Mange mennesker bruger ventestatistikker som en del af deres overordnede præstationsfejlfindingsmetode, og det samme gør jeg, så spørgsmålet, jeg ønskede at udforske i dette indlæg, er omkring ventetyper forbundet med observatør-overhead. Med observatør-overhead mener jeg indvirkningen på SQL Server-arbejdsbelastningsgennemstrømning forårsaget af SQL Profiler, sporing på serversiden eller udvidede hændelsessessioner. For mere om emnet observatør overhead, se følgende to indlæg fra min kollega Jonathan Kehayias :
- Måling af "Observer Overhead" af SQL Trace vs. udvidede hændelser
- Konsekvensen af query_post_execution_showplan Extended Event i SQL Server 2012
Så i dette indlæg vil jeg gerne gå gennem et par variationer af observatør overhead og se, om vi kan finde konsistente ventetyper forbundet med den målte nedbrydning. Der er en række måder, hvorpå SQL Server-brugere implementerer sporing i deres produktionsmiljøer, så dine resultater kan variere, men jeg ville gerne dække et par brede kategorier og rapportere tilbage om, hvad jeg fandt:
- SQL Profiler session brug
- Spor brug på serversiden
- Spor brug på serversiden, skrivning til en langsom I/O-sti
- Udvidet hændelsesbrug med et ringbuffermål
- Udvidet hændelsesbrug med et filmål
- Udvidet hændelsesbrug med et filmål på en langsom I/O-sti
- Udvidet hændelsesbrug med et filmål på en langsom I/O-sti uden tab af hændelser
Du kan sandsynligvis finde på andre varianter af temaet, og jeg inviterer dig til at dele eventuelle interessante resultater vedrørende observatør-overhead og ventestatistikker som en kommentar i dette indlæg.
Basislinje
Til testen brugte jeg en virtuel VMware-maskine med fire vCPU'er og 4 GB RAM. Min virtuelle maskine-gæst var på OCZ Vertex SSD'er. Operativsystemet var Windows Server 2008 R2 Enterprise, og versionen af SQL Server er 2012, SP1 CU4.
Med hensyn til "arbejdsbyrden" bruger jeg en skrivebeskyttet forespørgsel i en løkke mod 2008-kreditprøvedatabasen, indstillet til GO 10.000.000 gange.
USE [Credit];
GO
SELECT TOP 1
[member].[member_no],
[member].[lastname],
[payment].[payment_no],
[payment].[payment_dt],
[payment].[payment_amt]
FROM [dbo].[payment]
INNER JOIN [dbo].[member]
ON [member].[member_no] = [payment].[member_no];
GO 10000000 Jeg udfører også denne forespørgsel via 16 samtidige sessioner. Slutresultatet på mit testsystem er 100 % CPU-udnyttelse på tværs af alle vCPU'er på den virtuelle gæst og et gennemsnit på 14.492 batch-anmodninger pr. sekund over en periode på 2 minutter.
Med hensyn til hændelsessporingen brugte jeg i hver test Showplan XML Statistics Profile til SQL Profiler og Server-side sporingstests – og query_post_execution_showplan til udvidede begivenhedssessioner. Udførelsesplanhændelser er meget dyre, og det er netop derfor, jeg valgte dem, så jeg kunne se, om jeg under ekstreme omstændigheder kunne udlede ventetype-temaer eller ej.
Til at teste ventetypeakkumulering over en testperiode brugte jeg følgende forespørgsel. Ikke noget fancy – bare at rydde statistikken, vente 2 minutter og derefter indsamle de 10 bedste venteakkumuleringer for SQL Server-forekomsten i løbet af nedbrydningstestperioden:
-- Clearing the wait stats
DBCC SQLPERF('waitstats', clear);
WAITFOR DELAY '00:02:00';
GO
SELECT TOP 10
[wait_type],
[waiting_tasks_count],
[wait_time_ms]
FROM sys.[dm_os_wait_stats] AS [ws]
ORDER BY [wait_time_ms] DESC; Bemærk, at jeg er ikke frafiltrering af baggrundsventetyper, der typisk er filtreret fra, og det skyldes, at jeg ikke ønskede at fjerne noget, der normalt er godartet – men i denne omstændighed faktisk peger på et reelt område at undersøge nærmere.
SQL Profiler Session
Følgende tabel viser før-og-efter batch-anmodninger pr. sekund, når du aktiverer en lokal SQL Profiler-sporingssporing Showplan XML Statistics Profile (kører på samme VM som SQL Server-instansen):
| Baseline Batch-anmodninger pr. sekund (2 minutters gennemsnit) | SQL Profiler Session Batch-anmodninger pr. sekund (2 minutters gennemsnit) |
|---|---|
| 14.492 | 1.416 |
Du kan se, at SQL Profiler-sporingen forårsager et betydeligt fald i gennemløbet.
Hvad angår akkumuleret ventetid i samme periode, var de øverste ventetyper som følger (som med resten af testene i denne artikel, lavede jeg et par testkørsler, og outputtet var generelt konsistent):
| wait_type | waiting_tasks_count | ventetid_ms |
|---|---|---|
| TRACEWRITE | 67.142 | 1.149.824 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 313 | 180.449 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.111 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.086 |
| LAZYWRITER_SLEEP | 120 | 120.059 |
| DIRTY_PAGE_POLL | 1.198 | 120.038 |
| HADR_WORK_QUEUE | 12 | 120.015 |
| LOGMGR_QUEUE | 937 | 120.011 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
Ventetypen, der springer ud for mig, er TRACEWRITE – som er defineret af Books Online som en ventetype, der "opstår, når SQL Trace-rækkesæt-sporingsudbyderen venter på enten en ledig buffer eller en buffer med hændelser, der skal behandles". Resten af ventetyperne ligner standardbaggrundsventetyper, som man typisk ville filtrere fra dit resultatsæt. Desuden talte jeg om et lignende problem med oversporing i en artikel tilbage i 2011 kaldet Observer overhead - farerne ved for meget sporing - så jeg var bekendt med denne ventetype nogle gange korrekt peger på observatør overhead problemer. Nu i det særlige tilfælde, jeg bloggede om, var det ikke SQL Profiler, men et andet program, der bruger rækkesættets sporingsudbyder (ineffektivt).
Sporing på serversiden
Det var til SQL Profiler, men hvad med sporingsoverhead på serversiden? Følgende tabel viser før-og-efter batch-anmodninger pr. sekund, når du aktiverer en lokal server-side-sporingsskrivning til en fil:
| Baseline Batch-anmodninger pr. sekund (2 minutters gennemsnit) | SQL Profiler Batch-anmodninger pr. sekund (2 minutters gennemsnit) |
|---|---|
| 14.492 | 4.015 |
De øverste ventetyper var som følger (jeg lavede et par testkørsler, og outputtet var konsistent):
| wait_type | waiting_tasks_count | ventetid_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.015 |
| SLEEP_TASK | 253 | 180.871 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.046 |
| HADR_WORK_QUEUE | 12 | 120.042 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.021 |
| XE_DISPATCHER_WAIT | 3 | 120.006 |
| VENT | 1 | 120.000 |
| LOGMGR_QUEUE | 931 | 119.993 |
| DIRTY_PAGE_POLL | 1.193 | 119.958 |
| XE_TIMER_EVENT | 55 | 119.954 |
Denne gang ser vi ikke TRACEWRITE (vi bruger en filudbyder nu) og den anden sporingsrelaterede ventetype, den udokumenterede SQLTRACE_INCREMENTAL_FLUSH_SLEEP klatrede op – men har i sammenligning med den første test meget lignende akkumuleret ventetid (120.046 vs. 120.006) – og min kollega Erin Stellato (@erinstellato) talte om denne særlige ventetype i sit indlæg Finding Out When Wait Statistics Were Last Cleared . Så ser man på de andre ventetyper, er der ingen, der springer ud som et pålideligt rødt flag.
Server-Side Trace-skrivning til en langsom I/O-sti
Hvad hvis vi lægger sporingsfilen på serversiden på langsom disk? Følgende tabel viser før-og-efter batch-anmodninger pr. sekund, når du aktiverer en lokal server-side-sporing, der skriver til en fil på en USB-stick:
| Baseline Batch-anmodninger pr. sekund (2 minutters gennemsnit) | SQL Profiler Batch-anmodninger pr. sekund (2 minutters gennemsnit) |
|---|---|
| 14.492 | 260 |
Som vi kan se – er ydeevnen væsentligt forringet – selv sammenlignet med den tidligere test.
De bedste ventetyper var som følger:
| wait_type | waiting_tasks_count | ventetid_ms |
|---|---|---|
| SQLTRACE_FILE_BUFFER | 357 | 351.174 |
| SP_SERVER_DIAGNOSTICS_SLEEP | 2.273 | 299.995 |
| SLEEP_TASK | 240 | 194.264 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 2 | 181.458 |
| REQUEST_FOR_DEADLOCK_SEARCH | 25 | 125.007 |
| LAZYWRITER_SLEEP | 63 | 124.437 |
| LOGMGR_QUEUE | 941 | 120.559 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 67 | 120.516 |
| VENT | 1 | 120.515 |
| DIRTY_PAGE_POLL | 1.204 | 120.513 |
En ventetype, der springer ud for denne test, er den udokumenterede SQLTRACE_FILE_BUFFER . Ikke meget dokumenteret på denne, men baseret på navnet kan vi lave et kvalificeret gæt (især i betragtning af denne særlige tests konfiguration).
Udvidede hændelser til ringbuffermålet
Lad os derefter gennemgå resultaterne for ækvivalenter til udvidede begivenhedssessioner. Jeg brugte følgende sessionsdefinition:
CREATE EVENT SESSION [ApplicationXYZ] ON SERVER ADD EVENT sqlserver.query_post_execution_showplan, ADD TARGET package0.ring_buffer(SET max_events_limit=(1000)) WITH (STARTUP_STATE=ON); GO
Følgende tabel viser før-og-efter batch-anmodninger pr. sekund, når en XE-session aktiveres med et ringbuffermål (fanger query_post_execution_showplan begivenhed):
| Baseline Batch-anmodninger pr. sekund (2 minutters gennemsnit) | SQL Profiler Batch-anmodninger pr. sekund (2 minutters gennemsnit) |
|---|---|
| 14.492 | 4.737 |
De bedste ventetyper var som følger:
| wait_type | waiting_tasks_count | ventetid_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 612 | 299.992 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.006 |
| SLEEP_TASK | 240 | 181.739 |
| LAZYWRITER_SLEEP | 120 | 120.219 |
| HADR_WORK_QUEUE | 12 | 120.038 |
| DIRTY_PAGE_POLL | 1.198 | 120.035 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.017 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.011 |
| LOGMGR_QUEUE | 936 | 120.008 |
| VENT | 1 | 120.001 |
Intet sprang ud som XE-relateret, kun baggrundsopgave "støj".
Udvidede hændelser til et filmål
Hvad med at ændre sessionen til at bruge et filmål i stedet for et ringbuffermål? Følgende tabel viser før-og-efter batch-anmodninger pr. sekund, når en XE-session aktiveres med et filmål i stedet for et ringbuffermål:
| Baseline Batch-anmodninger pr. sekund (2 minutters gennemsnit) | SQL Profiler Batch-anmodninger pr. sekund (2 minutters gennemsnit) |
|---|---|
| 14.492 | 4.299 |
De bedste ventetyper var som følger:
| wait_type | waiting_tasks_count | ventetid_ms |
|---|---|---|
| SP_SERVER_DIAGNOSTICS_SLEEP | 2.103 | 299.996 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 253 | 180.663 |
| LAZYWRITER_SLEEP | 120 | 120.187 |
| HADR_WORK_QUEUE | 12 | 120.029 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.019 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| VENT | 1 | 120.001 |
| XE_TIMER_EVENT | 59 | 119.966 |
| LOGMGR_QUEUE | 935 | 119.957 |
Intet, med undtagelse af XE_TIMER_EVENT , sprang ud som XE-relateret. Bob Wards Wait Type Repository omtaler dette som sikkert at ignorere, medmindre der var noget muligt galt - men realistisk set ville du bemærke denne normalt godartede ventetype, hvis den var på 9-pladsen på dit system under en ydeevneforringelse? Og hvad hvis du allerede filtrerer det fra på grund af dets normalt godartede natur?
Udvidede hændelser til et langsom I/O-stifilmål
Hvad nu hvis jeg lægger filen på en langsom I/O-sti? Følgende tabel viser før- og efter batch-anmodninger pr. sekund, når en XE-session aktiveres med et filmål på en USB-stick:
| Baseline Batch-anmodninger pr. sekund (2 minutters gennemsnit) | SQL Profiler Batch-anmodninger pr. sekund (2 minutters gennemsnit) |
|---|---|
| 14.492 | 4.386 |
De bedste ventetyper var som følger:
| wait_type | waiting_tasks_count | ventetid_ms |
|---|---|---|
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.046 |
| SLEEP_TASK | 253 | 180.719 |
| HADR_FILESTREAM_IOMGR_IOCOMPLETION | 240 | 120.427 |
| LAZYWRITER_SLEEP | 120 | 120.190 |
| HADR_WORK_QUEUE | 12 | 120.025 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.013 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.011 |
| VENT | 1 | 120.002 |
| DIRTY_PAGE_POLL | 1.197 | 119.977 |
| XE_TIMER_EVENT | 59 | 119.949 |
Igen, intet XE-relateret springer ud bortset fra XE_TIMER_EVENT .
Udvidede hændelser til et langsom I/O-stifilmål, ingen hændelsestab
Følgende tabel viser før-og-efter batch-anmodninger pr. sekund, når du aktiverer en XE-session med et filmål på en USB-stick, men denne gang uden at tillade tab af hændelse (EVENT_RETENTION_MODE=NO_EVENT_LOSS) – hvilket ikke anbefales, og du vil se i resultaterne, hvorfor det kunne være:
| Baseline Batch-anmodninger pr. sekund (2 minutters gennemsnit) | SQL Profiler Batch-anmodninger pr. sekund (2 minutters gennemsnit) |
|---|---|
| 14.492 | 539 |
De bedste ventetyper var som følger:
| wait_type | waiting_tasks_count | ventetid_ms |
|---|---|---|
| XE_BUFFERMGR_FREEBUF_EVENT | 8.773 | 1.707.845 |
| FT_IFTS_SCHEDULER_IDLE_WAIT | 4 | 237.003 |
| SLEEP_TASK | 337 | 180.446 |
| LAZYWRITER_SLEEP | 120 | 120.032 |
| DIRTY_PAGE_POLL | 1.198 | 120.026 |
| HADR_WORK_QUEUE | 12 | 120.009 |
| REQUEST_FOR_DEADLOCK_SEARCH | 24 | 120.007 |
| SQLTRACE_INCREMENTAL_FLUSH_SLEEP | 30 | 120.006 |
| VENT | 1 | 120.000 |
| XE_TIMER_EVENT | 59 | 119.944 |
Med den ekstreme gennemløbsreduktion ser vi XE_BUFFERMGR_FREEBUF_EVENT spring til nummer et på vores akkumulerede ventetidsresultater. Denne er dokumenteret i Books Online, og Microsoft fortæller os, at denne hændelse er forbundet med XE-sessioner, der er konfigureret til ingen tab af hændelser, og hvor alle buffere i sessionen er fulde.
Observatørpåvirkning
Bortset fra ventetyper var det interessant at bemærke, hvilken indflydelse hver observationsmetode havde på vores arbejdsbyrdes evne til at behandle batch-anmodninger:
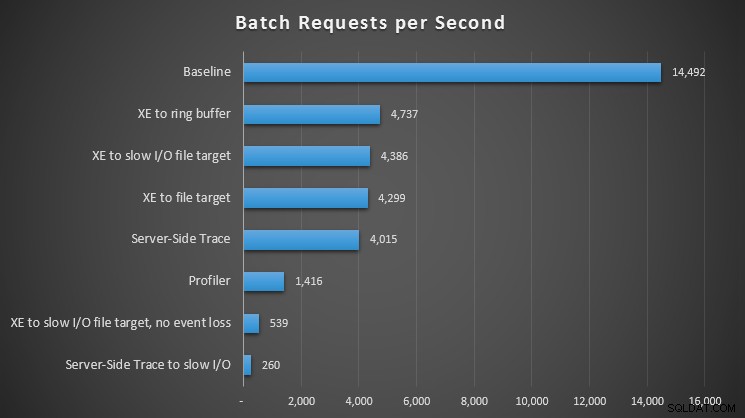
Indvirkning af forskellige observationsmetoder på batch-anmodninger pr. sekund
For alle tilgange var der et signifikant – men ikke chokerende – hit sammenlignet med vores baseline (ingen observation); den største smerte føltes dog ved brug af Profiler, når man brugte Server-Side Trace til en langsom I/O-sti eller udvidede hændelser til et filmål på en langsom I/O-sti – men kun når den var konfigureret til ingen hændelsestab. Med tab af hændelser fungerede denne opsætning faktisk på niveau med et filmål til en hurtig I/O-sti, formentlig fordi den var i stand til at droppe mange flere hændelser.
Oversigt
Jeg testede ikke alle mulige scenarier, og der er helt sikkert andre interessante kombinationer (for ikke at nævne forskellig adfærd baseret på SQL Server-versionen), men den vigtigste konklusion, jeg tager med fra denne udforskning, er, at du ikke altid kan stole på en åbenlys ventetype-akkumulering pointer, når du står over for et observatør overhead-scenarie. Baseret på testene i dette indlæg manifesterede kun tre ud af syv scenarier en specifik ventetype, der potentielt kunne hjælpe med at pege dig i den rigtige retning. Selv dengang – disse tests var på et kontrolleret system – og ofte filtrerer folk de førnævnte ventetyper fra som godartede baggrundstyper – så du måske slet ikke ser dem.
I betragtning af dette, hvad kan du gøre? For ydeevneforringelse uden klare eller tydelige symptomer anbefaler jeg at udvide omfanget for at spørge om spor og XE-sessioner (som en side – jeg anbefaler også at udvide dit omfang, hvis systemet er virtualiseret eller kan have forkerte strømindstillinger). For eksempel, som en del af fejlfinding af et system, skal du kontrollere sys.[traces] og sys.[dm_xe_sessions] for at se, om der kører noget på systemet, som er uventet. Det er et ekstra lag til det, du skal bekymre dig om, men at udføre et par hurtige valideringer kan spare dig en betydelig mængde tid.