I denne artikel fortsætter jeg dækningen af løsninger på Peter Larssons lokkende matchende udbud med efterspørgsel udfordring. Tak igen til Luca, Kamil Kosno, Daniel Brown, Brian Walker, Joe Obbish, Rainer Hoffmann, Paul White, Charlie og Peter Larsson for at sende jeres løsninger.
I sidste måned dækkede jeg en løsning baseret på interval skæringspunkter ved hjælp af en klassisk prædikatbaseret interval skæringstest. Jeg vil referere til den løsning som klassiske kryds . Den klassiske intervalskæringstilgang resulterer i en plan med kvadratisk skalering (N^2). Jeg demonstrerede dens dårlige ydeevne mod prøveinput, der spænder fra 100K til 400K rækker. Det tog løsningen 931 sekunder at fuldføre mod 400K-rækkens input! Denne måned vil jeg starte med kort at minde dig om sidste måneds løsning, og hvorfor den skalerer og yder så dårligt. Jeg vil derefter introducere en tilgang baseret på en revision af intervalskæringstesten. Denne tilgang blev brugt af Luca, Kamil og muligvis også Daniel, og den muliggør en løsning med meget bedre ydeevne og skalering. Jeg vil referere til den løsning som reviderede vejkryds .
Problemet med den klassiske intersektionstest
Lad os starte med en hurtig påmindelse om sidste måneds løsning.
Jeg brugte følgende indekser på input dbo.Auktionstabellen til at understøtte beregningen af de løbende totaler, der producerer efterspørgsels- og udbudsintervallerne:
-- Index to support solution CREATE UNIQUE NONCLUSTERED INDEX idx_Code_ID_i_Quantity ON dbo.Auctions(Code, ID) INCLUDE(Quantity); -- Enable batch-mode Window Aggregate CREATE NONCLUSTERED COLUMNSTORE INDEX idx_cs ON dbo.Auctions(ID) WHERE ID = -1 AND ID = -2;
Følgende kode har den komplette løsning, der implementerer den klassiske intervalskæringstilgang:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
CREATE UNIQUE CLUSTERED INDEX idx_cl_ES_ID ON #Supply(EndSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S WITH (FORCESEEK)
ON D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply; Denne kode starter med at beregne efterspørgsels- og udbudsintervallerne og skrive dem til midlertidige tabeller kaldet #Demand og #Supply. Koden opretter derefter et klynget indeks på #Supply med EndSupply som den førende nøgle for at understøtte skæringstesten bedst muligt. Endelig forbinder koden #Supply og #Demand, der identificerer handler som de overlappende segmenter af de skærende intervaller, ved hjælp af følgende joinprædikat baseret på den klassiske intervalskæringstest:
D.StartDemand < S.EndSupply AND D.EndDemand > S.StartSupply
Planen for denne løsning er vist i figur 1.
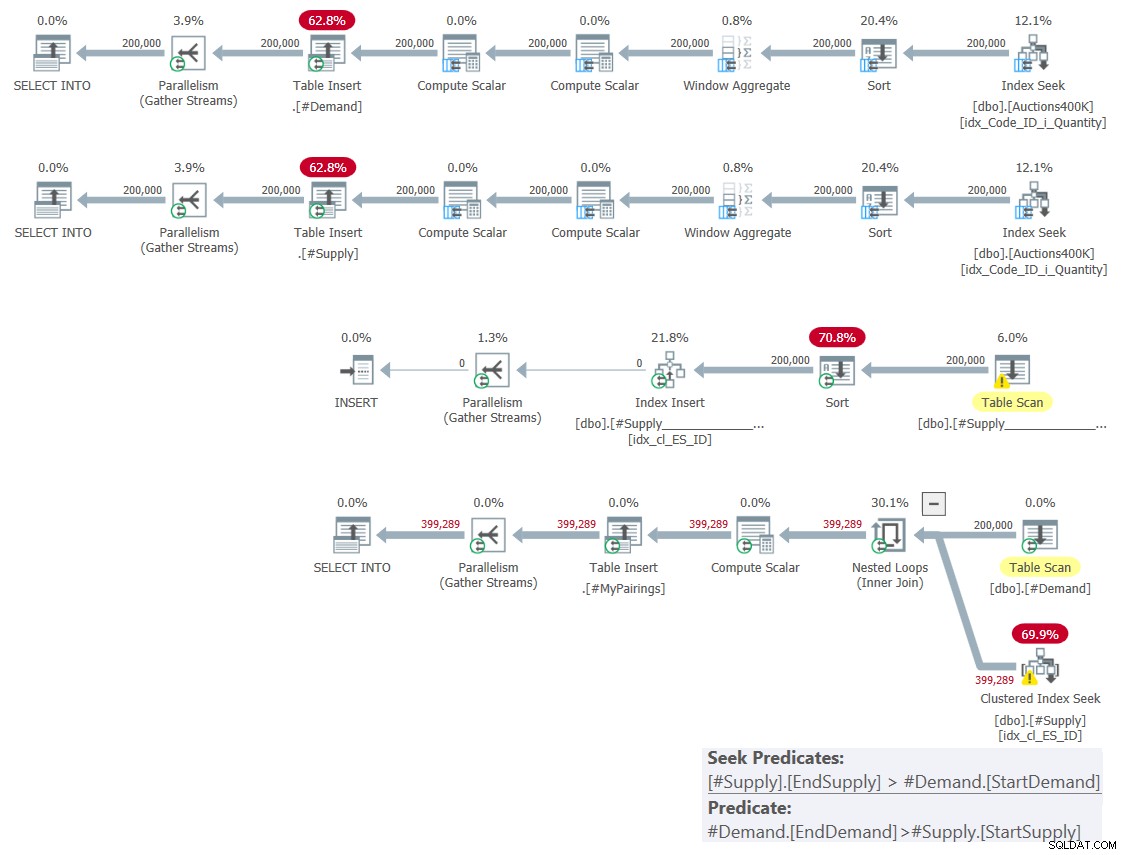 Figur 1:Forespørgselsplan for løsning baseret på klassiske kryds
Figur 1:Forespørgselsplan for løsning baseret på klassiske kryds
Som jeg forklarede i sidste måned, blandt de to involverede områdeprædikater kan kun det ene bruges som et søgeprædikat som en del af en indekssøgningsoperation, hvorimod det andet skal anvendes som et resterende prædikat. Det kan du tydeligt se i planen for den sidste forespørgsel i figur 1. Derfor gad jeg kun lave ét indeks på en af tabellerne. Jeg tvang også brugen af en søgning i det indeks, jeg oprettede ved hjælp af FORCESEEK-tippet. Ellers kan optimeringsværktøjet ende med at ignorere det indeks og oprette et af dets eget ved hjælp af en Index Spool-operator.
Denne plan har kvadratisk kompleksitet, da pr. række i den ene side—#Demand i vores tilfælde—indekssøgningen i gennemsnit skal have adgang til halvdelen af rækkerne i den anden side—#Udbud i vores tilfælde—baseret på søgeprædikatet, og identificere sidste kampe ved at anvende det resterende prædikat.
Hvis det stadig er uklart for dig, hvorfor denne plan har kvadratisk kompleksitet, kunne en visuel afbildning af arbejdet måske hjælpe, som vist i figur 2.
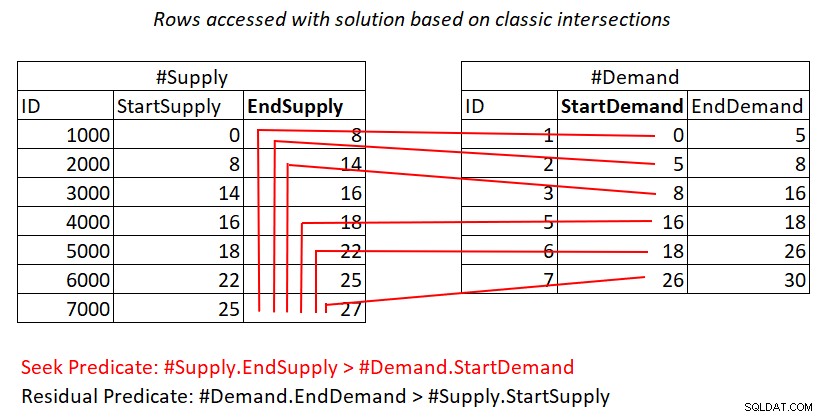 Figur 2:Illustration af arbejde med løsning baseret på klassiske skæringspunkter
Figur 2:Illustration af arbejde med løsning baseret på klassiske skæringspunkter
Denne illustration repræsenterer det arbejde, der er udført af de indlejrede løkker i planen for den sidste forespørgsel. #Demand-heapen er det ydre input af joinforbindelsen, og det klyngede indeks på #Supply (med EndSupply som den førende nøgle) er det indre input. De røde linjer repræsenterer indekssøgningsaktiviteterne udført pr. række i #Demand i indekset på #Supply og de rækker, de får adgang til som en del af rækkeviddescanningerne i indeksbladet. I retning af ekstremt lave StartDemand-værdier i #Demand skal rækkeviddescanningen have adgang tæt på alle rækker i #Supply. Mod ekstremt høje StartDemand-værdier i #Demand skal rækkeviddescanningen have adgang til tæt på nul rækker i #Supply. I gennemsnit skal rækkeviddescanningen have adgang til omkring halvdelen af rækkerne i #Forsyning pr. efterspurgt række. Med D-efterspørgselsrækker og S-forsyningsrækker er antallet af rækker, der tilgås, D + D*S/2. Det er ud over omkostningerne ved de søgninger, der bringer dig til de matchende rækker. For eksempel, når du udfylder dbo.Auktioner med 200.000 efterspørgselsrækker og 200.000 forsyningsrækker, oversættes dette til, at Nested Loops-sammenføjningen får adgang til 200.000 efterspørgselsrækker + 200.000*200.000/2 forsyningsrækker, eller 200,000,0,0,0,0,0,0,0,0,0,0,0,0,0,0,20 Der sker en masse genscanning af forsyningsrækker her!
Hvis du vil holde fast i ideen om intervalkryds, men opnå god ydeevne, skal du finde på en måde at reducere mængden af udført arbejde på.
I sin løsning bucketed Joe Obbish intervallerne baseret på den maksimale intervallængde. På denne måde var han i stand til at reducere antallet af rækker, de sammenføjninger var nødvendige for at håndtere og stole på batchbehandling. Han brugte den klassiske intervalskæringstest som et sidste filter. Joes løsning fungerer godt, så længe den maksimale intervallængde ikke er særlig høj, men løsningens køretid øges, når den maksimale intervallængde øges.
Så hvad kan du ellers gøre...?
Revideret skæringstest
Luca, Kamil og muligvis Daniel (der var en uklar del om hans postede løsning på grund af hjemmesidens formatering, så jeg var nødt til at gætte) brugte en revideret interval skæringstest, der muliggør meget bedre udnyttelse af indeksering.
Deres skæringstest er en adskillelse af to prædikater (prædikater adskilt af OR-operator):
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply >= D.StartDemand AND S.StartSupply < D.EndDemand)
På engelsk skærer efterspørgselsstartafgrænseren enten udbudsintervallet på en inkluderende, eksklusiv måde (inklusive starten og ekskluderet slutningen); eller udbudsstartafgrænseren skærer efterspørgselsintervallet på en inkluderende, eksklusiv måde. For at gøre de to prædikater usammenhængende (ikke have overlappende tilfælde), men alligevel fuldstændige i at dække alle tilfælde, kan du beholde =-operatoren i kun den ene eller den anden, for eksempel:
(D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand)
Denne reviderede intervalskæringstest er ret indsigtsfuld. Hvert af prædikaterne kan potentielt effektivt bruge et indeks. Overvej prædikat 1:
D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
Forudsat at du opretter et dækkende indeks på #Demand med StartDemand som den ledende nøgle, kan du potentielt få en Nested Loops join ved at anvende arbejdet illustreret i figur 3.
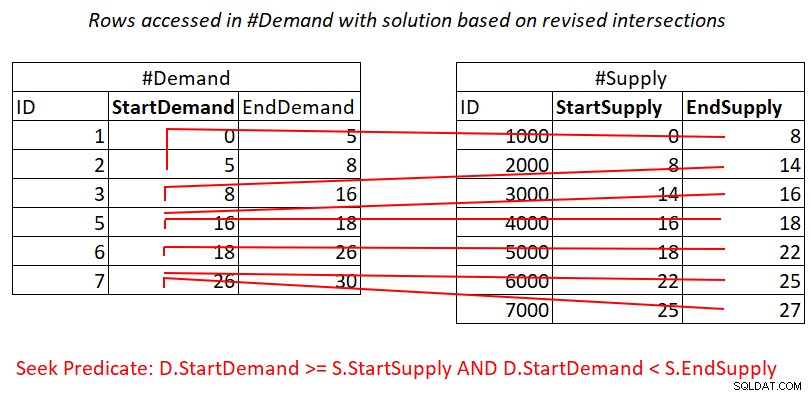
Figur 3:Illustration af teoretisk arbejde, der kræves for at behandle prædikatet 1
Ja, du betaler stadig for en søgning i #Demand-indekset pr. række i #Supply, men intervallet scanner i indeksbladet adgang til næsten usammenhængende undersæt af rækker. Ingen genscanning af rækker!
Situationen er den samme med prædikat 2:
S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand ^^^^^^^^^^^^^ ^^^^^^^^^^^^^
Hvis du antager, at du opretter et dækkende indeks på #Supply med StartSupply som den førende nøgle, kan du potentielt få en Nested Loops-sammenføjning ved at anvende arbejdet illustreret i figur 4.
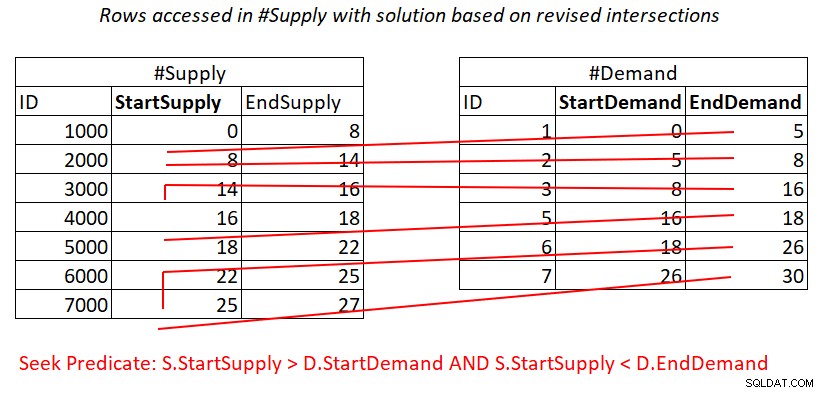
Figur 4:Illustration af teoretisk arbejde, der kræves for at behandle prædikatet 2
Her betaler du også for en søgning i #Udbudsindekset pr. række i #Demand, og derefter scanner intervallet i indeksbladet næsten usammenhængende delmængder af rækker. Igen, ingen genscanning af rækker!
Forudsat D efterspørgselsrækker og S forsyningsrækker, kan arbejdet beskrives som:
Number of index seek operations: D + S Number of rows accessed: 2D + 2S
Så sandsynligvis er den største del af omkostningerne her de I/O-omkostninger, der er forbundet med søgningerne. Men denne del af arbejdet har lineær skalering sammenlignet med den kvadratiske skalering af den klassiske intervalskæringsforespørgsel.
Selvfølgelig skal du overveje de foreløbige omkostninger ved indeksoprettelsen på de midlertidige tabeller, som har n log n skalering på grund af den involverede sortering, men du betaler denne del som en foreløbig del af begge løsninger.
Lad os prøve at omsætte denne teori i praksis. Lad os starte med at udfylde de midlertidige #Demand og #supply-tabeller med efterspørgsels- og udbudsintervallerne (samme som med de klassiske intervalskæringer) og oprette de understøttende indekser:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID); Planerne for at udfylde de midlertidige tabeller og oprette indekserne er vist i figur 5.
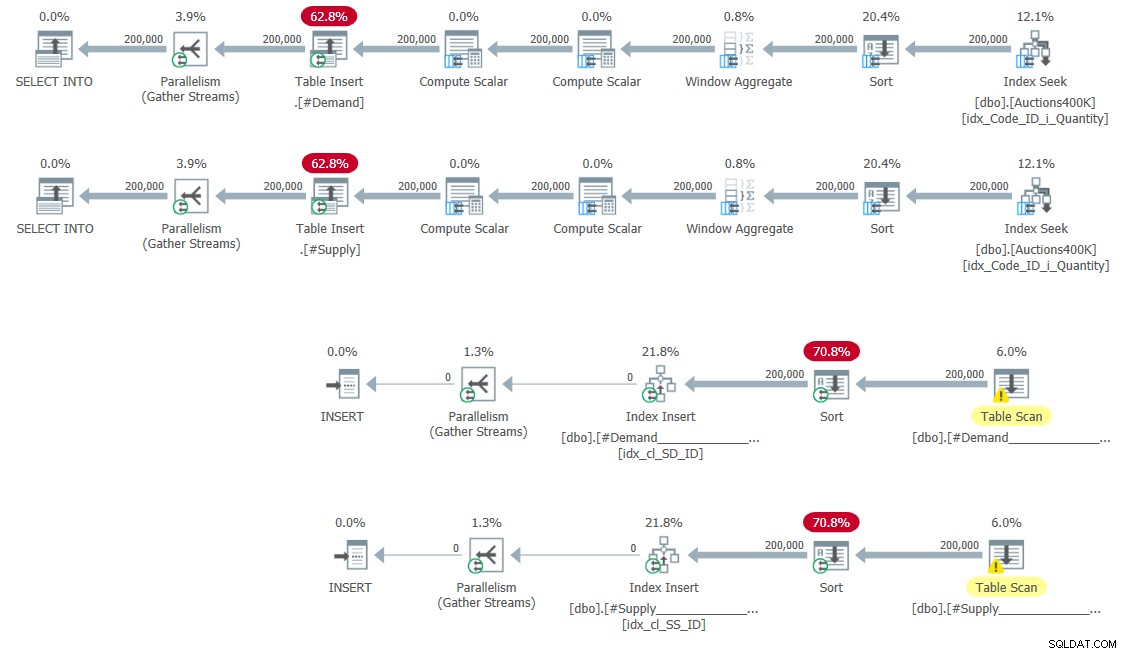
Figur 5:Forespørgselsplaner til udfyldning af midlertidige tabeller og oprettelse af indekser
Ingen overraskelser her.
Nu til den sidste forespørgsel. Du kan blive fristet til at bruge en enkelt forespørgsel med den førnævnte adskillelse af to prædikater, som sådan:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON (D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply) OR (S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand); Planen for denne forespørgsel er vist i figur 6.
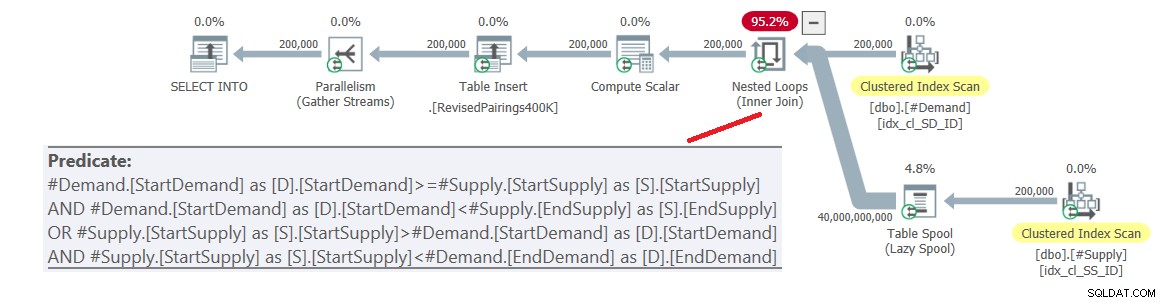
Figur 6:Forespørgselsplan for endelig forespørgsel ved hjælp af revideret kryds test, prøv 1
Problemet er, at optimeringsværktøjet ikke ved, hvordan man deler denne logik op i to separate aktiviteter, der hver håndterer et andet prædikat og udnytter det respektive indeks effektivt. Så det ender med et fuldt kartesisk produkt af de to sider, der anvender alle prædikater som resterende prædikater. Med 200.000 efterspørgselsrækker og 200.000 forsyningsrækker behandler joinforbindelsen 40.000.000.000 rækker.
Det indsigtsfulde trick, som Luca, Kamil og muligvis Daniel brugte, var at opdele logikken i to forespørgsler, der forenede deres resultater. Det er her, at det bliver vigtigt at bruge to usammenhængende prædikater! Du kan bruge en UNION ALL-operatør i stedet for UNION, så du undgår de unødvendige omkostninger ved at lede efter dubletter. Her er forespørgslen, der implementerer denne tilgang:
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; Planen for denne forespørgsel er vist i figur 7.
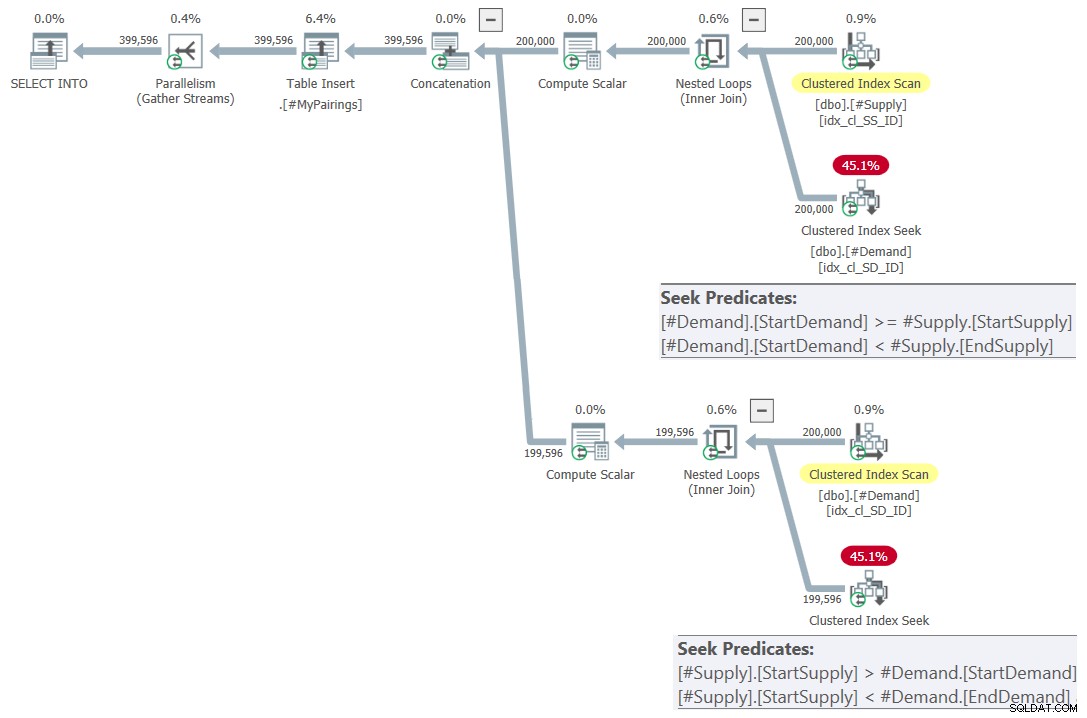
Figur 7:Forespørgselsplan for endelig forespørgsel ved hjælp af revideret kryds test, prøv 2
Det her er bare smukt! er det ikke? Og fordi det er så smukt, er her hele løsningen fra bunden, inklusive oprettelse af midlertidige tabeller, indeksering og den endelige forespørgsel:
-- Drop temp tables if exist
SET NOCOUNT ON;
DROP TABLE IF EXISTS #MyPairings, #Demand, #Supply;
GO
WITH D0 AS
-- D0 computes running demand as EndDemand
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndDemand
FROM dbo.Auctions
WHERE Code = 'D'
),
-- D extracts prev EndDemand as StartDemand, expressing start-end demand as an interval
D AS
(
SELECT ID, Quantity, EndDemand - Quantity AS StartDemand, EndDemand
FROM D0
)
SELECT ID,
CAST(ISNULL(StartDemand, 0.0) AS DECIMAL(19, 6)) AS StartDemand,
CAST(ISNULL(EndDemand, 0.0) AS DECIMAL(19, 6)) AS EndDemand
INTO #Demand
FROM D;
WITH S0 AS
-- S0 computes running supply as EndSupply
(
SELECT ID, Quantity,
SUM(Quantity) OVER(ORDER BY ID ROWS UNBOUNDED PRECEDING) AS EndSupply
FROM dbo.Auctions
WHERE Code = 'S'
),
-- S extracts prev EndSupply as StartSupply, expressing start-end supply as an interval
S AS
(
SELECT ID, Quantity, EndSupply - Quantity AS StartSupply, EndSupply
FROM S0
)
SELECT ID,
CAST(ISNULL(StartSupply, 0.0) AS DECIMAL(19, 6)) AS StartSupply,
CAST(ISNULL(EndSupply, 0.0) AS DECIMAL(19, 6)) AS EndSupply
INTO #Supply
FROM S;
-- Indexing
CREATE UNIQUE CLUSTERED INDEX idx_cl_SD_ID ON #Demand(StartDemand, ID);
CREATE UNIQUE CLUSTERED INDEX idx_cl_SS_ID ON #Supply(StartSupply, ID);
-- Trades are the overlapping segments of the intersecting intervals
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
INTO #MyPairings
FROM #Demand AS D
INNER JOIN #Supply AS S
ON D.StartDemand >= S.StartSupply AND D.StartDemand < S.EndSupply
UNION ALL
SELECT
D.ID AS DemandID, S.ID AS SupplyID,
CASE WHEN EndDemand < EndSupply THEN EndDemand ELSE EndSupply END - CASE WHEN StartDemand > StartSupply THEN StartDemand ELSE StartSupply END
AS TradeQuantity
FROM #Demand AS D
INNER JOIN #Supply AS S
ON S.StartSupply > D.StartDemand AND S.StartSupply < D.EndDemand; Som tidligere nævnt vil jeg referere til denne løsning som reviderede vejkryds .
Kamils løsning
Mellem Lucas, Kamils og Daniels løsninger var Kamils hurtigste. Her er Kamils komplette løsning:
SET NOCOUNT ON;
DROP TABLE IF EXISTS #supply, #demand;
GO
CREATE TABLE #demand
(
DemandID INT NOT NULL,
DemandQuantity DECIMAL(19, 6) NOT NULL,
QuantityFromDemand DECIMAL(19, 6) NOT NULL,
QuantityToDemand DECIMAL(19, 6) NOT NULL
);
CREATE TABLE #supply
(
SupplyID INT NOT NULL,
QuantityFromSupply DECIMAL(19, 6) NOT NULL,
QuantityToSupply DECIMAL(19,6) NOT NULL
);
WITH demand AS
(
SELECT
a.ID AS DemandID,
a.Quantity AS DemandQuantity,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromDemand,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToDemand
FROM dbo.Auctions AS a WHERE Code = 'D'
)
INSERT INTO #demand
(
DemandID,
DemandQuantity,
QuantityFromDemand,
QuantityToDemand
)
SELECT
d.DemandID,
d.DemandQuantity,
d.QuantityFromDemand,
d.QuantityToDemand
FROM demand AS d;
WITH supply AS
(
SELECT
a.ID AS SupplyID,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
- a.Quantity AS QuantityFromSupply,
SUM(a.Quantity) OVER(ORDER BY ID ROWS BETWEEN UNBOUNDED PRECEDING AND CURRENT ROW)
AS QuantityToSupply
FROM dbo.Auctions AS a WHERE Code = 'S'
)
INSERT INTO #supply
(
SupplyID,
QuantityFromSupply,
QuantityToSupply
)
SELECT
s.SupplyID,
s.QuantityFromSupply,
s.QuantityToSupply
FROM supply AS s;
CREATE UNIQUE INDEX ix_1 ON #demand(QuantityFromDemand)
INCLUDE(DemandID, DemandQuantity, QuantityToDemand);
CREATE UNIQUE INDEX ix_1 ON #supply(QuantityFromSupply)
INCLUDE(SupplyID, QuantityToSupply);
CREATE NONCLUSTERED COLUMNSTORE INDEX nci ON #demand(DemandID)
WHERE DemandID is null;
DROP TABLE IF EXISTS #myPairings;
CREATE TABLE #myPairings
(
DemandID INT NOT NULL,
SupplyID INT NOT NULL,
TradeQuantity DECIMAL(19, 6) NOT NULL
);
INSERT INTO #myPairings(DemandID, SupplyID, TradeQuantity)
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 end
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #demand AS d
INNER JOIN #supply AS s
ON (d.QuantityFromDemand < s.QuantityToSupply
AND s.QuantityFromSupply <= d.QuantityFromDemand)
UNION ALL
SELECT
d.DemandID,
s.SupplyID,
d.DemandQuantity
- CASE WHEN d.QuantityFromDemand < s.QuantityFromSupply
THEN s.QuantityFromSupply - d.QuantityFromDemand ELSE 0 END
- CASE WHEN s.QuantityToSupply < d.QuantityToDemand
THEN d.QuantityToDemand - s.QuantityToSupply ELSE 0 END AS TradeQuantity
FROM #supply AS s
INNER JOIN #demand AS d
ON (s.QuantityFromSupply < d.QuantityToDemand
AND d.QuantityFromDemand < s.QuantityFromSupply); Som du kan se, er det meget tæt på den reviderede vejkrydsløsning, jeg dækkede.
Planen for den endelige forespørgsel i Kamils løsning er vist i figur 8.
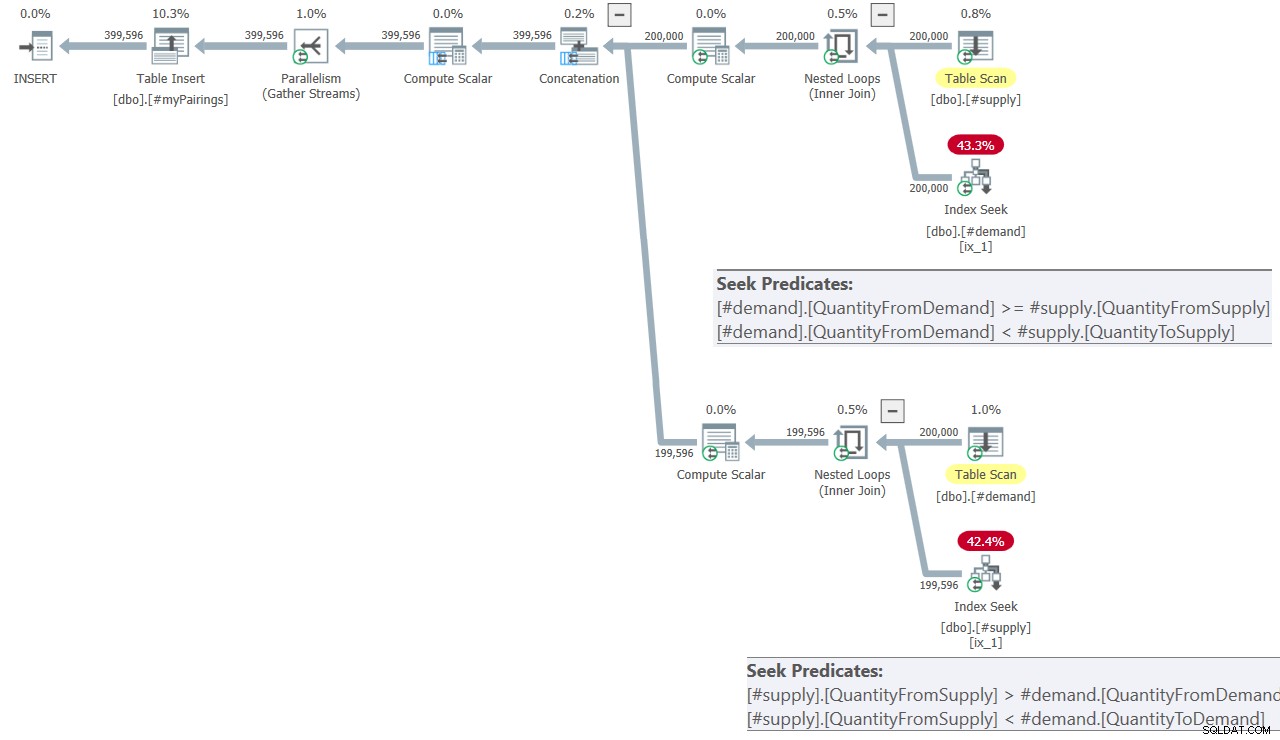
Figur 8:Forespørgselsplan for endelig forespørgsel i Kamils løsning
Planen ligner ret meget den, der er vist tidligere i figur 7.
Ydeevnetest
Husk, at den klassiske vejkryds-løsning tog 931 sekunder at fuldføre mod et input med 400K rækker. Det er 15 minutter! Det er meget, meget værre end markørløsningen, som tog omkring 12 sekunder at fuldføre mod det samme input. Figur 9 har ydelsestallene inklusive de nye løsninger, der er diskuteret i denne artikel.
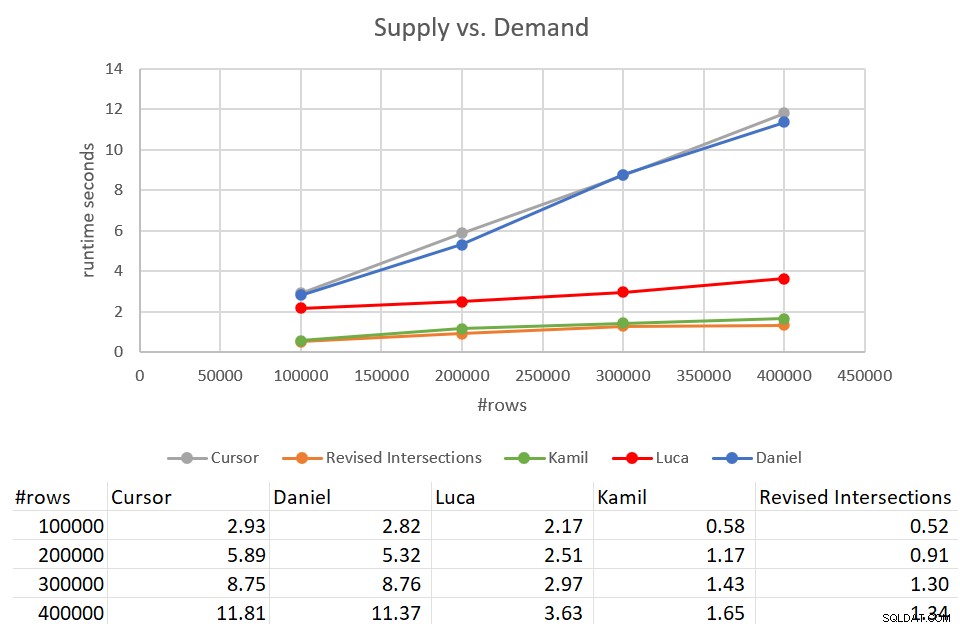
Figur 9:Ydelsestest
Som du kan se, tog Kamils løsning og den lignende reviderede vejkrydsløsning omkring 1,5 sekunder at fuldføre mod input fra 400K-rækkerne. Det er en ret anstændig forbedring sammenlignet med den originale markørbaserede løsning. Den største ulempe ved disse løsninger er I/O-omkostningerne. Med et søgning pr. række, for et input på 400.000 rækker, udfører disse løsninger et overskud på 1,35 millioner aflæsninger. Men det kunne også betragtes som en helt acceptabel pris i betragtning af den gode køretid og skalering, du får.
Hvad er det næste?
Vores første forsøg på at løse den matchende udbud versus efterspørgsel-udfordring var baseret på den klassiske interval skæringstest og fik en dårligt ydende plan med kvadratisk skalering. Meget værre end den markørbaserede løsning. Baseret på indsigt fra Luca, Kamil og Daniel, ved hjælp af en revideret intervalskæringstest, var vores andet forsøg en væsentlig forbedring, der udnytter indeksering effektivt og yder bedre end den markørbaserede løsning. Denne løsning indebærer dog en betydelig I/O-omkostning. Næste måned fortsætter jeg med at udforske yderligere løsninger.
[ Hop til:Original udfordring | Løsninger:Del 1 | Del 2 | del 3]