[ Del 1 | Del 2 | Del 3 ]
I del 1 viste jeg, hvordan både side- og columnstore-komprimering kunne reducere størrelsen af en 1TB-tabel med 80% eller mere. Selvom jeg var imponeret over, at jeg kunne krympe et bord fra 1 TB til 50 GB, var jeg ikke særlig tilfreds med den tid, det tog (alt fra 2 til 14 timer). Med nogle tip elskværdigt lånt fra folk som Joe Obbish, Lonny Niederstadt, Niko Neugebauer og andre, vil jeg i dette indlæg prøve at lave nogle ændringer i mit oprindelige forsøg på at få bedre belastningsydelse. Da det almindelige kolonnelagerindeks ikke komprimerede bedre end sidekomprimering på dette datasæt , og det tog 13 timer længere at komme dertil, vil jeg udelukkende fokusere på den mere avancerede løsning ved hjælp af COLUMNSTORE_ARCHIVE komprimering.
Nogle af de problemer, som jeg tror påvirkede ydeevnen, omfatter følgende:
- Dårlige valg af fillayout – Jeg lægger 8 filer i én filgruppe, med parallelitet, men ingen (eller suboptimal) partitionering, sprøjter I/O'er på tværs af flere filer med hensynsløs opgivelse. For at løse dette vil jeg:
- opdel tabellen i 8 partitioner (en pr. kerne)
- sæt hver partitions datafil i sin egen filgruppe
- brug 8 separate processer til at tilknytte hver partition
- brug arkivkomprimering på alle undtagen den "aktive" partition
- for mange små batches og suboptimal rækkegruppepopulation – ved at behandle 10 millioner rækker ad gangen, udfyldte jeg ni rækkegrupper med en pæn, 1.048.576 rækker, og så ville de resterende 562.816 rækker ende i en anden mindre rækkegruppe. Og enhver ujævn fordeling, som efterlod en rest på <102.400 rækker, ville sive indsætninger ind i den mindre effektive delta-lagerstruktur. For at fordele rækker mere ensartet og undgå delta store, vil jeg:
- behandle så meget af dataene som muligt i nøjagtige multipla af 1.048.576 rækker
- spred dem på 8 partitioner så jævnt som muligt
- brug en batchstørrelse tættere på 10x -> 100 millioner rækker
- planlægningsstabling – selvom jeg ikke tjekkede for dette, er det muligt, at noget af opbremsningen var forårsaget af, at en skemalægger påtog sig for meget arbejde, og en anden skemalægger ikke nok, på grund af round-robining. Nu hvor jeg med vilje vil indlæse dataene med 8 maxdop 1-processer i stedet for én maxdop 8-proces, for at holde alle planlæggere lige travlt, vil jeg:
- brug en lagret procedure, der forsøger at balancere jævnt på tværs af planlæggere (se side 189-191 i SQLCAT's Guide to:Relational Engine for inspirationen bag denne idé)
- aktiver global sporingsflag 2467 og 2469, som advaret mod i dokumentationen
- baggrundskolonnelagerkomprimeringsopgave – det var spild at lade dette køre under befolkning, da jeg alligevel planlagde at bygge om til sidst. Denne gang vil jeg:
- deaktiver denne opgave ved hjælp af globalt sporingsflag 634
Jeg skrottede den indledende partitionsfunktion og -skema og byggede en ny baseret på en mere jævn fordeling af dataene. Jeg vil have 8 partitioner til at matche antallet af kerner og antallet af datafiler, for at maksimere den "fattigmands parallelitet", jeg planlægger at bruge.
Først skal vi oprette et nyt sæt filgrupper, hver med sin egen fil:
ALTER DATABASE OCopi TILFØJ FILGROUP FG_CCI_Part1; ÆNDRE DATABASE OKopier TILFØJ FIL (navn =N'CCI_Part_1', størrelse =250000, filnavn ='K:\Data\o_cci_p_1.mdf') TIL FILGROUP FG_CCI_Part1; -- ... 6 flere ... ÆNDRE DATABASE OKopier TILFØJ FILGRUPPE FG_CCI_Part8; ÆNDRE DATABASE OKopier TILFØJ FIL (navn =N'CCI_Part_8', størrelse =250000, filnavn ='K:\Data\o_cci_p_8.mdf') TIL FILGRUPPE FG_CCI_Part8;
Dernæst så jeg på antallet af rækker i tabellen:3.754.965.954. For at distribuere disse præcis jævnt over 8 partitioner, det ville være 469.370.744,25 rækker pr. partition. For at få det til at fungere godt, lad os få partitionsgrænserne til at rumme den næste multiplum af 1.048.576 rækker. Dette er 1.048.576 x 448 =469.762.048 – hvilket ville være antallet af rækker, vi skyder efter i de første 7 partitioner, hvilket efterlader 466.631.618 rækker i den sidste partition. For at se den faktiske OID værdier, der ville tjene som grænser for at indeholde det optimale antal rækker i hver partition, kørte jeg denne forespørgsel mod den originale tabel (da det tog 25 minutter at køre, lærte jeg hurtigt at dumpe disse resultater i en separat tabel):
;WITH x AS (VÆLG OID, rn =ROW_NUMBER() OVER (ORDER BY OID) FRA dbo.tblOriginal WITH (NOLOCK))SELECT OID, PartitionID =1+(rn/((1048576*448)+1) ) INTO dbo.stage FRA x WHERE rn % (1048576*112) =0;
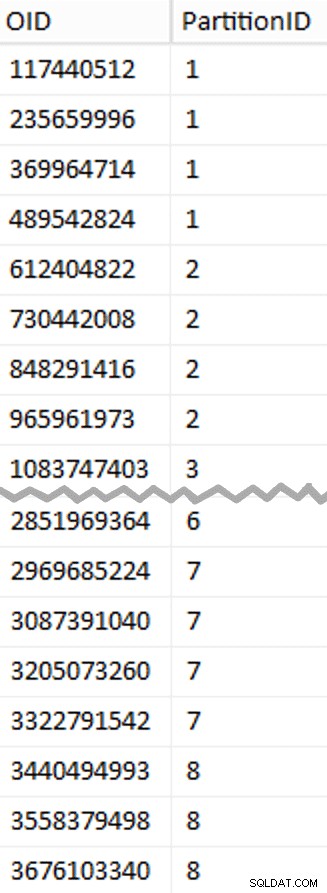 Mere at pakke ud her, end du måske forventer. CTE'en udfører alle de tunge løft, da den skal scanne hele 1,14 TB tabellen og tildele et rækkenummer til hver række . Jeg vil kun returnere hver
Mere at pakke ud her, end du måske forventer. CTE'en udfører alle de tunge løft, da den skal scanne hele 1,14 TB tabellen og tildele et rækkenummer til hver række . Jeg vil kun returnere hver (1048576*112)th række dog, da disse er mine batchgrænserækker, så dette er hvad WHERE klausul gør. Husk, at jeg vil opdele arbejdet i batches tættere på 100 millioner rækker ad gangen, men jeg vil heller ikke rigtig behandle 469 millioner rækker i ét skud. Så ud over at dele dataene op i 8 partitioner, vil jeg opdele hver af disse partitioner i fire batches af 117.440.512 (1.048.576*112) rækker. Hvert tilstødende sæt af fire batches tilhører én partition, så PartitionID I derive tilføjer blot én til resultatet af det aktuelle rækkenummer heltal divideret med (1.048.576*448) , som sikrer, at grænsen altid er i "venstre" sæt. Vi tilføjer derefter en til resultatet, fordi vi ellers ville henvise til en 0-baseret samling af partitioner, og det er der ingen, der ønsker.
Ok, det var mange ord. Til højre er et billede, der viser (forkortet) indholdet af stadiet tabel (klik for at vise det fulde resultat, fremhæver partitionsgrænseværdier).
Vi kan derefter udlede en anden forespørgsel fra den iscenesættelsestabel, der viser os min og maks. værdierne for hver batch inde i hver partition, såvel som den ekstra batch, der ikke er taget højde for (rækkerne i den oprindelige tabel med OID større end den højeste grænseværdi):
;WITH x AS ( SELECT OID, PartitionID FROM dbo.stage),y AS ( SELECT PartitionID, MinID =COALESCE(LAG(OID,1) OVER (ORDER BY OID),-1)+1, MaxID =OID FRA x UNION ALL SELECT PartitionID =8, MinID =MAX(OID)+1, MaxID =4000000000 -- nemmere end at huske det rigtige max. FRA x)SELECT PartitionID, BatchID =ROW_NUMBER() OVER (PARTITION BY PartitionID ORDER BY MinID), MinID, MaxID, RowsInRange =KONVERTER(int, NULL)INTO dbo.BatchQueueFROM y; -- lad os ikke efterlade dette som en bunke:CREATE UNIQUE CLUSTERED INDEX PK_bq ON dbo.BatchQueue(PartitionID, BatchID);
Disse værdier ser sådan ud:
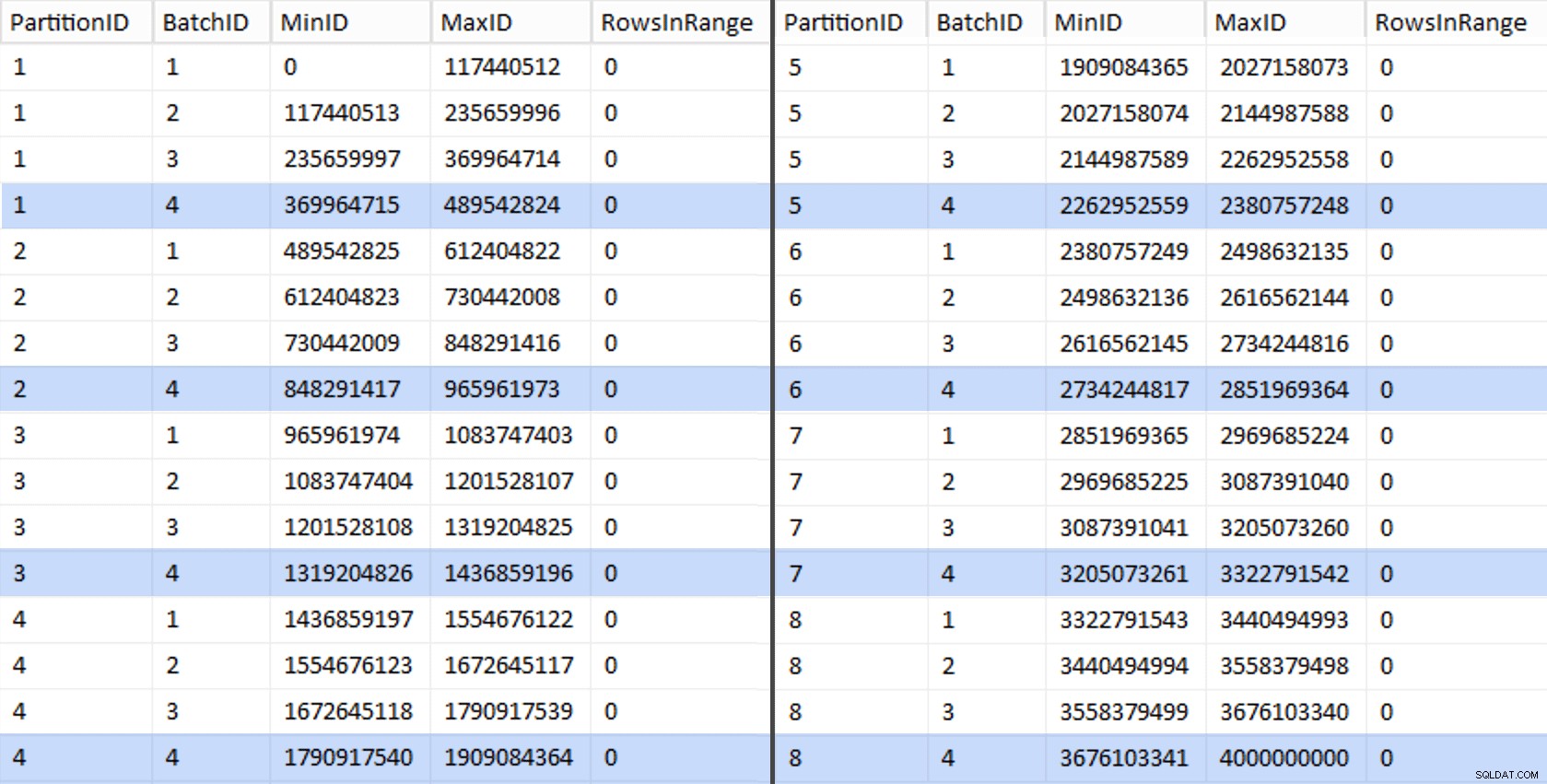
For at teste vores arbejde kan vi udlede et sæt forespørgsler derfra, der opdaterer BatchQueue med faktiske rækketal fra tabellen.
DECLARE @sql nvarchar(max) =N''; VÆLG @sql +='OPDATERING dbo.BatchQueue SET RowsInRange =( VÆLG COUNT(*) FRA dbo.tblOriginal MED (NOLOCK) WHERE CostID MELLEM ' + RTRIM(MinID) + ' OG ' + RTRIM(MaxID) + ') HVOR MinID =' + RTRIM(MinID) + ' OG MaxID =' + RTRIM(MaxID) + ';'FRA dbo.BatchQueue; EXEC sys.sp_executesql @sql;
Dette tog omkring 6 minutter på mit system. Derefter kan du køre følgende forespørgsel for at vise, at hver batch undtagen den allersidste er i stand til fuldt ud at udfylde rækkegrupper og ikke efterlade nogen rest til potentiel delta-butiksbrug:
ALTER TABLE dbo.BatchQueue ADD DeltaStore AS (RowsInRange % 1048576);
Nu ser tabellen således ud:
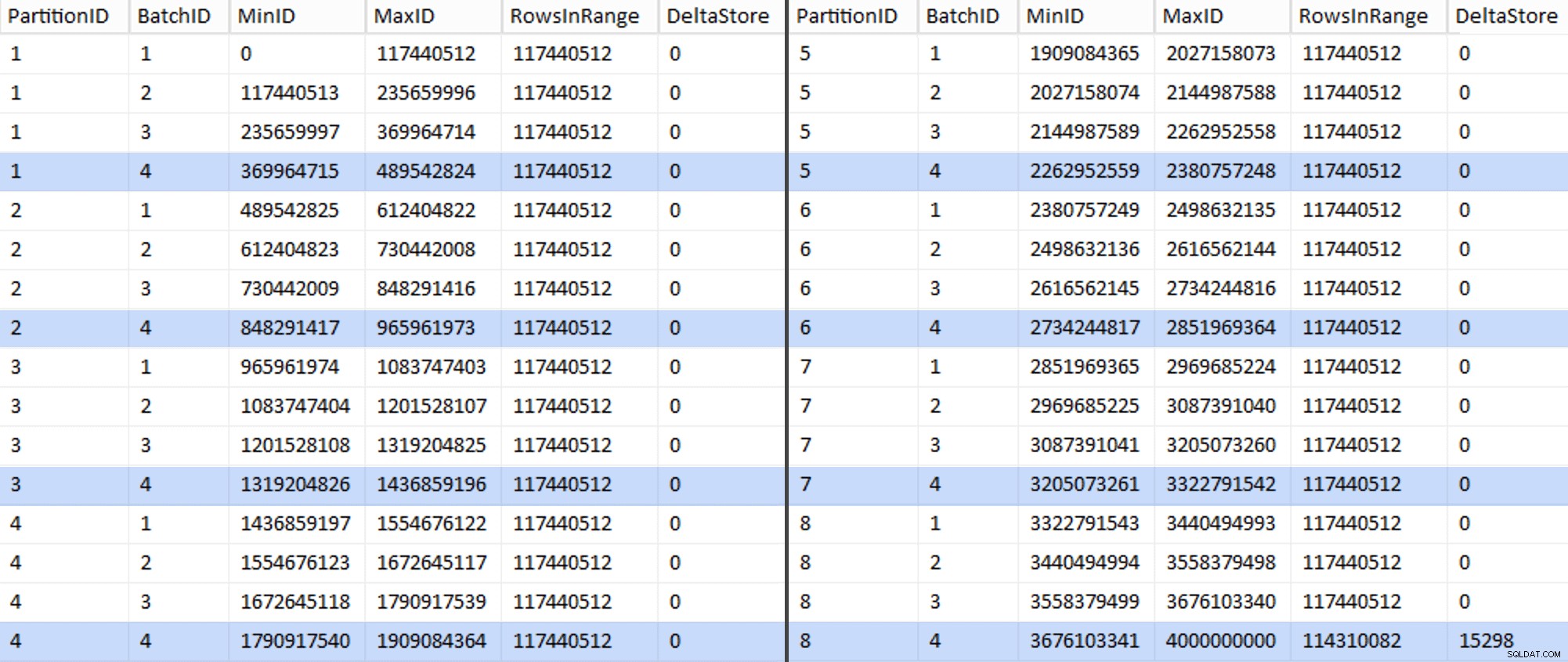
Sikkert nok har hver batch de beregnede 117.440.512 millioner rækker, bortset fra den sidste, som i det mindste ideelt vil indeholde vores eneste ukomprimerede deltalager. Vi kan sandsynligvis også forhindre dette ved at ændre batchstørrelsen en smule for denne partition så alle fire batches køres med samme størrelse, eller ved at ændre antallet af batches til at rumme et andet multiplum af 102.400 eller 1.048.576. Da det ville kræve at få ny OID værdier fra basistabellen, hvilket tilføjer yderligere 25 minutter plus til vores migreringsindsats, vil jeg lade denne ene ufuldkomne partition glide - især da vi alligevel ikke får den fulde arkivkomprimering udbytte af det.
BatchQueue tabel begynder at vise tegn på at være nyttig til at behandle vores batches for at migrere data til vores nye, opdelte, klyngede kolonnelagertabel. Som vi skal skabe, nu hvor vi kender grænserne. Der er kun 7 grænser, så du kan bestemt gøre dette manuelt, men jeg kan godt lide at få dynamisk SQL til at gøre mit arbejde for mig:
DECLARE @sql nvarchar(max) =N''; VÆLG @sql =N'OPRET PARTITIONSFUNKTION PF_OID([bigint])SOM OMRÅDE TILBAGE FOR VÆRDIER ( ' + STRING_AGG(MaxID, ', ') + ');' FRA dbo.BatchQueue WHERE PartitionID <8 OG BatchID =4; PRINT @sql;-- EXEC sys.sp_executesql @sql;
Resultater:
OPRET PARTITIONSFUNKTION PF_OID([bigint])SOM OMRÅDE TILBAGE TIL VÆRDIER ( 489542824, 965961973, 1436859196, 1909084364, 23807572518, 95226, 95226, 95226, 95226, 95226, 9526, 9526, 9526, 96226, 96226, 23807572518, 96226, 96226, 34226, 95226, 965961973, 1909084364;Når det er oprettet, kan vi oprette vores partitionsskema og tildele hver efterfølgende partition til dens dedikerede fil:
OPRET PARTITIONSSCHEMA PS_OID SOM PARTITION PF_OID TIL ( CCI_Part1, CCI_Part2, CCI_Part3, CCI_Part4, CCI_Part5, CCI_Part6, CCI_Part7, CCI_Part8);Nu kan vi oprette tabellen og gøre den klar til migrering:
CREATE TABLE dbo.tblPartitionedCCI( OID bigint NOT NULL, IN1 int NOT NULL, IN2 int NOT NULL, VC1 varchar(3) NULL, BI1 bigint NULL, IN3 int NULL, VC2 varchar(128) NOT NULL, VC3 varchar( 128) NOT NULL, VC4 varchar(128) NULL, NM1 numeric(24,12) NULL, NM2 numeric(24,12) NULL, NM3 numeric(24,12) NULL, BI2 bigint NULL, IN4 int NULL, BILL , NM4 numeric(24,12) NULL, IN5 int NULL, NM5 numeric(24,12) NULL, DT1 date NULL, VC5 varchar(128) NULL, BI4 bigint NULL, BI5 bigint NULL, BI6 bigint NULL, BI6 bigint NULL, , NV1 nvarchar(512) NULL, VB1 varbinary(8000) NULL, IN6 int NULL, IN7 int NULL, IN8 int NULL, -- skal oprette en PK-begrænsning på partitionsskemaet... CONSTRAINT PK_CCI_Part PRIMARY KEY CLUSTERED (OID ON PS_OID(OID)); -- ... kun for at droppe det med det samme...ALTER TABLE dbo.tblPartitionedCCI DROP CONSTRAINT PK_CCI_Part;GO -- ... så vi kan erstatte det med CCI:CREATE CLUSTERED COLUMNSTORE INDEX CCI_Part PÅ dbo.tblPartitionedCCI PÅ PS_OID(OID );GO -- genopbyg nu med den komprimering, vi ønsker:ALTER TABLE dbo.tblPartitionedCCI REBUILD PARTITION =ALT MED ( DATA_KOMPRESSION =COLUMNSTORE_ARCHIVE PÅ PARTITIONER (1 TIL 7), DATA_COMPRESSION =COLUMNSTORE (8) PARTITION); I del 3 vil jeg yderligere konfigurereBatchQueuetabel, opbygge en procedure for processer til at skubbe data til den nye struktur, og analysere resultaterne.[ Del 1 | Del 2 | Del 3 ]