Er du nogensinde stødt på en situation, hvor du har brug for at styre en enheds tilstand, der ændrer sig over tid? Der er mange eksempler derude. Lad os starte med en nem en:flette kunderegistreringer.
Antag, at vi slår lister over kunder fra to forskellige kilder sammen. Vi kunne have en af følgende tilstande opstået:Dubletter identificeret – systemet har fundet to potentielt duplikerede enheder; Bekræftede dubletter – en bruger validerer, at de to enheder faktisk er dubletter; eller Bekræftet unik – brugeren beslutter, at de to enheder er unikke. I enhver af disse situationer har brugeren kun en ja-nej-beslutning at træffe.
Men hvad med mere komplekse situationer? Er der en måde at definere den faktiske arbejdsgang mellem stater? Læs videre...
Hvordan ting nemt kan gå galt
Mange organisationer har brug for at administrere jobansøgninger. I en simpel model kunne du have en tabel kaldet JOB_APPLICATION , og du kan spore applikationens tilstand ved hjælp af en referencedatatabel, der indeholder værdier som disse:
| Applikationsstatus |
|---|
APPLICATION_RECEIVED |
APPLICATION_UNDER_REVIEW |
APPLICATION_REJECTED |
INVITED_TO_INTERVIEW |
INVITATION_DECLINED |
INVITATION_ACCEPTED |
INTERVIEW_PASSED |
INTERVIEW_FAILED |
REFERENCES_SOUGHT |
REFERENCES_ACCEPTABLE |
REFERENCES_UNACCEPTABLE |
JOB_OFFER_MADE |
JOB_OFFER_ACCEPTED |
JOB_OFFER_DECLINED |
APPLICATION_CLOSED |
Disse værdier kan til enhver tid vælges i enhver rækkefølge. Den er afhængig af slutbrugerne for at sikre, at der foretages et logisk og korrekt valg på hvert trin. Intet forbyder en ulogisk sekvens af tilstande.
Lad os for eksempel sige, at en ansøgning er blevet afvist. Den aktuelle status ville naturligvis være APPLICATION_REJECTED . Der er intet, der kan gøres på applikationsniveau for at forhindre en uerfaren bruger i efterfølgende at vælge INVITED_TO_INTERVIEW eller en anden ulogisk tilstand.
Det, der er brug for, er noget til at guide brugeren til at vælge den næste logiske tilstand, noget der definerer en logisk arbejdsgang .
Og hvad hvis du har forskellige krav til forskellige typer jobansøgninger? For eksempel kan nogle job kræve, at ansøgeren skal tage en egnethedsprøve. Selvfølgelig kan du tilføje flere værdier til listen for at dække disse, men der er intet i det nuværende design, der forhindrer slutbrugeren i at foretage et forkert valg for den pågældende type applikation. Virkeligheden er, at der er forskellige arbejdsgange til forskellige sammenhænge .
Et andet punkt at tænke over:er de anførte muligheder virkelig alle stater ? Eller er nogle faktisk resultater ? Eksempelvis kan tilbuddet om et job accepteres eller afvises af ansøgeren. Derfor JOB_OFFER_MADE har virkelig to resultater:JOB_OFFER_ACCEPTED og JOB_OFFER_DECLINED .
Et andet resultat kunne være, at et jobtilbud trækkes tilbage. Du ønsker måske at registrere årsagen til, at den blev trukket tilbage ved hjælp af en kvalifikation. Hvis du blot tilføjer disse grunde til ovenstående liste, guider intet slutbrugeren til at foretage logiske valg.
Så jo mere komplekse tilstande, resultater og kvalifikationer bliver, jo mere skal du definere arbejdsgangen af en proces .
Organisering af processer, tilstande og resultater
Det er vigtigt at forstå, hvad der sker med dine data, før du forsøger at modellere dem. Du kan i første omgang være tilbøjelig til at tro, at der er et strengt hierarki af typer her:
Når vi ser nærmere på ovenstående eksempel, ser vi, at INVITED_TO_INTERVIEW og JOB_OFFER_MADE stater deler de samme mulige udfald, nemlig ACCEPTERET og AFVISET . Dette fortæller os, at der er et mange-til-mange forhold mellem tilstande og resultater. Dette gælder ofte for andre stater, resultater og kvalifikationer.
På et konceptuelt niveau er det altså, hvad der faktisk foregår med vores metadata:
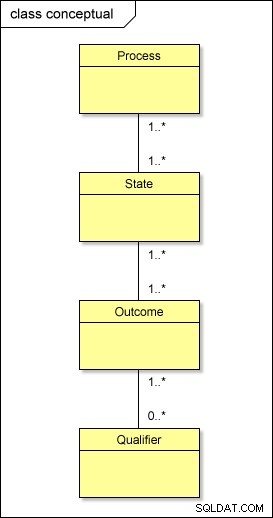
Hvis du skulle transformere denne model til den fysiske verden ved hjælp af standardtilgangen, ville du have tabeller kaldet PROCESS , STAT , RESULTAT , og QUALIFIER ; du skal også have mellemliggende tabeller mellem dem – PROCESS_STATE , STATE_OUTCOME , og OUTCOME_QUALIFIER – at løse mange-til-mange-relationerne . Dette komplicerer designet.
Mens det logiske hierarki af niveauer (proces → tilstand → resultat → kvalifikation) skal opretholdes, er der en enklere måde at organisere vores metadata fysisk på.
Workflow-mønsteret
Diagrammet nedenfor definerer hovedkomponenterne i en workflow-databasemodel:
De gule tabeller til venstre indeholder workflowmetadata, og de blå tabeller til højre indeholder forretningsdata.
Den første ting at påpege er, at enhver enhed kan administreres uden at kræve større ændringer af denne model. JOB_APPLICATION bord.
Dernæst skal vi blot tilføje wf_state_type_process_id kolonne til den tabel, vi ønsker at administrere. Denne kolonne peger på den faktiske arbejdsgang proces bruges til at administrere enheden. Dette er ikke udelukkende en fremmednøglekolonne, men det giver os mulighed for hurtigt at forespørge WORKFLOW_STATE_TYPE for den korrekte proces. Tabellen, der vil indeholde tilstandshistorikken er MANAGED_ENTITY_STATE . Igen, du ville vælge dit eget specifikke tabelnavn her og ændre det efter dine egne behov.
Metadataene
De forskellige niveauer af arbejdsgange er defineret i WORKFLOW_LEVEL_TYPE . Denne tabel indeholder følgende:
| Typenøgle | Beskrivelse |
|---|---|
| PROCES | Workflowproces på højt niveau. |
| STAT | En tilstand i processen. |
| RESULTAT | Hvordan en stat ender, dens udfald. |
| QUALIFIER | En valgfri, mere detaljeret kvalifikation til et resultat. |
WORKFLOW_STATE_TYPE og WORKFLOW_STATE_HIERARCHY danne en klassisk styklistestruktur . Denne struktur, som er meget beskrivende for en faktisk fremstillingsstykliste, er ret almindelig i datamodellering. Det kan definere hierarkier eller anvendes på mange rekursive situationer. Vi vil bruge det her til at definere vores logiske hierarki af processer, tilstande, resultater og valgfrie kvalifikationer.
Før vi kan definere et hierarki, skal vi definere de enkelte komponenter. Det er vores grundlæggende byggesten. Jeg vil bare henvise til disse ved hjælp af TYPE_KEY (hvilket er unikt) for korthedens skyld. For vores eksempel har vi:
| Workflow Level Type | Workflow State Type.Type Key |
|---|---|
| RESULTAT | Bestået |
| RESULTAT | FEJLDE |
| RESULTAT | ACCEPTERET |
| RESULTAT | AFSLAG |
| RESULTAT | CANDIDATE_CANCELLED |
| RESULTAT | EMPLOYER_CANCELLED |
| RESULTAT | AFVISET |
| RESULTAT | EMPLOYER_WITHDRAWN |
| RESULTAT | NO_SHOW |
| RESULTAT | LEJET |
| RESULTAT | NOT_HIRED |
| STAT | APPLICATION_RECEIVED |
| STAT | APPLICATION_REVIEW |
| STAT | INVITED_TO_INTERVIEW |
| STAT | INTERVIEW |
| STAT | TEST_APTITUDE |
| STAT | SEEK_REFERENCES |
| STAT | MAKE_OFFER |
| STAT | APPLICATION_CLOSED |
| BEHANDLING | STANDARD_JOB_APPLICATION |
| BEHANDLING | TECHNICAL_JOB_APPLICATION |
Nu kan vi begynde at definere vores hierarki. Det er her, vi tager vores byggeklodser og definerer vores struktur. For hver stat definerer vi de mulige resultater. Faktisk er det en regel i dette workflow-system, at hver tilstand skal afsluttes med et resultat:
| Forældretype – STATE | Barnetype – RESULTATER |
|---|---|
| APPLICATION_RECEIVED | ACCEPTERET |
| APPLICATION_RECEIVED | AFVISET |
| APPLICATION_REVIEW | Bestået |
| APPLICATION_REVIEW | FEJLDE |
| INVITED_TO_INTERVIEW | ACCEPTERET |
| INVITED_TO_INTERVIEW | AFSLAG |
| INTERVIEW | Bestået |
| INTERVIEW | FEJLDE |
| INTERVIEW | CANDIDATE_CANCELLED |
| INTERVIEW | NO_SHOW |
| MAKE_OFFER | ACCEPTERET |
| MAKE_OFFER | AFSLAG |
| SEEK_REFERENCES | Bestået |
| SEEK_REFERENCES | FEJLDE |
| APPLICATION_CLOSED | LEJET |
| APPLICATION_CLOSED | NOT_HIRED |
| TEST_APTITUDE | Bestået |
| TEST_APTITUDE | FEJLDE |
Vores processer er simpelthen et sæt tilstande, der hver især eksisterer i en periode. I tabellen nedenfor er de præsenteret i en logisk rækkefølge, men dette definerer ikke den faktiske rækkefølge for behandling.
| Forældretype – PROCESSER | Child Type – STATES |
|---|---|
| STANDARD_JOB_APPLICATION | APPLICATION_RECEIVED |
| STANDARD_JOB_APPLICATION | APPLICATION_REVIEW |
| STANDARD_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| STANDARD_JOB_APPLICATION | INTERVIEW |
| STANDARD_JOB_APPLICATION | MAKE_OFFER |
| STANDARD_JOB_APPLICATION | SEEK_REFERENCES |
| STANDARD_JOB_APPLICATION | APPLICATION_CLOSED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_RECEIVED |
| TECHNICAL_JOB_APPLICATION | APPLICATION_REVIEW |
| TECHNICAL_JOB_APPLICATION | INVITED_TO_INTERVIEW |
| TECHNICAL_JOB_APPLICATION | TEST_APTITUDE |
| TECHNICAL_JOB_APPLICATION | INTERVIEW |
| TECHNICAL_JOB_APPLICATION | MAKE_OFFER |
| TECHNICAL_JOB_APPLICATION | SEEK_REFERENCES |
| TECHNICAL_JOB_APPLICATION | APPLICATION_CLOSED |
Der er en vigtig pointe at gøre med et styklistehierarki. Ligesom en fysisk stykliste definerer samlinger og undersamlinger ned til de mindste komponenter, har vi et lignende arrangement i vores hierarki. Det betyder, at vi kommer til at genbruge ’samlinger’ og ’undersamlinger’.
Som eksempel:Både STANDARD_JOB_APPLICATION og TECHNICAL_JOB_APPLICATION processer har INTERVIEW stat . Til gengæld er INTERVIEW stat har PASSED , FEJLDE , CANDIDATE_CANCELLED og NO_SHOW resultater defineret til det.
Når du bruger en tilstand i en proces, får du automatisk dens underordnede resultater med den, fordi den allerede er en samling. Det betyder, at de samme resultater eksisterer for begge typer jobansøgninger ved INTERVIEW scene. Hvis du ønsker forskellige samtaleresultater for forskellige typer jobansøgninger, skal du definere f.eks. TECHNICAL_INTERVIEW og STANDARD_INTERVIEW angiver, at hver har deres egne specifikke resultater.
I dette eksempel er den eneste forskel mellem de to typer jobansøgninger, at en teknisk jobansøgning indeholder en egnethedstest.
Før du går
Del 1 af denne todelte artikel har introduceret workflowdatabasemønsteret. Det har vist, hvordan du kan inkorporere det for at administrere livscyklussen for enhver enhed i din database.
Del 2 viser dig hvordan du definerer den faktiske arbejdsgang ved hjælp af yderligere konfigurationstabeller. Det er her, brugeren vil blive præsenteret for tilladte næste trin. Vi vil også demonstrere en teknik til at omgå den strenge genbrug af 'samlinger' og 'undersamlinger' i styklister.