Udgivelsestest er typisk et af trinene i hele implementeringsprocessen. Du skriver koden, og derefter verificerer du, hvordan den opfører sig i et iscenesættelsesmiljø, og til sidst implementerer du den nye kode på produktionen. Databaser er interne i enhver form for applikation, og derfor er det vigtigt at verificere, hvordan de databaserelaterede ændringer ændrer applikationen. Det er muligt at verificere det på et par måder; en af dem ville være at bruge en dedikeret replika. Lad os tage et kig på, hvordan det kan gøres.
Selvfølgelig ønsker du ikke, at denne proces skal være manuel - den bør være en del af din virksomheds CI/CD-processer. Afhængigt af det nøjagtige program, miljø og processer, du har på plads, kan du bruge ad hoc-replikaer eller replikaer, der altid er en del af databasemiljøet.
Måden Galera Cluster fungerer på er, at den håndterer skemaændringer på en bestemt måde. Det er muligt at udføre en skemaændring på en enkelt node i klyngen, men det er vanskeligt, da det ikke understøtter alle mulige skemaændringer, og det vil påvirke produktionen, hvis noget går galt. En sådan node ville skulle genopbygges fuldstændigt ved hjælp af SST, hvilket betyder, at en af de resterende Galera-knuder skal fungere som donor og overføre alle sine data over netværket.
Et alternativ vil være at bruge en replika eller endda en hel ekstra Galera Cluster, der fungerer som en replika. Det er klart, at processen skal automatiseres for at tilslutte den til udviklingspipelinen. Der er mange måder at gøre dette på:scripts eller adskillige infrastruktur-orkestreringsværktøjer som Ansible, Chef, Puppet eller Salt stack. Vi vil ikke beskrive dem i detaljer, men vi vil gerne have dig til at vise de nødvendige trin for at hele processen fungerer korrekt, og vi overlader implementeringen i et af værktøjerne til dig.
Automatisk udgivelsestest
Først og fremmest ønsker vi at være i stand til nemt at implementere en ny database. Det bør være forsynet med de seneste data, og det kan gøres på mange måder - du kan kopiere dataene fra produktionsdatabasen til testserveren; det er den nemmeste ting at gøre. Alternativt kan du bruge den seneste backup - en sådan tilgang har yderligere fordele ved at teste backupgendannelsen. Sikkerhedskopieringsbekræftelse er et must-have i enhver form for seriøs implementering, og genopbygning af testopsætninger er en fantastisk måde at dobbelttjekke din gendannelsesproces fungerer på. Det hjælper dig også med at få tid til gendannelsesprocessen - at vide, hvor lang tid det tager at gendanne din sikkerhedskopi, hjælper dig med at vurdere situationen korrekt i et katastrofegendannelsesscenarie.
Når dataene er klargjort i databasen, vil du måske konfigurere den node som en replika af din primære klynge. Det har sine fordele og ulemper. Hvis du kunne genudføre al din trafik til den selvstændige node, ville det være perfekt - i sådanne tilfælde er der ingen grund til at konfigurere replikeringen. Nogle af belastningsbalancerne, som ProxySQL, giver dig mulighed for at spejle trafikken og sende dens kopi til en anden placering. På den anden side er replikering den næstbedste ting. Ja, du kan ikke udføre skrivninger direkte på den node, hvilket tvinger dig til at planlægge, hvordan du vil genudføre forespørgslerne, da den enkleste tilgang med bare at svare på det ikke virker. På den anden side vil alle skrivninger i sidste ende blive udført via SQL-tråden, så du skal kun planlægge, hvordan du skal håndtere SELECT-forespørgsler.
Afhængigt af den nøjagtige ændring, kan du prøve skemaændringsprocessen. Skemaændringer er ret almindelige at udføre, og de kan endda have en alvorlig indvirkning på databasen. Derfor er det vigtigt at verificere dem, før de anvendes i produktionen. Vi ønsker at se på den nødvendige tid til at udføre ændringen og kontrollere, om ændringen kan anvendes på noder separat eller er påkrævet for at udføre ændringen på hele topologien på samme tid. Dette vil fortælle os, hvilken proces vi skal bruge til en given skemaændring.
Brug af ClusterControl til at forbedre automatiseringen af frigivelsestestene
ClusterControl kommer med et sæt funktioner, der kan bruges til at hjælpe dig med at automatisere udgivelsestesten. Lad os tage et kig på, hvad det tilbyder. For at gøre det klart, er de funktioner, vi skal vise, tilgængelige på et par måder. Den enkleste måde er at bruge UI, men det er unødvendigt, hvad du vil gøre, hvis du har automatisering på hjerte. Der er yderligere to måder at gøre det på:Kommandolinjegrænseflade til ClusterControl og RPC API. I begge tilfælde kan jobs udløses fra eksterne scripts, så du kan tilslutte dem til dine eksisterende CI/CD-processer. Det vil også spare dig for masser af tid, da implementering af klyngen kun kan være et spørgsmål om at udføre en kommando i stedet for at konfigurere den manuelt.
Implementering af testklyngen
Først og fremmest kommer ClusterControl med en mulighed for at implementere en ny klynge og levere den med data fra den eksisterende database. Alene denne funktion giver dig mulighed for nemt at implementere klargøring af staging-serveren.
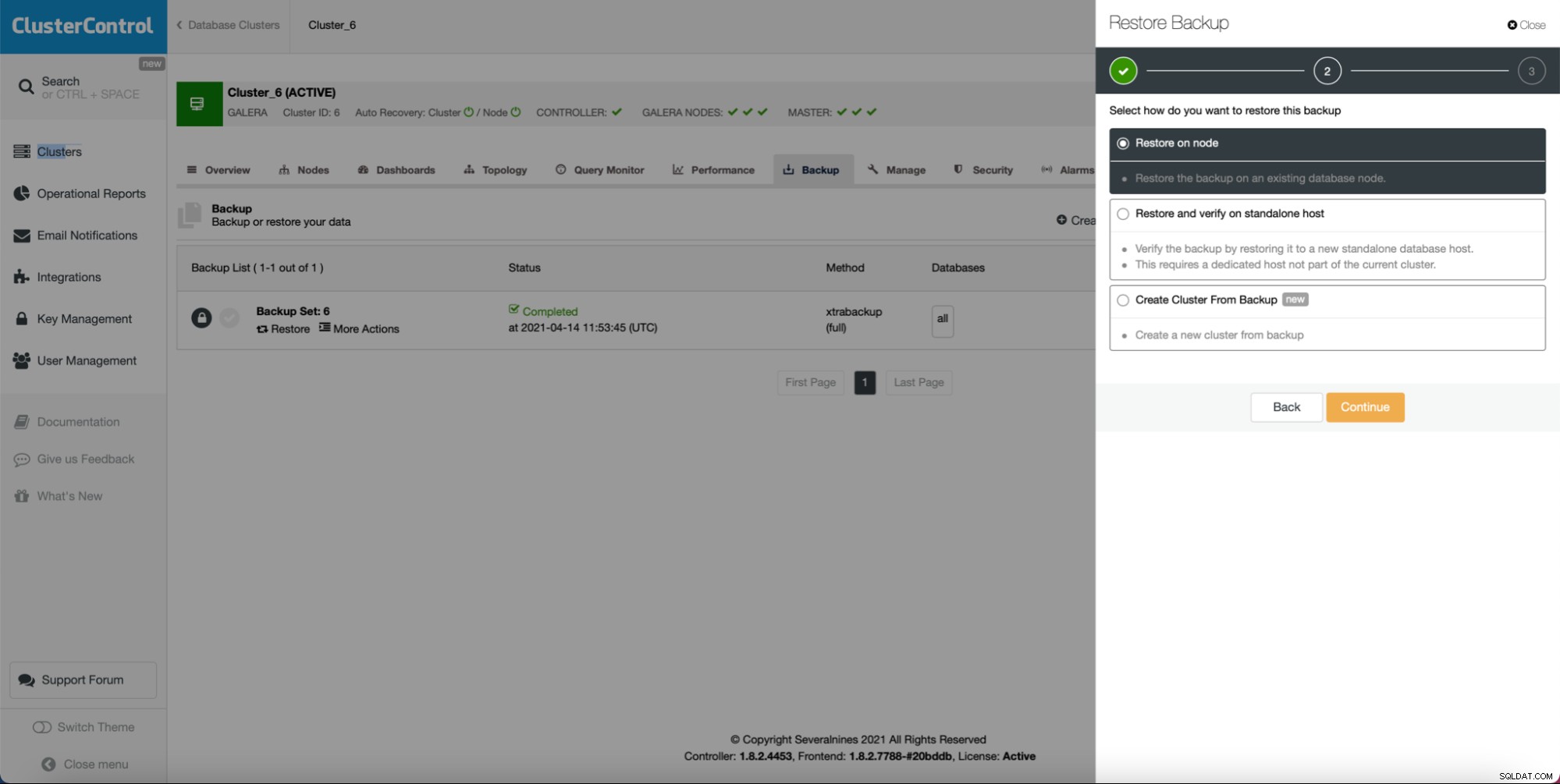
Som du kan se, så længe du har oprettet en sikkerhedskopi, kan du kan oprette en ny klynge og klargøre den ved hjælp af dataene fra sikkerhedskopien:
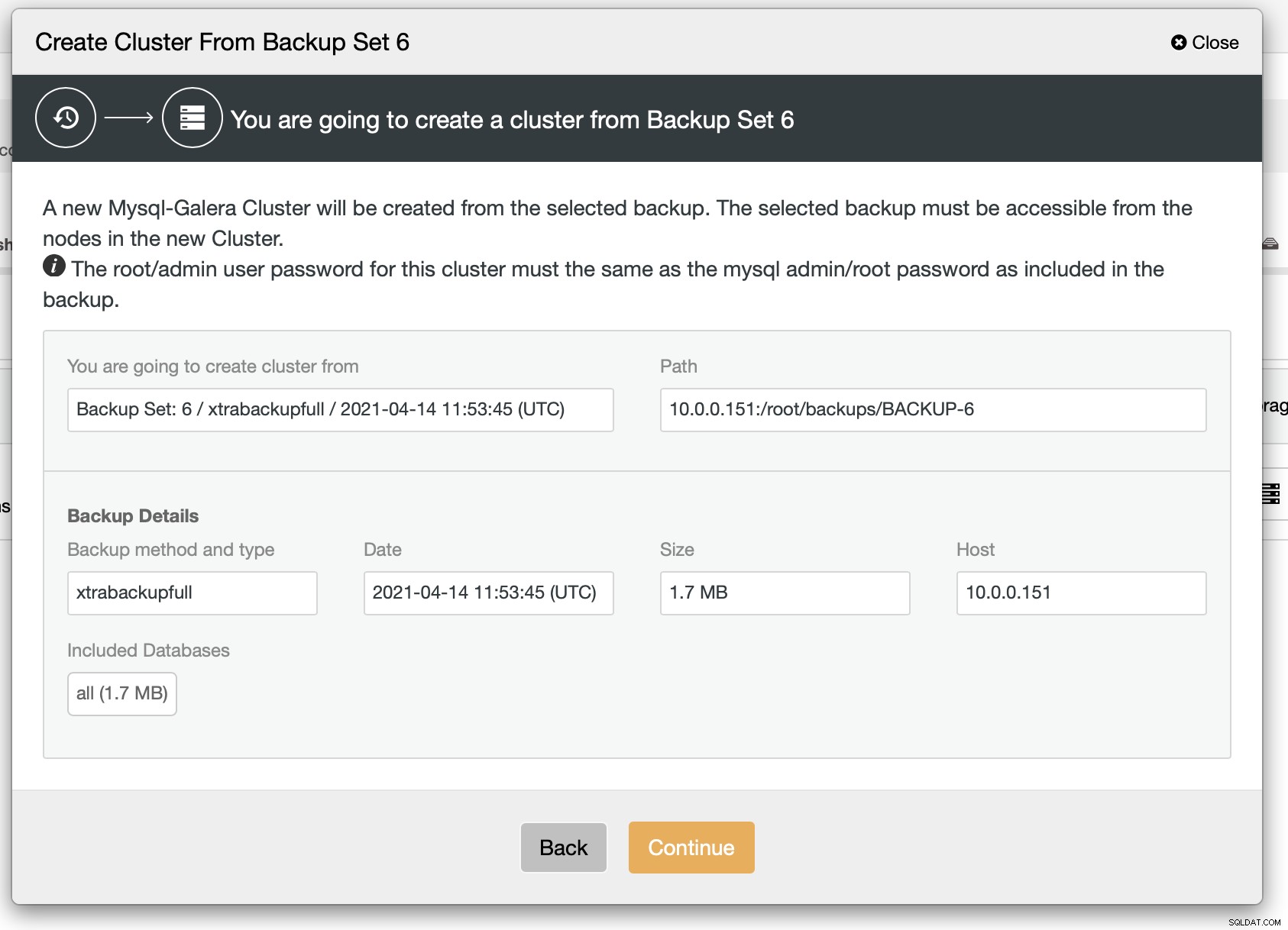
Som vi kan se, er der en hurtig oversigt over, hvad der vil ske. Hvis du klikker på Fortsæt, kommer du videre.
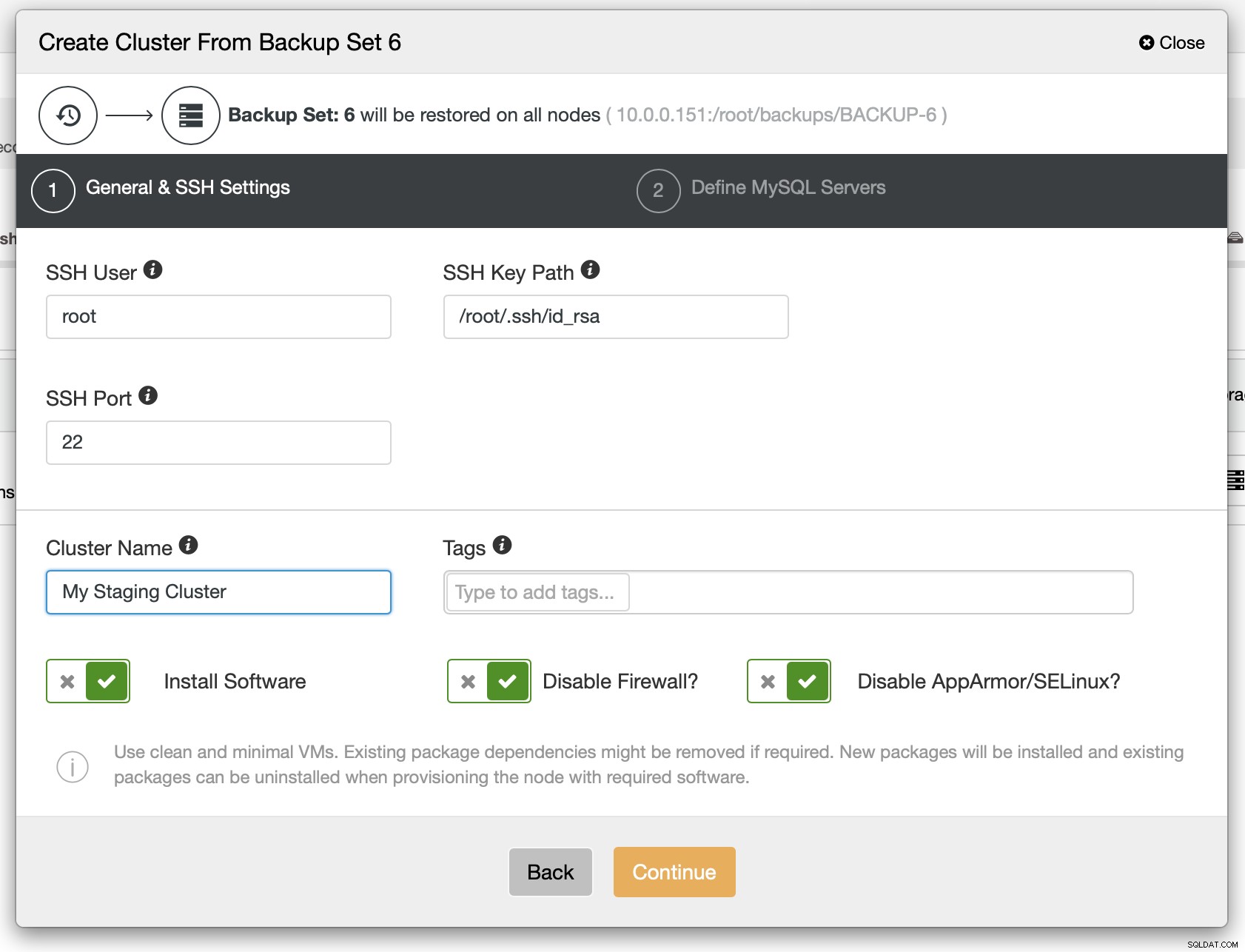
Som et næste trin bør du definere SSH-forbindelsen - den skal være på plads, før ClusterControl er i stand til at implementere noderne.
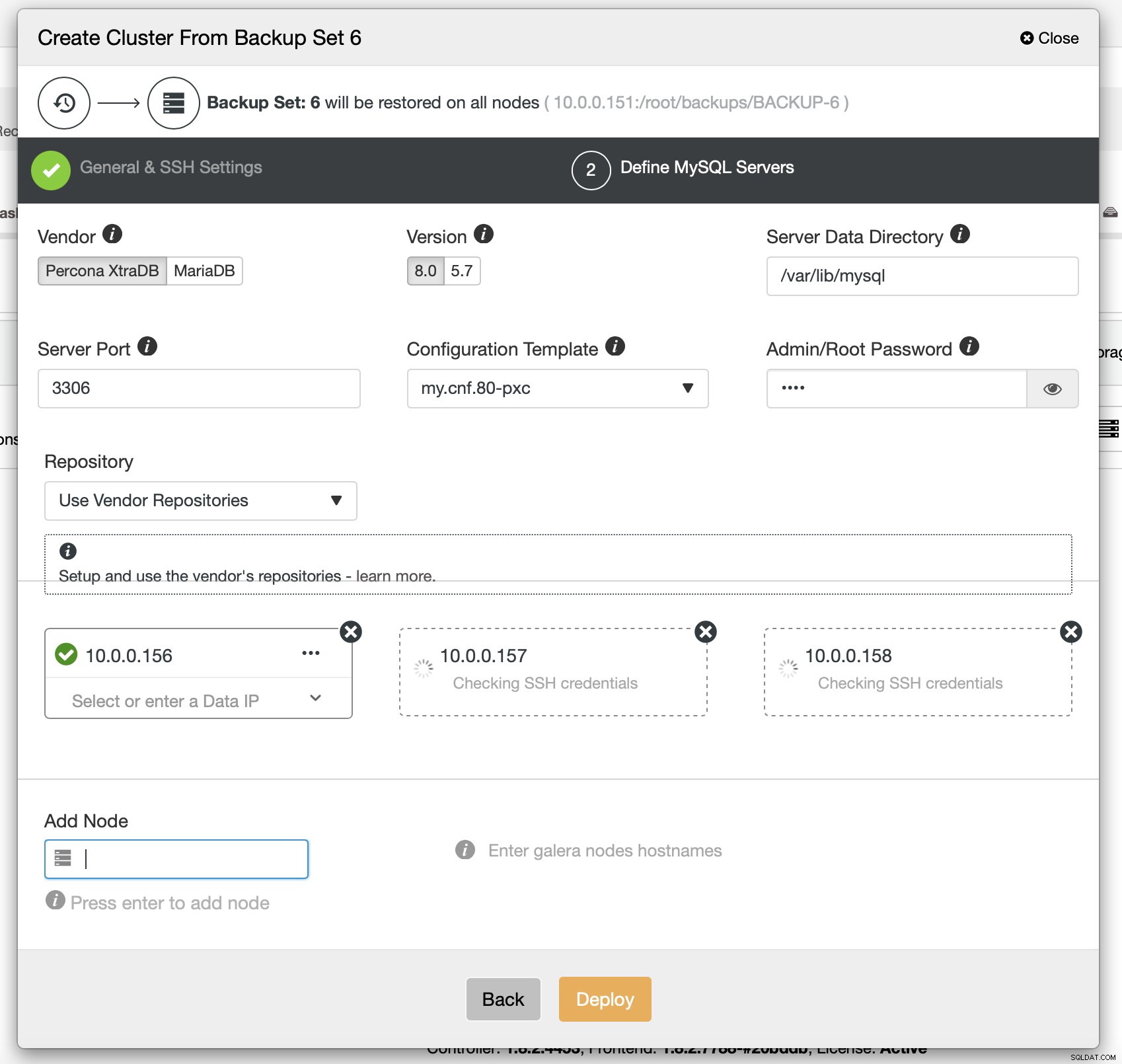
Til sidst skal du vælge (blandt andre) leverandøren, versionen og værtsnavnene på de noder, du vil bruge i klyngen. Det er bare det.
CLI-kommandoen, der ville udføre det samme, ser sådan ud:
s9s cluster --create --cluster-type=galera --nodes="10.0.0.156;10.0.0.157;10.0.0.158" --vendor=percona --cluster-name=PXC --provider-version=8.0 --os-user=root --os-key-file=/root/.ssh/id_rsa --backup-id=6Konfiguration af ProxySQL til at spejle trafikken
Hvis vi har en klynge installeret, vil vi måske sende produktionstrafikken til den for at bekræfte, hvordan det nye skema håndterer den eksisterende trafik. En måde at gøre dette på er ved at bruge ProxySQL.
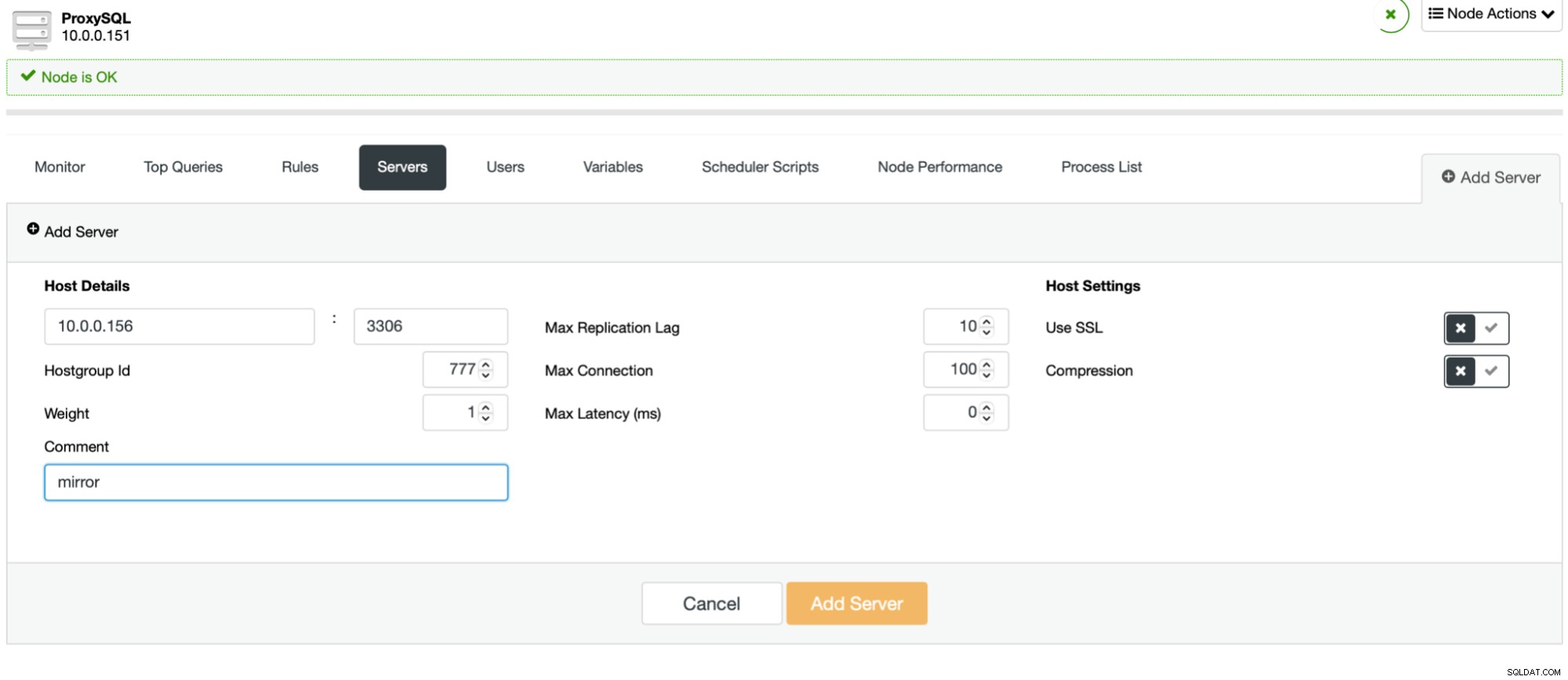
Processen er nem. Først skal du tilføje noderne til ProxySQL. De bør tilhøre en separat værtsgruppe, der ikke er i brug endnu. Sørg for, at ProxySQL-monitorbrugeren vil være i stand til at få adgang til dem.
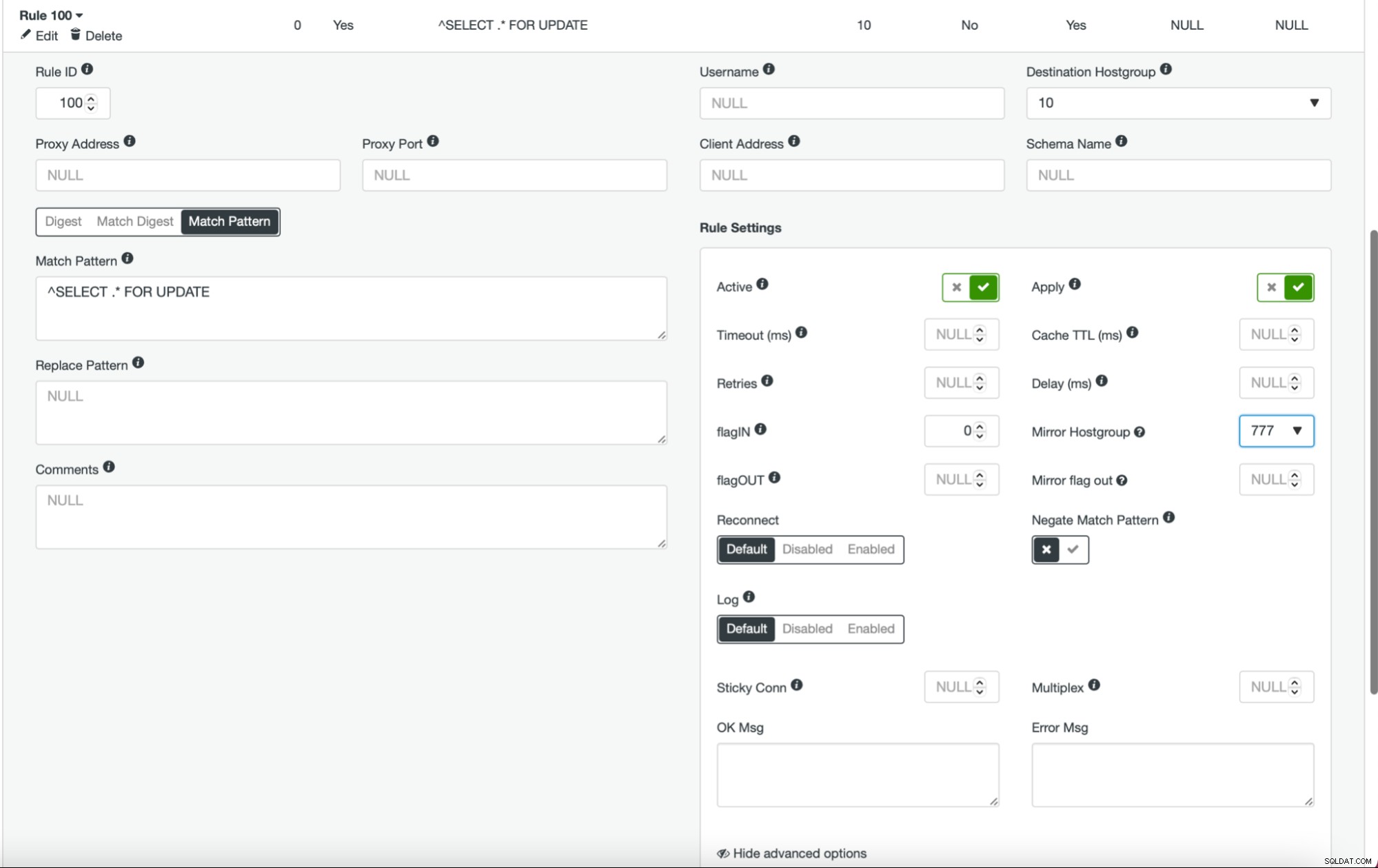
Når dette er gjort, og du har alle (eller nogle) af dine noder konfigureret i værtsgruppen, kan du redigere forespørgselsreglerne og definere spejlværtsgruppen (den er tilgængelig i de avancerede muligheder). Hvis du vil gøre det for hele trafikken, vil du sandsynligvis redigere alle dine forespørgselsregler på denne måde. Hvis du kun vil spejle SELECT-forespørgsler, bør du redigere passende forespørgselsregler. Når dette er gjort, bør din iscenesættelsesklynge begynde at modtage produktionstrafik.
Deployer klynge som slave
Som vi diskuterede tidligere, ville en alternativ løsning være at oprette en ny klynge, der vil fungere som en replika af den eksisterende opsætning. Med en sådan tilgang kan vi få alle skrivningerne testet automatisk ved hjælp af replikeringen. SELECT'er kan testes ved hjælp af den fremgangsmåde, vi beskrev ovenfor - spejling gennem ProxySQL.
Installationen af en slaveklynge er ret ligetil.
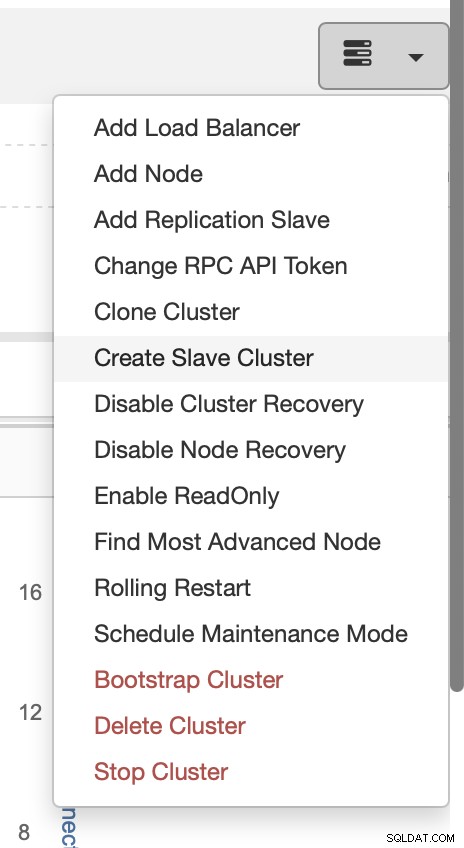
Vælg opgaven Opret slaveklynge.
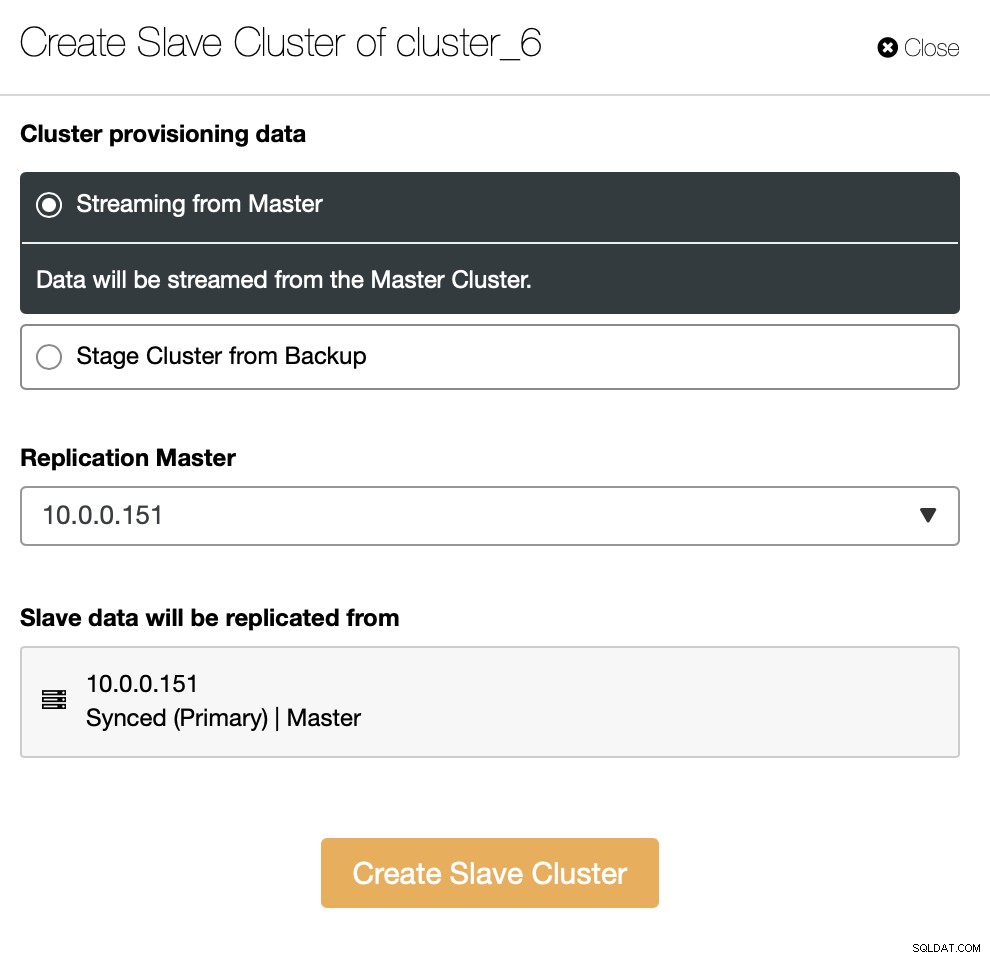
Du skal beslutte, hvordan du vil have replikeringssættet. Du kan få alle data overført fra masteren til de nye noder.
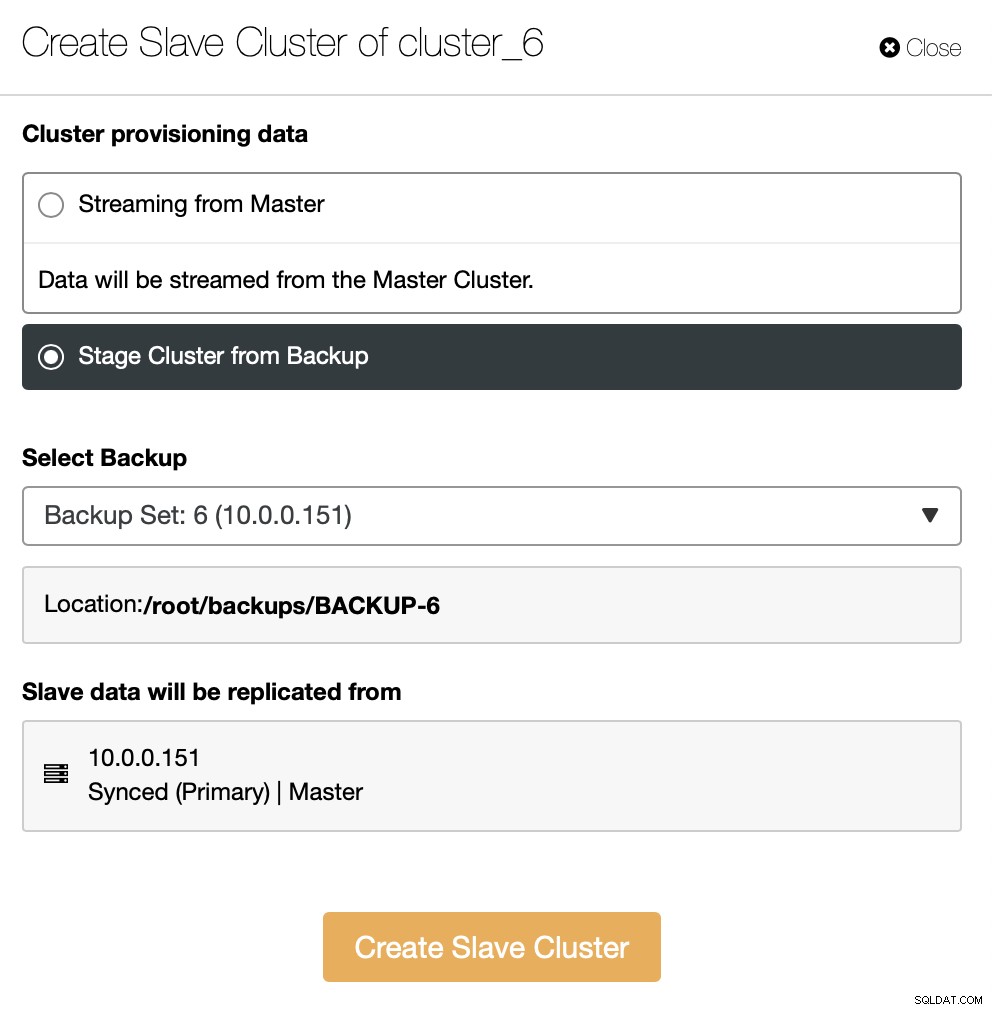
Som et alternativ kan du bruge eksisterende backup til at klargøre den nye klynge. Dette vil medvirke til at reducere arbejdsbyrden på masterknudepunktet - i stedet for at overføre alle data, er det kun transaktioner, der blev udført mellem tidspunktet for sikkerhedskopieringen, og det øjeblik replikeringen er blevet sat op, der skal overføres.
Resten er at følge standardimplementeringsguiden, der definerer SSH-forbindelse, version, leverandør, værter og så videre. Når det er implementeret, vil du se klyngen på listen.
Alternativ løsning til brugergrænsefladen er at opnå dette via RPC.
{
"command": "create_cluster",
"job_data": {
"cluster_name": "",
"cluster_type": "galera",
"company_id": null,
"config_template": "my.cnf.80-pxc",
"data_center": 0,
"datadir": "/var/lib/mysql",
"db_password": "pass",
"db_user": "root",
"disable_firewall": true,
"disable_selinux": true,
"enable_mysql_uninstall": true,
"generate_token": true,
"install_software": true,
"port": "3306",
"remote_cluster_id": 6,
"software_package": "",
"ssh_keyfile": "/root/.ssh/id_rsa",
"ssh_port": "22",
"ssh_user": "root",
"sudo_password": "",
"type": "mysql",
"user_id": 5,
"vendor": "percona",
"version": "8.0",
"nodes": [
{
"hostname": "10.0.0.155",
"hostname_data": "10.0.0.155",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.159",
"hostname_data": "10.0.0.159",
"hostname_internal": "",
"port": "3306"
},
{
"hostname": "10.0.0.160",
"hostname_data": "10.0.0.160",
"hostname_internal": "",
"port": "3306"
}
],
"with_tags": []
}
}Gå fremad
Hvis du er interesseret i at lære mere om, hvordan du kan integrere dine processer med ClusterControl, vil vi gerne henvise dig til dokumentationen, hvor vi har et helt afsnit om udvikling af løsninger, hvor ClusterControl spiller en væsentlig rolle:
https://docs.severalnines.com/docs/clustercontrol/developer-guide/cmon-rpc/
https://docs.severalnines.com/docs/clustercontrol/user-guide-cli/
Vi håber, du fandt denne korte blog informativ og nyttig. Hvis du har spørgsmål vedrørende integration af ClusterControl i dit miljø, bedes du kontakte os, og vi vil gøre vores bedste for at hjælpe dig.