I denne artikel fortsætter jeg med at udforske løsninger til den matchende udbud med efterspørgsel udfordring. Tak til Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie, Ian og Peter Larsson for at sende jeres løsninger.
I sidste måned dækkede jeg løsninger baseret på en revideret intervalskæringstilgang sammenlignet med den klassiske. Den hurtigste af disse løsninger kombinerede ideer fra Kamil, Luca og Daniel. Det forenede to forespørgsler med usammenhængende sargable prædikater. Det tog løsningen 1,34 sekunder at fuldføre mod et input på 400K-rækker. Det er ikke for lurvet i betragtning af, at løsningen baseret på den klassiske interval intersections-tilgang tog 931 sekunder at fuldføre mod det samme input. Husk også, at Joe kom med en genial løsning, der er afhængig af den klassiske interval skæringsmetode, men som optimerer matchningslogikken ved at samle intervaller baseret på den største intervallængde. Med det samme input på 400.000 rækker tog det Joes løsning 0,9 sekunder at færdiggøre. Det vanskelige ved denne løsning er, at dens ydeevne forringes, når den største intervallængde øges.
I denne måned udforsker jeg fascinerende løsninger, der er hurtigere end Kamil/Luca/Daniel Revised Intersections-løsningen og er neutrale i forhold til intervallængde. Løsningerne i denne artikel er skabt af Brian Walker, Ian, Peter Larsson, Paul White og mig.
Jeg testede alle løsninger i denne artikel i forhold til auktionsinputtabellen med 100K, 200K, 300K og 400K rækker og med følgende indekser:
-- Indeks til understøttelse af løsning OPRET UNIKT IKKE-KLUSTERET INDEX idx_Code_ID_i_Quantity PÅ dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Aktiver batch-mode Window Aggregate OPRET IKKE KLUSTERET COLUMNSTORE INDEX idx_cs PÅ dbo.Auctions(ID) WHERE ID =-1 OG ID =-2;
Når jeg beskriver logikken bag løsningerne, antager jeg, at auktionstabellen er udfyldt med følgende lille sæt eksempeldata:
ID-kode Mængde----------- ---- ----------1 D 5,0000002 D 3,0000003 D 8,0000005 D 2,0000006 D 8,0000007 D 4,0000008 D 2,0000000 S0 00000000 S0 00000000 S0 00000000 S0 2,0000004000 S 2,0000005000 S 4,0000006000 S 3,0000007000 S 2,000000
Følgende er det ønskede resultat for disse eksempeldata:
DemandID SupplyID TradeQuantity---------------------------------------------1 1000 5,0000002 1000 3,0000003 2000 6,0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Brian Walkers løsning
Outer joins er ret almindeligt brugt i SQL-forespørgselsløsninger, men når du bruger dem, bruger du langtfra enkeltsidede. Når jeg underviser om udvendige sammenføjninger, får jeg ofte spørgsmål, hvor jeg spørger om eksempler på praktiske anvendelsesmuligheder for fuld udvendig sammenføjning, og der er ikke så mange. Brians løsning er et smukt eksempel på en praktisk anvendelse af fulde ydre samlinger.
Her er Brians komplette løsningskode:
SLIP TABEL HVIS FINDER #MyPairings; CREATE TABLE #MyPairings(DemandID INT NOT NULL, SupplyID INT NOT NULL, TradeQuantity DECIMAL(19,06) NOT NULL); MED D AS( SELECT A.ID, SUM(A.Quantity) OVER (OPDELING AF A.Code ORDER BY A.ID ROWS UNboundED PRECEDING) AS Kører FRA dbo.Auctions AS A WHERE A.Code ='D'),S AS( SELECT A.ID, SUM(A.Quantity) OVER (PARTITION BY A.Code ORDER BY A.ID ROWS UNBOUNDED PRECEDING) AS Kører FRA dbo.Auctions AS A WHERE A.Code ='S'),W AS( VÆLG D.ID SOM DemandID, S.ID AS SupplyID, ISNULL(D.Running, S.Running) AS Kører FRA D FULD JOIN S PÅ D.Running =S.Running),Z AS( VÆLG CASE NÅR W.DemandID ER IKKE NULL SÅ W.DemandID ANDERS MIN(W.DemandID) OVER (ORDNERING EFTER W.RUNNING RÆKKER MELLEM AKTUELLE RÆKKE OG UBEGRÆNSET FØLGENDE) ENDER SOM DemandID, TILFÆLDE NÅR W.SupplyID IKKE ER NULL SÅ W.SupplyID ELSE MIN(W. ) OVER (REGLER EFTER W.RUNNING RÆKKER MELLEM AKTUELLE RÆKKE OG UBEGRÆNSET FØLGENDE) SLUT SOM SupplyID, W.Running FROM W)INSERT #MyPair ings( DemandID, SupplyID, TradeQuantity ) VÆLG Z.DemandID, Z.SupplyID, Z.Running - ISNULL(LAG(Z.Running) OVER (ORDER BY Z.Running), 0.0) SOM TradeQuantity FRA Z HVOR Z.DemandID IKKE ER NULL OG Z.SupplyID ER IKKE NULL;
Jeg reviderede Brians oprindelige brug af afledte tabeller med CTE'er for klarhedens skyld.
CTE D beregner løbende samlede efterspørgselsmængder i en resultatkolonne kaldet D.Running, og CTE S beregner løbende samlede forsyningsmængder i en resultatkolonne kaldet S.Running. CTE W udfører derefter en fuld ydre joinforbindelse mellem D og S, der matcher D.Running med S.Running, og returnerer den første ikke-NULL blandt D.Running og S.Running som W.Running. Her er resultatet, du får, hvis du forespørger på alle rækker fra W sorteret ved at køre:
DemandID SupplyID kører------------ ---------- ----------1 NULL 5,0000002 1000 8,000000NULL 2000 14,0000003 3000 16,0000005 4000 18,00000 NULL 5000 22,000000NULL 6000 25,0000006 NULL 26,000000NULL 7000 27,0000007 NULL 30,0000008 NULL 32,000000
Ideen om at bruge en fuld ydre sammenføjning baseret på et prædikat, der sammenligner de løbende totaler efter efterspørgsel og udbud, er en genistreg! De fleste rækker i dette resultat - de første 9 i vores tilfælde - repræsenterer resultatparringer, hvor der mangler lidt ekstra beregninger. Rækker med efterfølgende NULL ID'er af en af slagsen repræsenterer poster, der ikke kan matches. I vores tilfælde repræsenterer de sidste to rækker efterspørgselsposter, der ikke kan matches med udbudsposter. Så det, der er tilbage her, er at beregne DemandID, SupplyID og TradeQuantity for resultatparringerne og at filtrere de poster fra, der ikke kan matches.
Logikken, der beregner resultatet DemandID og SupplyID, udføres i CTE Z som følger (forudsat bestilling i W ved at køre):
- DemandID:hvis DemandID ikke er NULL, så DemandID, ellers minimum DemandID starter med den aktuelle række
- SupplyID:hvis SupplyID ikke er NULL, så SupplyID, ellers minimum SupplyID, der starter med den aktuelle række
Her er resultatet, du får, hvis du forespørger Z og bestiller rækkerne ved at køre:
DemandID SupplyID kører ------------ ---------- ----------1 1000 5,0000002 1000 8,0000003 2000 14,0000003 3000 16,0000005 4000 18,00000 22,0000006 6000 25,0000006 7000 26,0000007 7000 27,0000007 NULL 30,0000008 NULL 32,000000
Den ydre forespørgsel bortfiltrerer rækker fra Z, der repræsenterer indgange af én art, der ikke kan matches af indgange af den anden type ved at sikre, at både DemandID og SupplyID ikke er NULL. Resultatparringernes handelsmængde beregnes som den aktuelle løbende værdi minus den tidligere løbende værdi ved hjælp af en LAG-funktion.
Her er, hvad der bliver skrevet til #MyPairings-tabellen, som er det ønskede resultat:
DemandID SupplyID TradeQuantity---------------------------------------------1 1000 5,0000002 1000 3,0000003 2000 6,0000003 3000 2,0000005 4000 2,0000006 5000 4,0000006 6000 3,0000006 7000 1,0000007 7000 1,000000
Planen for denne løsning er vist i figur 1.
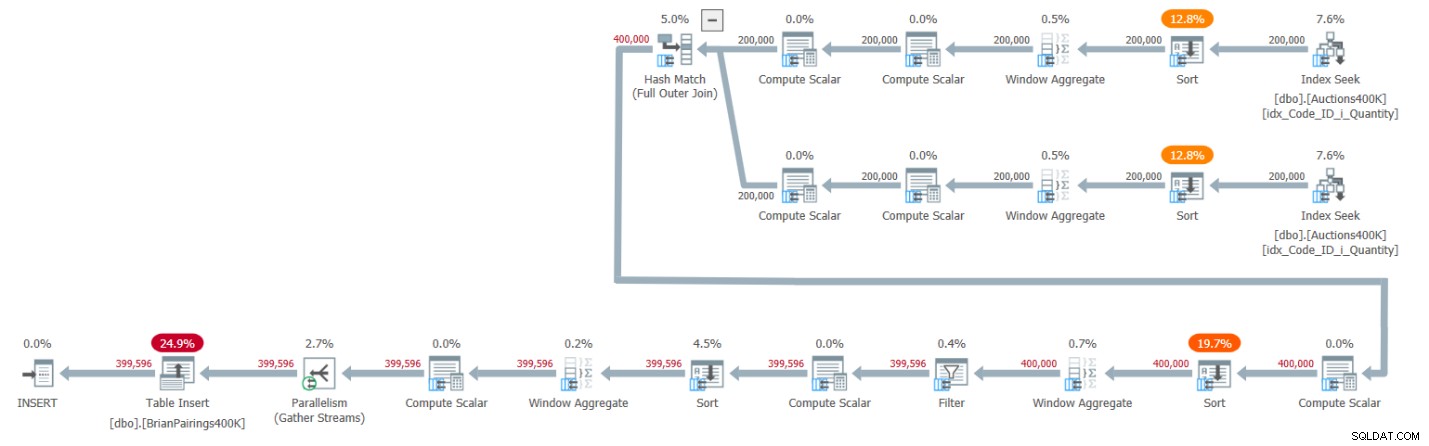 Figur 1:Forespørgselsplan for Brians løsning
Figur 1:Forespørgselsplan for Brians løsning
De to øverste grene af planen beregner de løbende totaler for efterspørgsel og udbud ved hjælp af en batch-mode Window Aggregate-operator, hver efter at have hentet de respektive poster fra det understøttende indeks. Som jeg forklarede i tidligere artikler i serien, da indekset allerede har rækkerne ordnet, som Window Aggregate-operatorerne skal have dem til, ville du tro, at eksplicitte sorteringsoperatorer ikke burde være påkrævet. Men SQL Server understøtter i øjeblikket ikke en effektiv kombination af parallel ordrebevarende indeksoperation forud for en parallel batch-mode Window Aggregate-operator, så som følge heraf går en eksplicit parallel Sort-operator forud for hver af de parallelle Window Aggregate-operatorer.
Planen bruger en batch-mode hash join til at håndtere den fulde ydre join. Planen bruger også to ekstra batch-mode Window Aggregate-operatorer forud for eksplicitte sorteringsoperatorer til at beregne MIN- og LAG-vinduefunktionerne.
Det er en ret effektiv plan!
Her er de køretider, jeg fik for denne løsning mod inputstørrelser fra 100.000 til 400.000 rækker på sekunder:
100K:0,368200K:0,845300K:1,255400K:1,315
Itziks løsning
Den næste løsning på udfordringen er et af mine forsøg på at løse den. Her er den komplette løsningskode:
SLIP TABEL HVIS FINDER #MyPairings; MED C1 AS( VÆLG *, SUM(Mængde) OVER(OPDELING EFTER KodeORDNERING EFTER ID RÆKKER UBEGRÆNSET FOREGÅENDE) SOM SumMængde FRA dbo.Auktioner),C2 AS( VÆLG *, SUM(Mængde * CASE Code WHEN 'D' THEN -1 NÅR 'S' SÅ 1 SLUTTER) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) SOM Lagerniveau, LAG(SumAntal, 1, 0,0) OVER(ORDNER EFTER SumMængde, Kode) SOM PrevSumQty, MAX(CASE WHEN Code ='D' THEN ID END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS PrevDemandID, MAX(CASE WHEN Code ='S' THEN ID END) OVER(ORDER BY SumQty, Code ROWS UNBOUNDED PRECEDING) AS PrevSupplyID, MIN(CASE WHEN) ='D' SÅ ID END) OVER(ORDER BY SumQty, Code RÆKKER MELLEM AKTUELLE RÆKKE OG UBEGRÆNSET FØLGENDE) SOM NextDemandID, MIN(CASE NÅR Kode ='S' THEN ID END) OVER(ORDER BY SumQty, Code RÆKKER MELLEM AKTUELLE RÆKKE OG UBEGRÆNSET FØLGENDE) SOM NextSupplyID FRA C1),C3 AS( SELECT *, CASE Code NÅR 'D ' THEN ID WHEN 'S' SÅ CASE NÅR StockLevel> 0 THEN NextDemandID ELSE PrevDemandID END END AS DemandID, CASE Code WHEN 'S' SÅ ID NÅR 'D' SÅ CASE NÅR StockLevel <=0 THEN NextSupplyID ELSE PrevSupplyID END AS SumQty - PrevSumQty AS TradeQuantity FRA C2)VÆLG DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM C3WHERE TradeQuantity> 0,0 OG DemandID ER IKKE NULL OG SupplyID ER IKKE NULL;
CTE C1 forespørger i auktionstabellen og bruger en vinduesfunktion til at beregne løbende samlede efterspørgsels- og udbudsmængder, kalder resultatkolonnen SumQty.
CTE C2 forespørger C1 og beregner en række attributter ved hjælp af vinduesfunktioner baseret på SumQty og Code-rækkefølge:
- Lagerniveau:Det aktuelle lagerniveau efter behandling af hver post. Dette beregnes ved at tildele et negativt fortegn til efterspørgselsmængder og et positivt fortegn til leveringsmængder og summere disse mængder til og med den aktuelle indtastning.
- PrevSumQty:Forrige rækkes SumQty-værdi.
- PrevDemandID:Sidste ikke-NULL-efterspørgsels-id.
- PrevSupplyID:Sidste ikke-NULL forsynings-id.
- NextDemandID:Næste ikke-NULL-efterspørgsels-id.
- NextSupplyID:Næste ikke-NULL forsynings-id.
Her er indholdet af C2 sorteret efter SumQty og Code:
ID-kode Mængde SumQty Lagerniveau PrevSumQty PrevDemandID PrevSupplyID NextDemandID NextSupplyID----- ---- ---------- ---------- ---------- ----------- ------------ ------------ ------------ - ----------- 1 D 5.000000 5.000000 -5.000000 0.000000 1 NULL 1 10002 D 3.000000 8.000000 -8.000000 5.000000 2 NUL D 8.000000 16.000000 -2.000000 14.000000 3 2000 3 30003000 S 2.000000 16.000000 0.000000 16.000000 3 3000 5 30005 D 2.000000 18.000000 -2.000000 16.000000 5 3000 5 40004000 S 2.000000 18.000000 0.000000 18.000000 5 4000 6 40005000 S 4.000000 22.000000 4.000000 18.000000 5 5000 6 50006000 S 3.000000 25.000000 7.000000 22.000000 5 6000 6 60006 D 8.000000 26.000000 -1.000000 25.000000 6 6000 6 70007000 S 2.000000 27.000000 1.000000 26.000000 6 7000 7 70007 D 4.000000 30.000000 -3.000000 27.000000 7 7000 7 NULL8 D 2.000000 32,000000 -5,000000 30,000000 8 7000 8 NULL
CTE C3 forespørger C2 og beregner resultatparringernes DemandID, SupplyID og TradeQuantity, før den fjerner nogle overflødige rækker.
Resultatet C3.DemandID-kolonnen beregnes således:
- Hvis den aktuelle post er en efterspørgselspost, returnerer DemandID.
- Hvis den aktuelle post er en forsyningspost, og det aktuelle lagerniveau er positivt, returneres NextDemandID.
- Hvis den aktuelle post er en forsyningspost, og det aktuelle lagerniveau er ikke-positivt, returneres PrevDemandID.
Resultatet C3.SupplyID-kolonnen beregnes således:
- Hvis den aktuelle post er en forsyningspost, skal du returnere SupplyID.
- Hvis den aktuelle post er en efterspørgselspost, og det aktuelle lagerniveau er ikke-positivt, returner NextSupplyID.
- Hvis den aktuelle post er en efterspørgselspost, og det aktuelle lagerniveau er positivt, returneres PrevSupplyID.
Resultatet TradeQuantity beregnes som den aktuelle rækkes SumQty minus PrevSumQty.
Her er indholdet af de kolonner, der er relevante for resultatet fra C3:
DemandID SupplyID TradeQuantity----------------------------------------------1 1000 5,0000002 1000 3,0000002 1000 0,0000003 2000 6.0000003 3000 2.0000003 3000 0.0000005 4000 2.0000005 4000 0.0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 NULL 3.0000008 NULL 2.000000
Det, der er tilbage til den ydre forespørgsel, er at filtrere overflødige rækker fra C3. Disse omfatter to tilfælde:
- Når de løbende totaler af begge typer er ens, har forsyningsposten en handelsmængde på nul. Husk at bestillingen er baseret på SumQty og Code, så når de løbende totaler er de samme, vises efterspørgselsposten før udbudsposten.
- Efterfølgende poster af én art, der ikke kan matches med poster af den anden type. Sådanne poster er repræsenteret af rækker i C3, hvor enten DemandID er NULL eller SupplyID er NULL.
Planen for denne løsning er vist i figur 2.
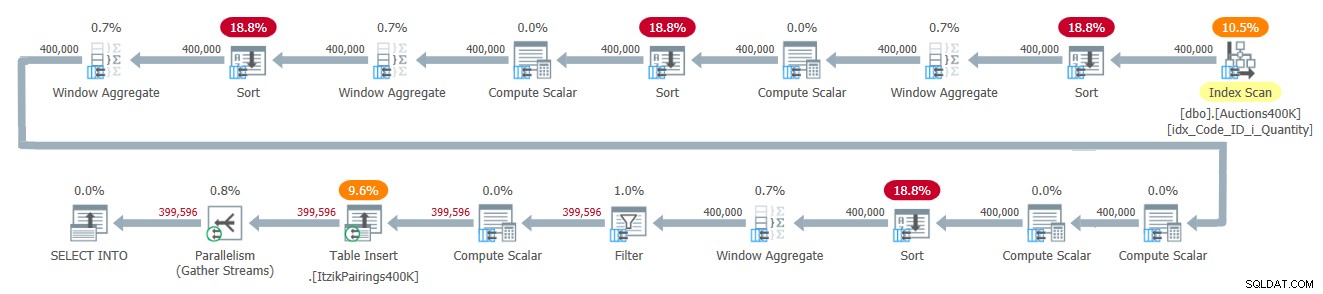 Figur 2:Forespørgselsplan for Itziks løsning
Figur 2:Forespørgselsplan for Itziks løsning
Planen anvender én gang over inputdataene og bruger fire batch-mode Window Aggregate-operatorer til at håndtere de forskellige vinduesberegninger. Alle Window Aggregate-operatorer er forudgået af eksplicitte sorteringsoperatorer, selvom kun to af dem er uundgåelige her. De to andre har at gøre med den nuværende implementering af den parallelle batch-mode Window Aggregate-operatør, som ikke kan stole på en parallel ordrebevarende input. En enkel måde at se, hvilke sorteringsoperatører er på grund af denne grund, er at gennemtvinge en seriel plan og se, hvilke sorteringsoperatører der forsvinder. Når jeg tvinger en seriel plan med denne løsning, forsvinder den første og tredje sorteringsoperator.
Her er de køretider i sekunder, jeg fik for denne løsning:
100K:0,246200K:0,427300K:0,616400K:0,841>
Ians løsning
Ians løsning er kort og effektiv. Her er den komplette løsningskode:
SLIP TABEL HVIS FINDER #MyPairings; MED A AS ( VÆLG *, SUM(Mængde) OVER (OPDELING EFTER KODE ORDRE EFTER ID RÆKKER UBEGRÆNSET FOREGÅENDE) SOM Kumulativ Kvantitet FRA dbo.Auctions), B AS ( VÆLG Kumulativ Kvantitet, Kumulativ Kvantitet - LAG( Kumulativ Kvantitet, OVER1, ORDER 0) BY CumulativeQuantity) AS TradeQuantity, MAX(CASE NÅR Kode ='D' THEN ID END) AS DemandID, MAX(CASE WHEN Code ='S' THEN ID END) AS SupplyID FROM A GROUP BY CumulativeQuantity, ID/ID -- falsk gruppering for at forbedre rækkeestimat -- (rækkeantal af auktioner i stedet for 2 rækker)), C AS ( -- udfyld NULLs med næste udbud/efterspørgsel -- FIRST_VALUE(ID) IGNORER NULLER OVER ... -- ville være bedre, men dette vil fungere, fordi ID'erne er i CumulativeQuantity rækkefølge VÆLG MIN(DemandID) OVER (ORDER BY CumulativeQuantity RÆKKER MELLEM AKTUELLE RÆKKE OG UBEGRÆNSET FØLGENDE) SOM DemandID, MIN(SupplyID) OVER (ORDER BY CumulativeQ mængde RÆKKER MELLEM AKTUELLE RÆKKE OG UBEGRÆNSET FØLGENDE) SOM SupplyID, TradeQuantity FRA B)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM CWHERE SupplyID IS NOT NULL -- trim uopfyldte krav OG DemandID ER IKKE NULL; -- trim ubrugte forbrugsvarer
Koden i CTE A forespørger i auktionstabellen og beregner løbende samlede efterspørgsels- og udbudsmængder ved hjælp af en vinduesfunktion, der navngiver resultatkolonnen CumulativeQuantity.
Koden i CTE B forespørger CTE A og grupperer rækkerne efter CumulativeQuantity. Denne gruppering opnår en lignende effekt som Brians ydre sammenføjning baseret på efterspørgsel og udbud løbende totaler. Ian tilføjede også dummy-udtrykket ID/ID til grupperingssættet for at forbedre grupperingens oprindelige kardinalitet under estimering. På min maskine resulterede dette også i, at jeg brugte en parallel plan i stedet for en seriel.
I SELECT-listen beregner koden DemandID og SupplyID ved at hente ID'et for den respektive indgangstype i gruppen ved hjælp af MAX-aggregatet og et CASE-udtryk. Hvis ID'et ikke er til stede i gruppen, er resultatet NULL. Koden beregner også en resultatkolonne kaldet TradeQuantity som den aktuelle kumulative mængde minus den forrige, hentet ved hjælp af LAG-vinduefunktionen.
Her er indholdet af B:
Koden i CTE C'en forespørger derefter CTE B'en og udfylder NULL efterspørgsels- og forsynings-id'er med de næste ikke-NULL efterspørgsels- og forsynings-id'er, ved hjælp af MIN-vinduefunktionen med rammen RÆKKER MELLEM AKTUEL RÆKKE OG UBEGRÆNSET FØLGENDE.
Her er indholdet af C:
DemandID SupplyID TradeQuantity ---------- ---------- --------------1 1000 5,000000 2 1000 3,000000 3 2000 6,000000 3 3000 2,000000 5 4000 2,000000 6 5000 4,000000 6 6000 3,000000 6 7000 1,000000 7 7000 1,000000 7 NULL 3,000000 2 0 førDet sidste trin, der håndteres af den ydre forespørgsel mod C, er at fjerne poster af den ene slags, der ikke kan matches med indgange af den anden slags. Det gøres ved at bortfiltrere rækker, hvor enten SupplyID er NULL eller DemandID er NULL.
Planen for denne løsning er vist i figur 3.
Figur 3:Forespørgselsplan for Ians løsning
Denne plan udfører én scanning af inputdataene og bruger tre parallelle batch-mode vinduesaggregatoperatorer til at beregne de forskellige vinduesfunktioner, alle forudgået af parallelle sorteringsoperatorer. To af dem er uundgåelige, som du kan bekræfte ved at tvinge en seriel plan. Planen bruger også en Hash Aggregate-operatør til at håndtere grupperingen og aggregeringen i CTE B.
Her er de køretider i sekunder, jeg fik for denne løsning:
100K:0,214200K:0,363300K:0,546400K:0,701
Peter Larssons løsning
Peter Larssons løsning er fantastisk kort, sød og yderst effektiv. Her er Peters komplette løsningskode:
SLIP TABEL HVIS FINDER #MyPairings; WITH cteSource(ID, Code, RunningQuantity)AS( SELECT ID, Code, SUM(Quantity) OVER (PARTITION BY Code ORDER BY ID) AS RunningQuantity FRA dbo.Auctions)SELECT DemandID, SupplyID, TradeQuantityINTO #MyPairingsFROM (VÆLG MIN(CASE WHEN) Kode ='D' THEN ID ELSE 2147483648 END) OVER (ORDER BY RunningQuantity, Code RÆKKER MELLEM AKTUELLE RÆKKE OG UBEGRÆNSET FØLGENDE) SOM DemandID, MIN(CASE NÅR Kode ='S' SÅ ID ELSE 2147488ORning) Kode RÆKKER MELLEM NUVÆRENDE RÆKKE OG UBEGRÆNSET FØLGENDE) AS SupplyID, RunningQuantity - COALESCE(LAG(RunningQuantity) OVER (ORDER BY RunningQuantity, Code), 0.0) AS TradeQuantity FRA cteSource ) AS dWHERE DemandID 48 SupplyANDQuantity <41487 .41487 .47487 .47487 48. SupplyANDQuantity .CTE cteSource forespørger i auktionstabellen og bruger en vinduesfunktion til at beregne løbende samlede efterspørgsels- og udbudsmængder, kalder resultatkolonnen RunningQuantity.
Koden, der definerer den afledte tabel d, forespørger cteSource og beregner resultatparringernes DemandID, SupplyID og TradeQuantity, før nogle overflødige rækker fjernes. Alle vinduesfunktioner, der bruges i disse beregninger, er baseret på RunningQuantity og Code-bestilling.
Resultatkolonnen d.DemandID beregnes som minimumskrav-id begyndende med det aktuelle eller 2147483648, hvis der ikke findes nogen.
Resultatkolonnen d.SupplyID beregnes som minimumsforsynings-id begyndende med det aktuelle eller 2147483648, hvis ingen findes.
Resultatet TradeQuantity beregnes som den aktuelle rækkes RunningQuantity-værdi minus den forrige rækkes RunningQuantity-værdi.
Her er indholdet af d:
DemandID SupplyID TradeQuantity--------- ------------------ ---------------1 1000 5,0000002 1000 3,0000003 1000 0,0000003 2000 6,0000003 3000 2.0000005 3000 0,0000005 4000 2.0000006 4000 0,0000006 5000 4.0000006 6000 3.0000006 7000 1.0000007 7000 1.0000007 2147483648 3.0000008 2147483648 2.000000Det, der er tilbage til den ydre forespørgsel, er at filtrere overflødige rækker fra d. Det er tilfælde, hvor handelsmængden er nul, eller poster af én art, der ikke kan matches med poster fra den anden type (med ID 2147483648).
Planen for denne løsning er vist i figur 4.
Figur 4:Forespørgselsplan for Peters løsning
Ligesom Ians plan er Peters plan afhængig af én scanning af inputdataene og bruger tre parallelle batch-mode vinduesaggregatoperatorer til at beregne de forskellige vinduesfunktioner, alle forudgået af parallelle sorteringsoperatorer. To af dem er uundgåelige, som du kan bekræfte ved at tvinge en seriel plan. I Peters plan er der ikke behov for en grupperet aggregatoperatør som i Ians plan.
Peters kritiske indsigt, der muliggjorde en så kort løsning, var erkendelsen af, at for en relevant indtastning af en af slagsen, vil det matchende ID af den anden slags altid dukke op senere (baseret på RunningQuantity og Code-bestilling). Efter at have set Peters løsning, føltes det som om, jeg overkomplicerede tingene i mit!
Her er de køretider i sekunder, jeg fik for denne løsning:
100K:0,197200K:0,412300K:0,558400K:0,696
Paul Whites løsning
Vores sidste løsning blev skabt af Paul White. Her er den komplette løsningskode:
SLIP TABEL HVIS FINDER #MyPairings; OPRET TABEL #MyPairings( DemandID heltal IKKE NULL, SupplyID integer NOT NULL, TradeQuantity decimal(19, 6) NOT NULL);GO INSERT #MyPairings WITH (TABLOCK)( DemandID, SupplyID, TradeQuantity)SELECT Q3.DemandID, Q3.Supply Q3.TradeQuantityFROM ( SELECT Q2.DemandID, Q2.SupplyID, TradeQuantity =-- Interval overlap CASE WHEN Q2.Code ='S' SÅ CASE NÅR Q2.CumDemand>=Q2.IntEnd SÅ Q2.IntLength WHEN Q2.CumDemand> Q2.CumDemand> Q2.CumDemand> Q2.CumDemand>=Q2.IntEnd. IntStart THEN Q2.CumDemand - Q2.IntStart ELSE 0.0 END WHEN Q2.Code ='D' THEN CASE WHEN Q2.CumSupply>=Q2.IntEnd THEN Q2.IntLength WHEN Q2.CumSupply> Q2.IntStartCumn Q2.IntStart THEN. IntStart ELSE 0.0 SLUT SLUT FRA ( VÆLG Q1.Code, Q1.IntStart, Q1.IntEnd, Q1.IntLength, DemandID =MAX(IIF(Q1.Code ='D', Q1.ID, 0)) OVER ( BESTIL EFTER Q1.IntStart, Q1.ID RÆKKER UBEGRÆNSET PRECEDING), SupplyID =MAX(IIF(Q1.Code ='S', Q1.ID, 0)) OVER (ORDER BY Q1.IntStart, Q1.ID ROWS UNboundED PRECEDING), CumSupply =SUM(IIF(Q1.Code ='S', Q1.IntLength, 0)) OVER (ORDER BY Q1.IntStart, Q1.ID ROWS UNBOUNDED PRECEDING), CumDemand =SUM(IIF(Q1.Code ='D', Q1.IntLength, 0)) OVER ( BESTIL EFTER Q1.IntStart, Q1.ID RÆKKER UBEGRÆNSET FOREGÅENDE) FRA ( -- Efterspørgselsintervaller VÆLG A.ID, A.Code, IntStart =SUM(A.Mængde) OVER ( BESTIL EFTER A.ID RÆKKER UBEGRÆNSET FOREGÅENDE) - A. Antal, IntEnd =SUM(A.Quantity) OVER (ORDER BY A.ID ROWS UNBOUNDED PRECEDING), IntLength =A.Quantity FRA dbo.Auctions AS A WHERE A.Code ='D' UNION ALL -- Supply intervaller SELECT A.ID, A.Code, IntStart =SUM(A.Quantity) OVER (ORDER BY A.ID ROWS UNBOUNDED PRECEDING) - A.Quantity, IntEnd =SUM(A.Quantity) OVER (ORDER BY A.ID ROWS UNBOUNDED PRECEDING), IntLength =A.Mængde FRA dbo.Auktioner AS A WHERE A.Code ='S' ) AS Q1 ) AS Q2) AS Q3WHERE Q3.TradeQuantity> 0;Koden, der definerer den afledte tabel Q1, bruger to separate forespørgsler til at beregne efterspørgsels- og udbudsintervaller baseret på løbende totaler og forener de to. For hvert interval beregner koden dets start (IntStart), slut (IntEnd) og længde (IntLength). Her er indholdet af Q1 sorteret efter IntStart og ID:
ID-kode IntStart IntEnd IntLength----- ---- ---------- ---------- ----------1 D 0,000000 5.000000 5.0000001000 S 0.000000 8.000000 8.0000002 D 5.000000 8.000000 3.0000003 D 8.000000 16.000000 8.0000002000 S 8.000000 14.000000 6.0000003000 S 14.000000 16.000000 2.0000005 D 16.000000 18.000000 2.0000004000 S 16.000000 18.000000 2.0000006 D 18.000000 26.000000 8.0000005000 S 18.000000 22.000000 4.0000006000 S 22.000000 25.000000 3.0000007000 S 25.000000 27.000000 2.0000007 D 26.000000 30.000000 4.0000008 D 30,000000 32,000000 2,000000Koden, der definerer den afledte tabel Q2, forespørger Q1 og beregner resultatkolonner kaldet DemandID, SupplyID, CumSupply og CumDemand. Alle vinduesfunktioner, der bruges af denne kode, er baseret på IntStart- og ID-bestilling og rammen RÆKKER UBEGRÆNSET FOREGÅENDE (alle rækker op til den nuværende).
DemandID er det maksimale efterspørgsels-id op til den aktuelle række, eller 0, hvis ingen findes.
SupplyID er det maksimale forsynings-ID op til den aktuelle række, eller 0, hvis ingen findes.
CumSupply er de kumulative forsyningsmængder (forsyningsintervallængder) op til den aktuelle række.
CumDemand er de kumulative efterspørgselsmængder (efterspørgselsintervallængder) op til den aktuelle række.
Her er indholdet af Q2:
Kode IntStart IntEnd IntLength DemandID SupplyID CumSupply CumDemand---- ---------- ---------- ---------- ----- ---- ---------- ---------- ----------D 0,000000 5,000000 5,000000 1 0 0,000000 5,000000S 0,000000 8,000000 8,000000 1 1000 00,05 D 5.000000 8.000000 3.000000 2 1000 8.000000 8.000000D 8.000000 16.000000 8.000000 3 1000 8.000000 16.000000S 8.000000 14.000000 6.000000 3 2000 14.000000 16.000000S 14.000000 16.000000 2.000000 3 3000 16.000000 16.000000D 16.000000 18.000000 2.000000 5 3000 16.000000 18.000000S 16.000000 18.000000 2.000000 5 4000 18.000000 18.000000D 18.000000 26.000000 8,000000 6 4000 18,000000 26,000000S 18,000000 22,000000 4,000000 6 5000 22,000000 26,000000S 02,000000S 000 00 00 00 00 00 000 25.000000 26.000000S 25.000000 27.000000 2.000000 6 7000 27.000000 26.000000d 26.000000 30.000000 4Q2 already has the final result pairings’ correct DemandID and SupplyID values. The code defining the derived table Q3 queries Q2 and computes the result pairings’ TradeQuantity values as the overlapping segments of the demand and supply intervals. Finally, the outer query against Q3 filters only the relevant pairings where TradeQuantity is positive.
The plan for this solution is shown in Figure 5.
Figure 5:Query plan for Paul’s solution
The top two branches of the plan are responsible for computing the demand and supply intervals. Both rely on Index Seek operators to get the relevant rows based on index order, and then use parallel batch-mode Window Aggregate operators, preceded by Sort operators that theoretically could have been avoided. The plan concatenates the two inputs, sorts the rows by IntStart and ID to support the subsequent remaining Window Aggregate operator. Only this Sort operator is unavoidable in this plan. The rest of the plan handles the needed scalar computations and the final filter. That’s a very efficient plan!
Here are the run times in seconds I got for this solution:
100K:0.187200K:0.331300K:0.369400K:0.425These numbers are pretty impressive!
Performance Comparison
Figure 6 has a performance comparison between all solutions covered in this article.
Figure 6:Performance comparison
At this point, we can add the fastest solutions I covered in previous articles. Those are Joe’s and Kamil/Luca/Daniel’s solutions. The complete comparison is shown in Figure 7.
Figure 7:Performance comparison including earlier solutions
These are all impressively fast solutions, with the fastest being Paul’s and Peter’s.
Konklusion
When I originally introduced Peter’s puzzle, I showed a straightforward cursor-based solution that took 11.81 seconds to complete against a 400K-row input. The challenge was to come up with an efficient set-based solution. It’s so inspiring to see all the solutions people sent. I always learn so much from such puzzles both from my own attempts and by analyzing others’ solutions. It’s impressive to see several sub-second solutions, with Paul’s being less than half a second!
It's great to have multiple efficient techniques to handle such a classic need of matching supply with demand. Well done everyone!
[ Jump to:Original challenge | Solutions:Part 1 | Part 2 | Part 3 ]