Galera Cluster kommer med mange bemærkelsesværdige funktioner, der ikke er tilgængelige i standard MySQL-replikering (eller gruppereplikering); automatisk node-provisioning, ægte multi-master med konfliktløsninger og automatisk failover. Der er også en række begrænsninger, der potentielt kan påvirke klyngens ydeevne. Heldigvis, hvis du ikke er klar over disse, er der løsninger. Og hvis du gør det rigtigt, kan du minimere virkningen af disse begrænsninger og forbedre den samlede ydeevne.
Vi har tidligere dækket mange tips og tricks relateret til Galera Cluster, herunder at køre Galera på AWS Cloud. Dette blogindlæg dykker tydeligt ned i præstationsaspekterne med eksempler på, hvordan du får mest muligt ud af Galera.
Replikeringsnyttelast
Lidt introduktion - Galera replikerer skrivesæt under commit-fasen og overfører skrivesæt fra originalknudepunktet til modtagernoderne synkront gennem wsrep-replikeringsplugin'et. Dette plugin vil også certificere skrivesæt på modtagernoderne. Hvis certificeringsprocessen passerer, returnerer den OK til klienten på originator-knudepunktet og vil blive anvendt på modtagernoderne på et senere tidspunkt asynkront. Ellers vil transaktionen blive rullet tilbage på originator-knudepunktet (returfejl til klienten), og de skrivesæt, der er blevet overført til modtagernoderne, vil blive kasseret.
Et skrivesæt består af skriveoperationer inde i en transaktion, der ændrer databasetilstanden. autocommit i Galera Cluster er standard til 1 (aktiveret). Bogstaveligt talt vil enhver SQL-sætning, der udføres i Galera Cluster, blive omsluttet som en transaktion, medmindre du udtrykkeligt starter med BEGIN, START TRANSACTION eller SET autocommit=0. Følgende diagram illustrerer indkapslingen af en enkelt DML-sætning i et skrivesæt:
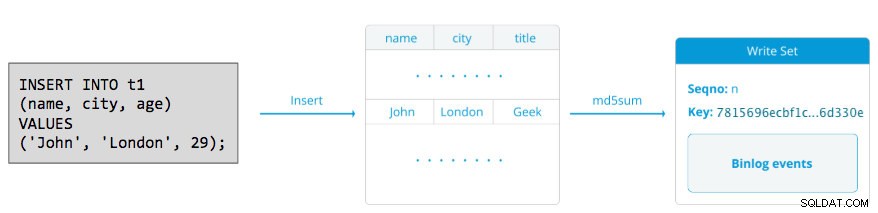
For DML (INSERT, UPDATE, DELETE..) består skrivesættets nyttelast af de binære loghændelser for en bestemt transaktion, mens for DDL'er (ALTER, GRANT, CREATE..) er skrivesættets nyttelast selve DDL-sætningen. For DML'er skal skrivesættet certificeres mod konflikter på modtagernoden, mens det for DDL'er (afhængigt af wsrep_osu_method , standard til TOI), kører klyngeklyngen DDL-sætningen på alle noder i den samme samlede ordresekvens, hvilket blokerer andre transaktioner i at forpligte sig, mens DDL er i gang (se også RSU). Med enkle ord håndterer Galera Cluster DDL- og DML-replikering forskelligt.
Tid for tur-retur
Generelt bestemmer følgende faktorer, hvor hurtigt Galera kan replikere et skrivesæt fra en originalknude til alle modtagernoder:
- Rundrejsetid (RTT) til den fjerneste node i klyngen fra originalknuden.
- Størrelsen af et skrivesæt, der skal overføres og certificeres til konflikt på modtagerknudepunktet.
For eksempel, hvis vi har en Galera-klynge med tre noder, og en af noderne er placeret 10 millisekunder væk (0,01 sekund), er det meget usandsynligt, at du kan skrive mere end 100 gange i sekundet til den samme række uden at komme i konflikt. Der er et populært citat fra Mark Callaghan, som beskriver denne adfærd ret godt:
"[I en Galera-klynge] kan en given række ikke ændres mere end én gang pr. RTT"
For at måle RTT-værdi skal du blot udføre ping på originalknuden til den fjerneste node i klyngen:
$ ping 192.168.55.173 # the farthest nodeVent et par sekunder (eller minutter), og afslut kommandoen. Den sidste linje i ping-statistiksektionen er det, vi leder efter:
--- 192.168.55.172 ping statistics ---
65 packets transmitted, 65 received, 0% packet loss, time 64019ms
rtt min/avg/max/mdev = 0.111/0.431/1.340/0.240 msmaks. værdien er 1,340 ms (0,00134s), og vi bør tage denne værdi, når vi estimerer minimum transaktioner pr. sekund (tps) for denne klynge. gennemsnittet værdien er 0,431ms (0,000431s), og vi kan bruge til at estimere gennemsnittet tps, mens min værdien er 0,111ms (0,000111s), som vi kan bruge til at estimere maksimum tps. Mdev betyder, hvordan RTT-prøverne blev fordelt fra gennemsnittet. Lavere værdi betyder mere stabil RTT.
Derfor kan transaktioner pr. sekund estimeres ved at dividere RTT (i sekund) i 1 sekund:

Resultatet,
- Minimum tps:1 / 0,00134 (maks. RTT) =746,26 ~ 746 tps
- Gennemsnitlig tps:1 / 0,000431 (gennemsnitlig RTT) =2320,19 ~ 2320 tps
- Maksimal tps:1 / 0,000111 (min. RTT) =9009,01 ~ 9009 tps
Bemærk, at dette kun er et estimat for at forudse replikeringsydelse. Der er ikke meget, vi kan gøre for at forbedre dette på databasesiden, når vi først har alt installeret og kørende. Undtagen hvis du flytter eller migrerer databaseserverne tættere på hinanden for at forbedre RTT mellem noder eller opgradere netværkets periferiudstyr eller infrastruktur. Dette ville kræve vedligeholdelsesvindue og ordentlig planlægning.
Sluk store transaktioner
En anden faktor er transaktionsstørrelsen. Efter at skrivesættet er overført, vil der være en certificeringsproces. Certificering er en proces til at bestemme, om noden kan anvende skrivesættet eller ej. Galera genererer MD5 checksum pseudo nøgler fra hver fuld række. Omkostningerne ved certificering afhænger af skrivesættets størrelse, hvilket udmønter sig i en række unikke nøgleopslag i certificeringsindekset (en hash-tabel). Hvis du opdaterer 500.000 rækker i en enkelt transaktion, for eksempel:
# a 500,000 rows table
mysql> UPDATE mydb.settings SET success = 1;Ovenstående vil generere et enkelt skrivesæt med 500.000 binære loghændelser i det. Dette enorme skrivesæt overstiger ikke wsrep_max_ws_size (standard til 2GB), så det vil blive overført af Galera-replikeringsplugin til alle noder i klyngen, hvilket bekræfter disse 500.000 rækker på modtagernoderne for eventuelle modstridende transaktioner, der stadig er i slavekøen. Til sidst returneres certificeringsstatussen til gruppereplikeringspluginnet. Jo større transaktionsstørrelsen er, jo højere risiko vil den være i konflikt med andre transaktioner, der kommer fra en anden master. Modstridende transaktioner spilder serverressourcer og forårsager en enorm tilbagerulning til originator-noden. Bemærk, at en rollback-operation i MySQL er meget langsommere og mindre optimeret end commit-operation.
Ovenstående SQL-sætning kan omskrives til en mere Galera-venlig sætning ved hjælp af simple loop, som eksemplet nedenfor:
(bash)$ for i in {1..500}; do \
mysql -uuser -ppassword -e "UPDATE mydb.settings SET success = 1 WHERE success != 1 LIMIT 1000"; \
sleep 2; \
doneOvenstående shell-kommando vil opdatere 1000 rækker pr. transaktion 500 gange og vente i 2 sekunder mellem udførelsen. Du kan også bruge en lagret procedure eller andre midler til at opnå et lignende resultat. Hvis omskrivning af SQL-forespørgslen ikke er en mulighed, skal du blot instruere applikationen til at udføre den store transaktion under et vedligeholdelsesvindue for at reducere risikoen for konflikter.
For store sletninger kan du overveje at bruge pt-archiver fra Percona Toolkit - et lav-impact, fremadrettet job til at nappe gamle data ud af bordet uden at påvirke OLTP-forespørgsler meget.
Parallelle slavetråde
I Galera er applieren en flertrådsproces. Applier er en tråd, der kører i Galera for at anvende de indgående skrivesæt fra en anden node. Hvilket betyder, at det er muligt for alle modtagere at udføre flere DML-operationer, der kommer direkte fra originator (master) noden samtidigt. Galera parallel replikering anvendes kun på transaktioner, når det er sikkert at gøre det. Det forbedrer sandsynligheden for, at noden synkroniserer med originalknuden. Replikeringshastigheden er dog stadig begrænset til RTT og skrivesætstørrelse.
For at få det bedste ud af dette, skal vi vide to ting:
- Antallet af kerner serveren har.
- Værdien af wsrep_cert_deps_distance status.
Status wsrep_cert_deps_distance fortæller os den potentielle grad af parallelisering. Det er værdien af den gennemsnitlige afstand mellem højeste og laveste seqno-værdier, der eventuelt kan anvendes parallelt. Du kan bruge wsrep_cert_deps_distance statusvariabel for at bestemme det maksimale antal mulige slavetråde. Vær opmærksom på, at dette er en gennemsnitsværdi over tid. For at få en god værdi skal du derfor ramme klyngen med skriveoperationer gennem testarbejdsbelastning eller benchmark, indtil du ser en stabil værdi udkomme.
For at få antallet af kerner kan du blot bruge følgende kommando:
$ grep -c processor /proc/cpuinfo
4Ideelt set er 2, 3 eller 4 tråde slaveapplier pr. CPU-kerne en god start. Minimumsværdien for slavetrådene bør derfor være 4 x antallet af CPU-kerner og må ikke overstige wsrep_cert_deps_distance værdi:
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cert_deps_distance';
+--------------------------+----------+
| Variable_name | Value |
+--------------------------+----------+
| wsrep_cert_deps_distance | 48.16667 |
+--------------------------+----------+Du kan kontrollere antallet af slave-appliertråde ved hjælp af wsrep_slave_thread variabel. Selvom dette er en dynamisk variabel, ville kun en forøgelse af antallet have en øjeblikkelig effekt. Hvis du reducerer værdien dynamisk, vil det tage noget tid, indtil applier-tråden forsvinder, efter at den er færdig. En anbefalet værdi er et sted mellem 16 og 48:
mysql> SET GLOBAL wsrep_slave_threads = 48;Bemærk, at for at parallelle slavetråde skal fungere, skal følgende indstilles (som normalt er forudkonfigureret til Galera Cluster):
innodb_autoinc_lock_mode=2Galera-cache (gcache)
Galera bruger en forudallokeret fil med en specifik størrelse kaldet gcache, hvor en Galera-node opbevarer en kopi af skrivesæt i cirkulær bufferstil. Som standard er dens størrelse 128 MB, hvilket er ret lille. Incremental State Transfer (IST) er en metode til at forberede en joiner ved kun at sende de manglende skrivesæt, der er tilgængelige i donorens gcache. IST er hurtigere end state snapshot transfer (SST), den er ikke-blokerende og har ingen væsentlig indvirkning på ydeevnen på donoren. Det bør være den foretrukne mulighed, når det er muligt.
IST kan kun opnås, hvis alle ændringer, der savnes af joineren, stadig er i donorens gcache-fil. Den anbefalede indstilling for dette er at være lige så stor som hele MySQL-datasættet. Hvis diskplads er begrænset eller dyr, er det afgørende at bestemme den rigtige størrelse af gcache-størrelsen, da det kan påvirke datasynkroniseringsydelsen mellem Galera-knudepunkter.
Nedenstående erklæring vil give os en idé om mængden af data, der replikeres af Galera. Kør følgende sætning på en af Galera-knuderne i myldretiden (testet på MariaDB>10.0 og PXC>5.6, galera>3.x):
mysql> SET @start := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); do sleep(60); SET @end := (SELECT SUM(VARIABLE_VALUE/1024/1024) FROM information_schema.global_status WHERE VARIABLE_NAME LIKE 'WSREP%bytes'); SET @gcache := (SELECT SUBSTRING_INDEX(SUBSTRING_INDEX(@@GLOBAL.wsrep_provider_options,'gcache.size = ',-1), 'M', 1)); SELECT ROUND((@end - @start),2) AS `MB/min`, ROUND((@end - @start),2) * 60 as `MB/hour`, @gcache as `gcache Size(MB)`, ROUND(@gcache/round((@end - @start),2),2) as `Time to full(minutes)`;
+--------+---------+-----------------+-----------------------+
| MB/min | MB/hour | gcache Size(MB) | Time to full(minutes) |
+--------+---------+-----------------+-----------------------+
| 7.95 | 477.00 | 128 | 16.10 |
+--------+---------+-----------------+-----------------------+
Vi kan vurdere, at Galera-knuden kan have cirka 16 minutters nedetid uden at kræve, at SST tilslutter sig (medmindre Galera ikke kan bestemme joiner-tilstanden). Hvis dette er for kort tid, og du har nok diskplads på dine noder, kan du ændre wsrep_provider_options="gcache.size=
Det anbefales også at bruge gcache.recover=yes i wsrep_provider_options (Galera>3.19), hvor Galera vil forsøge at gendanne gcache-filen til en brugbar tilstand ved opstart i stedet for at slette den, og dermed bevare muligheden for at have IST og undgå SST så meget som muligt. Codership og Percona har dækket dette i detaljer i deres blogs. IST er altid den bedste metode til at synkronisere efter, at en node slutter sig til klyngen igen. Det er 50 % hurtigere end xtrabackup eller mariabackup og 5 gange hurtigere end mysqldump.
Asynkron slave
Galera-noder er tæt koblede, hvor replikeringsydelsen er lige så hurtig som den langsomste knude. Galera bruger en flowkontrolmekanisme til at kontrollere replikationsflowet blandt medlemmer og eliminere enhver slaveforsinkelse. Replikeringen kan være hurtig eller langsom på hver knude og justeres automatisk af Galera. Hvis du vil vide mere om flowkontrol, så læs dette blogindlæg af Jay Janssen fra Percona.
I de fleste tilfælde er tunge operationer som langvarige analyser (læse-intensive) og backups (læse-intensive, låsning) ofte uundgåelige, hvilket potentielt kan forringe klyngens ydeevne. Den bedste måde at udføre denne type forespørgsler på er ved at sende dem til en løst koblet replikaserver, for eksempel en asynkron slave.
En asynkron slave replikerer fra en Galera-knude ved hjælp af standard MySQL asynkron replikeringsprotokol. Der er ingen begrænsning på antallet af slaver, der kan tilsluttes en Galera-node, og det er også muligt at kæde den ud med en mellemliggende master. MySQL-operationer, der udføres på denne server, vil ikke påvirke klyngens ydeevne, bortset fra den indledende synkroniseringsfase, hvor der skal tages en fuld backup på Galera-knuden for at iscenesætte slaven, før replikeringslinket etableres (selvom ClusterControl giver dig mulighed for at bygge asynkroniseringen slave fra en eksisterende backup først, før den forbindes til klyngen).
GTID (Global Transaction Identifier) giver en bedre transaktionskortlægning på tværs af noder og understøttes i MySQL 5.6 og MariaDB 10.0. Med GTID forenkles failover-handlingen på en slave til en anden master (en anden Galera-node), uden at det er nødvendigt at finde ud af den nøjagtige logfil og position. Galera kommer også med sin egen GTID-implementering, men disse to er uafhængige af hinanden.
Udskalering af en asynkron slave er et klik væk, hvis du bruger ClusterControl -> Tilføj replikeringsslave-funktion:
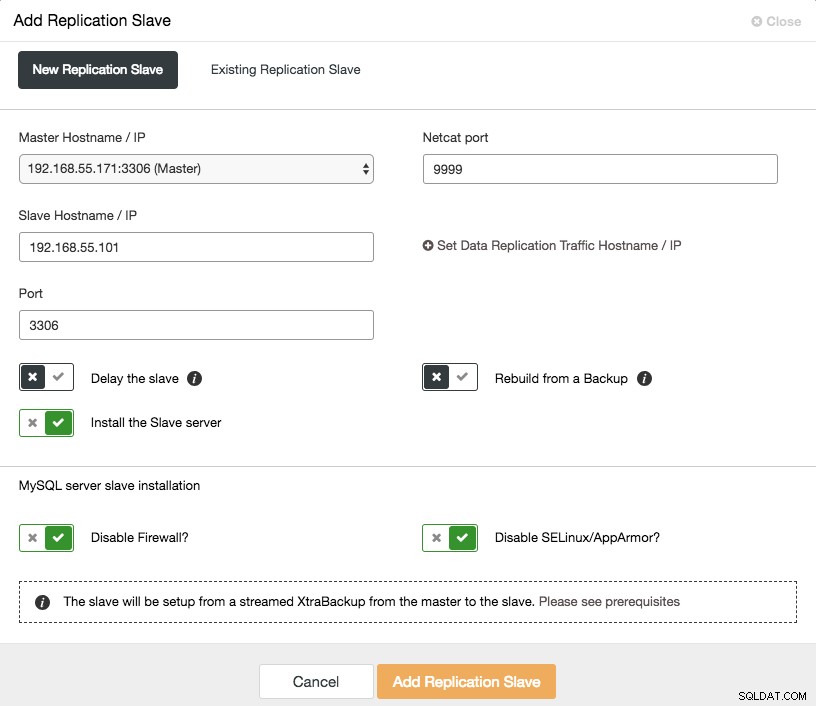
Bemærk, at binære logfiler skal være aktiveret på masteren (den valgte Galera-node), før vi kan fortsætte med denne opsætning. Vi har også dækket den manuelle måde i dette tidligere indlæg.
Følgende skærmbillede fra ClusterControl viser klyngetopologien, det illustrerer vores Galera Cluster-arkitektur med en asynkron slave:
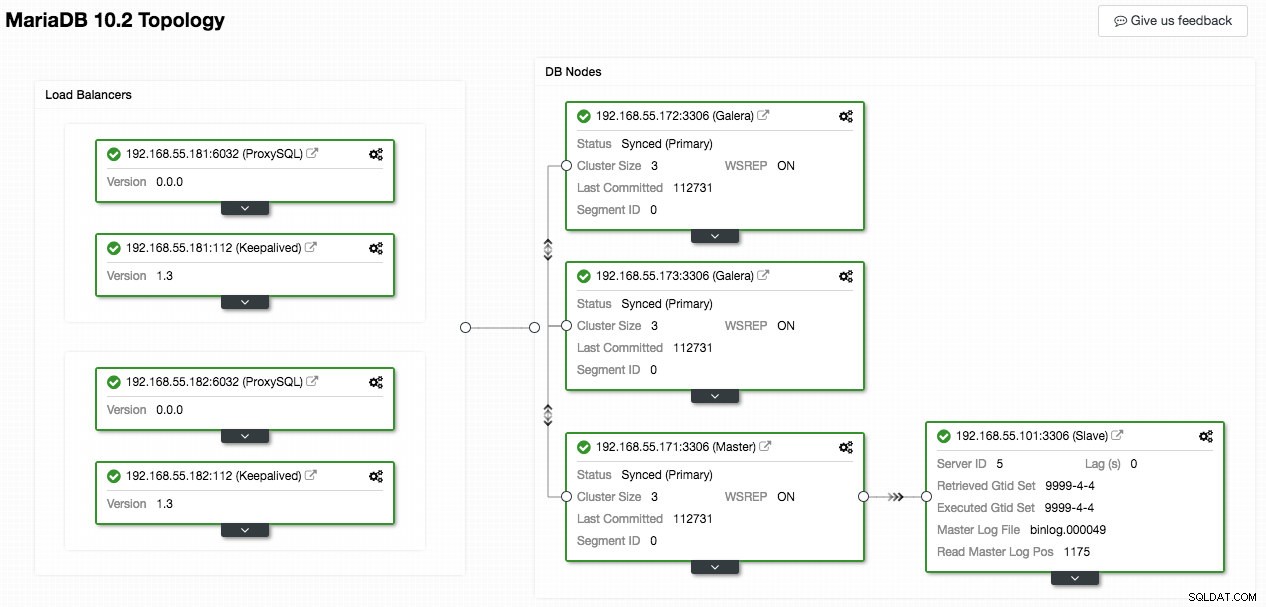
ClusterControl opdager automatisk topologien og genererer det super seje diagram som ovenfor. Du kan også udføre administrationsopgaver direkte fra denne side ved at klikke på gearikonet øverst til højre i hver boks.
SQL-bevidst omvendt proxy
ProxySQL og MariaDB MaxScale er intelligente omvendte proxyer, der forstår MySQL-protokollen og er i stand til at fungere som en gateway, router, belastningsbalancer og firewall foran dine Galera-noder. Ved hjælp af virtuelle IP-adresseudbydere som LVS eller Keepalved, og ved at kombinere dette med Galera multi-master replikeringsteknologi, kan vi have en meget tilgængelig databasetjeneste, der eliminerer alle mulige single-point-of-failures (SPOF) fra applikationspunktet -af-syn. Dette vil helt sikkert forbedre tilgængeligheden og pålideligheden af arkitekturen som helhed.
En anden fordel ved denne tilgang er, at du vil have mulighed for at overvåge, omskrive eller omdirigere de indkommende SQL-forespørgsler baseret på et sæt regler, før de rammer den faktiske databaseserver, hvilket minimerer ændringerne på applikations- eller klientsiden og dirigerer forespørgsler til en mere passende node for optimal ydeevne. Risikofyldte forespørgsler til Galera som LOCK TABLES og FLUSH TABLES MED LÆSELÅS kan forhindres langt frem, før de ville forårsage ødelæggelse af systemet, mens påvirkende forespørgsler som "hotspot"-forespørgsler (en række, som forskellige forespørgsler vil have adgang til på samme tid) kan blive omskrevet eller blive omdirigeret til en enkelt Galera-node for at reducere risikoen for transaktionskonflikter. For tunge skrivebeskyttede forespørgsler som OLAP eller backup, kan du dirigere dem over til en asynkron slave, hvis du har nogen.
Omvendt proxy overvåger også databasetilstanden, forespørgsler og variabler for at forstå topologiændringerne og producere en nøjagtig routingbeslutning til backend-serverne. Indirekte centraliserer den nodeovervågningen og klyngeoversigten uden at det er nødvendigt at tjekke hver eneste Galera-node regelmæssigt. Følgende skærmbillede viser ProxySQL-overvågningsdashboardet i ClusterControl:
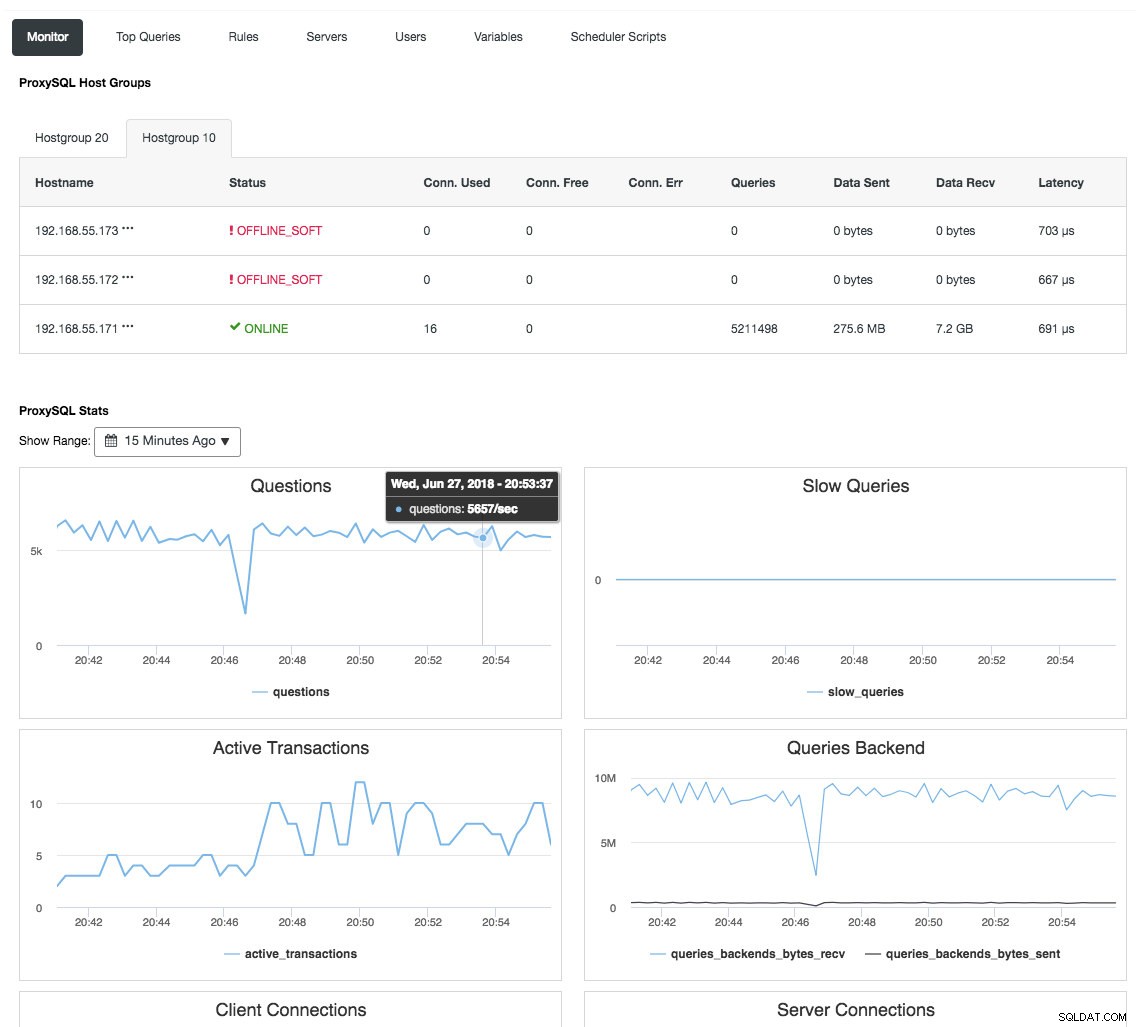
Der er også mange andre fordele, som en load balancer kan bringe for at forbedre Galera Cluster betydeligt, som beskrevet i detaljer i dette blogindlæg, Bliv en ClusterControl DBA:Making your DB-komponenter HA via Load Balancers.
Sidste tanker
Med en god forståelse for, hvordan Galera Cluster fungerer internt, kan vi omgå nogle af begrænsningerne og forbedre databasetjenesten. Glædelig klyngedannelse!