Introduktion
For nylig stødte vi på et interessant ydeevneproblem på en af vores SQL Server-databaser, der behandler transaktioner med en alvorlig hastighed. Transaktionstabellen, der blev brugt til at fange disse transaktioner, blev et varmt bord. Som et resultat dukkede problemet op i applikationslaget. Det var en intermitterende timeout af sessionen, der forsøgte at bogføre transaktioner.
Dette skete, fordi en session typisk ville "holde fast" på bordet og forårsage en række falske låse i databasen.
Den første reaktion fra en typisk databaseadministrator ville være at identificere den primære blokeringssession og afslutte den sikkert. Dette var sikkert, fordi det typisk var en SELECT-sætning eller en inaktiv session.
Der var også andre forsøg på at løse problemet:
- Tømmer bordet. Dette forventedes at give god ydeevne, selvom forespørgslen skulle scanne en fuld tabel.
- Aktivering af isolationsniveauet READ COMMITTED SNAPSHOT for at reducere virkningen af blokeringssessioner.
I denne artikel vil vi forsøge at genskabe en forsimplet version af scenariet og bruge den til at vise, hvor simpel indeksering kan løse situationer som denne, når det gøres rigtigt.
To relaterede tabeller
Tag et kig på liste 1 og liste 2. De viser de forenklede versioner af tabeller, der er involveret i det pågældende scenarie.
-- Listing 1: Create TranLog Table
use DB2
go
create table TranLog (
TranID INT IDENTITY(1,1)
,CustomerID char(4)
,ProductCount INT
,TotalPrice Money
,TranTime Timestamp
)
-- Listing 2: Create TranDetails Table
use DB2
go
create table TranDetails (
TranDetailsID INT IDENTITY(1,1)
,TranID INT
,ProductCode uniqueidentifier
,UnitCost Money
,ProductCount INT
,TotalPrice Money
)
Liste 3 viser en trigger, der indsætter fire rækker i TranDetails tabel for hver række indsat i TranLog tabel.
-- Listing 3: Create Trigger
CREATE TRIGGER dbo.GenerateDetails
ON dbo.TranLog
AFTER INSERT
AS
BEGIN
-- SET NOCOUNT ON added to prevent extra result sets from
-- interfering with SELECT statements.
SET NOCOUNT ON;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
insert into dbo.TranDetails (TranID, ProductCode,UnitCost, ProductCount, TotalPrice)
select top 1 dbo.TranLog.TranID, NEWID(), dbo.TranLog.TotalPrice/dbo.TranLog.ProductCount, dbo.TranLog.ProductCount, dbo.TranLog.TotalPrice
from dbo.TranLog order by TranID desc;
END
GO
Deltag i forespørgsel
Det er typisk at finde transaktionstabeller understøttet af store tabeller. Formålet er at beholde meget ældre transaktioner eller at gemme detaljerne i poster opsummeret i den første tabel. Tænk på dette som ordrer og ordredetaljer tabeller, der er typiske i SQL Server-eksempeldatabaser. I vores tilfælde overvejer vi TranLog og TranDetails tabeller.
Under normale omstændigheder udfylder transaktioner disse to tabeller over tid. Med hensyn til rapportering eller simple forespørgsler, vil forespørgslen udføre en joinforbindelse på disse to tabeller. Denne join vil udnytte en fælles kolonne mellem tabellerne.
Først udfylder vi tabellen ved hjælp af forespørgslen i liste 4.
-- Listing 4: Insert Rows in TranLog
use DB2
go
insert into TranLog values ('CU01', 5, '50.45', DEFAULT);
insert into TranLog values ('CU02', 7, '42.35', DEFAULT);
insert into TranLog values ('CU03', 15, '39.55', DEFAULT);
insert into TranLog values ('CU04', 9, '33.50', DEFAULT);
insert into TranLog values ('CU05', 2, '105.45', DEFAULT);
go 1000
use DB2
go
select * from TranLog;
select * from TranDetails;
I vores eksempel er den almindelige kolonne, der bruges af joinforbindelsen, TranID kolonne:
-- Listing 5 Join Query
-- 5a
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.CustomerID='CU03';
-- 5b
select * from TranLog a join TranDetails b
on a.TranID=b.TranID where a.TranID=30;
Du kan se de to simple eksempelforespørgsler, der bruger en joinforbindelse til at hente poster fra TranLog og TranDetails .
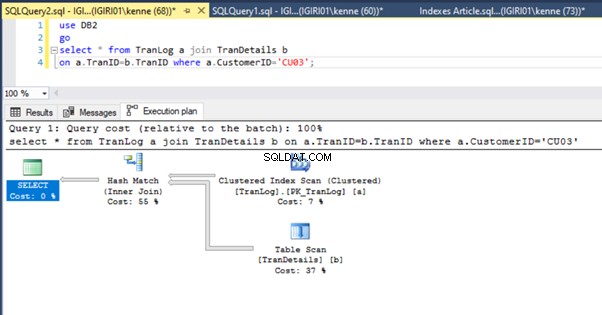
Når vi kører forespørgslerne i liste 5, skal vi i begge tilfælde lave en fuld tabelscanning på begge tabeller (se figur 1 og 2). Den dominerende del af hver forespørgsel er de fysiske operationer. Begge er indre sammenføjninger. Liste 5a bruger dog et Hash Match deltage, mens liste 5b bruger en Indlejret løkke tilslutte. Bemærk:Liste 5a returnerer 4000 rækker, mens liste 4b returnerer 4 rækker.
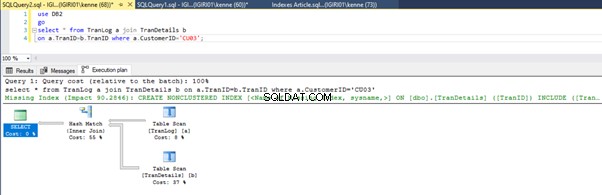
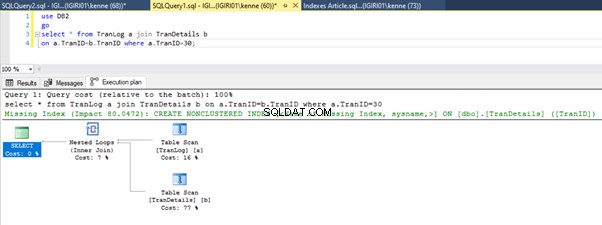
Tre trin til justering af ydeevne
Den første optimering, vi laver, er at introducere et indeks (en primær nøgle, for at være præcis) på TranID kolonne i TranLog tabel:
-- Listing 6: Create Primary Key
alter table TranLog add constraint PK_TranLog primary key clustered (TranID);
Figur 3 og 4 viser, at SQL Server bruger dette indeks i begge forespørgsler, og laver en scanning i liste 5a og en søgning i liste 5b.
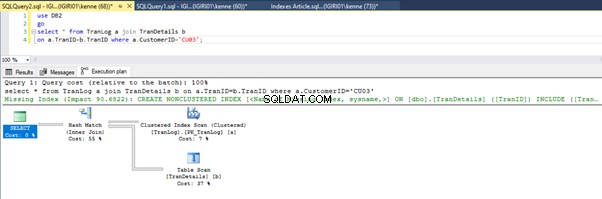
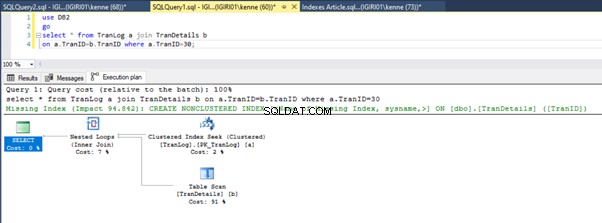
Vi har en indekssøgning i notering 5b. Det sker på grund af kolonnen involveret i WHERE-sætningsprædikatet – TranID. Det er den kolonne, vi har anvendt et indeks på.
Dernæst introducerer vi en fremmednøgle på TranID kolonne i TranDetails tabel (liste 7).
-- Listing 7: Create Foreign Key
alter table TranDetails add constraint FK_TranDetails foreign key (TranID) references TranLog (TranID);
Dette ændrer ikke meget i udførelsesplanen. Situationen er stort set den samme som vist tidligere i figur 3 og 4.
Derefter introducerer vi et indeks på kolonnen med fremmednøgle:
-- Listing 8: Create Index on Foreign Key
create index IX_TranDetails on TranDetails (TranID);
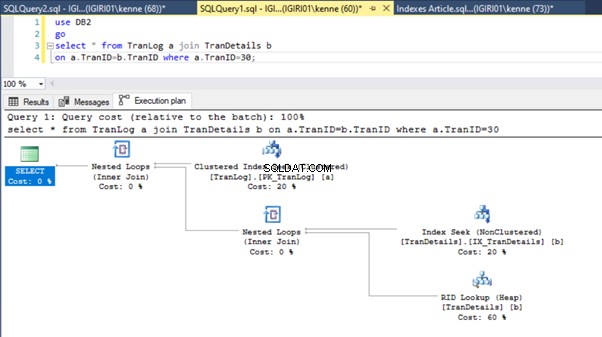
Denne handling ændrer udførelsesplanen for notering 5b dramatisk (se figur 6). Vi ser flere indeks søger at ske. Læg også mærke til RID-opslaget i figur 6.
RID-opslag på heaps sker typisk i fravær af en primær nøgle. En heap er en tabel uden primærnøgle.
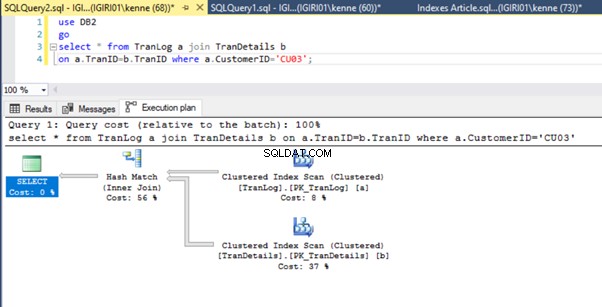
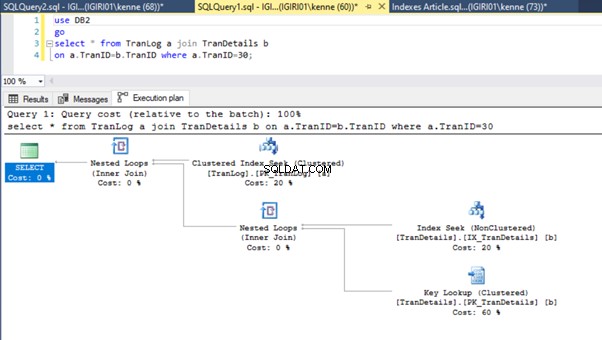
Til sidst tilføjer vi en primær nøgle til TranDetails bord. Dette fjerner tabelscanningen og RID-heap-opslaget i henholdsvis lister 5a og 5b (se figur 7 og 8).
-- Listing 9: Create Primary Key on TranDetailsID
alter table TranDetails add constraint PK_TranDetails primary key clustered (TranDetailsID);
Konklusion
Ydeevneforbedringen introduceret af indekser er velkendt for selv nybegyndere DBA. Vi vil dog påpege, at du skal se nærmere på, hvordan forespørgsler bruger indekser.
Ydermere er ideen at etablere løsningen i det særlige tilfælde, hvor vi har joinforespørgslerne mellem Transaktionslog tabeller og Transaktionsdetaljer tabeller.
Det giver generelt mening at håndhæve forholdet mellem sådanne tabeller ved hjælp af en nøgle og introducere indekser til primær- og fremmednøglekolonnerne.
Ved udvikling af applikationer, der bruger et sådant design, bør udviklere huske de nødvendige indekser og relationer på designstadiet. Moderne værktøjer til SQL Server-specialister gør disse krav meget nemmere at opfylde. Du kan profilere dine forespørgsler ved hjælp af det specialiserede Query Profiler-værktøj. Det er en del af den multifunktionelle professionelle løsning dbForge Studio til SQL Server udviklet af Devart for at gøre livet for DBA enklere.