Dette er den tredje af vores flerdelte serie om anvendelse af informationssikkerhedstilgange til datamodellering. Serien bruger en simpel datamodel, noget til at styre sociale klubber og interessegrupper, for at levere det indhold, vi ønsker at sikre. Senere vil vi behandle modellering for autorisation og brugerstyring samt andre dele af en sikker databaseimplementering.
I sociale situationer er det almindeligt at "læse mellem linjerne" - udlede de uudtalte antagelser og påstande i en samtale. Det samme sker ved oprettelse af software og lagring af data i en database. Fakturaer er opregnet med kunde-id'et indlejret, og hvor mange dataenheder bruger en dato-tid som en del af nøglen? Det er svært at forestille sig grundigt at dokumentere eller strukturere alt uden en form for udeladelse. Men i vores sidste omgang gennemgik vi netop den øvelse. Vi var i stand til at tilskrive følsomhed til flere dele af vores sociale klubdatabase. Men for at kvantificere og håndtere denne følsomhed skal vi udvide strukturen af vores datamodel for at gøre de følsomme data og deres relationer tydelige.
Lukning af huller i datamodel
Datamodellering for sikkerhed nødvendiggør adskillige forskellige varianter af strukturændringer. Vi udforsker disse igen ved at bruge en (meget!) enkel social klubdatamodel som vores base for denne serie. Efterhånden som vi er kommet videre, har vi forbedret modellen med flere data. I den sidste rate analyserede vi modellen for at tilskrive datafølsomhed, hvor vi fandt den. Denne analyse også afslørede, at der var steder, hvor datamodellen indikerede links, der faktisk ikke var fanget eksplicit i kolonner og nøglerelationer. Modelbyggeren bør forvente dette i en sikkerhedsanalyse. Når vi går videre fra disse opdagelser, vil vi gøre disse relationer så konkrete og klare som muligt ved at udbygge tabellerne og forbindelserne mellem dem. Dette vil give os mulighed for at tilføje sikkerhedsattributter længere fremme.
Udbygning af datarelationer i klubben
Alle relationerne i dataene, såvel som selve dataenhederne, skal have en vis repræsentation for at tillægge dem værdi eller følsomhed. Nye kolonner, nye nøgler, nye referencer, endda nye tabeller kan være nødvendige for at opnå dette. Da vi analyserede tabellerne og deres relationer i vores sidste indlæg, isolerede vi to hovedtabeller med højfølsomme data:
PersonPhoto
Derudover havde vi fire, der indeholdt data, der var moderat følsomme:
MemberClubOfficeClub_Office
Disse aspekter af følsomhed er delvist iboende for hver tabel, men ikke-eksplicitte relationer bærer meget af følsomheden. For at vedhæfte det begynder vi at registrere relationerne og give dem en struktur til at indeholde følsomheden.
Relationer integreret i billeder
Photo indeholder en masse indlejrede relationer, vi skal fange. Vi er primært interesserede i forholdet til Person . For at fange person-foto-forholdet tilføjer jeg Photo_Content tabel:
Der er mange forskellige aspekter, hvorved en Person kan relatere til et Photo . Jeg besluttede at tilføje en ny tabel, Photo_Content_Role , for at karakterisere forholdet mellem et billede og en person. I stedet for at have separate tabeller for hver slags relation, bruger vi en enkelt forbindelsestabel og tabellen Photo_Content_Role. Denne tabel er en referenceliste med standardforhold som det, vi allerede har noteret. Her er vores indledende datasæt for Photo_Content_Role :
| Etiket | Maks pr. person | Beskrivelse |
|---|---|---|
| Fotograf | 1 | Den person, der faktisk tog billedet |
| Afbildet person | 1 | En person, der kan genkendes på billedet |
| Ophavsretsejer | 1 | En person, der har ophavsretten til billedet |
| Licensgiver | 1 | En part, der har givet klubben licens til at bruge dette billede |
| Ophavsretsmægler | 1 | En part, der har løst problemer med ophavsret for dette billede |
| Objekt afbildet | ubegrænset | content_headline identificerer objektet, content_detailed uddyber det |
| Kommentar | ubegrænset |
OK, så dette er en agn-og-switch. Jeg sagde Photo_Content ville relatere mennesker til billeder, så hvorfor er der noget om "objekt afbildet"? Logisk set vil der være billeder, hvor vi vil beskrive indholdet uden at identificere en Person . Skal jeg tilføje en anden tabel til dette, med et separat sæt indholdsroller? Jeg besluttede ikke. I stedet vil jeg tilføje en nul personrække til Person tabel som frødata, og har ikke-personindhold henvise til den pågældende person. (Ja, programmører, det er lidt mere arbejde. I er velkomne.) 'Null Person' vil have id nul (0).
Nøglelæring nr. 1:
Minimer tabeller med følsomme data ved at overlejre lignende relationsstrukturer i en enkelt tabel.
Jeg forventer, at der kan være yderligere relationer, der vil blive opdaget nedstrøms. Og det er også muligt, at en social klub kan have sine egne roller at tildele en Person i et Foto . Af den grund har jeg brugt en 'ren' surrogat primærnøgle til Photo_Content_Role , og tilføjede også en valgfri fremmednøgle til Club . Dette vil give os mulighed for at støtte særlige anvendelser af individuelle klubber. Jeg kalder feltet 'eksklusivt' for at angive, at det ikke bør være tilgængeligt for andre klubber.
Nøglelæring nr. 2:
Når slutbrugere måske udvider en indbygget liste, så giv dens tabel en ren surrogatnøgle for at undgå datakollisioner.
Photo_Content_Role.max_per_person kan også være mystisk. Du kan ikke se det i diagrammet, men Photo_Content_Role.id bærer sin egen unikke begrænsning uden max_per_person . I bund og grund er den egentlige primære nøgle bare id . Ved at tilføje max_per_person til id i den primære nøgle tvinger jeg hver henvisende tabel til at optage information, hvormed den kan (bør!) håndhæve en kardinalitetskontrolbegrænsning. Her er kontrolbegrænsningen i Photo_Content .
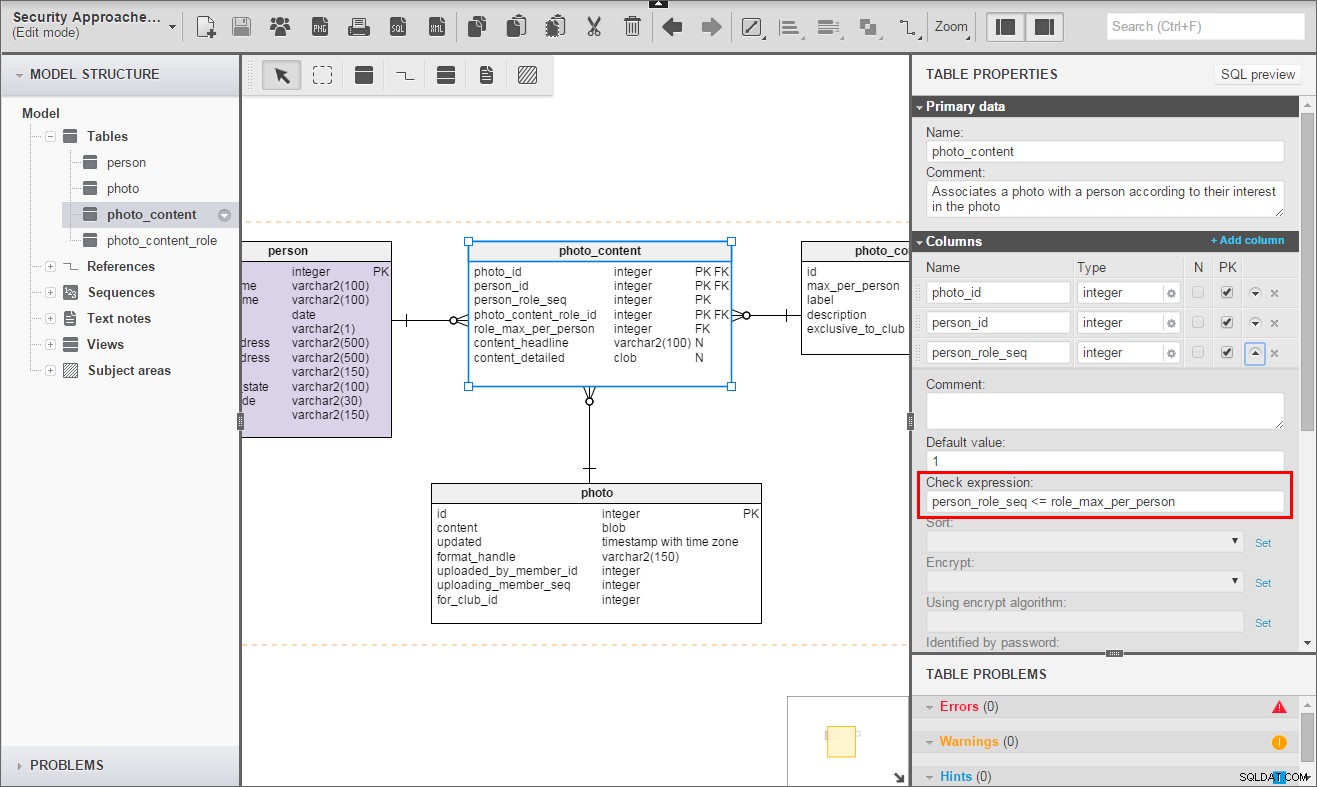
Nøglelæring nr. 3:
Når hver række i en tabel har individuelle begrænsninger, skal henvisende tabeller tilføje en ny unik begrænsning, der udvider en naturlig nøgle med begrænsningsfelterne. Få den underordnede tabel til at henvise til den nøgle.
Lad os se lidt mere på Photo_Content . Dette er primært et forhold mellem Photo og Person , med forholdet angivet af den vedhæftede indholdsrolle. Som jeg bemærkede før, er det dog her, vi gemmer alt beskrivende oplysninger om billedet. For at imødekomme denne form for åbenhed har vi den valgfrie content_headline og content_detailed kolonner. Disse vil sjældent være nødvendige for en almindelig forbindelse mellem en person og et foto. Men en overskrift som 'Bob Januskis modtager den årlige præstationspris' er let at forudse. Også hvis der ikke er nogen person - 'Objekt afbildet', Person 0 — vi skal kræve noget i content_headline , såsom 'Northwest Slope of Mt. Ararat.'
Det sidste manglende fotoforhold:Albums
Indtil videre har vi ikke tilføjet noget, der relaterer Photo s til Photo s. Det er en stor ting for sociale netværk og fototjenester:Album s. Og du vil ikke have dem i den velkendte skoæske, vel? Så lad os udfylde dette grelle hul - men lad os også tænke over det.
Album vedhæfter Photo er på en anden måde end de andre forhold, vi har dækket. Photo s kan være tilknyttet den samme klub, en lignende dato, nærliggende GPS-koordinater, den samme fotograf og så videre. Dog Album angiver tydeligt, at det vedlagte Photo s er en del af et enkelt emne eller en enkelt historie. Som sådan er de sikkerhedsrelevante aspekter af ét Photo kan udledes af en anden i Album . Ordningen kan også forstærke eller formindske disse slutninger. Så tænk ikke kun på Album som en ufarlig samling. Relateret Photo s er alt andet end.
Selvom det ikke er ufarligt ud fra et sikkerhedssynspunkt, Album er en ligetil enhed med et rent Id surrogatnøgle, der ejes af en Club (ikke en Person ). Album_Photo giver os et sæt Photo s sekventeret efter Photo_Order . Du vil bemærke, at jeg har lavet Album id og order den primære nøgle. Forholdet er virkelig mellem Photo og Album , så hvorfor ikke gøre dem til den primære nøgle? Fordi ulige tilfælde kræver et Photo for at gentage i et Album er bestemt mulige. Så jeg satte Photo_Order ind i den primære nøgle og besluttede efter nogen overvejelse at tilføje en alternativ unik nøgle med album og foto for at forhindre et Photo fra at gentage i et Album . Hvis nok græder til at gentage et Photo i et Album opstår, er en unik nøgle nemmere at fjerne end en primær nøgle.
Nøglelæring nr. 4:
Vælg en kandidatnøgle til den primære nøgle med mindst risiko for at blive kasseret senere.
Fotometadata
Den sidste potentielt følsomme information, der skal tilføjes, er metadataene (normalt oprettet af den enhed, der har taget billederne). Disse data er ikke del af et forhold, men det er iboende til billedet. Den primære definition af information, et kamera gemmer sammen med et foto, er EXIF, en industristandard fra Japan (JEITA). EXIF kan udvides og kan understøtte snesevis eller hundredvis af felter, hvoraf ingen kan kræves fra vores uploadede billeder. Denne ikke-påkrævede status skyldes, at disse felter ikke er fælles for alle fotoformater og kan slettes før upload. Jeg har bygget Photo med mange almindeligt anvendte felter, herunder:
- camera_mfr
- kameramodel
- camera_software_version
- image_x_resolution
- image_y_resolution
- image_resolution_unit
- image_exposure_time
- camera_aperture_f
- GPSLatitude
- GPSLængdegrad
- GPSAltitude
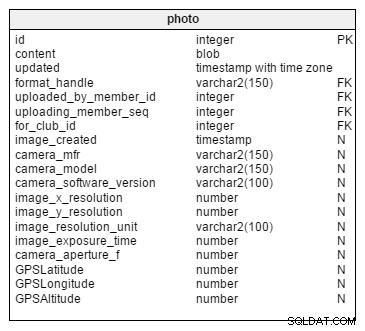
GPS-felterne er, naturligt nok, dem, der tilføjer den højeste følsomhed til et Photo .
Vores model med alle følsomme og værdifulde data defineret
Vi afslutter denne fase med at sikre klubdatabasen med disse ændringer. Alle forbindelser og de nødvendige yderligere data er til stede, som vist nedenfor. Jeg har lavet Photo information rød og Album lys turkis for at formidle min idé om logiske grupperinger. Forøgelsen af dataelementer er reel, men meget minimeret.
Konklusion
At sætte enhver datamodel på et godt sikkerhedsgrundlag kræver en velordnet og systematisk anvendelse af sikkerhedsprincipper samt relationel databasepraksis. I denne rate har vi gennemgået datamodellen og omhyggeligt udfyldt manglende struktur, der var underforstået, men ikke udtrykt i skemaet. Vi kunne ikke tildele værdi eller give beskyttelse til de eksisterende data uden at tilføje de data, der udfylder dem og binder dem korrekt sammen. Med dette på plads, vil vi fortsætte med at vedhæfte elementerne af dataværdiansættelse og datafølsomhed, der giver os mulighed for tydeligt at se alle data fra et komplet sikkerhedsperspektiv. Men det er i vores næste artikel.