Gruppering er en vigtig funktion, der hjælper med at organisere og arrangere data. Der er mange måder at gøre det på, og en af de mest effektive metoder er SQL GROUP BY-sætningen.
Du kan bruge SQL GROUP BY til at opdele rækker i resultater i grupper med en aggregerfunktion . Det lyder nemt at summere, gennemsnit eller tælle rekorder med det.
Men gør du det rigtigt?
"Ret" kan være subjektivt. Når det kører uden kritiske fejl med et korrekt output, anses det for at være fint. Det skal dog også være hurtigt.
I denne artikel vil hastighed også blive overvejet. Du vil se meget forespørgselsanalyse ved hjælp af logiske læsninger og udførelsesplaner i alle punkterne.
Lad os begynde.
1. Filtrer tidligt
Hvis du er i tvivl om, hvornår du skal bruge WHERE og HAVING, er denne noget for dig. For afhængigt af den betingelse, du angiver, kan begge give det samme resultat.
Men de er forskellige.
HAVING filtrerer grupperne ved hjælp af kolonnerne i SQL GROUP BY-sætningen. WHERE filtrerer rækkerne, før gruppering og aggregering forekommer. Så hvis du filtrerer ved hjælp af HAVING-sætningen, forekommer gruppering for alle rækker returneret.
Og det er dårligt.
Hvorfor? Det korte svar er:det er langsomt. Lad os bevise dette med 2 forespørgsler. Tjek koden nedenfor. Inden du kører det i SQL Server Management Studio, skal du først trykke på Ctrl-M.
SET STATISTICS IO ON
GO
-- using WHERE
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
ORDER BY Product, OrderYear, OrderMonth;
-- using HAVING
SELECT
MONTH(soh.OrderDate) AS OrderMonth
,YEAR(soh.OrderDate) AS OrderYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
GROUP BY p.Name, YEAR(soh.OrderDate), MONTH(soh.OrderDate)
HAVING YEAR(soh.OrderDate) = 2012
ORDER BY Product, OrderYear, OrderMonth;
SET STATISTICS IO OFF
GO
Analyse
De 2 SELECT-sætninger ovenfor vil returnere de samme rækker. Begge er korrekte med at returnere produktordrer efter måned i år 2012. Men det første SELECT tog 136 ms. at køre på min bærbare computer, mens en anden tog 764ms.!
Hvorfor?
Lad os tjekke de logiske læsninger først i figur 1. STATISTICS IO returnerede disse resultater. Derefter indsatte jeg det i StatisticsParser.com for det formaterede output.
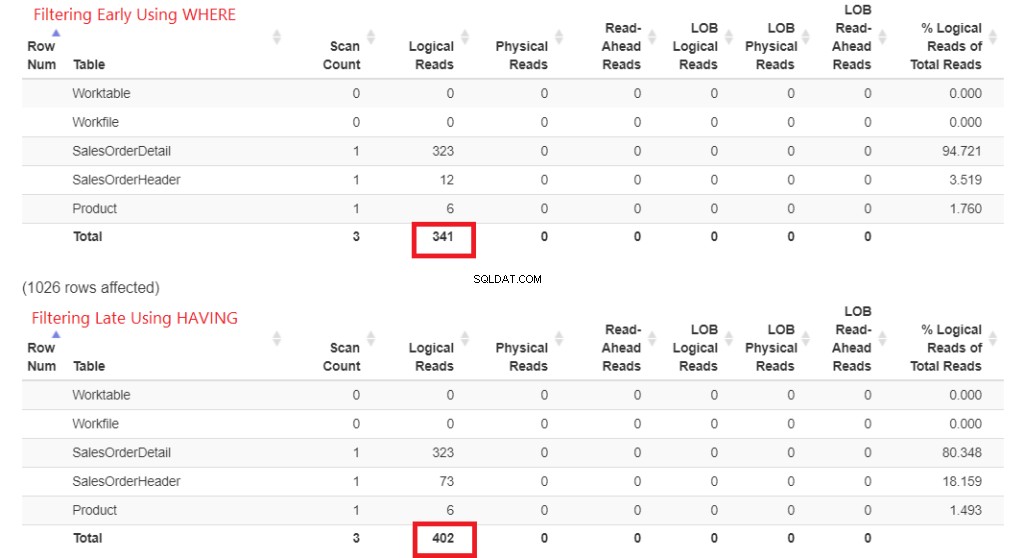
Figur 1 . Logiske læsninger af tidlig filtrering ved hjælp af WHERE vs. filtrering for sent ved hjælp af HAVING.
Se på de samlede logiske læsninger af hver. For at forstå disse tal, jo mere logiske læsninger det tog, jo langsommere vil forespørgslen være. Så det beviser, at det er langsommere at bruge HAVING, og at filtrere tidligt med WHERE er hurtigere.
Det betyder selvfølgelig ikke, at HAVING er nytteløst. En undtagelse er, når du bruger HAVING med et aggregat som HAVING SUM(sod.Linetotal)> 100000 . Du kan kombinere en WHERE-sætning og en HAVING-sætning i én forespørgsel.
Se udførelsesplanen i figur 2.
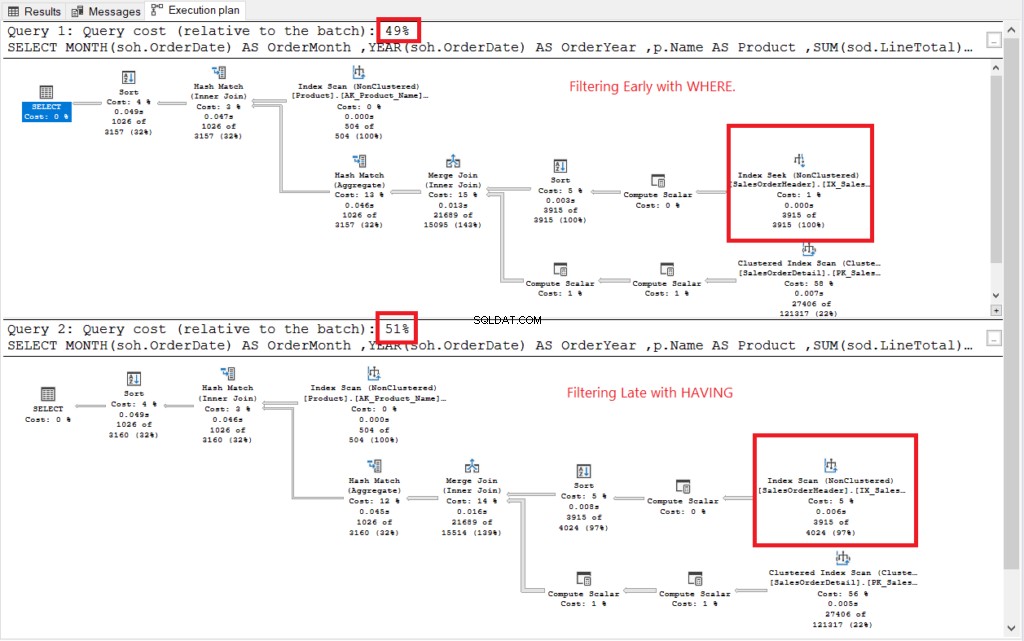
Figur 2 . Udførelsesplaner for tidlig filtrering vs. sent filtrering.
Begge udførelsesplaner lignede ens bortset fra dem, der var indrammet i rødt. Tidlig filtrering brugte Index Seek-operatoren, mens en anden brugte Index Scan. Søgninger er hurtigere end scanninger i store tabeller.
Nej te: At filtrere tidligt koster mindre end at filtrere sent. Så bundlinjen er, at filtrering af rækkerne tidligt kan forbedre ydeevnen.
2. Gruppe først, tilmeld dig senere
At deltage i nogle af de tabeller, du har brug for senere, kan også forbedre ydeevnen.
Lad os sige, at du vil have et månedligt produktsalg. Du skal også få produktnavnet, nummeret og underkategorien i den samme forespørgsel. Disse kolonner er i en anden tabel. Og de skal alle tilføjes i GROUP BY-sætningen for at få en vellykket eksekvering. Her er koden.
SET STATISTICS IO ON
GO
SELECT
p.Name AS Product
,p.ProductNumber
,ps.Name AS ProductSubcategory
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER JOIN Production.Product p ON sod.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.name, p.ProductNumber, ps.Name
ORDER BY Product
SET STATISTICS IO OFF
GO
Dette vil køre fint. Men der er en bedre og hurtigere måde. Dette kræver ikke, at du tilføjer de 3 kolonner for produktnavn, nummer og underkategori i GROUP BY-klausulen. Dette vil dog kræve lidt flere tastetryk. Her er den.
SET STATISTICS IO ON
GO
;WITH Orders2012 AS
(
SELECT
sod.ProductID
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
WHERE soh.OrderDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY sod.ProductID
)
SELECT
P.Name AS Product
,P.ProductNumber
,ps.Name AS ProductSubcategory
,o.ProductSales
FROM Orders2012 o
INNER JOIN Production.Product p ON o.ProductID = p.ProductID
INNER JOIN Production.ProductSubcategory ps ON p.ProductSubcategoryID = ps.ProductSubcategoryID
ORDER BY Product;
SET STATISTICS IO OFF
GO
Analyse
Hvorfor er dette hurtigere? Tilslutningen til Produkt og Produktunderkategori gøres senere. Begge er ikke involveret i GROUP BY-klausulen. Lad os bevise dette med tal i STATISTIK IO. Se figur 4.
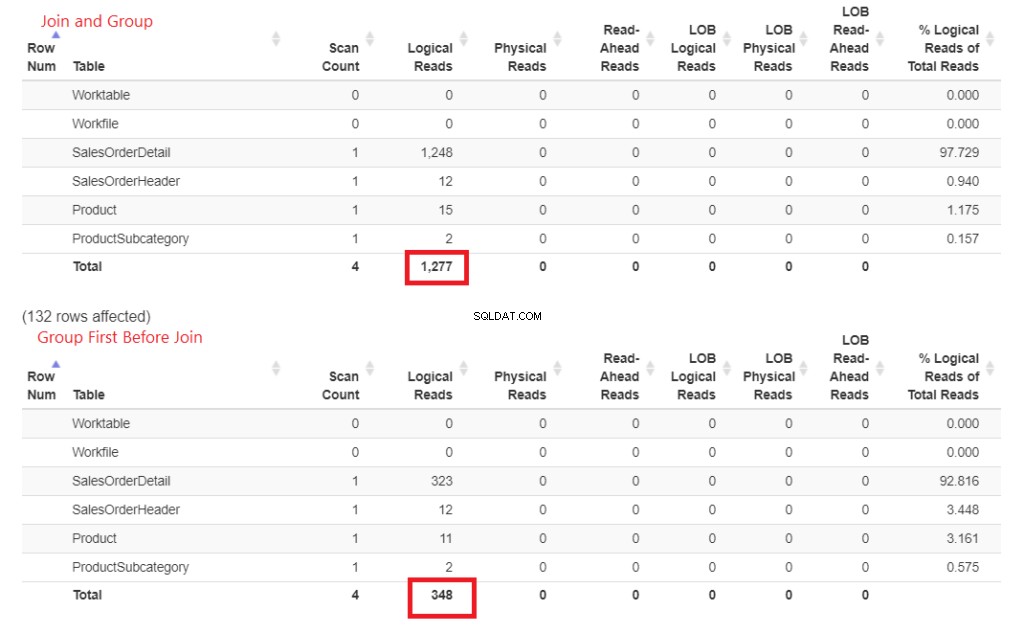
Figur 3 . At slutte sig tidligt og derefter gruppere krævede flere logiske læsninger end at udføre sammenkædningen senere.
Ser du de logiske læsninger? Forskellen er langt, og vinderen er åbenlys.
Lad os sammenligne udførelsesplanen for de 2 forespørgsler for at se årsagen bag tallene ovenfor. Se først figur 4 for udførelsesplanen for forespørgslen med alle tabeller sammenføjet, når de er grupperet.
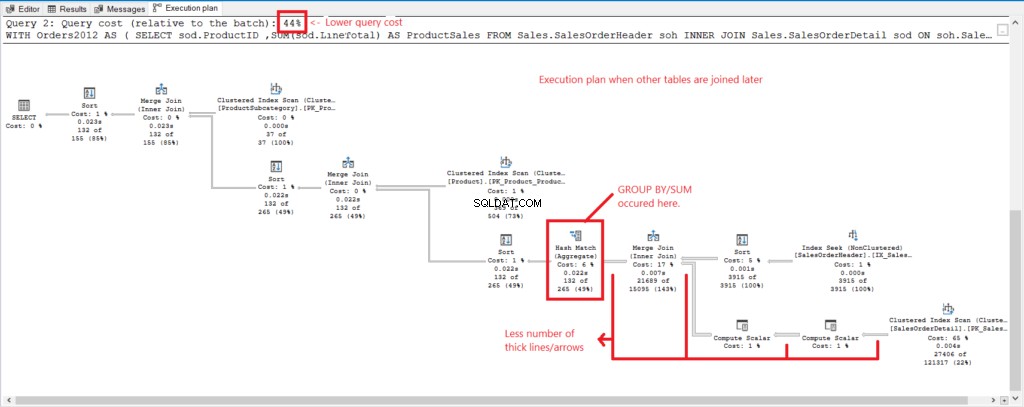
Figur 4 . Udførelsesplan, når alle tabeller er samlet.
Og vi har følgende observationer:
- GROUP BY og SUM blev udført sent i processen efter at have sluttet sig til alle tabeller.
- En masse tykkere linjer og pile – dette forklarer de 1.277 logiske læsninger.
- De 2 forespørgsler tilsammen udgør 100 % af forespørgselsomkostningerne. Men denne forespørgsels plan har en højere forespørgselsomkostning (56%).
Her er en udførelsesplan, da vi først grupperede os og sluttede os til Produktet og Produktunderkategori tabeller senere. Se figur 5.
Figur 5 . Udførelsesplan, når gruppen først, slutter sig til senere, er færdig.
Og vi har følgende observationer i figur 5.
- GROUP BY og SUM sluttede tidligt.
- Mindre antal tykke linjer og pile – dette forklarer kun de 348 logiske læsninger.
- Lavere forespørgselsomkostninger (44%).
3. Grupper en indekseret kolonne
Når SQL GROUP BY udføres på en kolonne, skal den kolonne have et indeks. Du vil øge udførelseshastigheden, når du grupperer kolonnen med et indeks. Lad os ændre den tidligere forespørgsel og bruge afsendelsesdatoen i stedet for ordredatoen. Forsendelsesdatokolonnen har intet indeks i SalesOrderHeader .
SET STATISTICS IO ON
GO
SELECT
MONTH(soh.ShipDate) AS ShipMonth
,YEAR(soh.ShipDate) AS ShipYear
,p.Name AS Product
,SUM(sod.LineTotal) AS ProductSales
FROM Sales.SalesOrderHeader soh
INNER JOIN Sales.SalesOrderDetail sod ON soh.SalesOrderID = sod.SalesOrderID
INNER join Production.Product p ON sod.ProductID = p.ProductID
WHERE soh.ShipDate BETWEEN '01/01/2012' AND '12/31/2012'
GROUP BY p.Name, YEAR(soh.ShipDate), MONTH(soh.ShipDate)
ORDER BY Product, ShipYear, ShipMonth;
SET STATISTICS IO OFF
GO
Tryk på Ctrl-M, og kør derefter forespørgslen ovenfor i SSMS. Opret derefter et ikke-klynget indeks på ShipDate kolonne. Bemærk de logiske læsninger og udførelsesplanen. Kør endelig forespørgslen ovenfor i en anden forespørgselsfane igen. Bemærk forskellene i logiske læsninger og udførelsesplaner.
Her er sammenligningen af de logiske læsninger i figur 6.
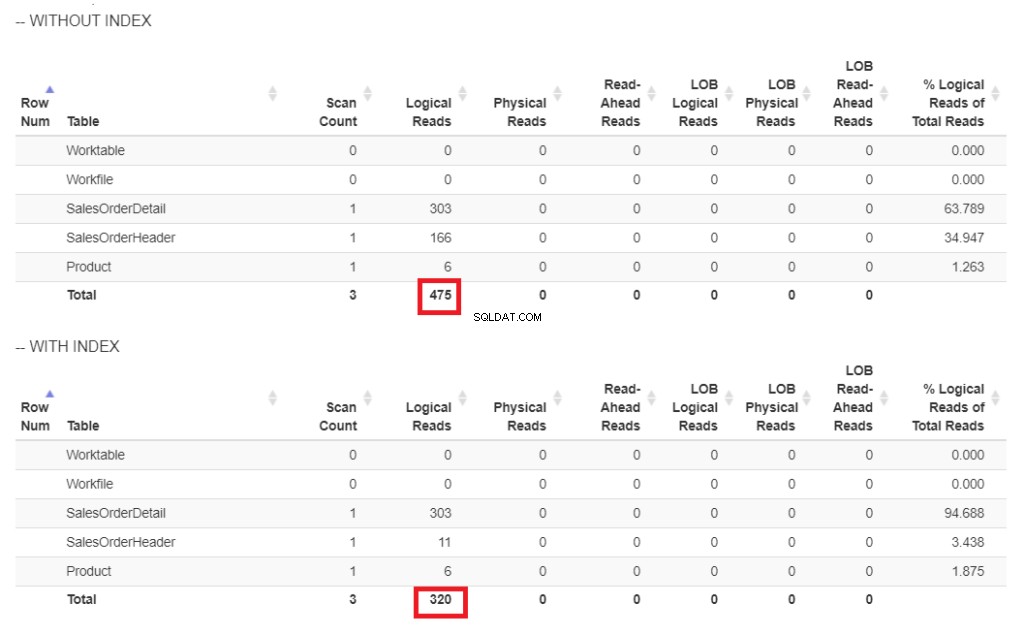
Figur 6 . Logiske læsninger af vores forespørgselseksempel med og uden et indeks på ShipDate.
I figur 6 er der højere logiske læsninger af forespørgslen uden et indeks på ShipDate .
Lad os nu have udførelsesplanen, når der ikke er noget indeks på ShipDate findes i figur 7.
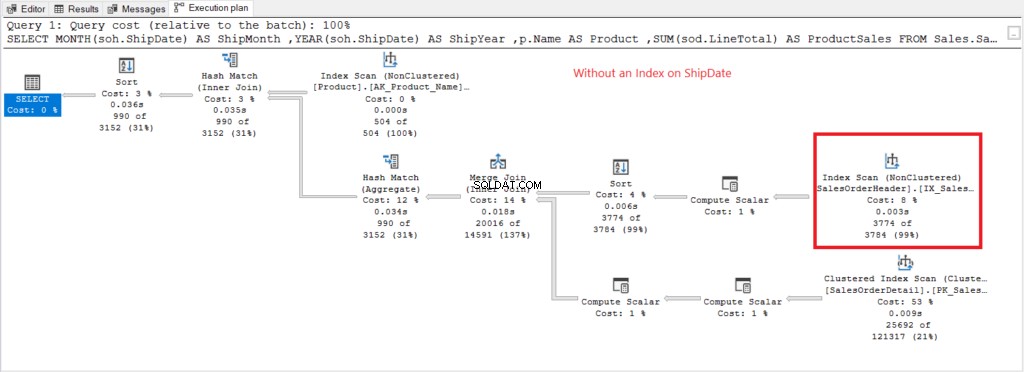
Figur 7 . Eksekveringsplan ved brug af GROUP BY på forsendelsesdato uindekseret.
Indeksscanning operatoren brugt i planen i figur 7 forklarer de højere logiske læsninger (475). Her er en eksekveringsplan efter indeksering af ShipDate kolonne.
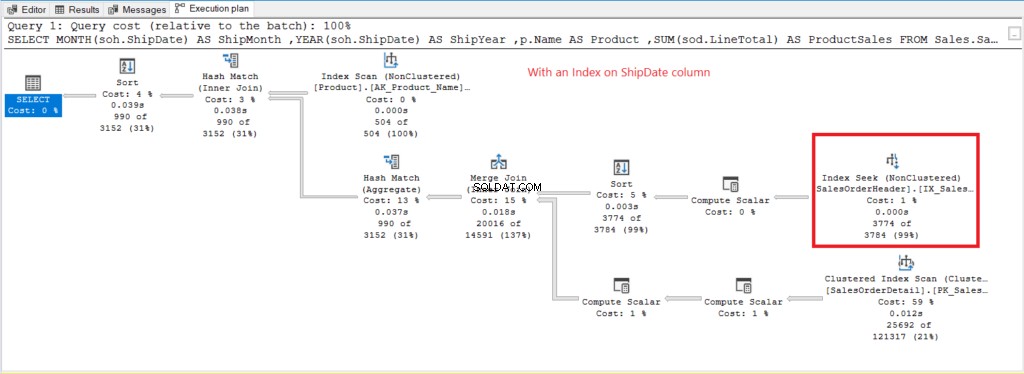
Figur 8 . Udførelsesplan ved brug af GROUP BY på indekseret forsendelsesdato.
I stedet for indeksscanning bruges en indekssøgning efter indeksering af ShipDate kolonne. Dette forklarer de nederste logiske læsninger i figur 6.
Så for at forbedre ydeevnen, når du bruger GROUP BY, bør du overveje at indeksere de kolonner, du brugte til gruppering.
Takeaways ved brug af SQL GROUP BY
SQL GROUP BY er nem at bruge. Men du skal tage det næste skridt for at gå ud over at opsummere dataene til rapporter. Her er pointerne igen:
- Filtrer tidligt . Fjern de rækker, du ikke behøver at opsummere ved hjælp af WHERE-sætningen i stedet for HAVING-sætningen.
- Grupper først, tilmeld dig senere . Nogle gange vil der være kolonner, du skal tilføje bortset fra de kolonner, du grupperer. I stedet for at inkludere dem i GROUP BY-sætningen, skal du dele forespørgslen med en CTE og slutte sig til andre tabeller senere.
- Brug GROUP BY med indekserede kolonner . Denne grundlæggende ting kan være nyttig, når databasen er hurtig som en snegl.
Håber dette hjælper dig med at forbedre dit spil i gruppering af resultater.
Hvis du kan lide dette opslag, så del det på dine foretrukne sociale medieplatforme.