Moodle, et open source Learning Management System, blev mere og mere populært sidste år, da pandemien tvang hårde nedlukninger, og størstedelen af uddannelsesaktiviteterne er flyttet fra skoler, gymnasier og universiteter til onlineplatforme. Med den blev der lagt et pres på it-teamene for at sikre, at de online platforme vil kunne rumme meget højere belastning, end de plejede at opleve. Der er blevet rejst spørgsmål - hvordan kan en Moodle-platform skaleres til at håndtere den øgede belastning? På den ene side er det ikke en svær bedrift at skalere selve applikationen, men databasen er på den anden side et andet dyr. Databaser, som alle statslige tjenester, er notorisk svære at skalere ud. I dette blogindlæg vil vi gerne diskutere nogle udfordringer, du vil stå over for, når du skalerer en Moodle-database.
Skalering af Moodle-database - Udfordringen
Hovedkilden til problemer er arven - Moodle kommer, ligesom mange databaser, fra en enkelt databasebaggrund, og som sådan kommer den med nogle forventninger, der er relateret til et sådant miljø. Den typiske er, at du kan udføre den ene transaktion efter den anden, og den anden transaktion vil altid se resultatet af den første. Dette er ikke nødvendigvis tilfældet i de fleste af de distribuerede databasemiljøer. Asynkron replikering giver ingen løfter. Enhver transaktion kan gå tabt i processen. Det er nok, at masteren går ned, før transaktionsdataene bliver overført til slaver. Semisynkron replikering bringer løftet om datasikkerhed, men det lover ikke andet. Slaver kan stadig være bagud, og selvom dataene er gemt på vedvarende lagring som en relælog, og til sidst vil de blive anvendt på datasættet, betyder det stadig ikke, at de allerede er blevet anvendt. Du kan forespørge på dine slaver og kan ikke se de data, du lige har skrevet til masteren.
Selv klynger som Galera kommer som standard ikke med den virkelig synkrone replikering - hullet er væsentligt reduceret sammenlignet med replikeringssystemerne, men det er der stadig, og øjeblikkelig SELECT udført efter en tidligere skrivning kan muligvis ikke se data, du lige har gemt i databasen, fordi din SELECT blev dirigeret til en anden Galera-node end din tidligere skrivning.
Der er flere løsninger, du kan bruge til at skalere Moodle MySQL-database. For det første, hvis du bruger replikeringsopsætning, kan du bruge funktionen "sikre læsninger" fra Moodle. Det dækkede vi i en af vores tidligere blogs. Dette vil føre til den situation, hvor Moodle vil bestemme, hvilke skrifter der vil blive fordelt på tværs af slaverne, og hvilke der vil ramme mesteren.
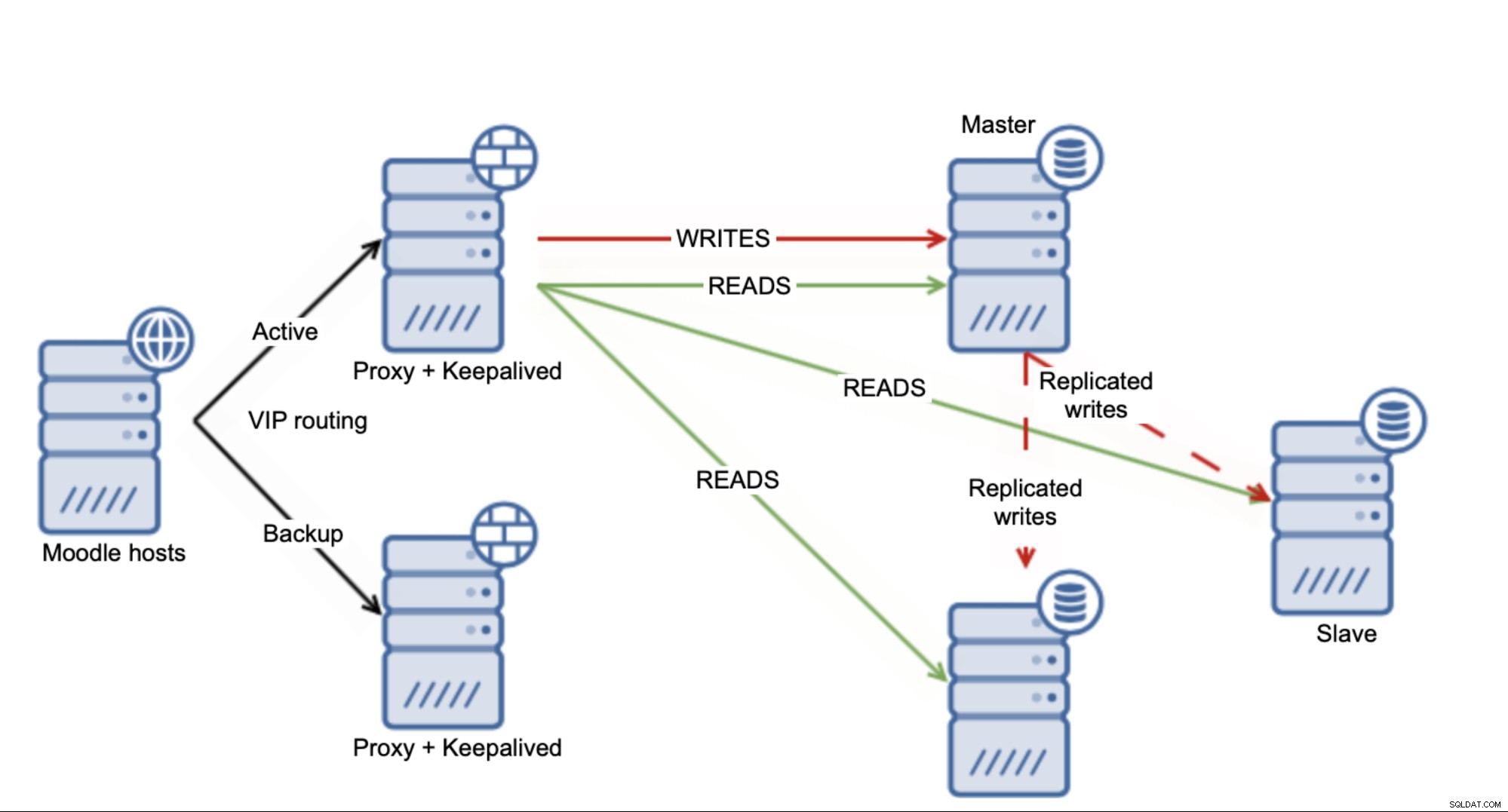
På den ene side er det godt - du er sikker på at bruge flere vedhæftede slaver til masteren, så du i det mindste i et vist omfang kan aflaste masteren. På den anden side er det langt fra ideelt, for det er blot en delmængde af SELECT'er, som du vil kunne sende til slaverne. Selvfølgelig afhænger det hele af den nøjagtige sag, men du kan forvente, at masteren fortsat vil være en flaskehals med hensyn til belastningen.
Alternativ tilgang kunne være at bruge Galera Cluster og fordele belastningen jævnt på tværs af alle noderne.
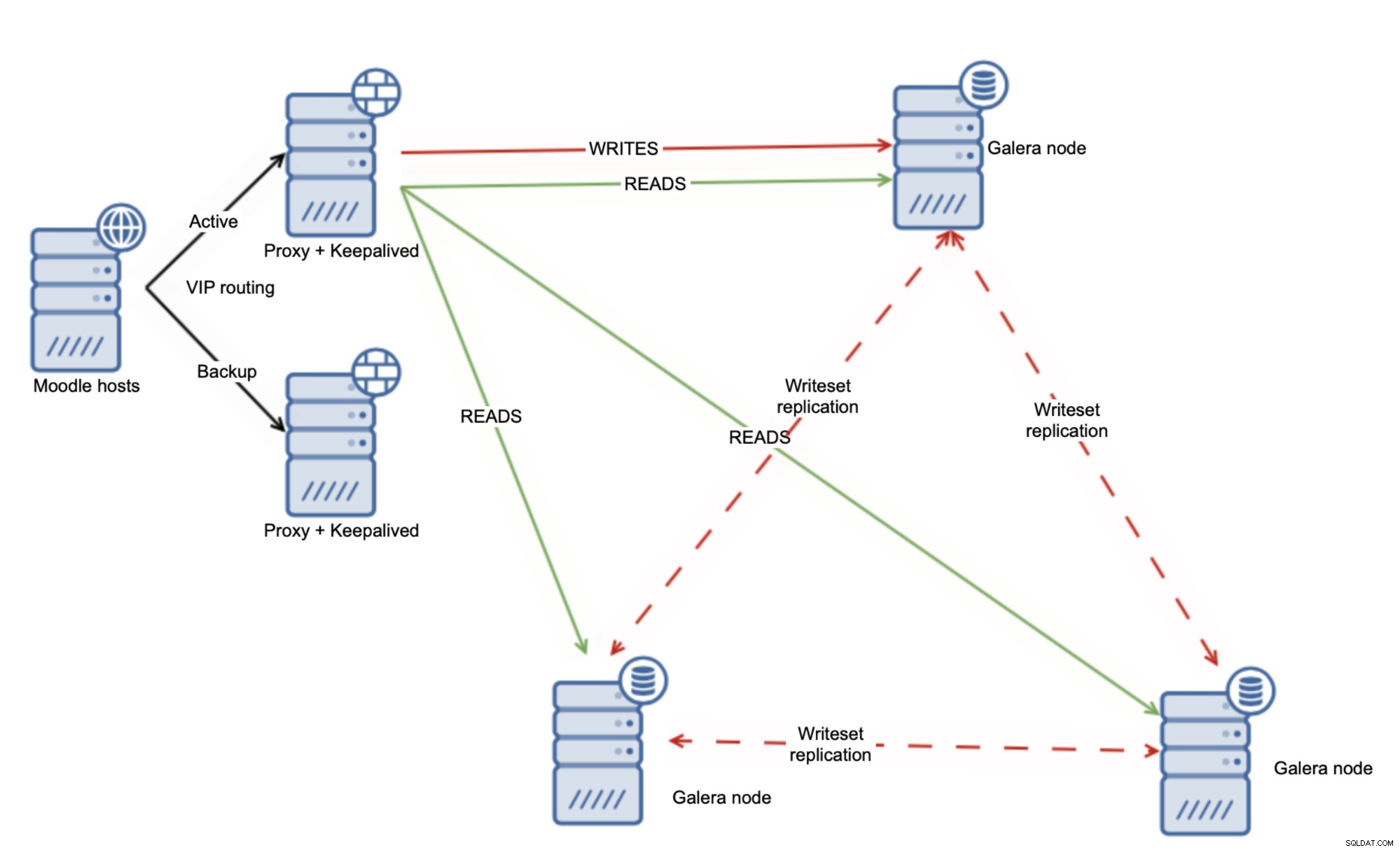
I sig selv er dette ikke nok til at håndtere hele læse-efter -skriveproblemer, men heldigvis kan du bruge variablen wsrep-sync-wait, som kan bruges til at sikre, at kausalitetskontrollen er på plads, og at klyngen opfører sig som en rigtig synkron klynge. Ved at bruge denne indstilling kan du læse sikkert fra alle dine Galera-knuder.
Selvfølgelig vil håndhævelse af kausalitetstjek påvirke Galera-ydelsen, men det giver stadig mening, da du kan drage fordel af at læse fra flere Galera-noder på samme tid. Fra det tidspunkt er det ret nemt at skalere læsninger med Galera-klyngen - du tilføjer bare flere Galera-noder til klyngen. Load Balancer bør omkonfigureres til at samle dem op og bruge som et ekstra mål for læsningerne, så du kan skalere ud til selv 10+ læserknudepunkter.
Du skal huske på, at tilføjelse af yderligere noder, replikering eller Galera, det er lige meget, tilføjer en vis kompleksitet til operationerne på klyngen. Du skal sikre dig, at dine noder overvåges korrekt, at du har sikkerhedskopier, der fungerer, at replikeringen fungerer korrekt, og at selve klyngen er i en korrekt tilstand. For replikeringsmiljøer skal failover håndteres på den ene eller den anden måde, og for både Galera og replikering vil du måske være i stand til at genopbygge noderne i klyngen, hvis du opdager nogen form for datainkonsistens på tværs af klyngen. Heldigvis kan ClusterControl hjælpe dig væsentligt med at håndtere disse udfordringer.
Hvordan ClusterControl hjælper med at administrere Moodle MySQL-databaseklyngen
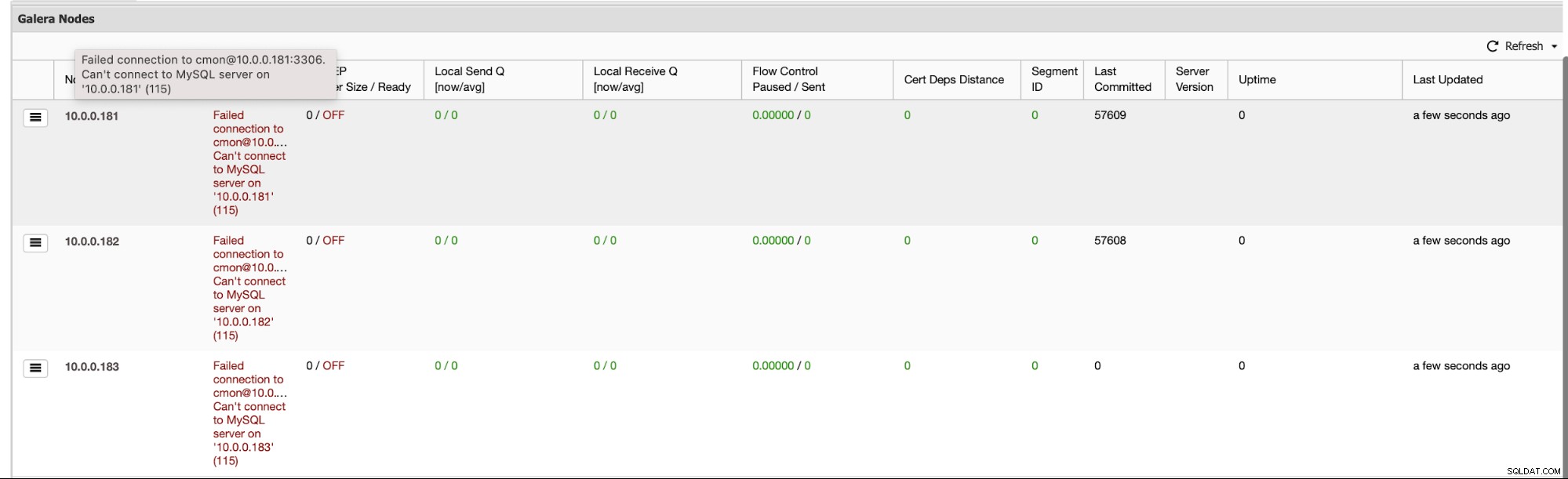
For det første, hvis hele klyngen kollapser, vil ClusterControl udføre en automatiseret klyngendannelse - så længe alle noderne vil være tilgængelige, starter ClusterControl klyngendannelsesprocessen:

Efter lidt tid burde hele klyngen være online igen.
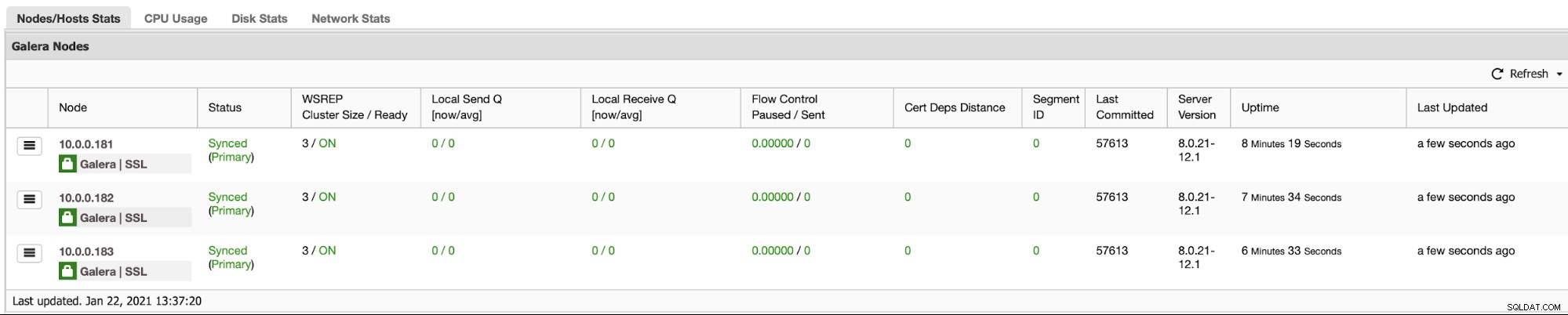
ClusterControl leveres med et sæt administrationsmuligheder:
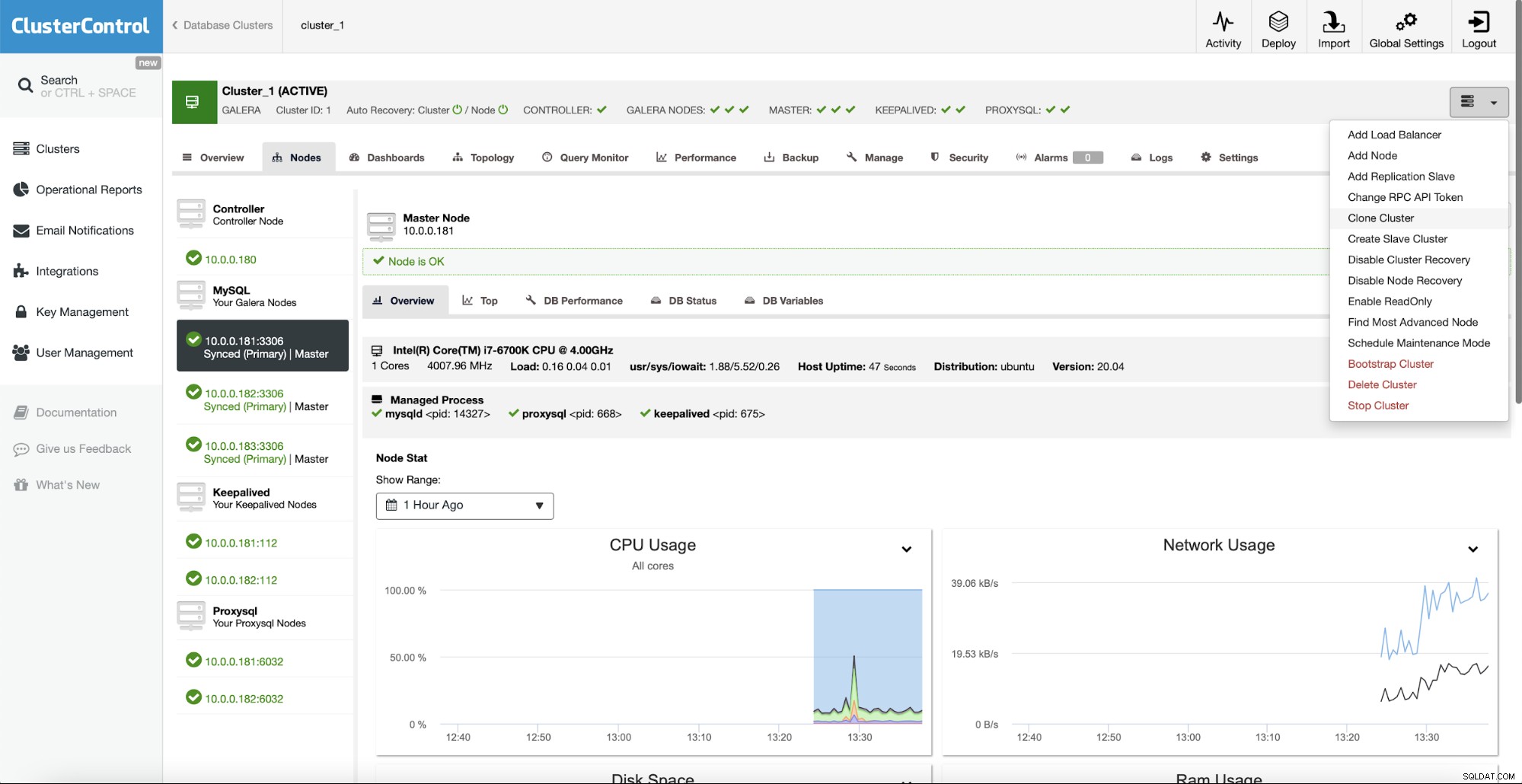
Du kan skalere klyngen ud ved at tilføje noder eller replikeringsslaver. Du kan endda oprette en hel slaveklynge, der vil replikere fra hovedklyngen.
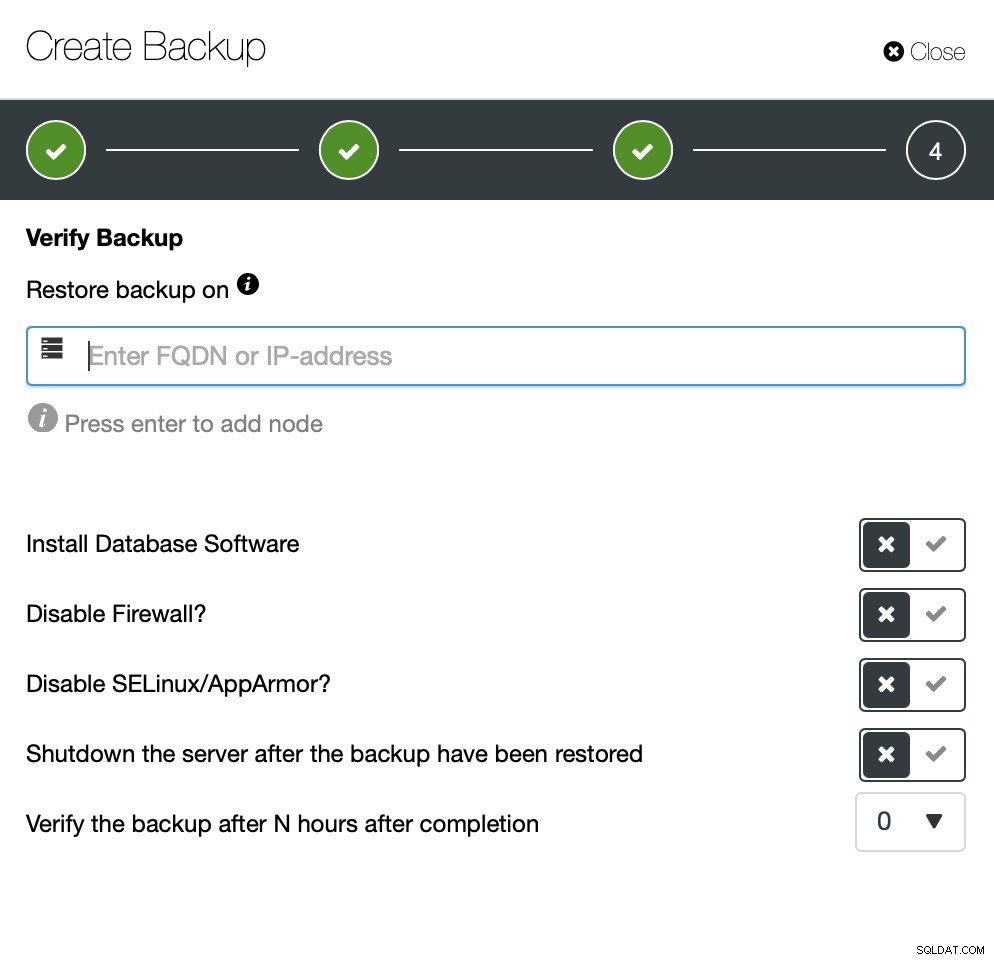
Det er muligt nemt at opsætte en sikkerhedskopieringsplan, som udføres af ClusterControl. Du kan endda konfigurere automatisk sikkerhedskopiering.
Du vil sikkert gerne kunne overvåge din databaseklynge. ClusterControl giver dig mulighed for at gøre netop det:
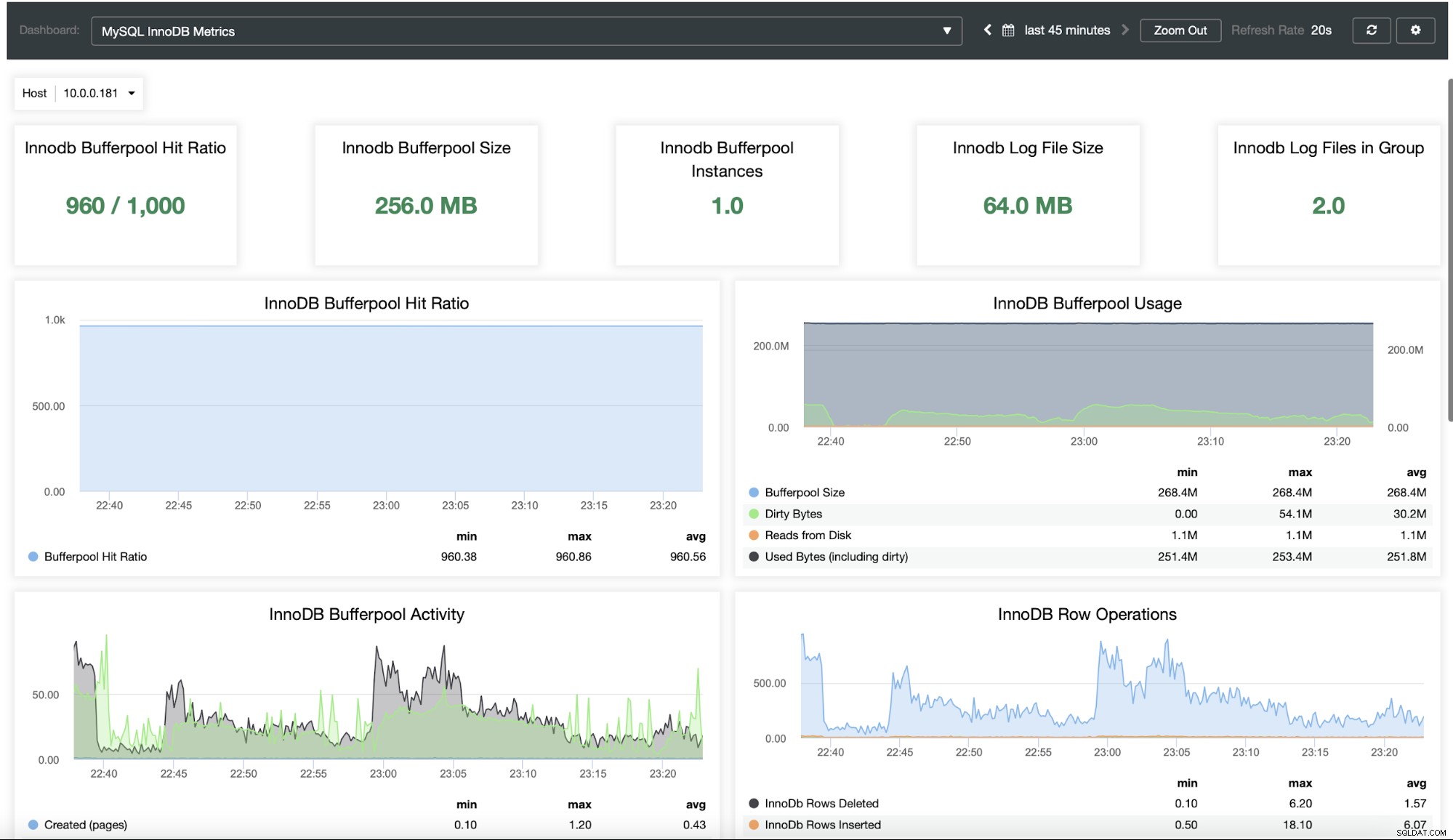
Som du kan se, er ClusterControl en fantastisk platform, der kan bruges til at reducere kompleksiteten af skalering og styring af Moodle MySQL-databasen. Vi vil meget gerne høre om din erfaring med at skalere ud af Moodle og dens database i særdeleshed.