp_updatestats , det er en kommando, der køres for hele databasen for at opdatere statistik. Men som Kimberly påpegede over for deltageren, sp_updatestats vil opdatere en statistik, så længe den har fået en række ændret. Hov. Jeg åbnede straks Books Online og for sp_updatestats du vil se dette:
Nu indrømmer jeg, at jeg lavede en antagelse om, hvad "...kræver opdatering baseret på rowmodctr-oplysningerne i sys.sysindexes-katalogvisningen..." betød. Jeg antog, at opdateringsbeslutningen ville følge den samme logik, som indstillingen Automatisk opdateringsstatistik følger, hvilket er:
- Tabelstørrelsen er gået fra 0 til>0 rækker (test 1).
- Antallet af rækker i tabellen, da statistikken blev indsamlet, var 500 eller mindre, og colmodctr i den forreste kolonne i statistikobjektet er ændret med mere end 500 siden da (test 2).
- Tabellen havde mere end 500 rækker, da statistikken blev indsamlet, og colmodctr i den forreste kolonne i statistikobjektet er ændret med mere end 500 + 20 % af antallet af rækker i tabellen, da statistikken blev indsamlet ( test 3).
Denne logik følges ikke for sp_updatestats . Faktisk er logikken så utrolig enkel, at den er skræmmende:Hvis en række ændres, opdateres statistikken. En række. EN RÆKKE. Hvad er min bekymring? Jeg er bekymret over omkostningerne ved at opdatere statistikker for en masse statistikker, der ikke virkelig skal opdateres. Lad os se nærmere på sp_updatestats .
Vi starter med en ny kopi af AdventureWorks2012-databasen, som du kan downloade fra Codeplex. Jeg vil først opdatere rækker i tre forskellige tabeller:
USE [AdventureWorks2012];
GO
SET NOCOUNT ON;
GO
UPDATE [Production].[Product]
SET [Name] = 'Bike Chain'
WHERE [ProductID] = 952;
UPDATE [Person].[Person]
SET [LastName] = 'Cameron'
WHERE [LastName] = 'Diaz';
GO
INSERT INTO Sales.SalesReason
(Name, ReasonType, ModifiedDate)
VALUES('Stats', 'Test', GETDATE());
GO 10000
Vi har ændret én række i Production.Product , 211 rækker i Person.Person , og vi tilføjede 10.000 rækker til Sales.SalesReason . Hvis sp_updatestats procedure fulgte den samme logik for opdateringer som indstillingen Automatisk opdatering af statistik, derefter kun Sales.SalesReason ville opdatere, fordi den havde 10 rækker til at starte (hvorimod de 211 rækker blev opdateret i Person.Person repræsentere omkring en procent af tabellen). Men hvis vi graver i sp_updatestats , kan vi se, at den anvendte logik er anderledes. Bemærk, at jeg kun uddrager erklæringerne fra sp_updatestats der bruges til at bestemme, hvilke statistikker der opdateres.
En cursor itererer gennem alle brugerdefinerede tabeller og interne tabeller i databasen:
declare ms_crs_tnames cursor local fast_forward read_only for select name, object_id, schema_id, type from sys.objects o where o.type = 'U' or o.type = 'IT' open ms_crs_tnames fetch next from ms_crs_tnames into @table_name, @table_id, @sch_id, @table_type
En anden markør går gennem statistikken for hver tabel og udelukker dynger og hypotetiske indekser og statistikker. Bemærk, at sys.sysindexes bruges i sp_helpstats . Sysindexes er en SQL Server 2000-systemtabel og er planlagt til at blive fjernet i en fremtidig version af SQL Server. Dette er interessant, da den anden metode til at bestemme rækker opdaterede er sys.dm_db_stats_properties DMF, som kun er tilgængelig i SQL 2008 R2 SP2 og SQL 2012 SP1.
set @index_names = cursor local fast_forward read_only for select name, indid, rowmodctr from sys.sysindexes where id = @table_id and indid > 0 and indexproperty(id, name, 'ishypothetical') = 0 order by indid
Efter lidt forberedelse og yderligere logik kommer vi til en IF erklæring, der afslører, at sp_updatestats filtrerer statistik fra, der ikke har fået opdateret nogen rækker... bekræfter, at selvom kun én række er blevet ændret, vil statistikken blive opdateret. Der er også en check for @is_ver_current , som er bestemt af en indbygget, intern funktion.
if ((@ind_rowmodctr <> 0) or ((@is_ver_current is not null) and (@is_ver_current = 0)))
Et par flere kontroller relateret til sampling og kompatibilitetsniveau, og derefter UPDATE sætning udføres for statistikken. Før vi rent faktisk kører sp_updatestats, kan vi forespørge sys.sysindexes for at se, hvilke statistikker der opdateres:
SELECT [o].[name], [si].[indid], [si].[name], [si].[rowmodctr], [si].[rowcnt], [o].[type] FROM [sys].[objects] [o] JOIN [sys].[sysindexes] [si] ON [o].[object_id] = [si].[id] WHERE ([o].[type] = 'U' OR [o].[type] = 'IT') AND [si].[indid] > 0 AND [si].[rowmodctr] <> 0 ORDER BY [o].[type] DESC, [o].[name];
Ud over de tre tabeller, som vi har ændret, er der en anden statistik for en brugertabel (dbo.DatabaseLog ) og tre interne statistikker, der vil blive opdateret:
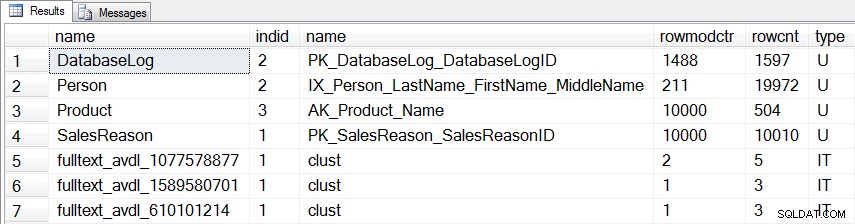
Statistik, der vil blive opdateret
Hvis vi kører sp_updatestats for AdventureWorks-databasen viser outputtet hver tabel og de(n) opdaterede statistik(er). Outputtet nedenfor er ændret til kun at vise opdaterede statistikker:
Opdaterer [sys].[fulltext_avdl_1589580701]
[clust] er blevet opdateret...
1 indeks(er)/statistik(er) er blevet opdateret, 0 krævede ikke opdatering.
…
Opdaterer [dbo].[DatabaseLog]
[PK_DatabaseLog_DatabaseLogID] er blevet opdateret...
1 indeks(er)/statistik(er) er blevet opdateret, 0 krævede ikke opdatering.
…
Opdaterer [sys].[fulltext_avdl_1077578877]
[clust] er blevet opdateret...
1 indeks(er)/statistik(er) er blevet opdateret, 0 krævede ikke opdatering.
…
Opdaterer [Person].[Person]
[PK_Person_BusinessEntityID], opdatering er ikke nødvendig...
[IX_Person_LastName_FirstName_MiddleName] er blevet opdateret...
[AK_Person_rowguid], opdatering er ikke nødvendig...
1 indeks(er)/statistik(er) er blevet opdateret, 2 krævede ikke opdatering.
…
Opdaterer [Sales].[SalesReason]
[PK_SalesReason_SalesReasonID] er blevet opdateret...
1 indeks(er)/statistik(er) er blevet opdateret, 0 krævede ikke opdatering.
…
Opdaterer [Produktion].[Produkt]
[PK_Product_ProductID], opdatering er ikke nødvendig...
[AK_Product_ProductNumber], opdatering er ikke nødvendig...
[AK_Product_Name] er blevet opdateret...
[ AK_Product_rowguid], opdatering er ikke nødvendig…
[_WA_Sys_00000013_75A278F5], opdatering er ikke nødvendig…
[_WA_Sys_00000014_75A278F5], opdatering er ikke nødvendig…
[_WA_050_0000… opdatering er ikke nødvendig…>[_WA_Sys_0000000C_75A278F5], opdatering er ikke nødvendig...
1 indeks(er)/statistik(er) er blevet opdateret, 7 krævede ikke opdatering.
…
Statistikken for alle tabeller er blevet opdateret.
Den sidste linje i outputtet er lidt misvisende - statistikker for alle tabeller er ikke blevet opdateret, kun de statistikker, der har fået en række eller flere ændret, er blevet opdateret. Og igen, ulempen ved det er, at der måske blev brugt ressourcer, som ikke behøvede at være. Hvis en statistik kun har én række ændret, skal den så opdateres? Nej. Hvis den har opdateret 10.000 rækker, skal den så opdateres? Nå, det afhænger af. Hvis tabellen kun har 5.000 rækker, så absolut; hvis tabellen har 1 million rækker, så nej, da kun én procent af tabellen er blevet ændret.
Take-away her er, at hvis du bruger sp_updatestats for at opdatere dine statistikker, spilder du højst sandsynligt ressourcer, inklusive CPU, I/O og tempdb. Ydermere tager det tid at opdatere hver statistik, og hvis du har et stramt vedligeholdelsesvindue, har du sandsynligvis andre vedligeholdelsesopgaver, der kan udføres på den tid, i stedet for unødvendige opdateringer. Endelig giver du sandsynligvis ikke nogen præstationsfordele ved at opdatere statistik, når så få rækker har ændret sig. Fordelingsændringen er sandsynligvis ubetydelig, hvis kun en lille procentdel af rækkerne er blevet ændret, så histogrammet og tæthedsværdierne ender ikke med at ændre sig så meget. Derudover skal du huske, at opdatering af statistik ugyldiggør forespørgselsplaner, der bruger disse statistikker. Når disse forespørgsler udføres, bliver planer gengenereret, og planen vil sandsynligvis være nøjagtig den samme, som den var før, fordi der ikke var nogen væsentlig ændring i histogrammet. Der er en omkostning ved at genkompilere forespørgselsplaner – det er ikke altid nemt at måle, men det bør ikke ignoreres.
En bedre metode til at administrere statistik - fordi du skal administrere statistik - er at implementere et planlagt job, der opdaterer baseret på procentdelen af rækker, der er blevet ændret. Du kan bruge den førnævnte forespørgsel, der udspørger sys.sysindexes , eller du kan bruge forespørgslen nedenfor, der udnytter den nye DMF tilføjet i SQL Server 2008 R2 SP2 og SQL Server 2012 SP1:
SELECT [sch].[name] + '.' + [so].[name] AS [TableName] , [ss].[name] AS [Statistic], [sp].[last_updated] AS [StatsLastUpdated] , [sp].[rows] AS [RowsInTable] , [sp].[rows_sampled] AS [RowsSampled] , [sp].[modification_counter] AS [RowModifications] FROM [sys].[stats] [ss] JOIN [sys].[objects] [so] ON [ss].[object_id] = [so].[object_id] JOIN [sys].[schemas] [sch] ON [so].[schema_id] = [sch].[schema_id] OUTER APPLY [sys].[dm_db_stats_properties]([so].[object_id], [ss].[stats_id]) sp WHERE [so].[type] = 'U' AND [sp].[modification_counter] > 0 ORDER BY [sp].[last_updated] DESC;
Indse, at forskellige tabeller kan have forskellige tærskler, og du bliver nødt til at justere forespørgslen ovenfor for dine databaser. For nogle borde kan det være ok at vente, indtil 15 % eller 20 % af rækkerne er blevet ændret. Men for andre skal du muligvis opdatere med 10 % eller endda 5 %, afhængigt af de faktiske værdier og deres skævhed. Der er ingen sølvkugle. Så meget som vi elsker absolutter, eksisterer de sjældent i SQL Server, og statistik er ingen undtagelse. Du ønsker stadig at lade Auto Update Statistics være aktiveret - det er en sikkerhed, der vil slå ind, hvis du går glip af noget, ligesom Auto Growth for dine databasefiler. Men dit bedste bud er at kende dine data og implementere en metode, der giver dig mulighed for at opdatere statistik baseret på procentdelen af ændrede rækker.