OPDATERING:2. september 2021 (Oprindeligt offentliggjort 26. juli 2012.)
Mange ting ændrer sig i løbet af nogle få større versioner af vores foretrukne databaseplatform. SQL Server 2016 bragte os STRING_SPLIT, en indbygget funktion, der eliminerer behovet for mange af de tilpassede løsninger, vi har haft brug for før. Det er også hurtigt, men det er ikke perfekt. For eksempel understøtter det kun et enkelt-tegns afgrænsning, og det returnerer ikke noget for at angive rækkefølgen af input-elementerne. Jeg har skrevet flere artikler om denne funktion (og STRING_AGG, som ankom i SQL Server 2017), siden dette indlæg blev skrevet:
- Ydeevne-overraskelser og antagelser:STRING_SPLIT()
- STRING_SPLIT() i SQL Server 2016:Opfølgning #1
- STRING_SPLIT() i SQL Server 2016:Opfølgning #2
- SQL Server Split String Erstatningskode med STRING_SPLIT
- Sammenligning af strengopdelings-/sammenkædningsmetoder
- Løs gamle problemer med SQL Servers nye STRING_AGG- og STRING_SPLIT-funktioner
- Håndtering af enkelttegnsadskilleren i SQL Servers STRING_SPLIT-funktion
- Hjælp venligst med STRING_SPLIT-forbedringer
- En måde at forbedre STRING_SPLIT i SQL Server – og du kan hjælpe
Jeg vil efterlade nedenstående indhold her for eftertiden og historisk relevans, og også fordi noget af testmetoden er relevant for andre problemer bortset fra at opdele strenge, men se venligst nogle af ovenstående referencer for information om, hvordan du skal opdele strenge i moderne, understøttede versioner af SQL Server – såvel som dette indlæg, som forklarer, hvorfor opdeling af strenge måske ikke er et problem, du ønsker, at databasen skal løse i første omgang, ny funktion eller ej.
- Opdeling af strenge:Nu med mindre T-SQL
Jeg ved, at mange mennesker er kede af problemet med "split strenge", men det ser stadig ud til at dukke op næsten dagligt på forum og Q &A-sider som Stack Overflow. Dette er problemet, hvor folk vil sende i en streng som denne:
EXEC dbo.UpdateProfile @UserID = 1, @FavoriteTeams = N'Patriots,Red Sox,Bruins';
Inde i proceduren vil de gøre sådan noget:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (@FavoriteTeams); Dette virker ikke, fordi @FavoriteTeams er en enkelt streng, og ovenstående oversættes til:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots,Red Sox,Bruins'); SQL Server vil derfor forsøge at finde et hold ved navn Patriots,Red Sox,Bruins , og jeg gætter på, at der ikke er et sådant hold. Det, de virkelig ønsker her, svarer til:
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, TeamID
FROM dbo.Teams WHERE TeamName IN (N'Patriots', N'Red Sox', N'Bruins'); Men da der ikke er nogen array-type i SQL Server, er det slet ikke sådan variablen fortolkes – det er stadig en simpel enkelt streng, der tilfældigvis indeholder nogle kommaer. Bortset fra tvivlsomt skemadesign, i dette tilfælde skal den kommaseparerede liste "opdeles" i individuelle værdier - og dette er spørgsmålet, der ofte ansporer til en masse "ny" debat og kommentarer om den bedste løsning til at opnå netop dette.
Svaret synes næsten altid at være, at du skal bruge CLR. Hvis du ikke kan bruge CLR – og jeg ved, at der er mange af jer derude, som ikke kan, på grund af virksomhedspolitik, den spidshårede chef eller stædighed – så bruger du en af de mange løsninger, der findes. Og der findes mange løsninger.
Men hvilken skal du bruge?
Jeg vil sammenligne ydelsen af nogle få løsninger – og fokusere på det spørgsmål, som alle altid stiller:"Hvilken er hurtigst?" Jeg har ikke tænkt mig at uddybe diskussionen omkring *alle* de potentielle metoder, for flere er allerede blevet elimineret på grund af det faktum, at de simpelthen ikke skaleres. Og jeg vil muligvis besøge dette igen i fremtiden for at undersøge indvirkningen på andre målinger, men indtil videre vil jeg kun fokusere på varighed. Her er de konkurrenter, jeg vil sammenligne (ved hjælp af SQL Server 2012, 11.00.2316, på en Windows 7 VM med 4 CPU'er og 8 GB RAM):
CLR
Hvis du ønsker at bruge CLR, bør du helt sikkert låne kode fra andre MVP Adam Machanic, før du tænker på at skrive din egen (jeg har tidligere blogget om at genopfinde hjulet, og det gælder også for gratis kodestykker som dette). Han brugte meget tid på at finjustere denne CLR-funktion for effektivt at analysere en streng. Hvis du i øjeblikket bruger en CLR-funktion, og det ikke er den, anbefaler jeg kraftigt, at du implementerer den og sammenligner – jeg testede den mod en meget enklere, VB-baseret CLR-rutine, der var funktionelt ækvivalent, men VB-tilgangen klarede sig omkring tre gange dårligere end Adams.
Så jeg tog Adams funktion, kompilerede koden til en DLL (ved hjælp af csc) og implementerede netop den fil til serveren. Derefter tilføjede jeg følgende samling og funktion til min database:
CREATE ASSEMBLY CLRUtilities FROM 'c:\DLLs\CLRUtilities.dll' WITH PERMISSION_SET = SAFE; GO CREATE FUNCTION dbo.SplitStrings_CLR ( @List NVARCHAR(MAX), @Delimiter NVARCHAR(255) ) RETURNS TABLE ( Item NVARCHAR(4000) ) EXTERNAL NAME CLRUtilities.UserDefinedFunctions.SplitString_Multi; GO
XML
Dette er den typiske funktion, jeg bruger til engangsscenarier, hvor jeg ved, at inputtet er "sikkert", men det er ikke en, jeg anbefaler til produktionsmiljøer (mere om det nedenfor).
CREATE FUNCTION dbo.SplitStrings_XML
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = y.i.value('(./text())[1]', 'nvarchar(4000)')
FROM
(
SELECT x = CONVERT(XML, '<i>'
+ REPLACE(@List, @Delimiter, '</i><i>')
+ '</i>').query('.')
) AS a CROSS APPLY x.nodes('i') AS y(i)
);
GO En meget stærk advarsel skal følge med XML-tilgangen:den kan kun bruges, hvis du kan garantere, at din inputstreng ikke indeholder ulovlige XML-tegn. Et navn med <,> eller &og funktionen vil sprænges. Så uanset ydeevnen, hvis du vil bruge denne tilgang, skal du være opmærksom på begrænsningerne - det bør ikke betragtes som en levedygtig mulighed for en generisk strengsplitter. Jeg medtager det i denne opsummering, fordi du måske har et tilfælde, hvor du kan stol på inputtet – for eksempel er det muligt at bruge det til kommaseparerede lister over heltal eller GUID'er.
Taltabellen
Denne løsning bruger en Numbers-tabel, som du selv skal bygge og udfylde. (Vi har anmodet om en indbygget version i evigheder.) Numbers-tabellen bør indeholde nok rækker til at overskride længden af den længste streng, du vil opdele. I dette tilfælde vil vi bruge 1.000.000 rækker:
SET NOCOUNT ON;
DECLARE @UpperLimit INT = 1000000;
WITH n AS
(
SELECT
x = ROW_NUMBER() OVER (ORDER BY s1.[object_id])
FROM sys.all_objects AS s1
CROSS JOIN sys.all_objects AS s2
CROSS JOIN sys.all_objects AS s3
)
SELECT Number = x
INTO dbo.Numbers
FROM n
WHERE x BETWEEN 1 AND @UpperLimit;
GO
CREATE UNIQUE CLUSTERED INDEX n ON dbo.Numbers(Number)
WITH (DATA_COMPRESSION = PAGE);
GO (Brug af datakomprimering vil drastisk reducere antallet af krævede sider, men du bør naturligvis kun bruge denne mulighed, hvis du kører Enterprise Edition. I dette tilfælde kræver de komprimerede data 1.360 sider, mod 2.102 sider uden komprimering – omkring en besparelse på 35 %. )
CREATE FUNCTION dbo.SplitStrings_Numbers
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING
AS
RETURN
(
SELECT Item = SUBSTRING(@List, Number,
CHARINDEX(@Delimiter, @List + @Delimiter, Number) - Number)
FROM dbo.Numbers
WHERE Number <= CONVERT(INT, LEN(@List))
AND SUBSTRING(@Delimiter + @List, Number, LEN(@Delimiter)) = @Delimiter
);
GO
Almindelig tabeludtryk
Denne løsning bruger en rekursiv CTE til at udtrække hver del af strengen fra "resten" af den forrige del. Som en rekursiv CTE med lokale variabler vil du bemærke, at dette skulle være en funktion med flere sætninger i tabelværdi, i modsætning til de andre, som alle er inline.
CREATE FUNCTION dbo.SplitStrings_CTE
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS @Items TABLE (Item NVARCHAR(4000))
WITH SCHEMABINDING
AS
BEGIN
DECLARE @ll INT = LEN(@List) + 1, @ld INT = LEN(@Delimiter);
WITH a AS
(
SELECT
[start] = 1,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll),
[value] = SUBSTRING(@List, 1,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, 1), 0), @ll) - 1)
UNION ALL
SELECT
[start] = CONVERT(INT, [end]) + @ld,
[end] = COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll),
[value] = SUBSTRING(@List, [end] + @ld,
COALESCE(NULLIF(CHARINDEX(@Delimiter,
@List, [end] + @ld), 0), @ll)-[end]-@ld)
FROM a
WHERE [end] < @ll ) INSERT @Items SELECT [value] FROM a WHERE LEN([value]) > 0
OPTION (MAXRECURSION 0);
RETURN;
END
GO
Jeff Modens splitter En funktion baseret på Jeff Modens splitter med mindre ændringer for at understøtte længere strenge
Ovenpå SQLServerCentral præsenterede Jeff Moden en splitterfunktion, der konkurrerede med CLR's ydeevne, så jeg tænkte, at det kun var rimeligt at inkludere en variation ved hjælp af en lignende tilgang i denne runde-up. Jeg var nødt til at lave et par mindre ændringer i hans funktion for at kunne håndtere vores længste streng (500.000 tegn), og gjorde også navnekonventionerne ens:
CREATE FUNCTION dbo.SplitStrings_Moden
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH E1(N) AS ( SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1),
E2(N) AS (SELECT 1 FROM E1 a, E1 b),
E4(N) AS (SELECT 1 FROM E2 a, E2 b),
E42(N) AS (SELECT 1 FROM E4 a, E2 b),
cteTally(N) AS (SELECT 0 UNION ALL SELECT TOP (DATALENGTH(ISNULL(@List,1)))
ROW_NUMBER() OVER (ORDER BY (SELECT NULL)) FROM E42),
cteStart(N1) AS (SELECT t.N+1 FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0))
SELECT Item = SUBSTRING(@List, s.N1, ISNULL(NULLIF(CHARINDEX(@Delimiter,@List,s.N1),0)-s.N1,8000))
FROM cteStart s; Som en sidebemærkning, for dem, der bruger Jeff Modens løsning, kan du overveje at bruge en taltabel som ovenfor og eksperimentere med en lille variation af Jeffs funktion:
CREATE FUNCTION dbo.SplitStrings_Moden2
(
@List NVARCHAR(MAX),
@Delimiter NVARCHAR(255)
)
RETURNS TABLE
WITH SCHEMABINDING AS
RETURN
WITH cteTally(N) AS
(
SELECT TOP (DATALENGTH(ISNULL(@List,1))+1) Number-1
FROM dbo.Numbers ORDER BY Number
),
cteStart(N1) AS
(
SELECT t.N+1
FROM cteTally t
WHERE (SUBSTRING(@List,t.N,1) = @Delimiter OR t.N = 0)
)
SELECT Item = SUBSTRING(@List, s.N1,
ISNULL(NULLIF(CHARINDEX(@Delimiter, @List, s.N1), 0) - s.N1, 8000))
FROM cteStart AS s; (Dette vil bytte lidt højere læsninger for lidt lavere CPU, så det kan være bedre afhængigt af om dit system allerede er CPU- eller I/O-bundet.)
Fornuftskontrol
Bare for at være sikker på, at vi er på rette vej, kan vi bekræfte, at alle fem funktioner returnerer de forventede resultater:
DECLARE @s NVARCHAR(MAX) = N'Patriots,Red Sox,Bruins'; SELECT Item FROM dbo.SplitStrings_CLR (@s, N','); SELECT Item FROM dbo.SplitStrings_XML (@s, N','); SELECT Item FROM dbo.SplitStrings_Numbers (@s, N','); SELECT Item FROM dbo.SplitStrings_CTE (@s, N','); SELECT Item FROM dbo.SplitStrings_Moden (@s, N',');
Og faktisk er det de resultater, vi ser i alle fem tilfælde...

Testdataene
Nu hvor vi ved, at funktionerne opfører sig som forventet, kan vi komme til den sjove del:test af ydeevne mod forskellige antal strenge, der varierer i længde. Men først skal vi have et bord. Jeg oprettede følgende enkle objekt:
CREATE TABLE dbo.strings ( string_type TINYINT, string_value NVARCHAR(MAX) ); CREATE CLUSTERED INDEX st ON dbo.strings(string_type);
Jeg udfyldte denne tabel med et sæt strenge af varierende længde, og sørgede for, at nogenlunde det samme sæt data ville blive brugt til hver test – først 10.000 rækker, hvor strengen er 50 tegn lang, derefter 1.000 rækker, hvor strengen er 500 tegn lang , 100 rækker, hvor strengen er 5.000 tegn lang, 10 rækker, hvor strengen er 50.000 tegn lang, og så videre op til 1 række med 500.000 tegn. Jeg gjorde dette både for at sammenligne den samme mængde overordnede data, der behandles af funktionerne, samt for at forsøge at holde mine testtider noget forudsigelige.
Jeg bruger en #temp-tabel, så jeg simpelthen kan bruge GO
SET NOCOUNT ON; GO CREATE TABLE #x(s NVARCHAR(MAX)); INSERT #x SELECT N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; GO INSERT dbo.strings SELECT 1, s FROM #x; GO 10000 INSERT dbo.strings SELECT 2, REPLICATE(s,10) FROM #x; GO 1000 INSERT dbo.strings SELECT 3, REPLICATE(s,100) FROM #x; GO 100 INSERT dbo.strings SELECT 4, REPLICATE(s,1000) FROM #x; GO 10 INSERT dbo.strings SELECT 5, REPLICATE(s,10000) FROM #x; GO DROP TABLE #x; GO -- then to clean up the trailing comma, since some approaches treat a trailing empty string as a valid element: UPDATE dbo.strings SET string_value = SUBSTRING(string_value, 1, LEN(string_value)-1) + 'x';
Oprettelse og udfyldning af denne tabel tog omkring 20 sekunder på min maskine, og tabellen repræsenterer omkring 6 MB værdi af data (ca. 500.000 tegn gange 2 bytes eller 1 MB pr. streng_type plus række- og indeksoverhead). Ikke et stort bord, men det skal være stort nok til at fremhæve eventuelle forskelle i ydeevne mellem funktionerne.
Testene
Med funktionerne på plads og bordet ordentligt proppet med store snore at tygge på, kan vi endelig køre nogle faktiske tests for at se, hvordan de forskellige funktioner klarer sig i forhold til rigtige data. For at måle ydeevne uden at tage højde for netværksomkostninger brugte jeg SQL Sentry Plan Explorer, hvor jeg kørte hvert sæt test 10 gange, indsamlede varighedsmålingerne og beregnede gennemsnit.
Den første test trak simpelthen emnerne fra hver streng som et sæt:
DBCC DROPCLEANBUFFERS; DBCC FREEPROCCACHE; DECLARE @string_type TINYINT = ; -- 1-5 from above SELECT t.Item FROM dbo.strings AS s CROSS APPLY dbo.SplitStrings_(s.string_value, ',') AS t WHERE s.string_type = @string_type;
Resultaterne viser, at når strengene bliver større, skinner fordelen ved CLR virkelig. I den nederste ende var resultaterne blandede, men igen skulle XML-metoden have en stjerne ved siden af, da dens brug afhænger af XML-sikker input. For denne specifikke brugssituation klarede Numbers-tabellen sig konsekvent dårligst:
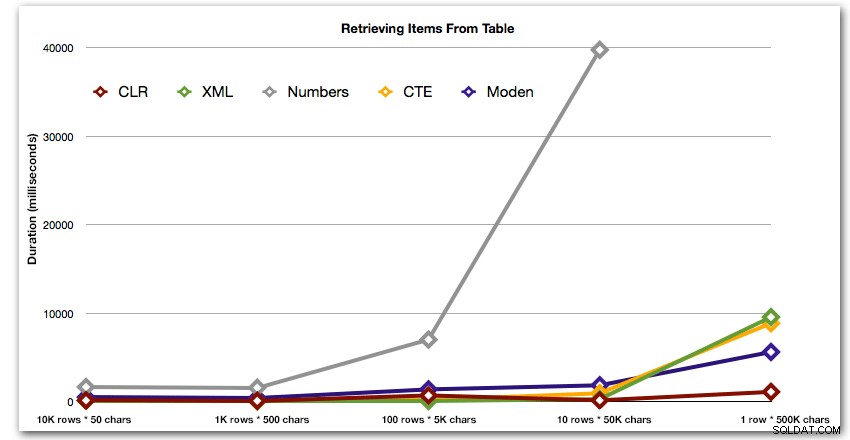
Varighed i millisekunder
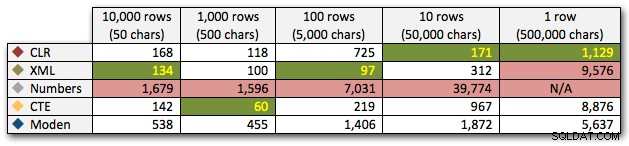
Efter den hyperbolske 40-sekunders ydeevne for taltabellen mod 10 rækker med 50.000 tegn, droppede jeg den fra at køre til den sidste test. For bedre at vise den relative ydeevne af de fire bedste metoder i denne test, har jeg helt droppet Numbers-resultaterne fra grafen:
Lad os derefter sammenligne, når vi udfører en søgning mod den kommaseparerede værdi (f.eks. returner de rækker, hvor en af strengene er 'foo'). Igen vil vi bruge de fem funktioner ovenfor, men vi vil også sammenligne resultatet med en søgning, der udføres under kørslen ved hjælp af LIKE i stedet for at genere opdelingen.
DBCC DROPCLEANBUFFERS;
DBCC FREEPROCCACHE;
DECLARE @i INT = , @search NVARCHAR(32) = N'foo';
;WITH s(st, sv) AS
(
SELECT string_type, string_value
FROM dbo.strings AS s
WHERE string_type = @i
)
SELECT s.string_type, s.string_value FROM s
CROSS APPLY dbo.SplitStrings_(s.sv, ',') AS t
WHERE t.Item = @search;
SELECT s.string_type
FROM dbo.strings
WHERE string_type = @i
AND ',' + string_value + ',' LIKE '%,' + @search + ',%'; Disse resultater viser, at for små strenge var CLR faktisk den langsomste, og at den bedste løsning vil være at udføre en scanning ved hjælp af LIKE, uden overhovedet at bryde med at dele dataene op. Igen droppede jeg Numbers-tabelløsningen fra den 5. tilgang, da det var klart, at dens varighed ville stige eksponentielt, efterhånden som størrelsen af strengen steg:
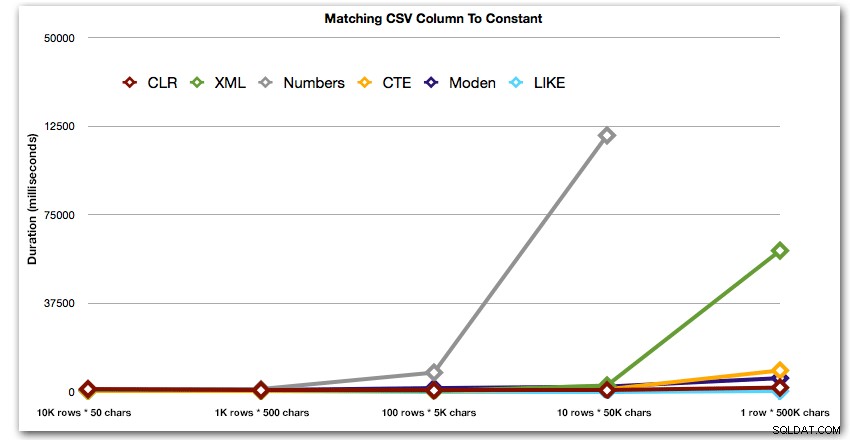
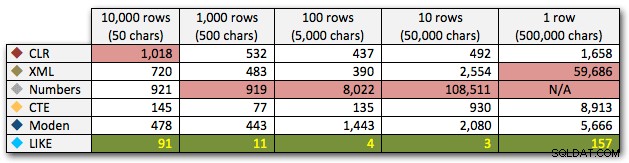
Varighed i millisekunder
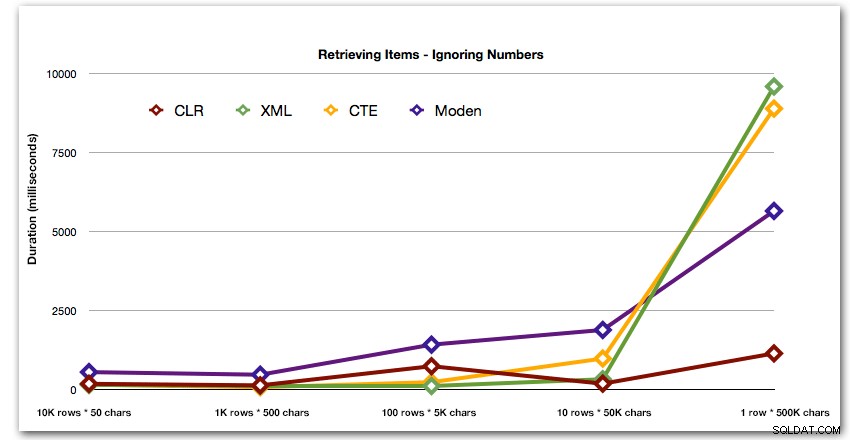
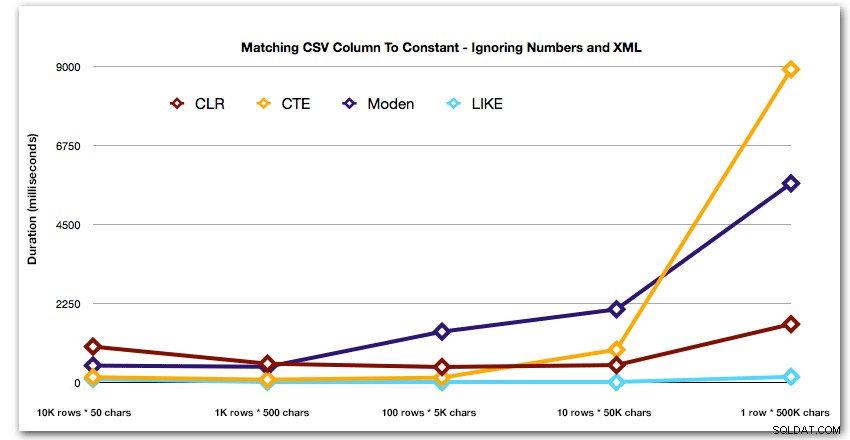
Og for bedre at demonstrere mønstrene for de 4 bedste resultater, har jeg fjernet tal- og XML-løsningerne fra grafen:
Lad os dernæst se på at replikere use casen fra begyndelsen af dette indlæg, hvor vi forsøger at finde alle rækkerne i én tabel, der findes i listen, der sendes ind. Som med dataene i tabellen, vi oprettede ovenfor, 'kommer til at oprette strenge, der varierer i længde fra 50 til 500.000 tegn, gemme dem i en variabel og derefter kontrollere, om en fælles katalogvisning findes på listen.
DECLARE
@i INT = , -- value 1-5, yielding strings 50 - 500,000 characters
@x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,';
SET @x = REPLICATE(@x, POWER(10, @i-1));
SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x';
SELECT c.[object_id]
FROM sys.all_columns AS c
WHERE EXISTS
(
SELECT 1 FROM dbo.SplitStrings_(@x, N',') AS x
WHERE Item = c.name
)
ORDER BY c.[object_id];
SELECT [object_id]
FROM sys.all_columns
WHERE N',' + @x + ',' LIKE N'%,' + name + ',%'
ORDER BY [object_id]; Disse resultater viser, at for dette mønster ser flere metoder deres varighed øges eksponentielt, efterhånden som størrelsen af strengen stiger. I den nederste ende holder XML godt trit med CLR, men dette forværres også hurtigt. CLR er konsekvent den klare vinder her:
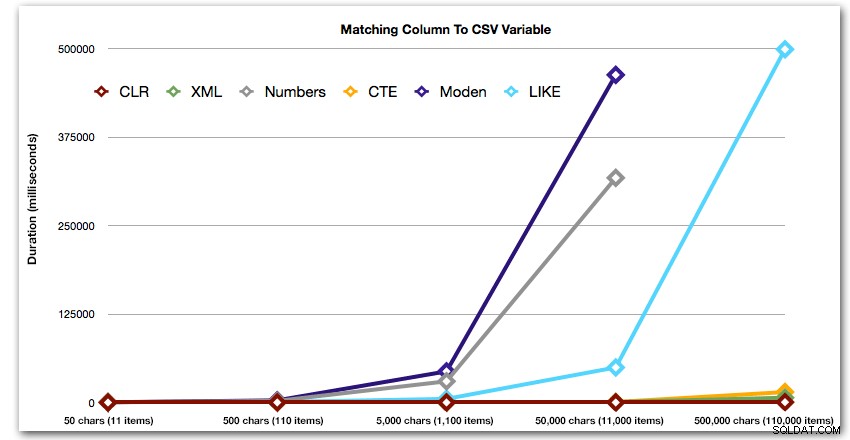
Varighed i millisekunder
Og igen uden de metoder, der eksploderer opad i forhold til varighed:
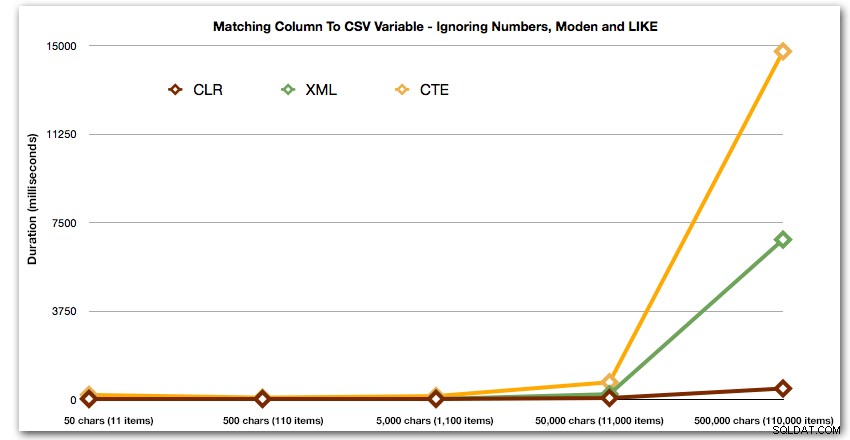
Lad os endelig sammenligne omkostningerne ved at hente data fra en enkelt variabel af varierende længde, idet vi ignorerer omkostningerne ved at læse data fra en tabel. Igen genererer vi strenge af varierende længde, fra 50 – 500.000 tegn, og returnerer derefter værdierne som et sæt:
DECLARE @i INT = , -- value 1-5, yielding strings 50 - 500,000 characters @x NVARCHAR(MAX) = N'a,id,xyz,abcd,abcde,sa,foo,bar,mort,splunge,bacon,'; SET @x = REPLICATE(@x, POWER(10, @i-1)); SET @x = SUBSTRING(@x, 1, LEN(@x)-1) + 'x'; SELECT Item FROM dbo.SplitStrings_(@x, N',');
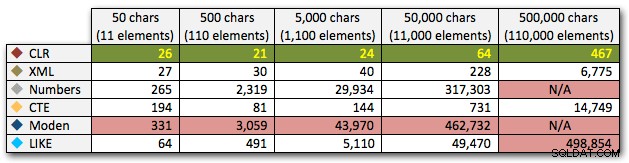
Disse resultater viser også, at CLR er ret flad-linet med hensyn til varighed, helt op til 110.000 genstande i sættet, mens de andre metoder holder pænt tempo indtil nogen tid efter 11.000 genstande:
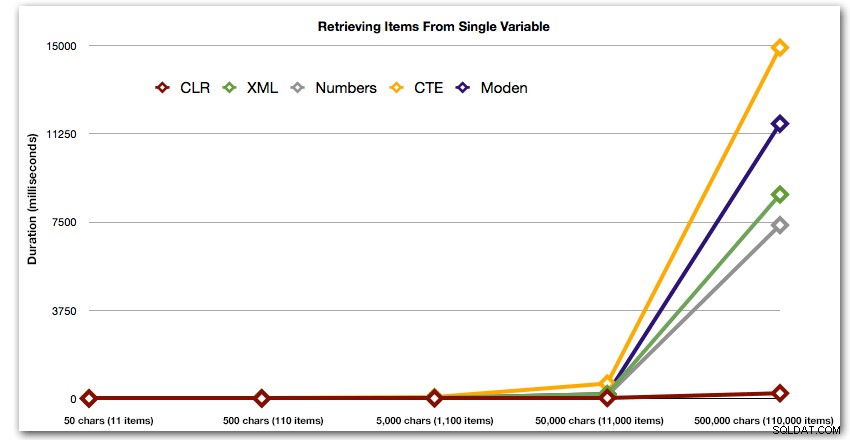
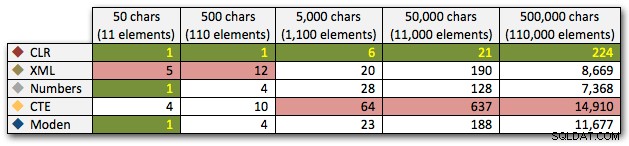
Varighed i millisekunder
Konklusion
I næsten alle tilfælde overgår CLR-løsningen klart de andre tilgange – i nogle tilfælde er det en jordskredssejr, især når strengstørrelserne øges; i nogle få andre er det en fotofinish, der kan falde begge veje. I den første test så vi, at XML og CTE præsterede CLR i den lave ende, så hvis dette er en typisk use case *og* du er sikker på, at dine strenge er i intervallet 1 – 10.000 tegn, kan en af disse tilgange muligvis være en bedre mulighed. Hvis dine strengstørrelser er mindre forudsigelige end det, er CLR nok stadig din bedste indsats generelt – du taber et par millisekunder i den lave ende, men du vinder en hel del i den høje ende. Her er de valg, jeg ville træffe, afhængigt af opgaven, med andenpladsen fremhævet for tilfælde, hvor CLR ikke er en mulighed. Bemærk, at XML kun er min foretrukne metode, hvis jeg ved, at inputtet er XML-sikkert; disse er måske ikke nødvendigvis dine bedste alternativer, hvis du har mindre tillid til dit input.
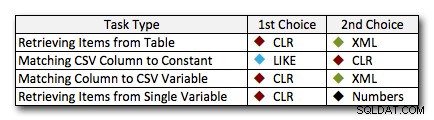
Den eneste virkelige undtagelse, hvor CLR ikke er mit valg over hele linjen, er tilfældet, hvor du faktisk gemmer kommaseparerede lister i en tabel og derefter finder rækker, hvor en defineret enhed er på listen. I det specifikke tilfælde vil jeg nok først anbefale at redesigne og normalisere skemaet korrekt, så disse værdier gemmes separat, i stedet for at bruge det som en undskyldning for ikke at bruge CLR til opdeling.
Hvis du ikke kan bruge CLR af andre årsager, er der ikke en entydig "andenplads" afsløret af disse tests; mine svar ovenfor var baseret på overordnet skala og ikke på nogen specifik strengstørrelse. Hver løsning her var nummer to i mindst ét scenarie – så selvom CLR klart er valget, hvornår du kan bruge det, er hvad du skal bruge, når du ikke kan det, mere et "det afhænger af"-svar – du bliver nødt til at bedømme baseret på dit(e) use case(r) og testene ovenfor (eller ved at konstruere dine egne tests), hvilket alternativ er bedre for dig.
Tillæg :Et alternativ til opdeling i første omgang
Ovenstående tilgange kræver ingen ændringer af din(e) eksisterende applikation(er), forudsat at de allerede samler en kommasepareret streng og smider den til databasen for at håndtere. En mulighed, du bør overveje, hvis enten CLR ikke er en mulighed, og/eller du kan ændre applikationen/applikationerne, er at bruge Table-Valued Parameters (TVP'er). Her er et hurtigt eksempel på, hvordan man bruger en TVP i ovenstående sammenhæng. Først skal du oprette en tabeltype med en enkelt strengkolonne:
CREATE TYPE dbo.Items AS TABLE ( Item NVARCHAR(4000) );
Så kan den lagrede procedure tage denne TVP som input og tilslutte sig indholdet (eller bruge det på andre måder – dette er kun et eksempel):
CREATE PROCEDURE dbo.UpdateProfile
@UserID INT,
@TeamNames dbo.Items READONLY
AS
BEGIN
SET NOCOUNT ON;
INSERT dbo.UserTeams(UserID, TeamID) SELECT @UserID, t.TeamID
FROM dbo.Teams AS t
INNER JOIN @TeamNames AS tn
ON t.Name = tn.Item;
END
GO Nu i din C#-kode, for eksempel, i stedet for at bygge en kommasepareret streng, skal du udfylde en datatabel (eller bruge en hvilken som helst kompatibel samling, der allerede kan indeholde dit sæt værdier):
DataTable tvp = new DataTable();
tvp.Columns.Add(new DataColumn("Item"));
// in a loop from a collection, presumably:
tvp.Rows.Add(someThing.someValue);
using (connectionObject)
{
SqlCommand cmd = new SqlCommand("dbo.UpdateProfile", connectionObject);
cmd.CommandType = CommandType.StoredProcedure;
SqlParameter tvparam = cmd.Parameters.AddWithValue("@TeamNames", tvp);
tvparam.SqlDbType = SqlDbType.Structured;
// other parameters, e.g. userId
cmd.ExecuteNonQuery();
} Du kan måske betragte dette som en prequel til et opfølgende indlæg.
Dette spiller selvfølgelig ikke godt sammen med JSON og andre API'er – ret ofte grunden til, at en kommasepareret streng sendes til SQL Server i første omgang.