Tabelpartitionering i SQL Server er i bund og grund en måde at få flere fysiske tabeller (rækkesæt) til at ligne en enkelt tabel. Denne abstraktion udføres udelukkende af forespørgselsprocessoren, et design, der gør tingene nemmere for brugerne, men som stiller komplekse krav til forespørgselsoptimeringsværktøjet. Dette indlæg ser på to eksempler, som overstiger optimizerens evner i SQL Server 2008 og fremefter.
Tilmeld dig kolonnebestillingsspørgsmål
Dette første eksempel viser, hvordan den tekstmæssige rækkefølge ON klausulbetingelser kan påvirke den forespørgselsplan, der produceres, når du forbinder partitionerede tabeller. Til at starte med har vi brug for et partitioneringsskema, en partitioneringsfunktion og to tabeller:
CREATE PARTITION FUNCTION PF (integer)
AS RANGE RIGHT
FOR VALUES
(
10000, 20000, 30000, 40000, 50000,
60000, 70000, 80000, 90000, 100000,
110000, 120000, 130000, 140000, 150000
);
CREATE PARTITION SCHEME PS
AS PARTITION PF
ALL TO ([PRIMARY]);
GO
CREATE TABLE dbo.T1
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T1
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
);
CREATE TABLE dbo.T2
(
c1 integer NOT NULL,
c2 integer NOT NULL,
c3 integer NOT NULL,
CONSTRAINT PK_T2
PRIMARY KEY CLUSTERED (c1, c2, c3)
ON PS (c1)
); Dernæst indlæser vi begge tabeller med 150.000 rækker. Dataene betyder ikke så meget; dette eksempel bruger en standard Numbers-tabel, der indeholder alle heltalværdier fra 1 til 150.000 som datakilde. Begge tabeller er indlæst med de samme data.
INSERT dbo.T1 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
INSERT dbo.T2 WITH (TABLOCKX)
(c1, c2, c3)
SELECT
N.n * 1,
N.n * 2,
N.n * 3
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000;
Vores testforespørgsel udfører en simpel indre sammenføjning af disse to tabeller. Igen, forespørgslen er ikke vigtig eller beregnet til at være særlig realistisk, den bruges til at demonstrere en mærkelig effekt, når du forbinder opdelte tabeller. Den første form af forespørgslen bruger en ON klausul skrevet i c3, c2, c1 kolonnerækkefølge:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1; Eksekveringsplanen, der er udarbejdet for denne forespørgsel (på SQL Server 2008 og nyere) indeholder en parallel hash join, med en estimeret pris på 2.6953 :
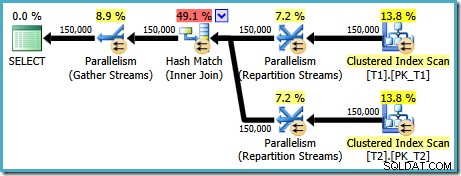
Dette er lidt uventet. Begge tabeller har et klynget indeks i (c1, c2, c3) rækkefølge, opdelt med c1, så vi ville forvente en sammenføjning, der udnytter indeksrækkefølgen. Lad os prøve at skrive ON klausul i (c1, c2, c3) rækkefølge i stedet for:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c1 = t2.c1
AND t1.c2 = t2.c2
AND t1.c3 = t2.c3; Udførelsesplanen bruger nu den forventede sammenføjning med en estimeret pris på 1,64119 (ned fra 2.6953 ). Optimeringsværktøjet beslutter også, at det ikke er værd at bruge parallel eksekvering:
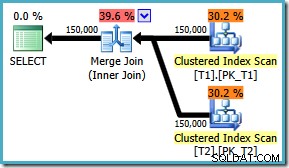
Når vi bemærker, at sammenføjningsplanen klart er mere effektiv, kan vi forsøge at gennemtvinge en sammenføjning for den oprindelige ON klausulrækkefølge ved hjælp af et forespørgselstip:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (MERGE JOIN); Den resulterende plan bruger en sammenføjning som anmodet, men den har også sorteringer på begge input og går tilbage til at bruge parallelisme. De anslåede omkostninger ved denne plan er hele 8,71063 :
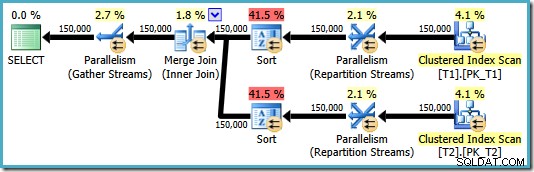
Begge sorteringsoperatorer har de samme egenskaber:
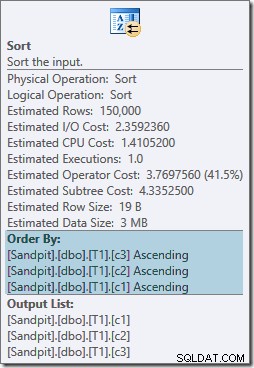
Optimeringsværktøjet mener, at flettesammenføjningen har brug for sine input sorteret i strengt skrevet rækkefølge ON klausul, der indfører eksplicitte sorteringer som et resultat. Optimizeren er klar over, at en merge join kræver sine input sorteret på samme måde, men den ved også, at kolonnerækkefølgen ikke betyder noget. Merge join on (c1, c2, c3) er lige så tilfreds med input sorteret på (c3, c2, c1), som det er med input sorteret på (c2, c1, c3) eller enhver anden kombination.
Desværre er denne begrundelse brudt i forespørgselsoptimeringsværktøjet, når partitionering er involveret. Dette er en optimeringsfejl der er blevet rettet i SQL Server 2008 R2 og senere, selvom sporingsflag 4199 er påkrævet for at aktivere rettelsen:
SELECT *
FROM dbo.T1 AS T1
JOIN dbo.T2 AS T2
ON t1.c3 = t2.c3
AND t1.c2 = t2.c2
AND t1.c1 = t2.c1
OPTION (QUERYTRACEON 4199);
Du ville normalt aktivere dette sporingsflag ved hjælp af DBCC TRACEON eller som en opstartsmulighed, fordi QUERYTRACEON tip er ikke dokumenteret til brug med 4199. Sporingsflaget er påkrævet i SQL Server 2008 R2, SQL Server 2012 og SQL Server 2014 CTP1.
Uanset hvad flaget er aktiveret, producerer forespørgslen nu den optimale sammenføjning uanset ON klausulrækkefølge:
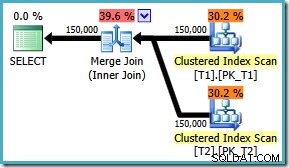
Der er ingen rettelse til SQL Server 2008 , er løsningen at skrive ON klausul i den 'rigtige' rækkefølge! Hvis du støder på en forespørgsel som denne på SQL Server 2008, så prøv at tvinge en sammenfletning og se på sorteringerne for at bestemme den 'korrekte' måde at skrive din forespørgsel på ON klausul.
Dette problem opstår ikke i SQL Server 2005, fordi denne udgivelse implementerede partitionerede forespørgsler ved hjælp af APPLY model:

SQL Server 2005-forespørgselsplanen forbinder én partition fra hver tabel ad gangen ved at bruge en tabel i hukommelsen (den konstante scanning), der indeholder partitionsnumre, der skal behandles. Hver partition flettes sammen separat på indersiden af sammenføjningen, og 2005-optimeringsværktøjet er smart nok til at se, at ON klausulens kolonnerækkefølge er ligegyldig.
Denne seneste plan er et eksempel på en samlokaliseret fusionsforbindelse , en facilitet, der gik tabt, da der blev flyttet fra SQL Server 2005 til den nye partitioneringsimplementering i SQL Server 2008. Et forslag om Connect for at genindsætte samlokaliserede sammenføjninger er blevet lukket, da Won't Fix.
Grupper efter ordrespørgsmål
Den anden ejendommelighed, jeg vil se på, følger et lignende tema, men relaterer sig til rækkefølgen af kolonner i en GROUP BY klausulen i stedet for ON klausul af en indre sammenføjning. Vi skal bruge en ny tabel for at demonstrere:
CREATE TABLE dbo.T3
(
RowID integer IDENTITY NOT NULL,
UserID integer NOT NULL,
SessionID integer NOT NULL,
LocationID integer NOT NULL,
CONSTRAINT PK_T3
PRIMARY KEY CLUSTERED (RowID)
ON PS (RowID)
);
INSERT dbo.T3 WITH (TABLOCKX)
(UserID, SessionID, LocationID)
SELECT
ABS(CHECKSUM(NEWID())) % 50,
ABS(CHECKSUM(NEWID())) % 30,
ABS(CHECKSUM(NEWID())) % 10
FROM dbo.Numbers AS N
WHERE
N.n BETWEEN 1 AND 150000; Tabellen har et justeret ikke-klynget indeks, hvor "aligned" blot betyder, at den er opdelt på samme måde som det klyngede indeks (eller heap):
CREATE NONCLUSTERED INDEX nc1 ON dbo.T3 (UserID, SessionID, LocationID) ON PS (RowID);
Vores testforespørgsel grupperer data på tværs af de tre ikke-klyngede indekskolonner og returnerer et antal for hver gruppe:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 GROUP BY LocationID, UserID, SessionID;
Forespørgselsplanen scanner det ikke-klyngede indeks og bruger et Hash Match Aggregate til at tælle rækker i hver gruppe:
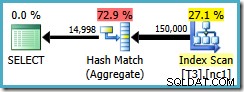
Der er to problemer med Hash Aggregate:
- Det er en blokerende operatør. Ingen rækker returneres til klienten, før alle rækker er blevet aggregeret.
- Det kræver en hukommelsesbevilling at holde hash-tabellen.
I mange scenarier i den virkelige verden ville vi foretrække et Stream Aggregate her, fordi denne operatør kun blokerer pr. gruppe og ikke kræver en hukommelsesbevilling. Ved at bruge denne mulighed ville klientapplikationen begynde at modtage data tidligere, ville ikke vente på, at hukommelsen blev tildelt, og SQL Serveren kan bruge hukommelsen til andre formål.
Vi kan kræve, at forespørgselsoptimeringsværktøjet bruger et Stream Aggregate til denne forespørgsel ved at tilføje en OPTION (ORDER GROUP) forespørgselstip. Dette resulterer i følgende udførelsesplan:

Sort-operatøren blokerer fuldt ud og kræver også en hukommelsesbevilling, så denne plan ser ud til at være værre end blot at bruge et hashaggregat. Men hvorfor er den slags nødvendig? Egenskaberne viser, at rækkerne sorteres i den rækkefølge, der er angivet af vores GROUP BY klausul:
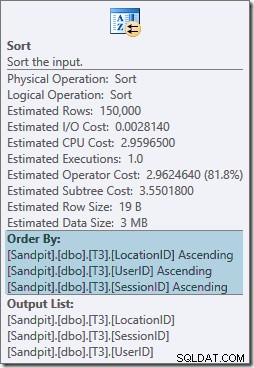
Denne type er forventet fordi partitionsjustering af indekset (i SQL Server 2008 og frem) betyder, at partitionsnummeret tilføjes som en ledende kolonne i indekset. Faktisk skyldes de ikke-klyngede indeksnøgler (partition, bruger, session, placering) partitioneringen. Rækker i indekset er stadig sorteret efter bruger, session og placering, men kun inden for hver partition.
Hvis vi begrænser forespørgslen til en enkelt partition, burde optimeringsværktøjet være i stand til at bruge indekset til at feed et Stream Aggregate uden sortering. Hvis det kræver en forklaring, betyder angivelse af en enkelt partition, at forespørgselsplanen kan fjerne alle andre partitioner fra den ikke-klyngede indeksscanning, hvilket resulterer i en strøm af rækker, der er sorteret efter (bruger, session, placering).
Vi kan opnå denne partitioneliminering eksplicit ved at bruge $PARTITION funktion:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID;
Desværre bruger denne forespørgsel stadig et Hash Aggregate med en anslået planpris på 0,287878 :
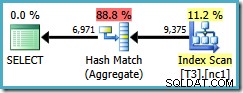
Scanningen er nu lidt over én partition, men (bruger, session, placering) bestilling har ikke hjulpet optimizeren til at bruge et Stream Aggregate. Du kan indvende, at (bruger, session, placering) bestilling ikke er nyttig, fordi GROUP BY klausulen er (placering, bruger, session), men nøglerækkefølgen er ligegyldig for en grupperingsoperation.
Lad os tilføje en ORDER BY klausul i rækkefølgen af indeksnøglerne for at bevise pointen:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 WHERE $PARTITION.PF(RowID) = 1 GROUP BY LocationID, UserID, SessionID ORDER BY UserID, SessionID, LocationID;
Bemærk, at ORDER BY klausulen matcher den ikke-klyngede indeksnøglerækkefølge, selvom GROUP BY klausul ikke. Udførelsesplanen for denne forespørgsel er:
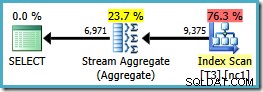
Nu har vi det Stream Aggregate, vi ledte efter, med en anslået planomkostning på 0,0423925 (sammenlignet med 0,287878 for Hash Aggregate-planen – næsten 7 gange mere).
Den anden måde at opnå et Stream Aggregate på her er at omarrangere GROUP BY kolonner for at matche de ikke-klyngede indeksnøgler:
SELECT LocationID, UserID, SessionID, COUNT_BIG(*) FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1 GROUP BY UserID, SessionID, LocationID;
Denne forespørgsel producerer den samme Stream Aggregate-plan, som vist umiddelbart ovenfor, med nøjagtig de samme omkostninger. Denne følsomhed over for GROUP BY kolonnerækkefølgen er specifik for partitionerede tabelforespørgsler i SQL Server 2008 og nyere.
Du kan måske genkende, at årsagen til problemet her ligner den tidligere sag, der involverer en Merge Join. Både Merge Join og Stream Aggregate kræver input sorteret på join- eller aggregeringsnøglerne, men ingen af dem bekymrer sig om rækkefølgen af disse nøgler. En Merge Join på (x, y, z) er lige så glade for at modtage rækker sorteret efter (y, z, x) eller (z, y, x), og det samme gælder for Stream Aggregate.
Denne optimeringsbegrænsning gælder også for DISTINCT under samme omstændigheder. Følgende forespørgsel resulterer i en Hash Aggregate-plan med en estimeret pris på 0,286539 :
SELECT DISTINCT LocationID, UserID, SessionID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
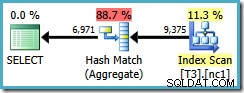
Hvis vi skriver DISTINCT kolonner i rækkefølgen af de ikke-klyngede indeksnøgler...
SELECT DISTINCT UserID, SessionID, LocationID FROM dbo.T3 AS T1 WHERE $PARTITION.PF(RowID) = 1;
…vi belønnes med en Stream Aggregate-plan med en pris på 0,041455 :

For at opsummere er dette en begrænsning af forespørgselsoptimeringsværktøjet i SQL Server 2008 og senere (inklusive SQL Server 2014 CTP 1), som ikke løses ved at bruge sporingsflag 4199 som det var tilfældet med Merge Join-eksemplet. Problemet opstår kun med partitionerede tabeller med en GROUP BY eller DISTINCT over tre eller flere kolonner ved hjælp af et justeret partitioneret indeks, hvor en enkelt partition behandles.
Som med Merge Join-eksemplet repræsenterer dette et tilbageskridt fra SQL Server 2005-adfærden. SQL Server 2005 tilføjede ikke en underforstået ledende nøgle til partitionerede indekser ved hjælp af en APPLY teknik i stedet for. I SQL Server 2005, alle forespørgsler præsenteret her ved hjælp af $PARTITION at specificere et enkelt partitionsresultat i forespørgselsplaner, der udfører partitionseliminering og bruge Stream Aggregates uden nogen forespørgselstekst omarrangering.
Ændringerne af partitioneret tabelbehandling i SQL Server 2008 forbedrede ydeevnen på flere vigtige områder, primært relateret til effektiv parallelbehandling af partitioner. Desværre havde disse ændringer bivirkninger, som ikke alle er blevet løst i senere udgivelser.