En af de mange nye funktioner, der blev introduceret tilbage i SQL Server 2008, var datakomprimering. Komprimering på enten række- eller sideniveau giver mulighed for at spare diskplads, med den afvejning, at det kræver lidt mere CPU for at komprimere og dekomprimere dataene. Det hævdes ofte, at de fleste systemer er IO-bundne, ikke CPU-bundne, så afvejningen er det værd. Fangsten? Du skulle være på Enterprise Edition for at bruge datakomprimering. Med udgivelsen af SQL Server 2016 SP1 har det ændret sig! Hvis du kører Standard Edition af SQL Server 2016 SP1 og nyere, kan du nu bruge datakomprimering. Der er også en ny indbygget funktion til komprimering, COMPRESS (og dens modstykke DECOMPRESS). Datakomprimering virker ikke på data uden for rækken, så hvis du har en kolonne som NVARCHAR(MAX) i din tabel med værdier, der typisk er større end 8000 bytes, bliver disse data ikke komprimeret (tak Adam Machanic for den påmindelse) . COMPRESS-funktionen løser dette problem og komprimerer data på op til 2 GB. Selvom jeg vil hævde, at funktionen kun bør bruges til store data uden for rækken, syntes jeg, at det var et værdifuldt eksperiment at sammenligne den direkte med række- og sidekomprimering.
OPSÆTNING
Til testdata arbejder jeg ud fra et script, Aaron Bertrand har brugt tidligere, men jeg har lavet nogle justeringer. Jeg oprettede en separat database til test, men du kan bruge tempdb eller en anden eksempeldatabase, og så startede jeg med en kundetabel, der har tre NVARCHAR-kolonner. Jeg overvejede at oprette større kolonner og udfylde dem med strenge af gentagne bogstaver, men at bruge læsbar tekst giver et eksempel, der er mere realistisk og dermed giver større nøjagtighed.
Bemærk: Hvis du er interesseret i at implementere komprimering og gerne vil vide, hvordan det vil påvirke lagring og ydeevne i dit miljø, ANBEFALDER JEG STÆRKT AT TEST DET. Jeg giver dig metoden med eksempeldata; implementering af dette i dit miljø burde ikke indebære yderligere arbejde.
Du vil bemærke nedenfor, at efter at have oprettet databasen, aktiverer vi Query Store. Hvorfor oprette en separat tabel for at prøve at spore vores præstationsmålinger, når vi bare kan bruge funktionalitet indbygget i SQL Server?!
USE [master]; GO CREATE DATABASE [CustomerDB] CONTAINMENT = NONE ON PRIMARY ( NAME = N'CustomerDB', FILENAME = N'C:\Databases\CustomerDB.mdf' , SIZE = 4096MB , MAXSIZE = UNLIMITED, FILEGROWTH = 65536KB ) LOG ON ( NAME = N'CustomerDB_log', FILENAME = N'C:\Databases\CustomerDB_log.ldf' , SIZE = 2048MB , MAXSIZE = UNLIMITED , FILEGROWTH = 65536KB ); GO ALTER DATABASE [CustomerDB] SET COMPATIBILITY_LEVEL = 130; GO ALTER DATABASE [CustomerDB] SET RECOVERY SIMPLE; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE = ON; GO ALTER DATABASE [CustomerDB] SET QUERY_STORE ( OPERATION_MODE = READ_WRITE, CLEANUP_POLICY = (STALE_QUERY_THRESHOLD_DAYS = 30), DATA_FLUSH_INTERVAL_SECONDS = 60, INTERVAL_LENGTH_MINUTES = 5, MAX_STORAGE_SIZE_MB = 256, QUERY_CAPTURE_MODE = ALL, SIZE_BASED_CLEANUP_MODE = AUTO, MAX_PLANS_PER_QUERY = 200 ); GO
Nu sætter vi nogle ting op inde i databasen:
USE [CustomerDB]; GO ALTER DATABASE SCOPED CONFIGURATION SET MAXDOP = 0; GO -- note: I removed the unique index on [Email] that was in Aaron's version CREATE TABLE [dbo].[Customers] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers] ON [dbo].[Customers]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers] ON [dbo].[Customers]([LastName],[FirstName]) INCLUDE ([EMail]);
Med tabellen oprettet tilføjer vi nogle data, men vi tilføjer 5 millioner rækker i stedet for 1 million. Det tager cirka otte minutter at køre på min bærbare computer.
INSERT dbo.Customers WITH (TABLOCKX)
(CustomerID, FirstName, LastName, EMail, [Active])
SELECT rn = ROW_NUMBER() OVER (ORDER BY n), fn, ln, em, a
FROM
(
SELECT TOP (5000000) fn, ln, em, a = MAX(a), n = MAX(NEWID())
FROM
(
SELECT fn, ln, em, a, r = ROW_NUMBER() OVER (PARTITION BY em ORDER BY em)
FROM
(
SELECT TOP (20000000)
fn = LEFT(o.name, 64),
ln = LEFT(c.name, 64),
em = LEFT(o.name, LEN(c.name)%5+1) + '.'
+ LEFT(c.name, LEN(o.name)%5+2) + '@'
+ RIGHT(c.name, LEN(o.name + c.name)%12 + 1)
+ LEFT(RTRIM(CHECKSUM(NEWID())),3) + '.com',
a = CASE WHEN c.name LIKE '%y%' THEN 0 ELSE 1 END
FROM sys.all_objects AS o CROSS JOIN sys.all_columns AS c
ORDER BY NEWID()
) AS x
) AS y WHERE r = 1
GROUP BY fn, ln, em
ORDER BY n
) AS z
ORDER BY rn;
GO Nu laver vi yderligere tre tabeller:en til rækkekomprimering, en til sidekomprimering og en til COMPRESS-funktionen. Bemærk, at med funktionen COMPRESS skal du oprette kolonnerne som VARBINARY-datatyper. Som et resultat er der ingen ikke-klyngede indekser i tabellen (da du ikke kan oprette en indeksnøgle på en varbinær kolonne).
CREATE TABLE [dbo].[Customers_Page] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Page] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Page] ON [dbo].[Customers_Page]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Page] ON [dbo].[Customers_Page]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Row] ( [CustomerID] [int] NOT NULL, [FirstName] [nvarchar](64) NOT NULL, [LastName] [nvarchar](64) NOT NULL, [EMail] [nvarchar](320) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Row] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO CREATE NONCLUSTERED INDEX [Active_Customers_Row] ON [dbo].[Customers_Row]([FirstName],[LastName],[EMail]) WHERE ([Active]=1); GO CREATE NONCLUSTERED INDEX [PhoneBook_Customers_Row] ON [dbo].[Customers_Row]([LastName],[FirstName]) INCLUDE ([EMail]); GO CREATE TABLE [dbo].[Customers_Compress] ( [CustomerID] [int] NOT NULL, [FirstName] [varbinary](max) NOT NULL, [LastName] [varbinary](max) NOT NULL, [EMail] [varbinary](max) NOT NULL, [Active] [bit] NOT NULL DEFAULT 1, [Created] [datetime] NOT NULL DEFAULT SYSDATETIME(), [Updated] [datetime] NULL, CONSTRAINT [PK_Customers_Compress] PRIMARY KEY CLUSTERED ([CustomerID]) ); GO
Dernæst kopierer vi dataene fra [dbo].[Kunder] til de tre andre tabeller. Dette er en lige INSERT for vores side- og rækketabeller og tager omkring to til tre minutter for hver INSERT, men der er et skalerbarhedsproblem med COMPRESS-funktionen:Det er bare ikke rimeligt at indsætte 5 millioner rækker i ét hug. Scriptet nedenfor indsætter rækker i batches af 50.000, og indsætter kun 1 million rækker i stedet for 5 millioner. Jeg ved godt, det betyder, at vi ikke rigtig er æbler-til-æbler her til sammenligning, men jeg er ok med det. Det tager 10 minutter at indsætte 1 million rækker på min maskine; du er velkommen til at justere scriptet og indsætte 5 millioner rækker til dine egne tests.
INSERT dbo.Customers_Page WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO INSERT dbo.Customers_Row WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT CustomerID, FirstName, LastName, EMail, [Active] FROM dbo.Customers; GO SET NOCOUNT ON DECLARE @StartID INT = 1 DECLARE @EndID INT = 50000 DECLARE @Increment INT = 50000 DECLARE @IDMax INT = 1000000 WHILE @StartID < @IDMax BEGIN INSERT dbo.Customers_Compress WITH (TABLOCKX) (CustomerID, FirstName, LastName, EMail, [Active]) SELECT top 100000 CustomerID, COMPRESS(FirstName), COMPRESS(LastName), COMPRESS(EMail), [Active] FROM dbo.Customers WHERE [CustomerID] BETWEEN @StartID AND @EndID; SET @StartID = @StartID + @Increment; SET @EndID = @EndID + @Increment; END
Med alle vores borde udfyldt, kan vi kontrollere størrelsen. På nuværende tidspunkt har vi ikke implementeret ROW- eller PAGE-komprimering, men COMPRESS-funktionen er blevet brugt:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [o].[name], [i].[index_id];
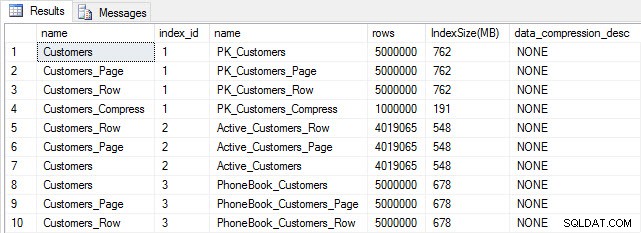 Tabel- og indeksstørrelse efter indsættelse
Tabel- og indeksstørrelse efter indsættelse
Som forventet har alle tabeller undtagen Customers_Compress omtrent samme størrelse. Nu genopbygger vi indekser på alle tabeller og implementerer række- og sidekomprimering på henholdsvis Customers_Row og Customers_Page.
ALTER INDEX ALL ON dbo.Customers REBUILD; GO ALTER INDEX ALL ON dbo.Customers_Page REBUILD WITH (DATA_COMPRESSION = PAGE); GO ALTER INDEX ALL ON dbo.Customers_Row REBUILD WITH (DATA_COMPRESSION = ROW); GO ALTER INDEX ALL ON dbo.Customers_Compress REBUILD;
Hvis vi tjekker tabelstørrelsen efter komprimering, kan vi nu se vores diskpladsbesparelser:
SELECT [o].[name], [i].[index_id], [i].[name], [p].[rows], (8*SUM([au].[used_pages]))/1024 AS [IndexSize(MB)], [p].[data_compression_desc] FROM [sys].[allocation_units] [au] JOIN [sys].[partitions] [p] ON [au].[container_id] = [p].[partition_id] JOIN [sys].[objects] [o] ON [p].[object_id] = [o].[object_id] JOIN [sys].[indexes] [i] ON [p].[object_id] = [i].[object_id] AND [p].[index_id] = [i].[index_id] WHERE [o].[is_ms_shipped] = 0 GROUP BY [o].[name], [i].[index_id], [i].[name], [p].[rows], [p].[data_compression_desc] ORDER BY [i].[index_id], [IndexSize(MB)] DESC;
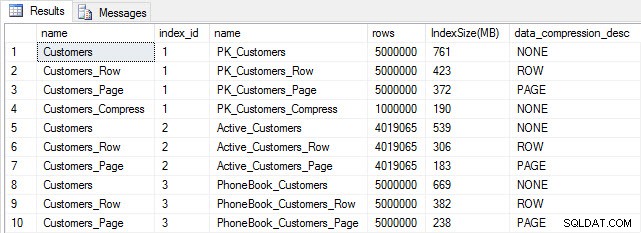
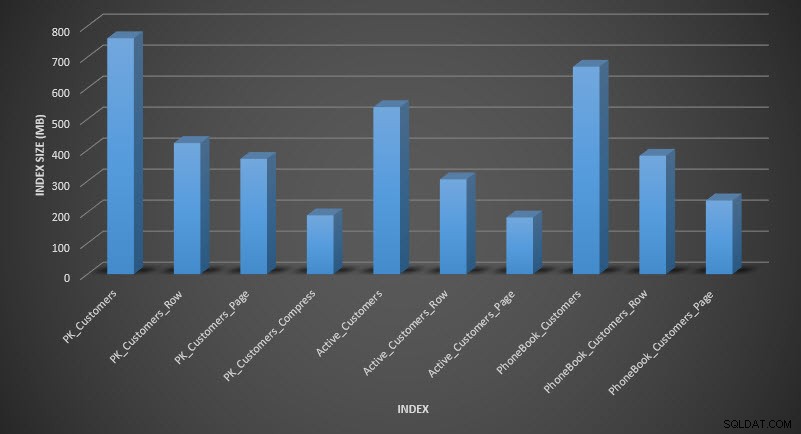 Indeksstørrelse efter komprimering
Indeksstørrelse efter komprimering
Som forventet reducerer række- og sidekomprimeringen betydeligt størrelsen af tabellen og dens indekser. COMPRESS-funktionen sparede os for mest plads – det klyngede indeks er en fjerdedel af størrelsen på den oprindelige tabel.
UNDERSØGELSE AF FORESPØRGSELENS YDELSE
Før vi tester forespørgselsydeevne, skal du være opmærksom på, at vi kan bruge Query Store til at se på INSERT og REBUILD ydeevne:
SELECT [q].[query_id], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], AVG([rs].[avg_duration])/1000 [AvgDuration_ms], AVG([rs].[avg_cpu_time]) [AvgCPU], AVG([rs].[avg_logical_io_reads]) [AvgLogicalReads], AVG([rs].[avg_physical_io_reads]) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] LEFT OUTER JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [qt].[query_sql_text] LIKE '%INSERT%' OR [qt].[query_sql_text] LIKE '%ALTER%' GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [q].[query_id];
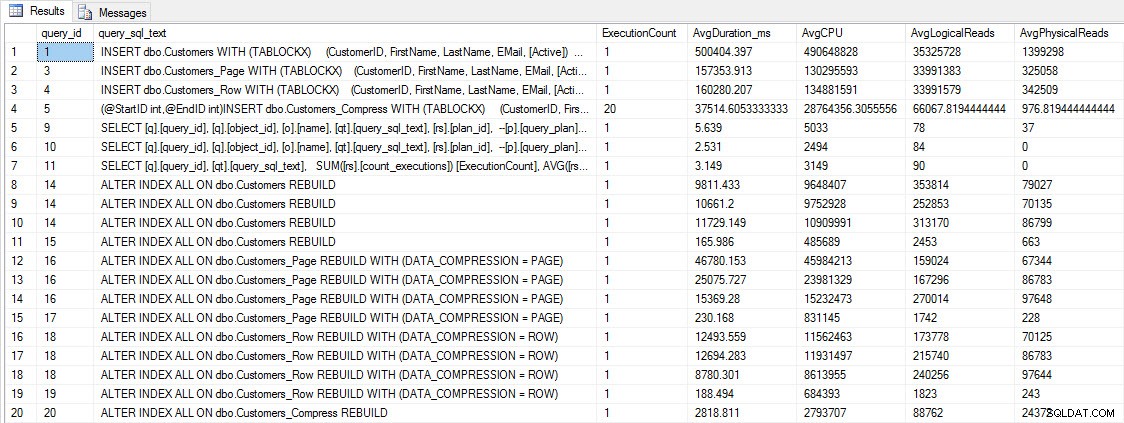 INDSÆT og GENBYG ydeevnemålinger
INDSÆT og GENBYG ydeevnemålinger
Selvom disse data er interessante, er jeg mere nysgerrig efter, hvordan komprimering påvirker mine daglige SELECT-forespørgsler. Jeg har et sæt af tre lagrede procedurer, der hver har en SELECT-forespørgsel, så hvert indeks bruges. Jeg oprettede disse procedurer for hver tabel og skrev derefter et script til at trække værdier for for- og efternavne til brug til test. Her er scriptet til at oprette procedurerne.
Når vi har oprettet de lagrede procedurer, kan vi køre scriptet nedenfor for at kalde dem. Sæt det i gang, og vent derefter et par minutter...
SET NOCOUNT ON; GO DECLARE @RowNum INT = 1; DECLARE @Round INT = 1; DECLARE @ID INT = 1; DECLARE @FN NVARCHAR(64); DECLARE @LN NVARCHAR(64); DECLARE @SQLstring NVARCHAR(MAX); DROP TABLE IF EXISTS #FirstNames, #LastNames; SELECT DISTINCT [FirstName], DENSE_RANK() OVER (ORDER BY [FirstName]) AS RowNum INTO #FirstNames FROM [dbo].[Customers] SELECT DISTINCT [LastName], DENSE_RANK() OVER (ORDER BY [LastName]) AS RowNum INTO #LastNames FROM [dbo].[Customers] WHILE 1=1 BEGIN SELECT @FN = ( SELECT [FirstName] FROM #FirstNames WHERE RowNum = @RowNum) SELECT @LN = ( SELECT [LastName] FROM #LastNames WHERE RowNum = @RowNum) SET @FN = SUBSTRING(@FN, 1, 5) + '%' SET @LN = SUBSTRING(@LN, 1, 5) + '%' EXEC [dbo].[usp_FindActiveCustomer_C] @FN; EXEC [dbo].[usp_FindAnyCustomer_C] @LN; EXEC [dbo].[usp_FindSpecificCustomer_C] @ID; EXEC [dbo].[usp_FindActiveCustomer_P] @FN; EXEC [dbo].[usp_FindAnyCustomer_P] @LN; EXEC [dbo].[usp_FindSpecificCustomer_P] @ID; EXEC [dbo].[usp_FindActiveCustomer_R] @FN; EXEC [dbo].[usp_FindAnyCustomer_R] @LN; EXEC [dbo].[usp_FindSpecificCustomer_R] @ID; EXEC [dbo].[usp_FindActiveCustomer_CS] @FN; EXEC [dbo].[usp_FindAnyCustomer_CS] @LN; EXEC [dbo].[usp_FindSpecificCustomer_CS] @ID; IF @ID < 5000000 BEGIN SET @ID = @ID + @Round END ELSE BEGIN SET @ID = 2 END IF @Round < 26 BEGIN SET @Round = @Round + 1 END ELSE BEGIN IF @RowNum < 2260 BEGIN SET @RowNum = @RowNum + 1 SET @Round = 1 END ELSE BEGIN SET @RowNum = 1 SET @Round = 1 END END END GO
Efter et par minutter kan du se, hvad der er i Query Store:
SELECT [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], SUM([rs].[count_executions]) [ExecutionCount], CAST(AVG([rs].[avg_duration])/1000 AS DECIMAL(10,2)) [AvgDuration_ms], CAST(AVG([rs].[avg_cpu_time]) AS DECIMAL(10,2)) [AvgCPU], CAST(AVG([rs].[avg_logical_io_reads]) AS DECIMAL(10,2)) [AvgLogicalReads], CAST(AVG([rs].[avg_physical_io_reads]) AS DECIMAL(10,2)) [AvgPhysicalReads] FROM [sys].[query_store_query] [q] JOIN [sys].[query_store_query_text] [qt] ON [q].[query_text_id] = [qt].[query_text_id] JOIN [sys].[objects] [o] ON [q].[object_id] = [o].[object_id] JOIN [sys].[query_store_plan] [p] ON [q].[query_id] = [p].[query_id] JOIN [sys].[query_store_runtime_stats] [rs] ON [p].[plan_id] = [rs].[plan_id] WHERE [q].[object_id] <> 0 GROUP BY [q].[query_id], [q].[object_id], [o].[name], [qt].[query_sql_text], [rs].[plan_id] ORDER BY [o].[name];
Du vil se, at de fleste lagrede procedurer kun er blevet udført 20 gange, fordi to procedurer mod [dbo].[Customers_Compress] er virkelig langsom. Dette er ikke en overraskelse; hverken [FirstName] eller [LastName] er indekseret, så enhver forespørgsel bliver nødt til at scanne tabellen. Jeg ønsker ikke, at disse to forespørgsler skal bremse min testning, så jeg vil ændre arbejdsbyrden og kommentere EXEC [dbo].[usp_FindActiveCustomer_CS] og EXEC [dbo].[usp_FindAnyCustomer_CS] og derefter starte det igen. Denne gang lader jeg den køre i cirka 10 minutter, og når jeg ser på Query Store-outputtet igen, har jeg nu nogle gode data. Rå tal er nedenfor, med manager-favoritgraferne nedenfor.
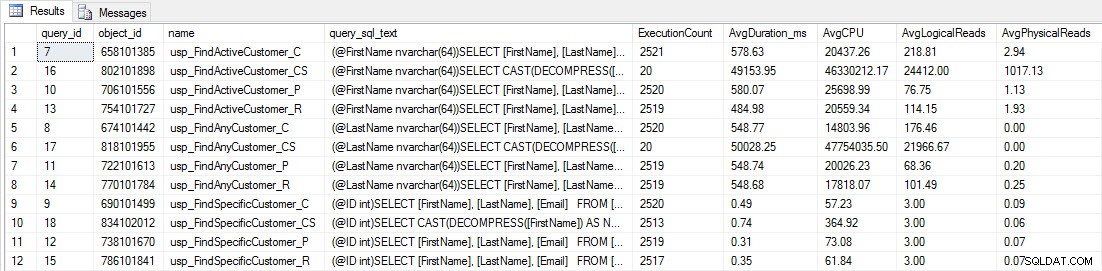 Ydeevnedata fra Query Store
Ydeevnedata fra Query Store
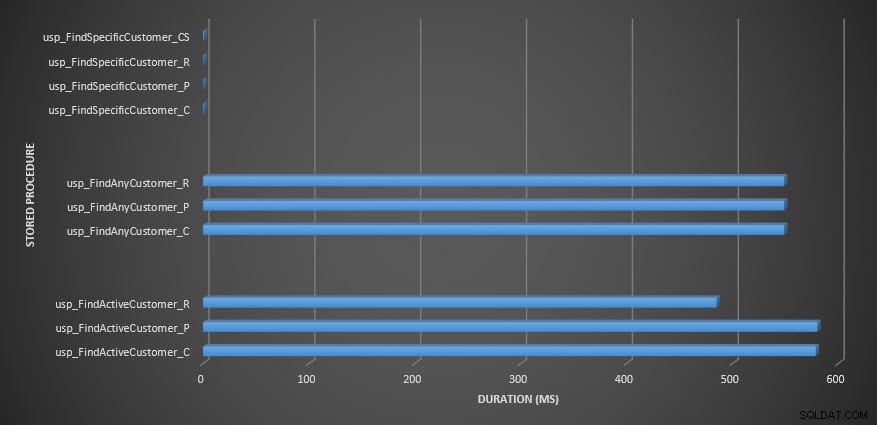 Varighed af lagret procedure
Varighed af lagret procedure
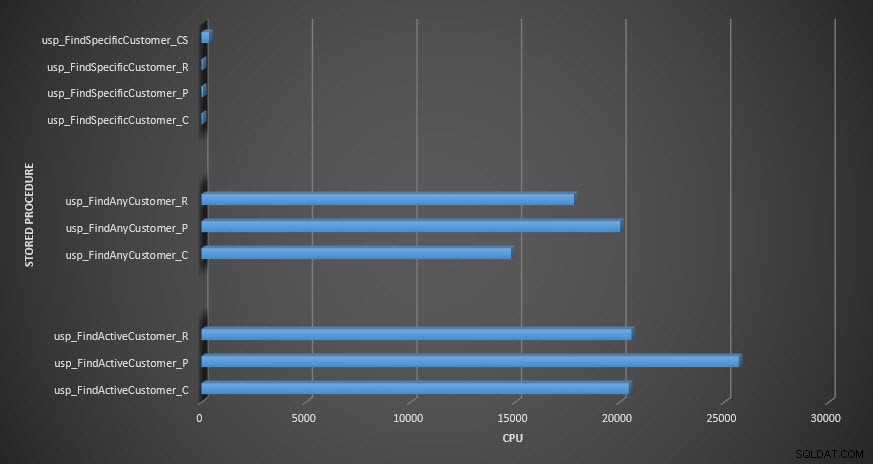 CPU for lagret procedure
CPU for lagret procedure
Påmindelse:Alle lagrede procedurer, der slutter med _C, er fra den ikke-komprimerede tabel. Procedurerne, der slutter med _R, er den rækkekomprimerede tabel, dem, der slutter med _P, er sidekomprimerede, og den med _CS bruger COMPRESS-funktionen (jeg fjernede resultaterne for nævnte tabel for usp_FindAnyCustomer_CS og usp_FindActiveCustomer_CS, da de skævede grafen så meget, at vi mistede forskelle i resten af dataene). Procedurerne usp_FindAnyCustomer_* og usp_FindActiveCustomer_* brugte ikke-klyngede indekser og returnerede tusindvis af rækker for hver udførelse.
Jeg forventede, at varigheden ville være højere for procedurerne usp_FindAnyCustomer_* og usp_FindActiveCustomer_* mod række- og sidekomprimerede tabeller sammenlignet med den ikke-komprimerede tabel på grund af overheaden ved at dekomprimere dataene. Query Store-dataene understøtter ikke min forventning – varigheden for disse to lagrede procedurer er nogenlunde den samme (eller mindre i ét tilfælde!) på tværs af disse tre tabeller. Den logiske IO for forespørgslerne var næsten den samme på tværs af de ikke-komprimerede og side- og rækkekomprimerede tabeller.
Med hensyn til CPU var den i de lagrede procedurer usp_FindActiveCustomer og usp_FindAnyCustomer altid højere for de komprimerede tabeller. CPU var sammenlignelig for proceduren usp_FindSpecificCustomer, som altid var et singleton-opslag mod det klyngede indeks. Bemærk den høje CPU (men relativt lave varighed) for usp_FindSpecificCustomer-proceduren i forhold til tabellen [dbo].[Customer_Compress], som krævede DECOMPRESS-funktionen for at vise data i læsbart format.
RESUMÉ
Den ekstra CPU, der kræves for at hente komprimerede data, findes og kan måles ved hjælp af Query Store eller traditionelle basislinjemetoder. Baseret på denne indledende test er CPU sammenlignelig for singleton-opslag, men stiger med flere data. Jeg ville tvinge SQL Server til at dekomprimere mere end blot 10 sider – jeg ville i det mindste have 100. Jeg udførte variationer af dette script, hvor titusindvis af rækker blev returneret, og resultaterne stemte overens med det, du ser her. Min forventning er, at for at se betydelige forskelle i varighed på grund af den tid, der skal dekomprimeres dataene, skal forespørgsler returnere hundredtusindvis eller millioner af rækker. Hvis du er i et OLTP-system, vil du ikke returnere så mange rækker, så testene her burde give dig en idé om, hvordan komprimering kan påvirke ydeevnen. Hvis du er i et datavarehus, vil du sandsynligvis se højere varighed sammen med den højere CPU, når du returnerer store datasæt. Mens COMPRESS-funktionen giver betydelige pladsbesparelser sammenlignet med side- og rækkekomprimering, gør præstationshittet i form af CPU og manglende evne til at indeksere de komprimerede kolonner på grund af deres datatype, den kun levedygtig for store datamængder, der ikke vil blive søgte.