Ændringerne i den interne repræsentation af partitionerede tabeller mellem SQL Server 2005 og SQL Server 2008 resulterede i forbedrede forespørgselsplaner og ydeevne i de fleste tilfælde (især når parallel eksekvering er involveret). Desværre gjorde de samme ændringer, at nogle ting, der fungerede godt i SQL Server 2005, pludselig ikke fungerede så godt i SQL Server 2008 og senere. Dette indlæg ser på et eksempel, hvor SQL Server 2005-forespørgselsoptimeringsværktøjet producerede en overlegen eksekveringsplan sammenlignet med senere versioner.
Eksempeltabel og data
Eksemplerne i dette indlæg bruger følgende opdelte tabel og data:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T4
(
RowID integer IDENTITY NOT NULL,
SomeData integer NOT NULL,
CONSTRAINT PK_T4
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T4 WITH (TABLOCKX)
(SomeData)
SELECT
ABS(CHECKSUM(NEWID()))
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
CREATE NONCLUSTERED INDEX nc1
ON dbo.T4 (SomeData)
ON PS (RowID); Partitioneret datalayout
Vores tabel har et opdelt klyngeindeks. I dette tilfælde fungerer clustering-nøglen også som partitioneringsnøglen (selvom dette generelt ikke er et krav). Partitionering resulterer i separate fysiske lagerenheder (rækkesæt), som forespørgselsprocessoren præsenterer for brugerne som en enkelt enhed.
Diagrammet nedenfor viser de første tre partitioner i vores tabel (klik for at forstørre):
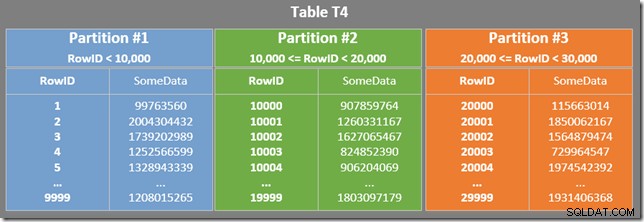
Det ikke-klyngede indeks er opdelt på samme måde (det er "justeret"):

Hver partition i det ikke-klyngede indeks dækker en række RowID-værdier. Inden for hver partition er dataene ordnet af SomeData (men RowID-værdierne vil ikke blive ordnet generelt).
MIN/MAX-problemet
Det er rimeligt velkendt, at MIN og MAX aggregater optimerer ikke godt på partitionerede tabeller (medmindre den kolonne, der aggregeres, også tilfældigvis er partitioneringskolonnen). Denne begrænsning (som stadig eksisterer i SQL Server 2014 CTP 1) er blevet skrevet om mange gange gennem årene; min yndlingsdækning er i denne artikel af Itzik Ben-Gan. For kort at illustrere problemet kan du overveje følgende forespørgsel:
SELECT MIN(SomeData) FROM dbo.T4;
Udførelsesplanen på SQL Server 2008 eller nyere er som følger:

Denne plan læser alle 150.000 rækker fra indekset, og et Stream Aggregate beregner minimumsværdien (udførelsesplanen er i det væsentlige den samme, hvis vi anmoder om den maksimale værdi i stedet). SQL Server 2005-udførelsesplanen er lidt anderledes (dog ikke bedre):
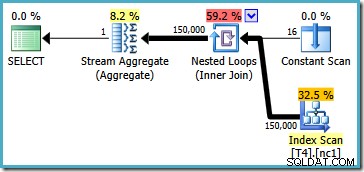
Denne plan gentager partitionsnumre (angivet i Constant Scan) og scanner en partition fuldstændigt ad gangen. Alle 150.000 rækker bliver stadig til sidst læst og behandlet af Stream Aggregate.
Se tilbage på de opdelte tabel og indeksdiagrammer og tænk på, hvordan forespørgslen kunne behandles mere effektivt på vores datasæt. Det ikke-klyngede indeks ser ud til at være et godt valg til at løse forespørgslen, fordi det indeholder SomeData-værdier i en rækkefølge, der kunne udnyttes ved beregning af aggregatet.
Det faktum, at indekset er partitioneret, komplicerer sagen en smule:hver partition af indekset er sorteret efter SomeData-kolonnen, men vi kan ikke bare læse den laveste værdi fra nogen bestemt partition for at få det rigtige svar på hele forespørgslen.
Når først den væsentlige karakter af problemet er forstået, kan et menneske se, at en effektiv strategi ville være at finde den enkelte laveste værdi af SomeData i hver partition af indekset, og tag derefter den laveste værdi fra resultaterne pr. partition.
Dette er i bund og grund den løsning, som Itzik præsenterer i sin artikel; omskriv forespørgslen for at beregne en samlet per-partition (ved hjælp af APPLY syntaks) og aggregér derefter igen over disse resultater pr. partition. Ved at bruge den tilgang, den omskrevne MIN query producerer denne eksekveringsplan (se Itziks artikel for den nøjagtige syntaks):
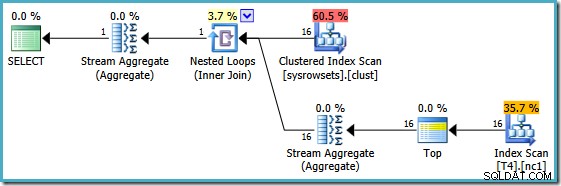
Denne plan læser partitionsnumre fra en systemtabel og henter den laveste værdi af SomeData i hver partition. Det endelige Stream Aggregate beregner blot minimumet over resultaterne pr. partition.
Den vigtige funktion i denne plan er, at den læser en enkelt række fra hver partition (udnytter sorteringsrækkefølgen af indekset inden for hver partition). Det er meget mere effektivt end optimeringsprogrammets plan, der behandlede alle 150.000 rækker i tabellen.
MIN og MAX inden for en enkelt partition
Overvej nu følgende forespørgsel for at finde minimumsværdien i SomeData-kolonnen for en række RowID-værdier, der er indeholdt inden for en enkelt partition :
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 18000;
Vi har set, at optimeringsværktøjet har problemer med MIN og MAX over flere partitioner, men vi forventer, at disse begrænsninger ikke gælder for en enkelt partitionsforespørgsel.
Den enkelte partition er den, der er afgrænset af RowID-værdierne 10.000 og 20.000 (se tilbage til definitionen af partitioneringsfunktionen). Partitioneringsfunktionen blev defineret som RANGE RIGHT , så grænseværdien på 10.000 hører til partition #2 og grænsen på 20.000 tilhører partition #3. Udvalget af RowID-værdier specificeret af vores nye forespørgsel er derfor indeholdt i partition 2 alene.
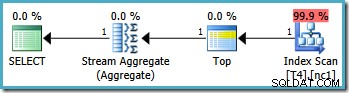
De grafiske udførelsesplaner for denne forespørgsel ser ens ud på alle SQL Server-versioner fra 2005 og frem:
Plananalyse
Optimizeren tog RowID-området angivet i WHERE klausul og sammenlignede den med partitionsfunktionsdefinitionen for at bestemme, at kun partition 2 i det ikke-klyngede indeks skulle tilgås. SQL Server 2005-planegenskaberne for Index Scan viser enkeltpartitionsadgangen tydeligt:
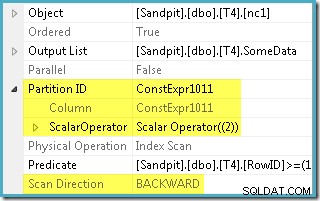
Den anden fremhævede egenskab er scanningsretningen. Rækkefølgen af scanningen varierer afhængigt af, om forespørgslen leder efter den minimale eller maksimale SomeData-værdi. Det ikke-klyngede indeks er ordnet (pr. partition, husk) på stigende SomeData-værdier, så indeksscanningsretningen er FORWARD hvis forespørgslen beder om minimumsværdien og BACKWARD hvis den maksimale værdi er nødvendig (skærmbilledet ovenfor er taget fra MAX). forespørgselsplan).
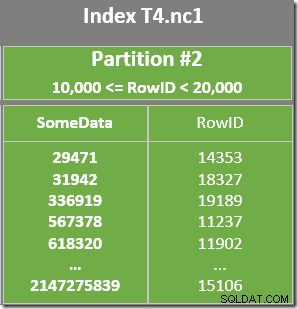
Der er også et resterende prædikat på indeksscanningen for at kontrollere, at RowID-værdierne scannet fra partition 2 matcher WHERE klausul prædikat. Optimizeren antager, at RowID-værdier fordeles ret tilfældigt gennem det ikke-klyngede indeks, så det forventer at finde den første række, der matcher WHERE klausul prædikat ret hurtigt. Det partitionerede datalayoutdiagram viser, at RowID-værdierne faktisk er ret tilfældigt fordelt i indekset (som er sorteret efter SomeData-kolonnen husk):
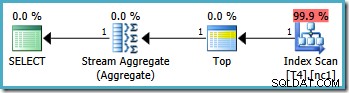
Topoperatoren i forespørgselsplanen begrænser indeksscanningen til en enkelt række (fra enten den lave eller høje ende af indekset afhængigt af scanningsretningen). Indeksscanninger kan være problematiske i forespørgselsplaner, men Top-operatøren gør det til en effektiv mulighed her:scanningen kan kun producere én række, så stopper den. Kombinationen af top- og bestilt indeksscanning udfører effektivt en søgning til den højeste eller laveste værdi i indekset, der også matcher WHERE klausul prædikater. Et Stream Aggregate vises også i planen for at sikre, at en NULL genereres i tilfælde af, at ingen rækker returneres af indeksscanningen. Skalær MIN og MAX aggregater er defineret til at returnere en NULL når input er et tomt sæt.
Samlet set er dette en meget effektiv strategi, og planerne har en estimeret pris på kun 0,0032921 enheder som følge heraf. Så langt så godt.
Grænseværdiproblemet
Dette næste eksempel ændrer den øverste ende af RowID-området:
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000;
Bemærk, at forespørgslen ekskluderer værdien på 20.000 ved at bruge en "mindre end"-operator. Husk, at 20.000-værdien tilhører partition 3 (ikke partition 2), fordi partitionsfunktionen er defineret som RANGE RIGHT . SQL Server2005 optimizer håndterer denne situation korrekt og producerer den optimale enkeltpartitionsforespørgselsplan med en estimeret pris på 0,0032878 :
Den samme forespørgsel producerer dog en anden plan på SQL Server2008 og senere (inklusive SQL Server 2014 CTP 1):
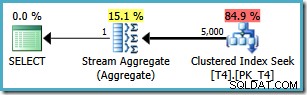
Nu har vi en Clustered Index Seek (i stedet for den ønskede Index Scan og Top operator kombination). Alle 5.000 rækker, der matcher WHERE klausulen behandles gennem Stream Aggregate i denne nye eksekveringsplan. De anslåede omkostninger ved denne plan er 0,0199319 enheder – mere end seks gange omkostningerne ved SQL Server 2005-planen.
Årsag
SQL Server 2008 (og senere) optimizere får ikke helt den interne logik rigtigt, når et interval refererer, men udelukker , en grænseværdi, der tilhører en anden partition. Optimizeren tror fejlagtigt, at flere partitioner vil blive tilgået, og konkluderer, at den ikke kan bruge enkeltpartitionsoptimering til MIN og MAX aggregater.
Løsninger
En mulighed er at omskrive forespørgslen ved at bruge>=og <=operatorer, så vi ikke refererer til en grænseværdi fra en anden partition (selv for at udelukke den!):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID <= 19999;
Dette resulterer i den optimale plan, ved at berøre en enkelt partition:
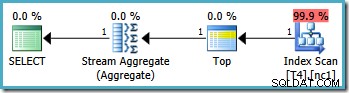
Desværre er det ikke altid muligt at angive korrekte grænseværdier på denne måde (afhængigt af typen af partitioneringskolonnen). Et eksempel på det er med dato- og tidstyper, hvor det er bedst at bruge halvåbne intervaller. En anden indvending mod denne løsning er mere subjektiv:partitioneringsfunktionen udelukker én grænse fra området, så det virker mest naturligt at skrive forespørgslen også ved hjælp af halvåben intervalsyntaks.
En anden løsning er at specificere partitionsnummeret eksplicit (og bibeholde det halvåbne interval):
SELECT MIN(SomeData) FROM dbo.T4 WHERE RowID >= 15000 AND RowID < 20000 AND $PARTITION.PF(RowID) = 2;
Dette producerer den optimale plan, til den dyre pris at kræve et ekstra prædikat og stole på, at brugeren finder ud af, hvad partitionsnummeret skal være.
Det ville selvfølgelig være bedre, hvis optimeringsprogrammerne fra 2008 og senere producerede den samme optimale plan, som SQL Server 2005 gjorde. I en perfekt verden ville en mere omfattende løsning også adressere sagen med flere partier, hvilket også gør den løsning, Itzik beskriver, unødvendig.